Week 7 作業
以下两题,至少选做一题
性能压测的时候,随着并发压力的增加,系统响应时间和吞吐量如何变化,为什么? (Chosen)
用你熟悉的编程语言写一个 Web 性能压测工具,输入参数:URL,请求总次数,并发数。输出参数:平均响应时间,95%响应时间。用这个测试工具以 10 并发、100 次请求压测 www.baidu.com。 (有時間再做)
系统响应时间的变化
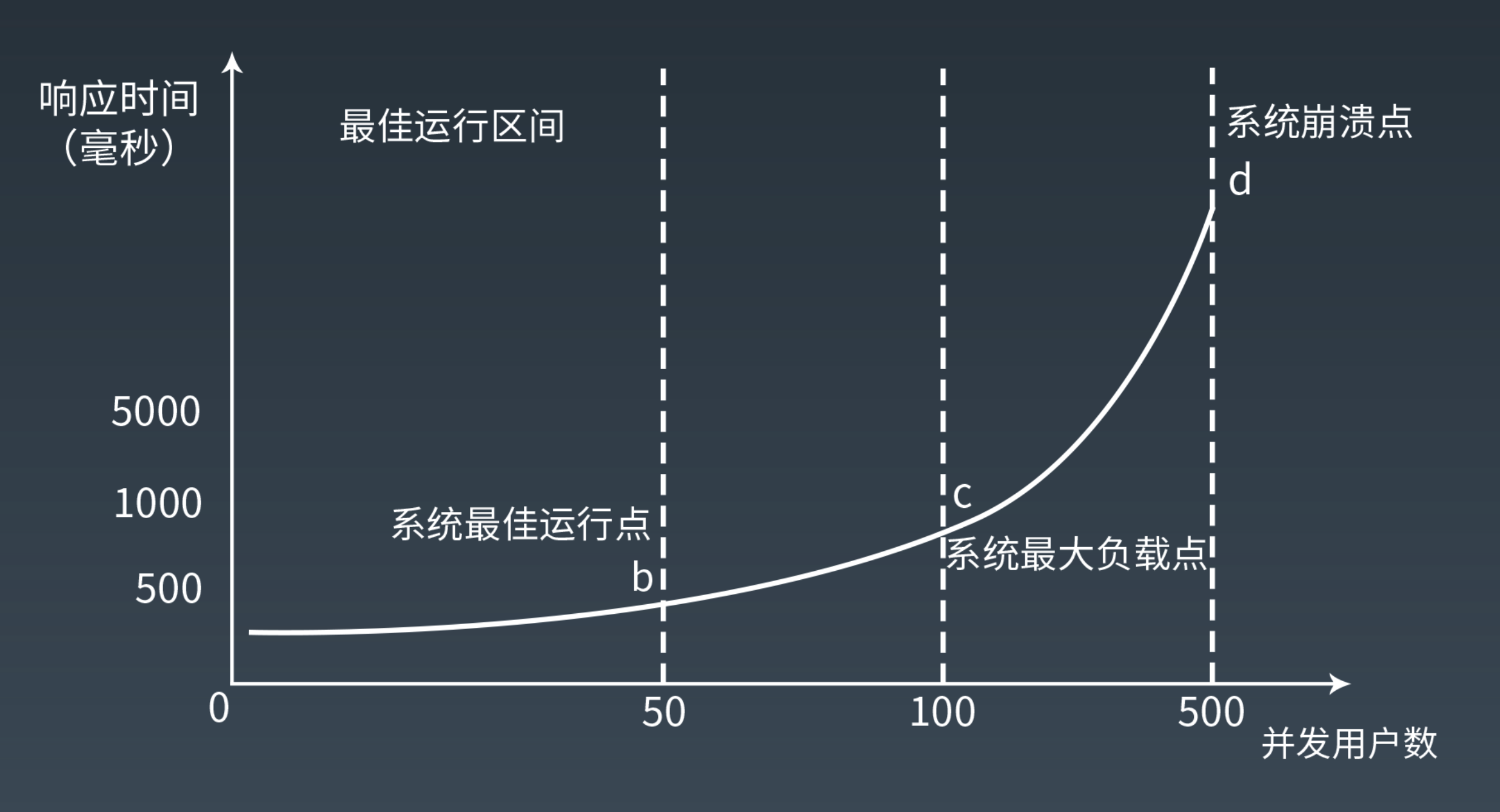
=> 加速上升的曲線
[a to b]
響應時間慢慢增加
原因:資源都充足夠用,響應時間不會受到影響
[b to c]
響應時間加速增加
原因:過了 b 點,某些資源開始出現不足(eg CPU),有些 threads 就要等待被 CPU 調度執行了,所以響應時間開始變長。
[c(最大負載點) to d]
響應時間急劇增加
原因:再增加併發數,系統資源嚴重不足,
[after d]
超越系統負載,server down
原因:CPU 的資源都花費在虛擬內存的置換上,處理能力越降越低,CPU 到最後什麼也處理不了了,一堆 thread 都在等待資源,資源被耗盡了,所以的請求都失去了響應,系統看起來就崩潰了。
吞吐量(以 TPS 為例作為指標)的变化
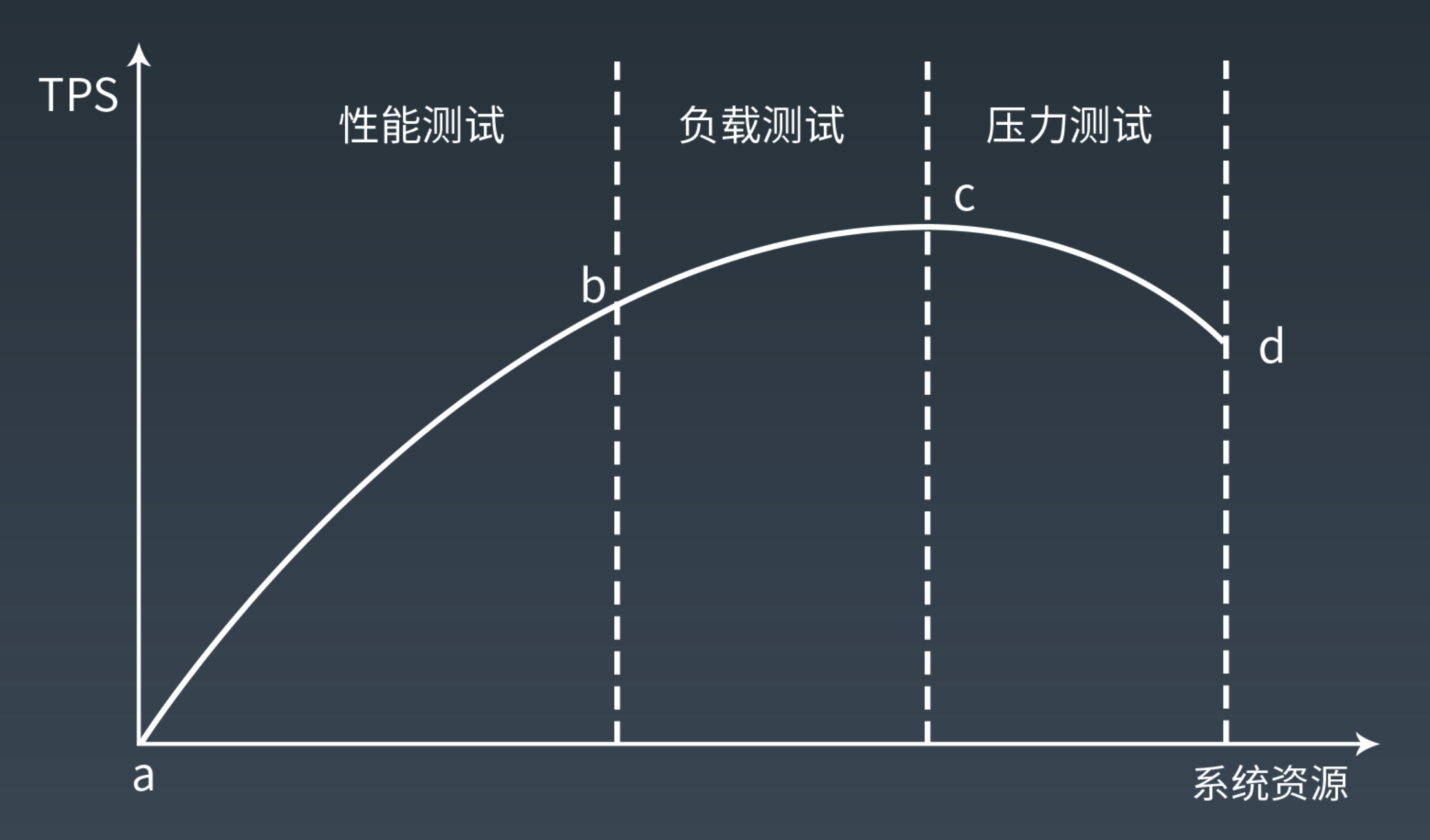
=> 拋物線
[a to b]
TPS 增加比併發數的增加快
原因:一開始沒有併發請求,server 都是空閒的(一開始 TPS=0)。慢慢增加,系統開始為每個請求創建幾個 threads 去處理請求,每個 thread 都能獲得 CPU 的 schedule 調度,都可以有足夠的內存空間供它使用,這時候資源都是夠用的,所以 TPS 很快就處理完了。
[b to c (巔峰)]
增長減慢
原因:資源開始不足,有些 threads 要等待 CPU 調度,
[c to d]
開始下降
原因:內存不足,開始使用 disk(硬盤)幫忙處理。disk is slow.
[d 之後]
超越系統負載,server down, TPS = 0
原因:CPU 的資源都花費在虛擬內存的置換上,處理能力越降越低,CPU 到最後什麼也處理不了了,一堆 thread 都在等待資源,資源被耗盡了,所以的請求都失去了響應,系統看起來就崩潰了。
=》Distributed system 要解決我的問題
就是攤分請求,讓效率停留在[a to b] 或者 [b to c] 的最好狀態。
版权声明: 本文为 InfoQ 作者【Christy LAW】的原创文章。
原文链接:【http://xie.infoq.cn/article/954b9656544b3abad7aa14cde】。文章转载请联系作者。

Christy | Software Engineer 2020.03.19 加入
Github : https://github.com/christypacc21









评论