「更高更快更稳」,看阿里巴巴如何修炼容器服务「内外功」


作者 | 守辰、志敏
来源|阿里巴巴云原生公众号
11 月 11 日零点刚过 26 秒,阿里云再一次抗住了全球最大的流量洪峰。今年 双11 是阿里经济体核心系统全面云原生化的一年,相比去年核心系统的上云,云原生化不仅让阿里享受到了云计算技术成本优化的红利,也让阿里的业务最大化获得云的弹性、效率和稳定性等价值。
为应对 双11,阿里云原生面临怎样的挑战?
为了支持阿里这样大规模业务的云原生化,阿里云原生面临怎么样的挑战呢?
1. 集群多、规模大
基于对业务稳定性和系统性能等方面的综合考虑,大型企业往往需要将业务集群部署到多个地域,在这样的场景下,支撑多集群部署的容器服务能力非常必要。同时,为了简化多集群管理的复杂度,以及为不能实现跨集群服务发现的业务提供支持,还需要关注容器服务中单个集群对大规模节点的管理能力。另外,大型企业的业务复杂多样,因此一个集群内往往需要部署丰富的组件,不仅包括主要的 Master 组件, 还需要部署业务方定制的 Operator 等。集群多、规模大,再加上单个集群内组件众多, 容器服务的性能、可扩展性、可运维性都面临着很大的挑战。
2. 变化快、难预期
市场瞬息万变,企业,特别是互联网企业,如果仅凭借经验、依靠规划来应对市场变化,越来越难以支撑业务发展,往往需要企业快速地进行业务迭代、部署调整以应对市场的变化。这对为业务提供应用交付快速支持、弹性伸缩性能和快速响应支撑的容器服务提出了很大的要求。
3. 变更多、风险大
企业 IT 系统的云原生化过程不仅要面临一次性的云迁移和云原生改造成本,还将持续应对由于业务迭代和基础设施变更、人员流动带来的风险。而业务的迭代、基础设施的变更会无法避免地为系统引入缺陷,严重时甚至造成故障,影响业务正常运行。最后,这些风险都可能会随着人员的流动进一步加剧。
阿里云容器服务大规模实践
1. 高扩展性
为了提高容器服务的可扩展性,需要自底向上、联动应用和服务一起优化。
1)接口最小化
针对上层 PaaS,容器服务依托 OAM(Open Application Model) 和 OpenKruise Workload 提供了丰富的应用交付能力抽象。对于 PaaS 层来说,只需要读取汇总的应用部署统计数值即可,极大减少了上层系统需要批量查询 pod、event 等信息的工作量,进而减小了对容器服务的管控压力;同时,通过把数量多、占用空间大的 pod 及 events 信息转存到数据库中, 并根据数据库中的内容提供一个统一的、可内嵌的部署状态查看和诊断页面的方式,可以使 PaaS 层避免直接访问容器服务来实现相关功能。
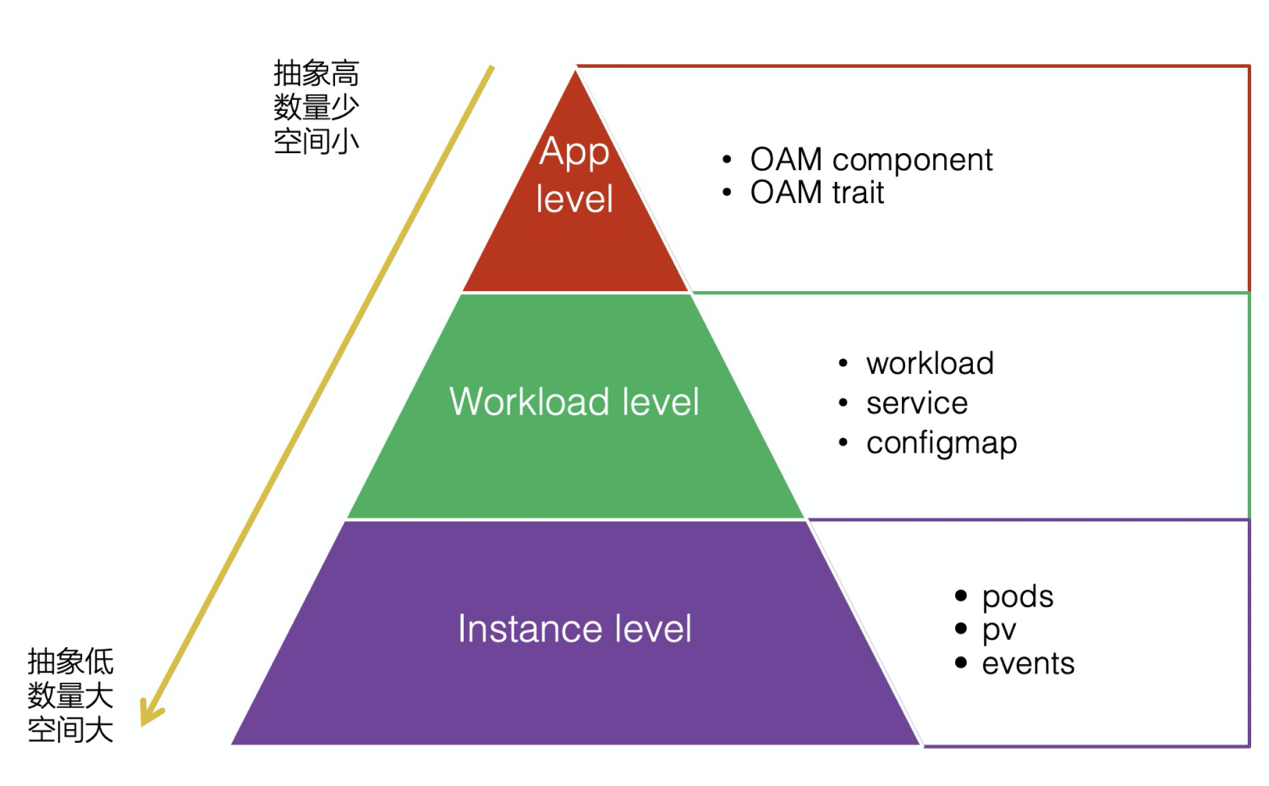
2)分化而治之
“分化而治之”是指要对业务做出合理的划分,避免因为所有业务和应用都集中在少数几个命名空间中,导致容器服务管控(控制器和 APIServer)在查询命名空间下所有资源时产生过大消耗的情况。目前在阿里内部最广泛的实践方式是使用“应用名”做为命名空间。一方面应用是业务交付的基本单位,且不受组织调整的影响;另一方面,容器服务的组件以及业务自己的 Operator,在处理时往往会 list 命名空间下的资源,而命名空间默认在控制器和 APIServer 中都实现有索引,如果使用应用作为命名空间可以利用默认的索引加速查询操作。
3)苦修内外功
对于容器服务的核心管控,需要扎实的内功做基础。针对大规模的使用场景,阿里云的容器服务进行了大量的组件优化,比如通过索引、Watch 书签等的方式,避免直接穿透 APIServer 访问底层存储 ETCD,并通过优化 ETCD 空闲页面分配算法、分离 event 和 lease 存储至独立 ETCD 的方法,提升 ETCD 本身的存储能力,其中不少已经反馈给了社区,极大降低了 ETCD 处理读请求的压力。 详情可查看:https://4m.cn/JsXsU。
其次,对于核心管控本身,要做好保护的外功。特别是安全防护,需要在平时就做好预案,并且常态化地执行演练。例如, 对于容器服务 APIServer, 需要保证任何时候的 APIServer 都能保持可用性。 除了常见的 HA 方案外, 还需要保证 APIServer 不受异常的 operator 和 daemonset 等组件的影响。为了保证 APIServer 的鲁棒性,可以利用官方提供的 max-requests-inflight 和 max-mutating-requests-inflight 来实现, 在紧急情况下阿里云还提供了动态修改 infight 值配置的功能,方便在紧急情况下不需要重启 APIServer 就可以应用新的配置进行限流。
对于最核心的 ETCD,要做好数据的备份。考虑到数据备份的及时性,不仅要进行数据定期的冷备,还需要实时地进行数据的异地热备,并常态化地执行数据备份、灰度的演练,保证可用性。
2. 快速
在应对业务变化多、基础设施变化多带来的不可预期问题,可采取以下方式。
1)负载自动化
为了高效地进行应用交付,研发需要权衡交付效率和业务稳定性。阿里大规模地使用 OpenKruise 进行应用的交付,其中 cloneset 覆盖了阿里上百万的容器。 在 cloneset 中可以通过 partition 来控制暂停发布从而进行业务观察,通过 maxunavailable 来控制发布的并发度。通过综合设置 partition 和 maxunavailable 可以实现复杂的发布策略。实际上,大多数情况下 PaaS 层在设计分批发布的功能时,往往选取了每批暂停的方式(仅通过 cloneset partition 字段来控制分批),如下图。然而,每批暂停的方式往往因为应用每批中个别机器的问题而产生卡单的问题,严重影响发布效率。
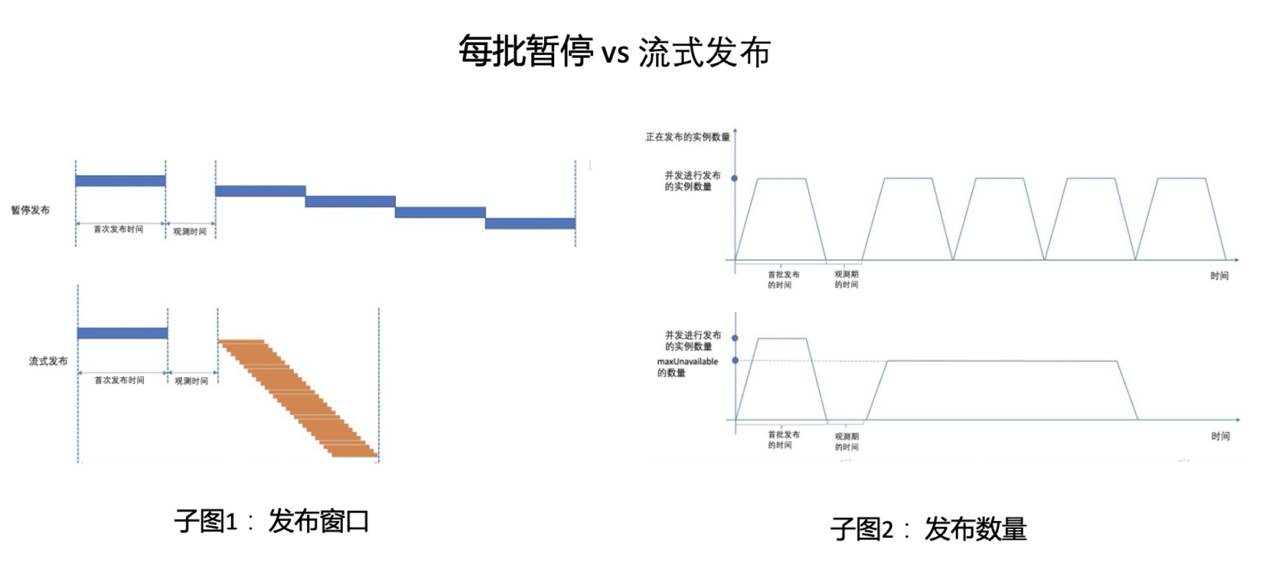
因此推荐使用流式发布的配置:
2)以快制动
为了应对突发的业务流量, 需要能够快速的进行应用的部署,并从多方面保障紧急场景的快速扩容。
一方面,通过推进业务使用方的 CPUShare 化,让应用能够原地利用节点额外计算资源,从而给紧急扩容争取更多的反应时间。
其次,通过镜像预热的方式来预热基础镜像,通过 P2P 和 CDN 的技术加速大规模的镜像分发,通过按需下载容器启动实际需要的镜像数据,使业务镜像下载时间极大地降低。
3)打好提前量
俗话说,"不打无准备之仗" 。要实现高效率的部署,做好准备是必需的。
首先是对于资源的准备, 如果集群内没有为服务准备好一定的容量,或者没有为集群准备好额外节点额度的话,就无法在必要时实现弹性。因为阿里不同业务有着不同的流量峰值,我们会结合实际情况定期对部分业务缩容,并对另外一种业务进行扩容的方式实现计划资源的伸缩。
当然,寻找这样可以匹配较好的业务组会比较困难,对于采用函数等 Serverless 形态的应用, 阿里构建一个公共预扩容的 Pod 池,使得不同业务紧急扩容时能够完全规避调度、网络和储存的开销, 达到极致的扩容速度。
3. 稳定
为了确保使用容器服务的业务稳定,阿里在具体实践中遵循了以下几个原则。
1)信任最小化
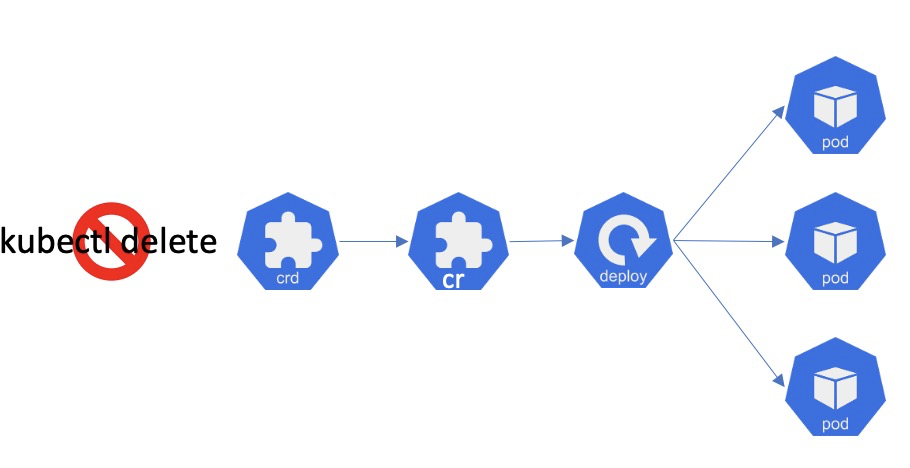
俗话说,"常在河边走,哪有不湿鞋"。为了确保频繁进行集群运维工作的同学不因为疏忽而犯错,就要保证业务可操作的权限最小化,对于授权的写和删除操作,还要增加额外的保护。近一步来讲,为了防止容器服务用户的误操作,我们对 Namespace、CRD 和 Workload 的资源都增加了级联删除的保护,避免用户因为误删除还在运行 Pod 的 Namespace、CRD 和 Workload 而引发灾难性的后果。下图展示了删除一个 CRD 可能造成的级联删除故障,实际应用中,许多 operator 中都会设置 CR 为关联 Workload 的 Owner, 因此一旦删除了 CRD(例如非预期的 Operator 升级操作),极有可能会导致级联删除关联的所有 Pod,引起故障。
另外, 对于业务运行依赖的如日志上传、微服务调用、安全审计等基础设功能,需要进行资源的隔离。因此,阿里在对应用进行大量的轻量化容器改造过程中,采取了把基础设施功能从应用的富容器中剥离到 Sidecar 或者 Daemonset 中的方式,并对 Sidecar 或者 Daemon 的容器进行资源的隔离, 保证即使基础设施功能发生内存泄露等异常也不会直接影响业务的正常运行。
2)默认稳定性
指保证所有应用都具备基本的稳定性保障配置,包括默认的调度打散策略、Pod 中断预算、应用负载发布最大不可用数量,让稳定性成为像水、电、煤一样的基础设施。这样能够避免应用因为宿主机故障、运维操作、应用发布操作导致服务的完全不可用。保障可以通过 webhook 或者通过全局的应用交付模板来实现,应用 PaaS 也可以根据业务的实际要求来定制。
3)规范化应用
在进行云原生改造时,需要制定启停脚本、可用和探活探针规范,帮助业务把自愈能力内置到应用中去。这包括推动应用配置相应的存活探针,保证应用在异常退出后能够被自动拉起;保证应用启动和退出时执行优雅上下线的操作等。配合这些规范,还需要设置相关探针的准入、监测机制,防止业务研发同学在对 K8s 机制不完全了解的情况下编写错误的探针。我们常常见到很多研发同学直接复用已有的健康检查脚本来作为探活探针,但是这些脚本往往存在调用开销大(例如执行了解压缩)、存在副作用(例如会修改业务流量开启状态)、以及执行不稳定(例如调用涉及下游服务)的问题,这些对业务的正常运行都会产生非常大的干扰,甚至引发故障。
4)集中化处理
对于探活失败的自动重启、问题节点的驱逐操作, 阿里云容器服务把 Kubelet 自主执行的自愈操作,改为了中心控制器集中触发,从而可以利用应用级别的可用度数据实现限流、熔断等安全防护措施。这样,即使发生了业务错配探活脚本或者运维误操作执行批量驱逐等操作状况,业务同样能得到保护;而在大促峰值等特殊的业务场景下,可以针对具体需求设计相应的预案,关闭相应探活、重启、驱逐等操作,避免在业务峰值时因为探活等活动引起应用资源使用的波动,保证业务短期的极致确定性要求。
5)变更三板斧
首先,要保证容器服务自身的变更可观测、可灰度、可回滚。 对于 Controller 和 Webhook 这类的中心管控组件,一般可以通过集群来进行灰度,但如果涉及的改动风险过大,甚至还需要进行 Namespace 级别细粒度的灰度;由于阿里部分容器服务是在节点上或者 Pod 的 Sidecar 中运行的,而官方 K8s 中欠缺对于节点上 Pod 和Sidecar 中容器的灰度发布支持,因此阿里使用了 OpenKruise 中的 Advance Daemonset 和 Sidecarset 来执行相关的发布。
使用阿里云容器服务轻松构建大规模容器平台
阿里云容器服务 ACK(Alibaba Cloud Container Service for Kubernetes)是全球首批通过 Kubernetes 一致性认证的服务平台,提供高性能的容器应用管理服务,支持企业级 Kubernetes 容器化应用的生命周期管理。ACK 在阿里集团内作为核心的容器化基础设施,有丰富的应用场景和经验积累,包括电商、实时音视频、数据库、消息中间件、人工智能等场景,支撑广泛的内外部客户参加 双11 活动;同时,容器服务将阿里内部各种大规模场景的经验和能力融入产品,向公有云客户开放,提升了更加丰富的功能和更加突出的稳定性,容器服务连续多年保持国内容器市场份额第一。
在过去的一年,ACK 进行了积极的技术升级,针对阿里的大规模实践和企业的丰富生产实践,进一步增强了可靠性、安全性,并且提供可赔付的 SLA 的 Kubernetes 集群 - ACKPro 版。ACK Pro 版集群是在原 ACK 托管版集群的基础上发展而来的集群类型,继承了原托管版集群的所有优势,例如 Master 节点托管、Master 节点高可用等。同时,相比原托管版进一步提升了集群的可靠性、安全性和调度性能,并且支持赔付标准的 SLA,适合生产环境下有着大规模业务,对稳定性和安全性有高要求的企业客户。
9 月底,阿里云成为率先通过信通院容器规模化性能测试的云服务商,获得最高级别认证—“卓越”级别,并首先成功实现以单集群 1 万节点 1 百万 Pod 的规模突破,构建了国内最大规模容器集群,引领国内容器落地的技术风向标。此次测评范围涉及:资源调度效率、满负载压力测试、长稳测试、扩展效率测试、网络存储性能测试、采集效率测试等,客观真实反映容器集群组件级的性能表现。目前开源版本 Kubernetes 最多可以支撑 5 千节点及 15 万 Pod,已经无法满足日益增长的业务需求。作为云原生领域的实践者和引领者,阿里云基于服务百万客户的经验,从多个维度对 Kubernetes 集群进行优化,率先实现了单集群 1 万节点 1 百万 Pod 的规模突破,可帮助企业轻松应对不断增加的规模化需求。
在应用管理领域,OpenKruise 项目已经正式成为了 CNCF 沙箱项目。OpenKruise 的开源也使得每一位 Kubernetes 开发者和阿里云上的用户,都能便捷地使用阿里内部云原生应用统一的部署发布能力。阿里通过将 OpenKruise 打造为一个 Kubernetes 之上面向大规模应用场景的通用扩展引擎,当社区用户或外部企业遇到了 K8s 原生 Workload 不满足的困境时,不需要每个企业内部重复造一套相似的“轮子”,而是可以选择复用 OpenKruise 的成熟能力。阿里集团内部自己 OpenKruise;而更多来自社区的需求场景输入,以及每一位参与 OpenKruise 建设的云原生爱好者,共同打造了这个更完善、普适的云原生应用负载引擎。
在应用制品管理领域,面向安全及性能需求高的企业客户,阿里云推出容器镜像服务企业版 ACR EE,提供公共云首个独享实例的企业级服务。ACR EE 除了支持多架构容器镜像,还支持多版本 Helm Chart、Operator 等符合 OCI 规范制品的托管。在安全治理部分,ACR EE 提供了网络访问控制、安全扫描、镜像加签、安全审计等多维度安全保障,助力企业从 DevOps 到 DevSecOps 的升级。在全球分发加速场景,ACR EE 优化了网络链路及调度策略,保障稳定的跨海同步成功率。在大镜像规模化分发场景,ACR EE 支持按需加载,实现镜像数据免全量下载和在线解压,平均容器启动时间降低 60%,提升 3 倍应用分发效率。目前已有众多企业生产环境模使用 ACR EE,保障企业客户云原生应用制品的安全托管及多场景高效分发。
我们希望,阿里云上的开发者可以自由组合云上的容器产品家族,通过 ACK Pro+ACR EE+OpenKruise 等项目,像搭积木一样在云上打造众多企业自有的大规模容器平台。

阿里巴巴云原生 2019.05.21 加入
还未添加个人简介









评论