Spring 不止 AOP 与 IOC:Spring 生态详解
一、概述
很多人认为 Spring 中亮点是 AOP 与 IOC,其实这个理解是非常片面的,除了暴露你是一个小白以外什么也说明不了;在 Spring 中最大的亮点是整个 Spring 的生态;也就是基于这个生态,才可以让 Spring 集成其他资源(MyBatis 等)的时候可以有序不乱的没有问题的管控及执行,这些都必须要归功于 Spring 的生态;
AOP 与 IOC 的区别
AOP(Aspect Oriented Programming):面向切面编程,是一个概念,是一个理论的东西,需要其他外部的实现;可以理解成一种解耦抽象的方式,且 :指的是横切逻辑,原有业务逻辑代码不动,只能操作横切逻辑代码,所以面向横切逻辑;面 :横切逻辑代码往往要影响的是很多个方法,每个方法如同一个点,多个点构成一个面。这里有一个面的概念
IOC(Inverse of Control):是控制反转的意思,是一种模式,是一种设计思想,依赖注入(DI)是 IOC 最常见以及最合理的实现方式;
在 Spring 中所有资源都是依赖于 IOC,即:所有类及资源的加载都是基于 IOC 容器来管理的;另外在源码中可以看到都是基于 IOC 的基础上进行的拓展;除了 IOC 以外的所有资源都是通过拓展功能进行装载及管理的;
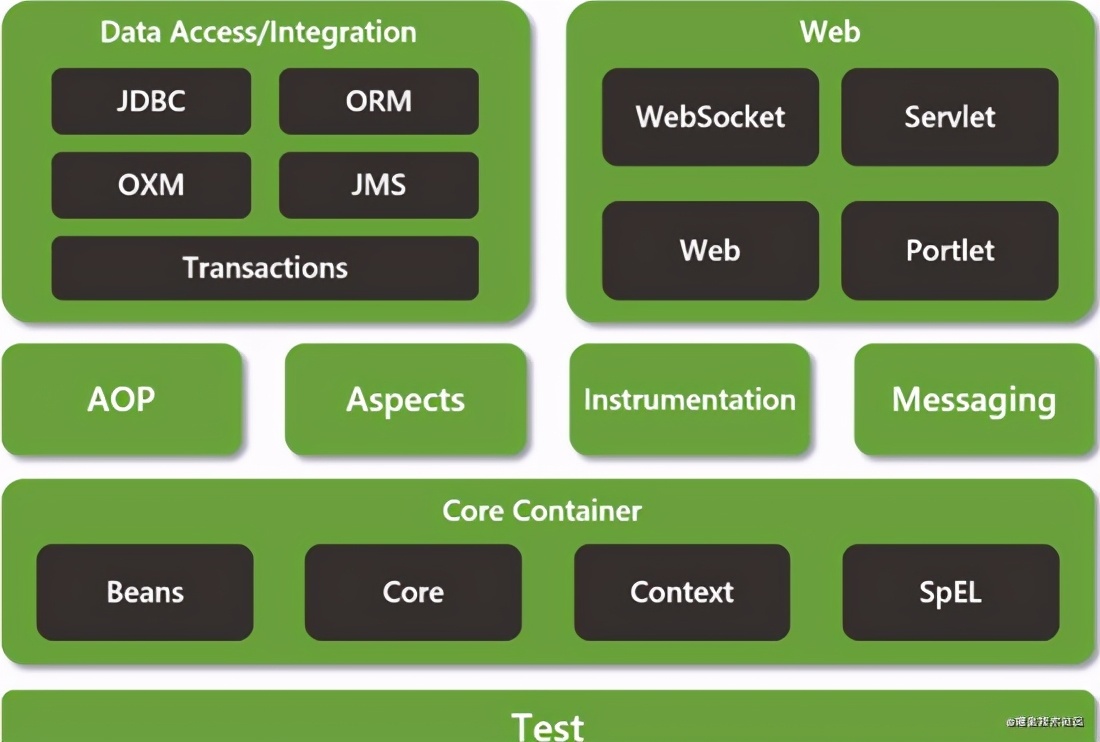
二、Spring 体系结构
下图基于 Spring4.X;在 Spring5 之后官方推荐使用 SpringBoot 来构建;
Core Container:是核心容器,IOC 容器就属于这个核心容器;
**Beans:**用于管理 Bean 的维护管理;
**Core:**核心工具;
**Context:**上下文;
**SpEL:**EL 表达式处理;
AOP 与 Aspects:在 Spring 中 AOP 仅仅是引用了 Aspects 的注解及表达式,并没有完全地使用 Aspects;
三、IOC
是控制反转,是一个设计理念,也称为:依赖倒置,用于解决层与层之间或者类与类之间的耦问题;
在传统开发中假设有 A、B 两个类,其中 B 依赖 A,在使用的时候必须先要创建一个 A 的实例,其中要考虑创建 A 的各种条件及因素(创建、初始化、销毁、变更等);而在控制反转中,是将需求方进行统一管理,当 B 需要 A 的时候只需要说一声“我要 A”就会有人主动把初始化好的 A 交到你的手中;对于 B 而言直接使用 A 中的 API 即可;
上面的例子,可能一般人不能明白,这里转换一下,换一个普通人可以理解的例子:
董事长依赖总经理、总经理依赖部门经理、部门经理依赖员工;如果“员工离职了”、“部门经理叛逃了”老板怎么办?那么把关系颠倒过来:“员工受部门经理管理,部门经理受总经理管理,总经理受董事长管理”;这样一来是不是解决了问题了呢;
在 Spring 中实现了一个容器(其实就是一个 Map 对象,Key:Bean 的名称;Value:为 Bean 的定义),这个容器中装载了所有的 Bean 对象,在需要使用地方只需要向容器中索取即可,由依赖注入(DI)来解决创建、初始化、销毁、变更等问题;
四、委托管理
如何将自己定义的 Bean 委托交给 IOC 来进行管理呢?方法归纳如下:
1、通过 XML 配置
2、通过注解方式
通过上面的两种方法可以将配置的类委托给 IOC 来进行管理;
注:在 SpringBoot 中直接通过 Main 方法可以自动扫描 Main 所在路径下(包含所有子路径下)的所有类;
结合上述内容,可以轻松地把需要的对象委托给 IOC 容器进行管理,那么委托给 IOC 容器的对象是如何进行处理的呢;这里需要了解一个 Spring 的重要知识点:BeanFactory(Bean 工厂)
4.1)简单的示例
创建一个简单的接口;public interface IBean { void testDemoFunction1(); }
创建一个实现类 public class TestBean implements IBean {@Override publicvoid testDemoFunction1(){ System.out.println("testDemoFunction1"); } 复制代码}
创建一个配置类,注意 @Configuration 与 @Bean 注解,当然你也可以 @ComponentScan 等注解用于描述一个将被扫描的路径;@Configuration public class TestConfig { @Bean public IBean testBean(){ return new TestBean(); } }
创建启动类,运行看效果;public class TestMain { public static void main(String[] values){ final AnnotationConfigApplicationContext annotationConfigApplicationContext = new AnnotationConfigApplicationContext(TestConfig.class); final IBean testBean = (IBean)annotationConfigApplicationContext.getBean("testBean"); testBean.testDemoFunction1(); } }---------------最终打印结果--------------------- testDemoFunction1
4.2)简单的源码跟踪
从 4.1 中可以看到通过 getBean 方法可以直接获取到我们定义的 Bean 对象;那么他是如何实现的呢?进入 getBean 的源码中看看
来看看这个是 ConfigurableListableBeanFactory 个什么东西
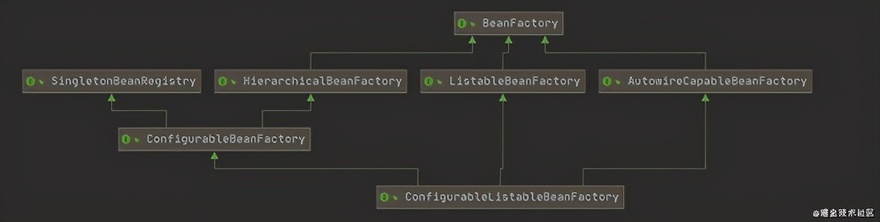
很明显这类是 BeanFactory 的接口抽象;
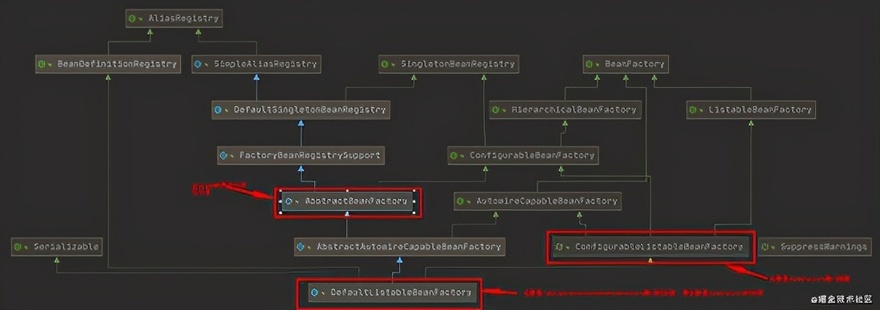
从这个 UML 图中可以看出 DefaultListableBeanFactory 中仅仅是实现了 ConfigurableListableBeanFactory,但是没有实现超类接口中的 getBean 方法,具体的 getBean 方法是在 AbstractBeanFactory 中实现的;
4.3)BeanFactory 是什么
BeanFactory 是 Spring 对 Bean 管理的顶层核心接口,使用了简单工厂模式,负责生产 Bean;
4.4)Bean 的装配
上面说了一堆,都是说得怎么获取到 Bean,那么这些 Bean 是什么时候及怎么放进去的呢?在最前面有过介绍 Bean 的装载是由多种形式的,有 XML(ClassPathXmlApplicationContext)、也有注解(AnnotationConfigApplicationContext)等多种方式,如果一种方式写一种加载模式,Spring 的开发人员肯定要哭了,这么多的方式是通过什么办法统计进行处理的呢?
先来看看下面的一个例子:
业务人员拿到了某小区的销售信息,查询到张先生与李先生都购买了这个小区的房子,装修公司的销售找到了张先生与李先生,张先生需要装修而李先生不需要装修,销售带张先生先来到装修公司,张先生提出自己的需求,装修公司的设计师根据张三的需求出装修设计图纸,然后装修公司再找到工厂去下单生产,最后在张三的房子中安装完成装修;
在这个例子中翻译过来:
**张先生与装修:**可以看作 2 个类,张三需要依赖装修才能入住;
**装修公司:**可以看作上下文对象(ApplicationContext),由装修公司进行统一的管理;
**业务人员:**可以看作 Bean 定义读取对象(BeanDefinitionReader),用于加载配置信息;
**销售:**可以看作 Bean 定义扫描对象(BeanDefinitionSacnner),用于扫描所有对象;用于处理配置中的信息,确定哪些需要装载到容器,哪些不需要;
**设计师的图纸:**可以看作 Bean 定义对象(BeanDefinition),这里包含了 Bean 的所有描述信息,为工厂的生产提供依据;
**工厂:**可以看作 BeanFactory 用于生产装修需要的东西;
装修公司的业务人员拿到楼盘购买信息,销售人员根据业务人员提供的业主信息把所有业主的联系方式都找出来,最终找到了张先生,邀请张先生到装修公司来洽谈业务,装修公司根据张先生的装修的风格(是否单例)、灯具要求(是否懒加载)、墙面需求、地板需求等多方面的需要进行设计;设计好的图纸交给工厂,工厂根据设计的图纸进行生产;虽然张先生对房屋整装的需求很多,但最终都变成了可量化的图纸,而工厂不关心张先生还是李先生,只根据图纸进行生产,根据多源同根的原则解决了问题;
在 Spring 中也是如此操作及处理的,不管外部的源是什么,最终都会变成一个统一的 Bean 定义对象(BeanDefinition),最后 Bean 工厂(BeanFactory)根据这个 Bean 定义(BeanDefinition)进行生产;大致的流程为:读取配置——>筛选对象——>生成 Bean 定义——>注册 Bean 定义——>生产 Bean;
对于外部配置而言,不管外面是什么样的场景,最终都是转换为对应的 BeanDefinitionReader;
**AnnotatedBeanDefinitionReader:**用于读取注解的 Bean 定义配置;
**XmlBeanDefinitionReader:**用于读取 XML 的 Bean 定义配置;
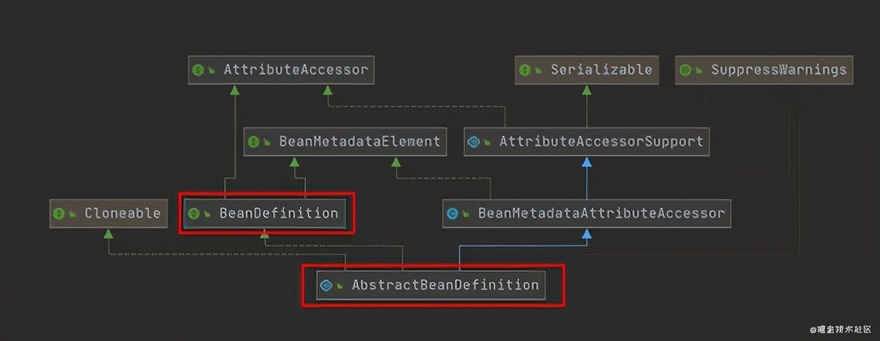
在 AbstractBeanDefinition 中可以看到定义了如下几个关键的属性
BeanDefinition 也是 Spring 中的一个重要的核心接口,封装了生产 Bean 的一切信息;BeanDefinition 是通过 BeanDefinitionRegistry 进行装载的;BeanDefinitionRegistry 的装载方法如下:
总结:一个类要变成一个 Bean,首先要把类变成 Bean 定义,需要经过:ApplicationContext 读取配置类——>根据配置类扫描满足加载条件的类——>将满足条件的类变成 Bean 定义(BeanDefinition)——>将 Bing 定义进行注册——>由 BeanFactory 进行生产——>最后变成我们的 Bean;并且 ApplicationContext 可以调用 BeanFactoryPostProcessor 修改 Bean 定义,也可以调用 BeanDefinitionRegistryPostProcessor 来注册 Bean 定义;
五、Bean 的生命周期
上面已经把我们的 Bean 装载到 IOC 中了,那么一个 Bean 的周期是什么样的?需要经过哪些步骤?带着这些问题我们继续往下看;
5.1)实例化
一般情况下是使用反射的方式进行处理,但是需要注意的是,这里仅仅只是 Bean 对象的实例化,Bean 中的资源还没有解析(例如:@Autowired 这些注解类型的资源),这个时候的 Bean 仅仅只是一个空壳而已;
还可以通过工厂方法来进行处理,我们在配置类中使用 @Bean 注解标识的方法就是一个工厂方法;
反射是由 Spring 自身的机制完成实例化的,而工厂方法是用户自己完成的,通俗的讲反射是 Spring 通过自己的算法来实现的(也就是上面说的没看明白的那个方法),而工厂方法是用户自己控制 new 方法来完成的,用户拥有初始化的完全掌控权;
我们常用的 @Service、@RestController、@Component 等都是通过反射的方式来进行实例化的;
反射没有工厂灵活
5.2)注入填充属性
在这一步里才是真正的解析 @Autowired、@Value 等资源,开始将对象的资源进行注入;
在填充的时候会出现循环依赖问题,即:BeanA 中 @Autowired BeanB,BeanB 中 @Autowired BeanA。BeanA 依赖 BeanB,BeanB 依赖 BeanA,这个时候一个闭环就出现了,这就是循环依赖问题产生的原因,目前 Spring 已经解决了这个问题,是采用三级缓存来解决的,貌似是采用的标识方法来解决的,当初始化 BeanA 的时候标识为正在创建,当创建 BeanB 的时候发现依赖的 BeanA 被标识为正在创建,那么就会直接退出,从而解决了循环依赖的问题,这部分内容在后面的章节中再进行详细的阐述吧;
5.3)初始化
这一步是对 Bean 的属性进行初始化处理,例如调用我们定义的 initMethod、destroy 等方法;到了这里 Bean 基本上是一个可用状态了;注意,这里也是 AOP 接入的地方;
5.4)装入缓存
这里会把初始化好的 Bean 装载到一个 Map 中(Key:Bean 的名称;Value:Bean 的实例),这个 Map 就是 Spring 中大名鼎鼎的“单例缓存池”,也是我们常说的一级缓存,在调用 getBean 的时候都是从这里面获取的;
注意:到这里一个 Bean 的生命周期基本完成,但是不完整,因为在 Bean 初始化阶段还会调用很多(一堆)Bean 声明周期回调方法,例如:BeanNameAware、BeanClassLoaderAware、BeanFactoryAware 等等等等等等等等等等,总之就是疯狂的各种各样的一堆 Aware;通过这些接口可以获取到很多有用的资源,例如:Bean 的名字、Bean 的类加载器
原文链接:https://juejin.cn/post/6931996590664220679
如果觉得本文对你有帮助,可以关注一下我公众号,回复关键字【面试】即可得到一份 Java 核心知识点整理与一份面试大礼包!另有更多技术干货文章以及相关资料共享,大家一起学习进步!

版权声明: 本文为 InfoQ 作者【Java王路飞】的原创文章。
原文链接:【http://xie.infoq.cn/article/8d581e0db3f9fc4e0c64e1ec3】。未经作者许可,禁止转载。

需要资料添加小助理vx:17375779923 即可 2021.01.29 加入
Java领域;架构知识;面试心得;互联网行业最新资讯









评论 (1 条评论)