开发效率提升 15 倍!批流融合实时平台在好未来的应用实践

摘要:本文由好未来资深数据平台工程师毛祥溢分享,主要介绍批流融合在教育行业的实践。内容包括两部分,第一部分是好未来在做实时平台中的几点思考,第二部分主要分享教育行业中特有数据分析场景。大纲如下:
1、背景介绍
2、好未来 T-Streaming 实时平台
3、 K12 教育典型分析场景
4、展望与规划
1.背景介绍
好未来介绍

好未来是一家 2003 年成立教育科技公司,旗下有品牌学而思,现在大家听说的学而思培优、学而思网校都是该品牌的衍生,2010 年公司在美国纳斯达克上市,2013 年更名为好未来。2016 年,公司的业务范围已经覆盖负一岁到 24 岁的用户。目前公司主营业务单元有智慧教育、教育领域的开放平台、K12 教育以及海外留学等业务。
好未来数据中台全景图
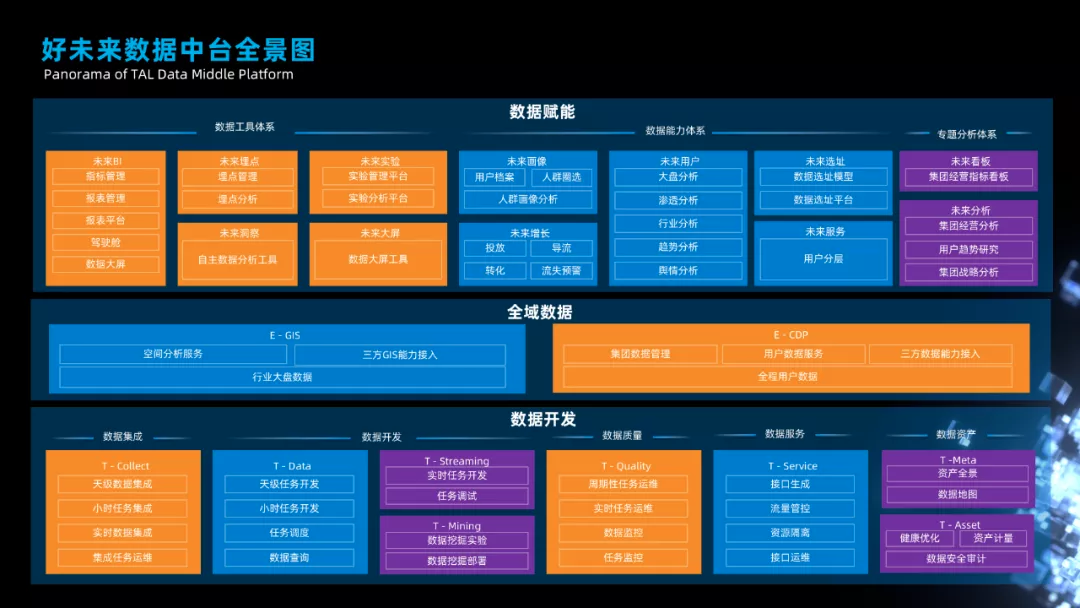
上图为好未来数据中台的全景图,主要分为三层:
● 第一层是数据赋能层
● 第二层是全域数据层
● 第三层是数据开发层
首先,数据赋能层。主要是商业智能、智慧决策的应用,包括一些数据工具、数据能力以及专题分析体系,数据工具主要包括埋点数据分析工具、AB 测试工具、大屏工具;数据能力分析主要包括未来画像服务、未来增长服务、未来用户服务以及新校区的选址服务;专题分析体系主要包企业经营类专题分析等等。
其次,数据全域层。我们期望将全集团所有的事业部的数据进行深入的拉通和融合,打通不同业务线、产品线的用户池,从而盘活全集团的数据。具体的手段是 IDMapping,将设备 id、自然人、家庭三个层级的 id 映射关系挖掘出来,将不同产品上的用户数据关联起来。这样就能够形成一个打的用户池,方便我们更好的赋能用户。
最后,数据开发层。数据开发通过一些列的平台承载了全集团所有的数据开发工程,主要包括数据集成、数据开发、数据质量、数据服务、数据治理等服务。我们今天要分享的实时平台就是在数据开发中。
2.好未来 T-Streaming 实时平台
实时平台构建前的诉求

实时平台在构建之初,我们梳理了四个重要的诉求。
● 第一个诉求是期望有一套统一的集群,通过提供多租户,资源隔离的方式提高资源利用率,解决多个事业部多套集群的问题。
● 第二个诉求是期望通过平台的方式降低实时数据开发的门槛,从而能够覆盖更多的开发者。
● 第三个诉求是期望能够提供通用场景的解决解方案,提高项目的复用性,避免每个事业部都开发相同场景的分析工具。
● 第四个诉求是对作业进行全方位的生命周期管理,包括元数据和血缘,一旦有一个作业出现异常,我们可以快速分析和定位影响范围。
实时平台功能概述
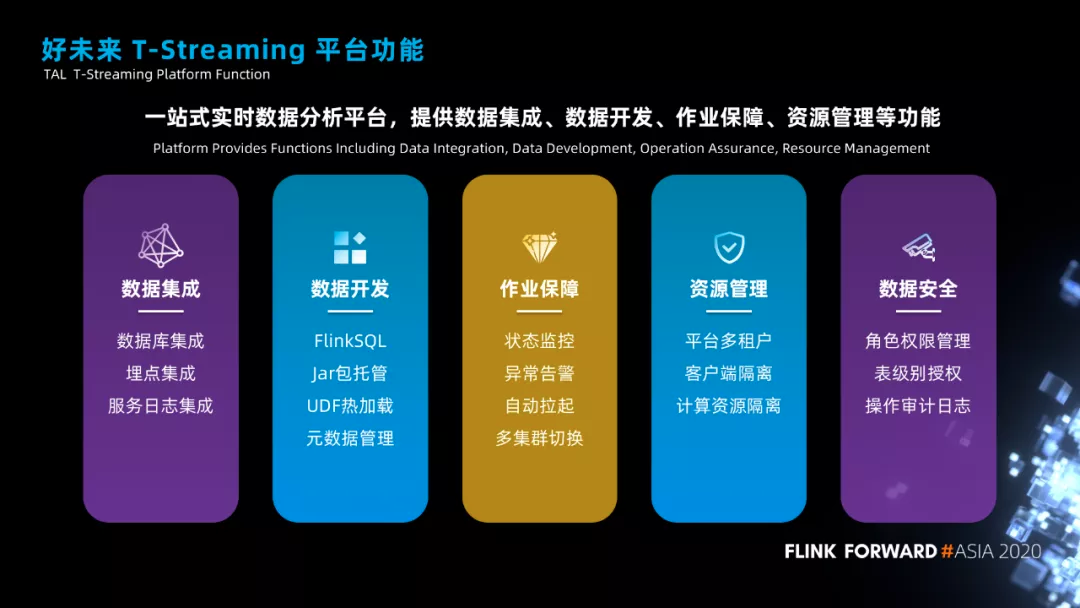
现在我们平台已经是一个一站式的实时数据分析平台,包括了数据集成、数据开发、作业保障、资源管理、数据安全等功能。
● 在数据集成方面,我们支持数据库、埋点数据、服务端日志数据的集成,为了能够提高数据集成的效率,我们提供了很多的通用模板作业,用户只需要配置即可快速实现数据的集成。
● 在数据开发方面,我们支持两种方式的作业开发,一种是 Flink SQL 作业开发、一种是 Flink Jar 包托管,在 Flink SQL 开发上我们内置了很多 UDF 函数,比如可以通过 UDF 函数实现维表 join,也支持用户自定义 UDF,并且实现了 UDF 的热加载。除此之外,我们也会记录用户在作业开发过程中的元数据信息,方便血缘系统的建设。
● 在作业保障方面,我们支持作业状态监控、异常告警、作业失败之后的自动拉起,作业自动拉起我们会自动选择可用的 checkpoint 版本进行拉起,同时也支持作业在多集群之间的切换。
● 在资源管理方面,我们支持平台多租户,每个租户使用 namespace 进行隔离、实现了不同事业部、不同用户、不同版本的 Flink 客户端隔离、实现了计算资源的隔离。
● 在数据安全方面,我们支持角色权限管理、表级别权限管理、操作审计日志查询等功能。
以上就是我们平台的功能,在赋能业务的同时,我们也还在快速迭代中,期望平台简单好用,稳定可信赖。
实时平台的批流融合
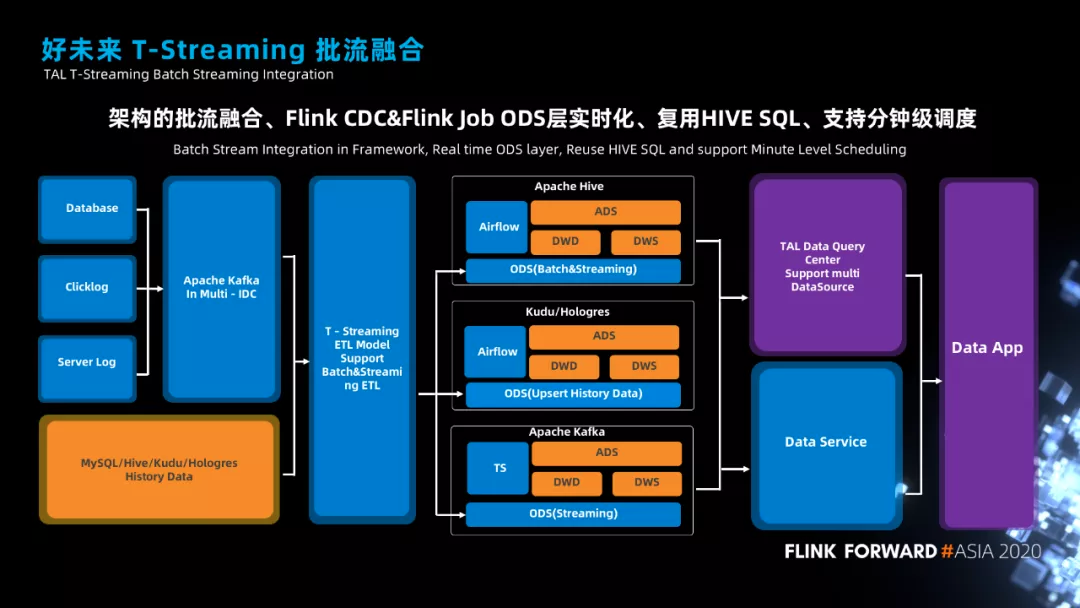
接下来说一下平台建设中的一些实践,第一个是批流融合。
我们先理清楚批流融合是什么?
批流融合可以分为两个概念,一个是 Flink 提出的批流融合,具体的理解就是一个 Flink SQL 既可以作用于流数据、也可以作用于批数据,通过保证计算引擎一致从而减少结果数据的差异,这是一个技术层面上的批流融合。另个一概念是我们内部提出来的,那就是架构层面的批流融合。具体的操作手法就是通过 Flink 作业保证数据仓库 ODS 层的实时化,然后提供小时级别、分钟级别的调度,从而提高数据分析的实时化。
为什么我们会提出架构上的批流融合,主要我们看到行业发展的两个趋势。
● 第一个趋势是数据集成的实时化和组件化,比如 Flink 集成 Hive、Flink CDC 的持续完善和增强,这样我们做数据集成的时候就会变得非常简单。
● 第二个趋势是实时 OLAP 引擎越来越成熟,比如 Kudu+impala、阿里云的 Hologres、湖仓一体的方案。
这两个趋势让用户开发实时数据会变得越来越简单,用户只需要关注 SQL 本身就可以。
如上图所示,我们有三个类型的实时数仓,一个是基于 Hive 的、一个是基于实时 OLAP 引擎的、一个是基于 Kafka 的。其中,蓝色线条就是我们 ODS 层实时化的具体实现。我们提供了一个统一的工具,可以将实时的将数据写入到 Hive、实时 OLAP 引擎、当然还有 Kafka。这个工具使用起来比较简单,如果是 MySQL 数据的同步,用户只需要输入数据库名称和表名就可以了。
通过 ODS 层实时化的工具,我们就可以在 Hive、实时 OLAP 引擎、Kafka 中构建实时数仓。
● 如果是 Hive 实时数仓,我们会使用 Flink 将实时的增量数据写入到 ODS 层,然后提供一个定时 merge 的脚本,用来 merge 增量数据和历史数据,从而保证 ODS 层的数据是最新最全的。配合 airflow 小时级别的调度能力,用户就可以得到一个小时级别的数仓了。
● 如果是类似于 Kudu / Hologres 这样的实时 OLAP 引擎,我们会先把离线数据从 Hive 中导入到实时 OLAP 引擎中,然后使用 Flink 将实时的增量数据写入到 ODS 层,写入的方式推荐使用 upsert 这样的特性,这样用户就能够得到一个纯实时的数仓了。配合 airflow 分钟级别的调度能力,用户就可以得到一个分钟级别的数仓了。
● 基于 Kafka 构建实时数仓,就是非常经典的架构了,开发成本也比较高一些,除了必须要秒级更新的分析场景,我们不太建议用户使用。当然在 2021 年的时候,我们也会去做 Flink 批流一体解决方案,让用户有更多选择方式的同时,让整个实时数仓变得更加简单。
以上就是我们对批流融合的思考和实践,通过这种架构层面的批流融合,原来需要开发一个月的实时需求,现在 2 天就差不多能完成。大大降低了开发实时数据的门槛,提高了数据分析的效率。
实时平台 ODS 层实时化
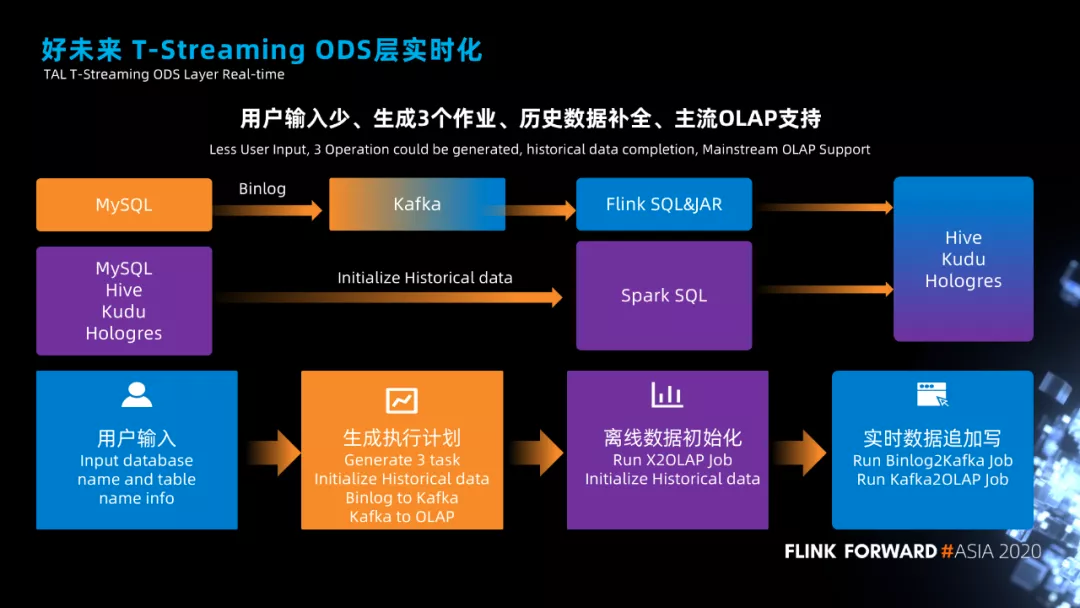
说一下 ODS 层实时化我们具体是怎么做的。
要想把 ODS 层数据实时化,我们需要解决两个问题,第一个是离线数据的初始化问题,第二个是增量数据如何写入的问题。离线数据导入比较好做,如果数据源是 MySQL,我们可以使用 DataX 或者 Spark 作业的方式将 MySQL 的全量数据导入到 Hive 中,而实时增量数据的写入我们需要有两个步骤,第一个步骤是将 MySQL 的 binlog 采集到 Kafka,第二个步骤是将 Kafka 的数据使用 Flink 作业导入到 Hive。这样算下来,要解决 ODS 层实时化的问题,我们就需要一个离线初始化的作业,一个增量数据采集的作业,一个增量数据写入的作业,也就是需要 3 个作业。
在我们的平台上,我们对 ODS 层的 3 个作业进行了封装和统一调度,用户只需要输入一个数据库名称和表的名称就能完成 ODS 层实时化的工作。
以上就是我们批流融合中 ODS 层实时化的实现过程。
实时平台 Flink SQL 开发流程
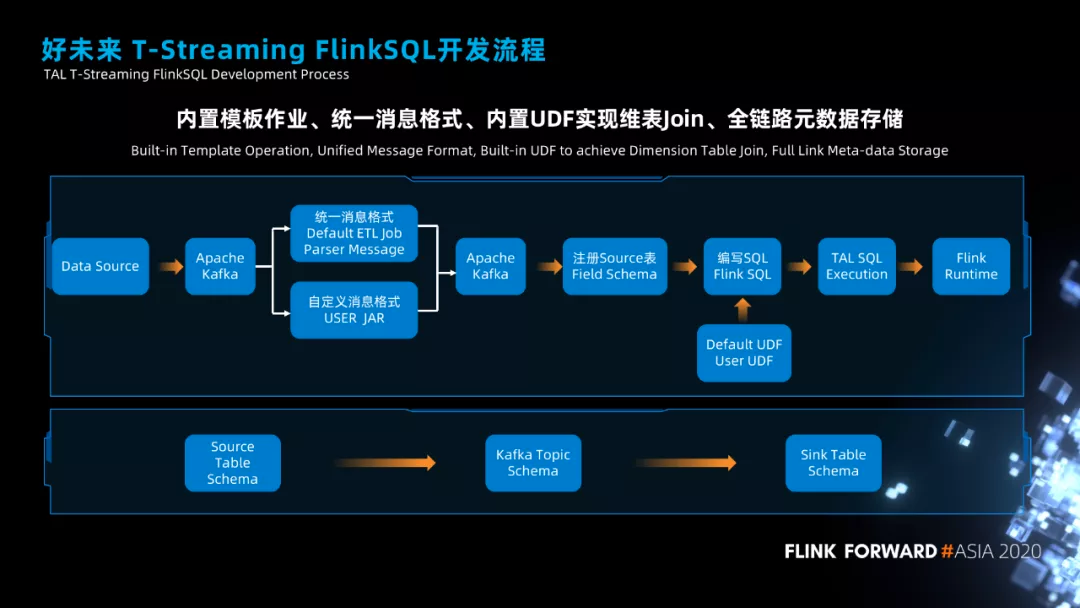
我们另外一个实践,就是对 Flink SQL 的作业封装。先看一下,在我们平台上进行 Flink SQL 开发的整体流程。
从左往右看,数据源中的数据会通过 Maxwell、canal 这样的工具采集到 Kafka,采集到 Kafka 的原始数据格式并不是统一的,所以我们需要将 Kafka 中的数据进行统一格式化处理,我们默认支持埋点数据格式、canal 数据格式、maxwell 数据的解析,也支持用户自己上传 Jar 包进行数据解析,解析得到的标准化数据就会再次发送到 Kafka。
然后我们会使用 Flink SQL 作业来消费 Kafka 的数据,进行 SQL 脚本的开发。这里的 SQL 脚本开发和原生的 Flink SQL 的脚本开发有一点不一样,原生的 SQL 脚本开发用户需要编写 Source 信息、Sink 信息,在我们平台上用户只需要写具体的 SQL 逻辑就可以了。
那用户写完 SQL 之后,会将 SQL 作业信息提交到我们封装好的 Flink SQL 执行作业上,最后通过我们封装的 SQL 引擎将作业提交的 Flink 集群上去运行。后面将介绍我们是怎么封装的。
以上就是在我们平台上进行 Flink SQL 开发的流程,出了 Flink 作业本身的开发和提交,平台也会保留与作业有关的各种输入、输出的 schema 信息。比如业务数据库表的 schema 信息,经过同意加工之后的 schema 信息,数据输出的表的 schema 信息,通过这些记录,后期我们排查问题的时候就能够快速梳理出作业的来龙去脉和影响范围。
实时平台 Flink SQL 开发过程
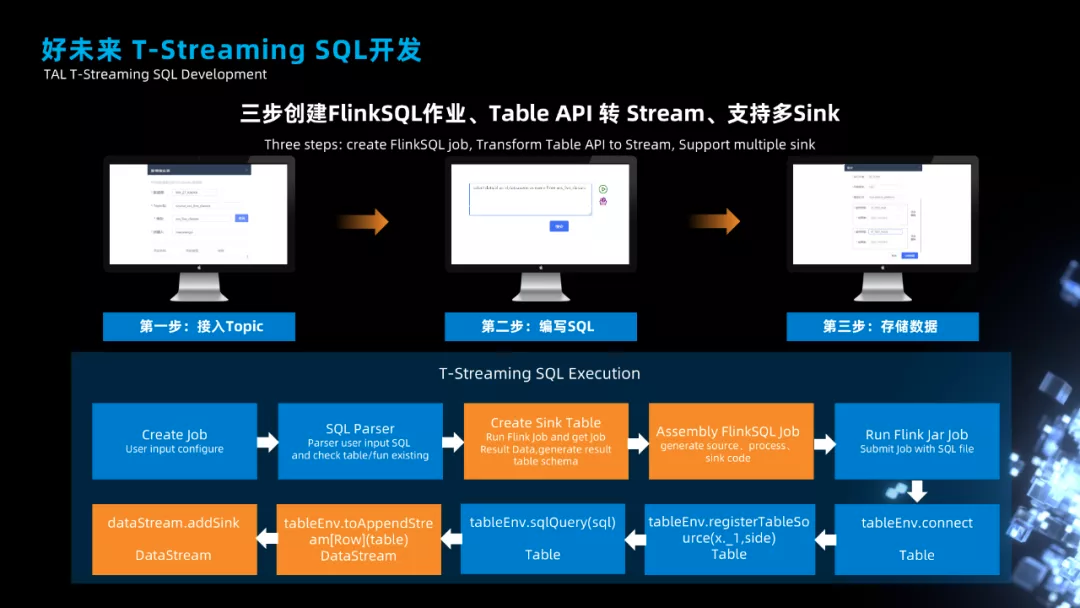
在我们平台上开发 Flink SQL 作业,只需要三个步骤:
● 第一个步骤确认 Kafka 的 Topic 是否已经注册过了,如果没有注册就需要用户手动注册下,完成注册后,我们会把 Topic 的数据解析出来,将字段信息保存起来。
● 第二步使用户编写 SQL,刚才说过,用户只需要写具体的 SQL 逻辑,不需要写 Source 和 Sink 信息。
● 第三步是用户指定将数据输出到哪里,现在平台可以支持同时指定多个 Sink 存储设备,比如将计算好的数据同时写入到 Hive、Holo 等存储。
通过以上三个步骤的配置,用户就可以提交作业了。
接下来说一下,我们是怎么做的,我把整个执行过程分为 2 个阶段 10 个步骤。
第一个阶段就是作业准备阶段,第二个阶段就是 SQL 执行阶段。
■ 作业准备阶段
● 第一步,用户在页面数据 SQL 和指定 Sink 信息。
● 第二步,SQL 解析及校验过程,当用户提交 SQL 时,我们会对 SQL 进行解析,看看 SQL 中用到的 Source 表和 UDF 是否在平台中注册过。
● 第三步,推测建表,我们会先运用下用户的 SQL,然后得到 SQL 的返回结果,根据结果数据生成一些建表语句,最后通过程序自动到目标 Sink 存储上去建表。
● 第四步,拼装 Flink SQL 的脚本文件,得到一个有 Source、SQL、Sink 三要素的脚本文件。
● 第五步,作业提交,这里会把 Flink SQL 文件提交到我们自己执行引擎中。
■ SQL 执行阶段
● 第一步是会初始化 StreamTableAPI,然后使用 connect 方法注册 Kafka Source,Kafka 的 Source 信息需要指定数据解析的规则和字段的 schema 信息,我们会根据元数据自动生成。
● 第二步是使用 StreamTableAPI 注册 SQL 中使用到的维表和 UDF 函数,UDF 函数包括用户自己上传的 UDF 函数。
● 第三步是使用 StreamTable API 执行 SQL 语句,如果有视图也可以执行视图。
● 第四步是一个比较关键的步骤,我们会把 StreamTabAPI 转成 DataStream API。
● 第五步就是在 DataStream 的基础上 addSink 信息了。
以上是两个阶段的执行过程,通过第二个阶段,用户的 SQL 作业就会真正的运行起来。
实时平台原生作业与模板任务
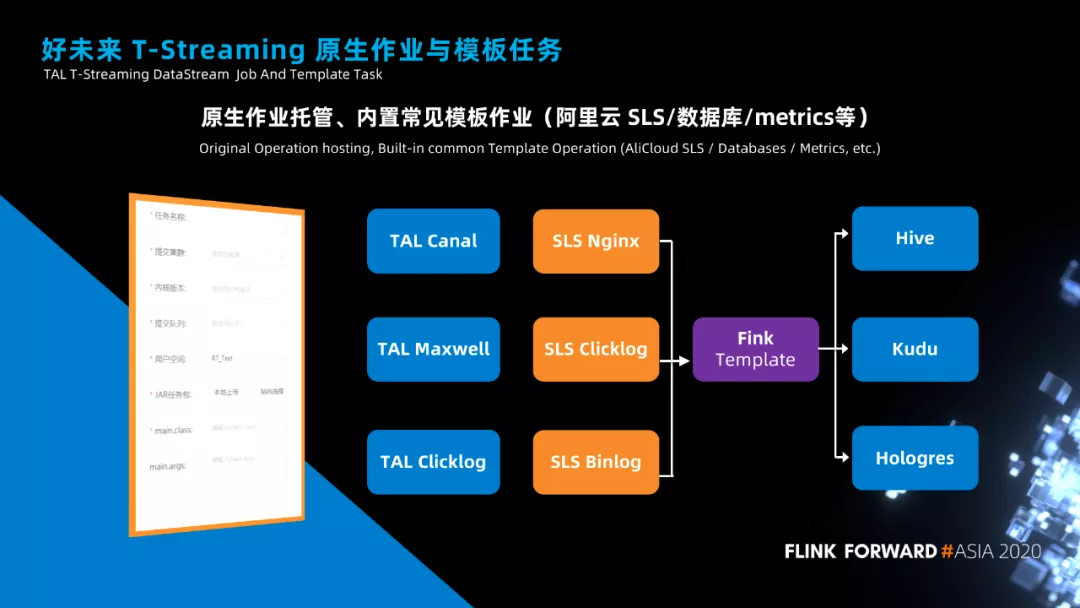
上面分享了我们的 Flink SQL 作业如何开发和运行,接下来说一下我们平台对 JAR 包类型作业的支持。
在我们平台上,我们支持用户自己上传 JAR 包作业,然后在我们平台上进行管理。与此同时,为了提高代码通常场景的复用性,我们开发了很多模板作业,比如支持 Maxwell 采集的 binlog 直接写入到 Hive、Kudu、Holo 等存储设备,支持阿里云 SLS 日志写入到各种 OLAP 引擎。
实时平台混合云部署方案
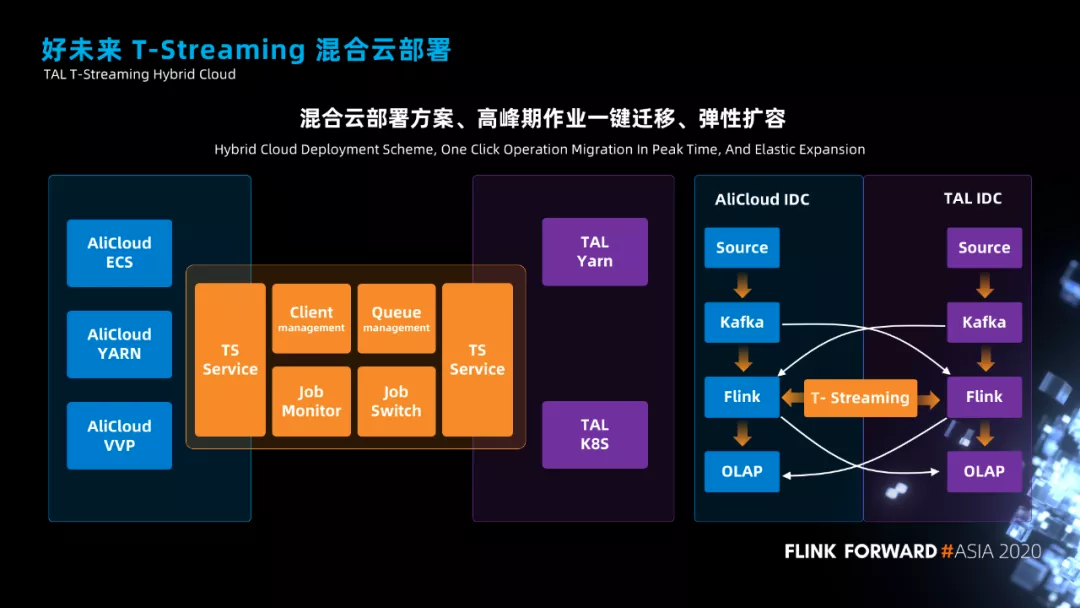
讲一下混合云部署方案和平台技术架构。
我们平台现在支持将作业提交到阿里云机房、自建机房中,并且作业可以在两个机房中来回切换。为了要有这个功能呢?
今年年初,随着疫情的爆发,互联网在线教育涌入了大量的流量,为了应对暴增的流量,春节期间我们采购了上千台机器进行紧急的部署和上线,后来疫情稳定住了之后,这些机器的利用率就比较低了,为了解决这个问题,我们平台就支持了混合云部署方案,高峰期的时候作业可以迁移到阿里云上运行,平常就在自己的集群上运行,既节约了资源又保证了弹性扩容。
实时平台技术架构
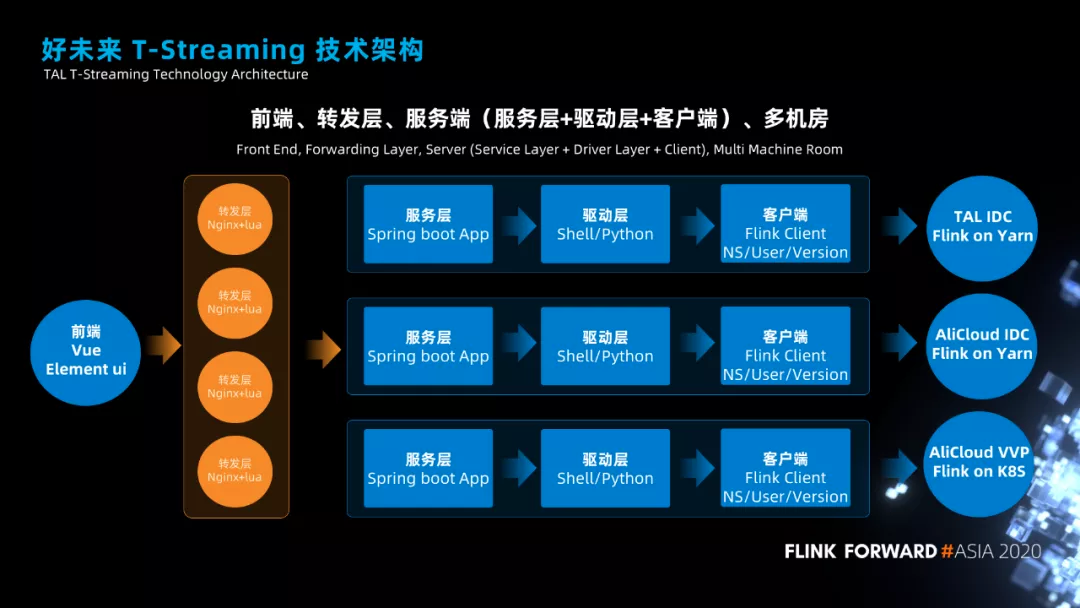
接下来说一下平台的技术架构。
我们是一个前后端分离的项目,前端使用 vue+elmentui、服务端使用 springboot,不同的机房里面我们会部署一个后端服务的实例。任务提交到不同的机房主要通过转发层的 nginx+lua 来实现的。平台上任务的提交、暂停、下线操作,都是通过驱动层来完成的,驱动层主要是一些 shell 脚本。最后就是客户端了,在客户端上我们做了 Namespace/用户/Flink 版本的隔离。
3.K12 教育典型分析场景
续报业务介绍
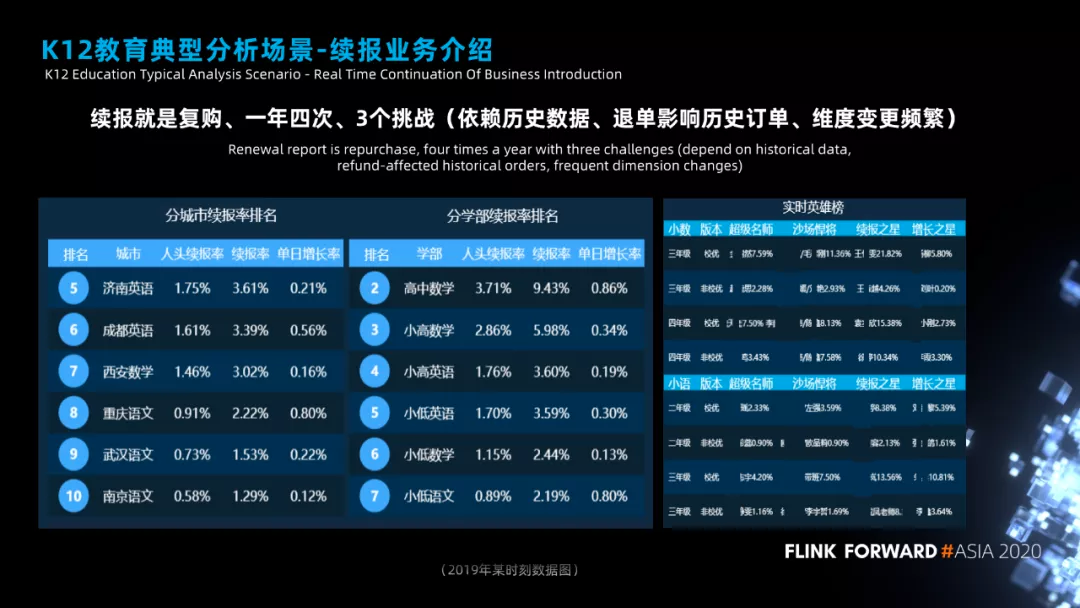
我们聊一个具体的案例,案例是 K12 教育行业中典型的分析场景,用户续报业务。
先说下什么是续报,续报就是重复购买,用户购买了一年的课程,我们期望用户购买二年的课程。为了用户购买课程,我们会有一个集中的时间段用来做续报,每次持续一周左右,一年四次。
因为续报周期比较集中,时间比较短暂,每次做续报业务老师对实时续报数据的需求就特别迫切。
为此我们做了一个通用的续报解决方案,来支持各事业部的续报动作。要做实时续报,有几个挑战。
● 第一个挑战是计算一个用户的订单是否是续报,需要依赖这个用户历史上所有的订单,也就是需要历史数据参与计算。
● 第二个挑战就是一个订单的变化会影响其它订单的变化,是一个连锁效应。比如用户有 5 个订单,编号为 345 的订单都是续报状态,如果用户取消了编号为 3 的订单,订单 4 和订单 5 的续报状态就需要重新计算。
● 第三个挑战是维度变化很频繁,比如用户上午的分校状态是北京,下午的分校状态可能就是上海,上午的辅导老师是张三,下午的辅导老师就是李四,频繁变化的维度给实时汇总数据带来了挑战。
依赖历史数据、订单改变的连锁效应、频繁变化的维度,这些挑战如果单个看都不算什么,如果放在一起就会变得比较有意思了。
实时续报解决方案
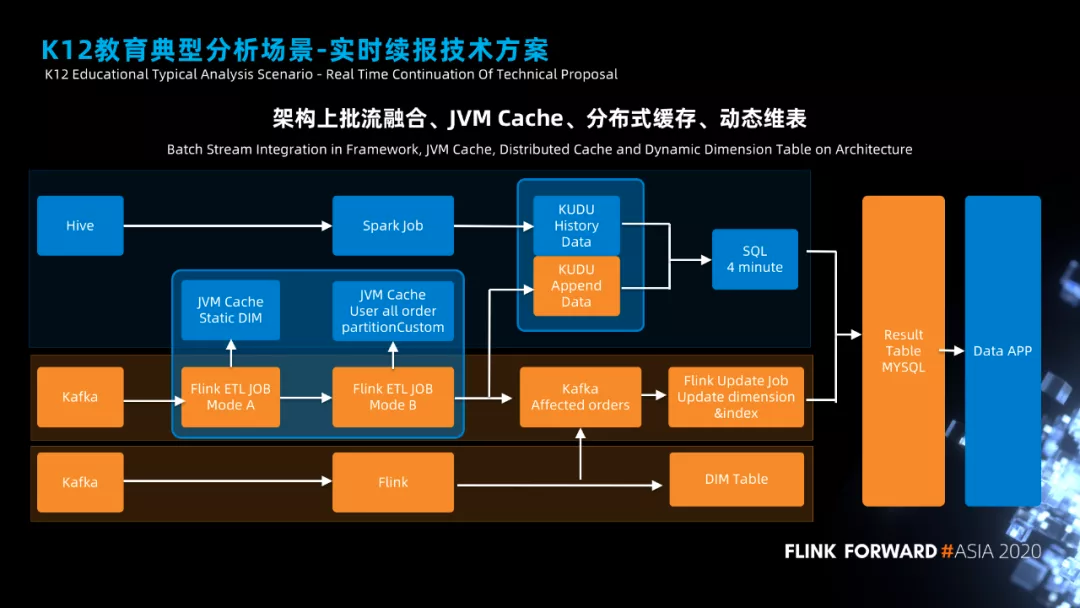
先说下整体架构,我们采用的批流融合方式来做的,分成两条线,一条线是分钟级实时续报数据计算,一条是秒级实时续报数据计算。计算好的数据放在 MYSQL 中,用来做大屏和 BI 看板。
先看下蓝色的这条线,我们会把 Hive 中的离线数据导入到 Kudu 中,离线数据都是计算好的订单宽表。然后会使用 Flink 作业把新增的订单做成宽表写入到 Kudu 中,这样 Kudu 里面就会有最新最全的数据。配合 4 分钟的调度,我们就提供了分钟级的实时续报数据。
在看第一条橙色的线条,这条线上有两个 Flink 作业,一个是 ETL Job,一个是 Update Job。
ETL job 会负责静态维度的拼接与续报状态的计算,静态维度拼接我们是直接访问 MySQL,然后缓存在 JVM 中。续报状态的计算需要依赖历史数据,ETL Job 会将所有的订单数据加载到 JVM 中,具体的实现方法是我们自定义了一个 partitioncustom 方法,对所有的历史数据进行了分片,下游的每个 Task 缓存一个分片的数据。通过将数据加载到内存中,我们大大的加快了 Flink 实时计算的速度。
ETL Job 的计算的数据,会有两个输出,一个是输出到 Kudu,用来保证 Kudu 中的数据最新最全,两个一个数据是 Kafka,Kafka 中有一个 Topic 记录的是是当前订单的变化导致了哪些订单或者维度变化的信息。
接在 Kafka 后面的程序就是 Update Job,专门用来处理受影响的订单或者维度,直接去修改 MySQL 中相关的统计数据。
这样我们就通过 2 个 Flink 作业实现的实时续报的计算。
最下面的一条线是实时维度的数据变更的处理,维度变更的数据会发送到 Kafka 中,然后使用 Flink 进行处理,看看维度的变化影响了哪些数据的统计,最后将受影响的订单发送到受影响的 Topic 中,由 Update Job 来重新计算。
以上就是我们实时续报的整体解决方案,如果有教育行业的朋友听到这个分享,或许可以参考下。
实时续报稳定性保障

我们看看这个通用的解决方案上线之后有哪些保障。
● 第一个保障是异地双活,我们在阿里云和自建机房都部署了一套续报程序,如果其中一套有异常,我们切换前端接口就可以了。如果两个机房的程序都挂了,我们重零开始启动程序,也只需要 10 分钟。
● 第二个保障是作业容错,我们有两个 Flink 作业,这两个作业随停随启,不影响数据的准确性。另外一点就是我们缓存了所有订单数据在 JVM 中,如果数据量暴涨,我们只需要改变 ETL 程序的并行度就可以,不用担心 JVM 内存溢出。
● 第三个保障是作业监控,我们支持作业的异常告警和失败后的自动拉起,也支持消费数据延迟告警。
通过以上保障措施,实时续报程序经过了几次续报周期,都比较平稳,让人很省心。
4.展望与规划
上述内容详细介绍了好未来当前业务及技术方案,总结而言我们通过多租户实现各事业部资源隔离、通过批流融合的架构方案解决分析实时化、通过 ODS 层实时化解决数据源到 OLAP 的数据集成问题、通过 Flink SQL 封装降低实时数据开发门槛、通过模板任务提供通用场景解决方案、通过混合云部署方案解决资源的弹性扩容、通过实时续报解决方案覆盖相同场景的数据分析。

最后,来看一下我们展望和规划。接下来我们要继续深化批流融合,强化混合云部署,提高数据分析的时效性和稳定性。支持算法平台的实时化,数据应用的实时化,提高数据决策的时效性。
版权声明: 本文为 InfoQ 作者【Apache Flink】的原创文章。
原文链接:【http://xie.infoq.cn/article/89400262d82063c72084529a7】。文章转载请联系作者。

Apache Flink 中文社区 2020.04.29 加入
公众号:Flink中文社区 Apache Flink 官方帐号,Flink PMC 维护









{kind=link}
评论