图解 Janusgraph 系列 - 图数据底层序列化源码分析(Data Serialize)

大家好,我是洋仔,JanusGraph图解系列文章,实时更新~
图数据库文章总目录:
整理所有图相关文章,请移步(超链):图数据库系列-文章总目录
**
源码分析相关可查看github(码文不易,求个star~)**: https://github.com/YYDreamer/janusgraph
下述流程高清大图地址:https://www.processon.com/view/link/5f471b2e7d9c086b9903b629
版本:JanusGraph-0.5.2
转载文章请保留以下声明:
作者:洋仔聊编程
微信公众号:匠心Java
原文地址:https://www.infoq.cn/u/yybiancheng/publish
正文
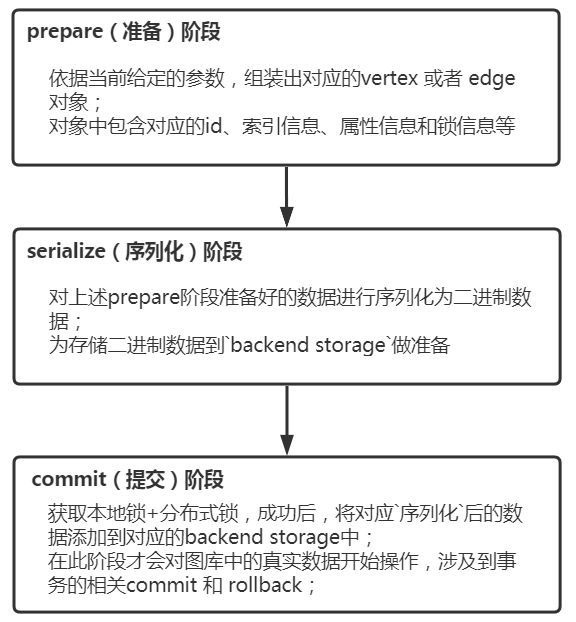
JanusGraph的数据导入过程主要分为三阶段:prepare(准备)、serialize(序列化)、commit(提交);不同阶段有不同的作用,如下:
下面我们分别从导入vertex节点和edge边两部分来分析写流程
建议依据源码同步看本文章,便于理解!
一:vertex数据写流程
下面vertex节点数据的导入,
prepare阶段
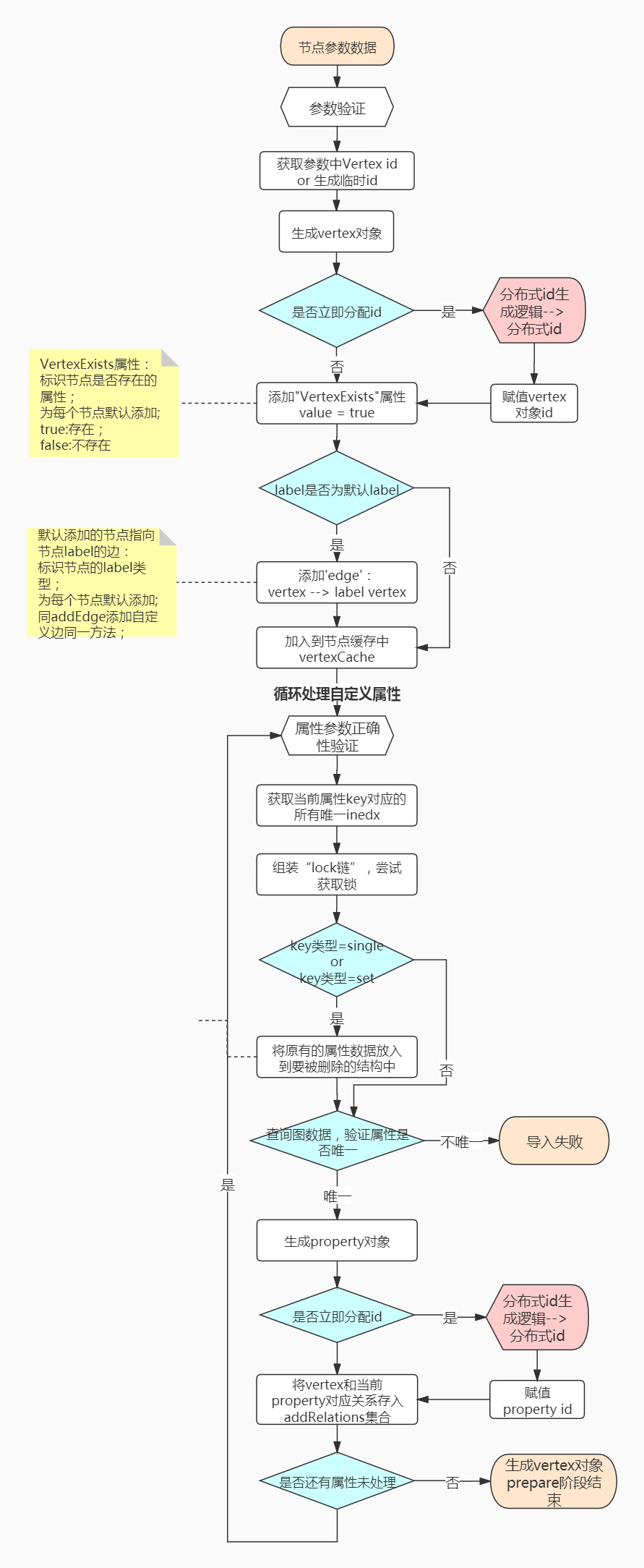
主要是依据当前给定的参数,组装出对应的vertex 或者 edge 对象;对象中包含对应的id、索引信息、属性信息和锁信息等;
过程中包含以下几种作用:
默认添加
vertex exist属性,值为true,标识当前节点是否存在默认添加
label edge边,标识当前的节点 或者 边是什么label生成
vertex、edge、property的全局分布式唯一id自定义属性验证是否满足唯一性约束
主要流程如下图(建议依照源码一块查看,上述github地址已给出):
serialize阶段
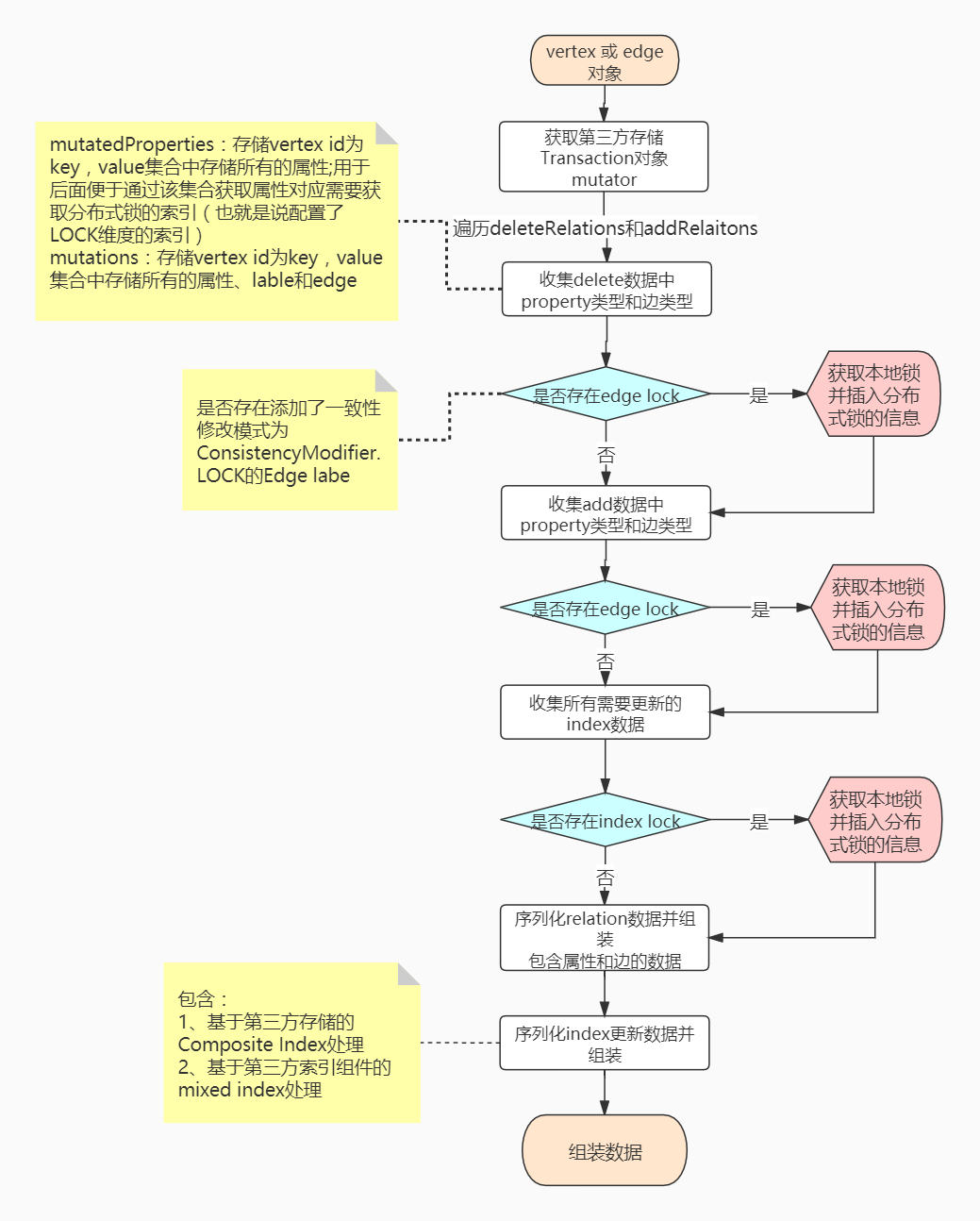
主要是对上述prepare阶段准备好的数据进行序列化为二进制数据,为存储二进制数据到backend storage做准备; 另外获取本地锁 + 分布式锁数据插入(此处只是将数据插入到Hbase,插入成功并不代表获取成功)
过程中包含以下几种作用:
序列化所有
relation数据并存储,包含属性、label edge、normal edge获取属性对应
index需要更新的数据,并序列化存储; 包含组合索引和mixed index的处理获取基于图实例的本地锁
获取了本地锁的前提前,获取
edge lock和index lock分布式锁(此处的获取锁只是将对应的KLV存储到Hbase中!存储成功并不代表获取锁成功,在commit阶段才会去检查是不是获取分布式锁成功!)
主要流程如下图:
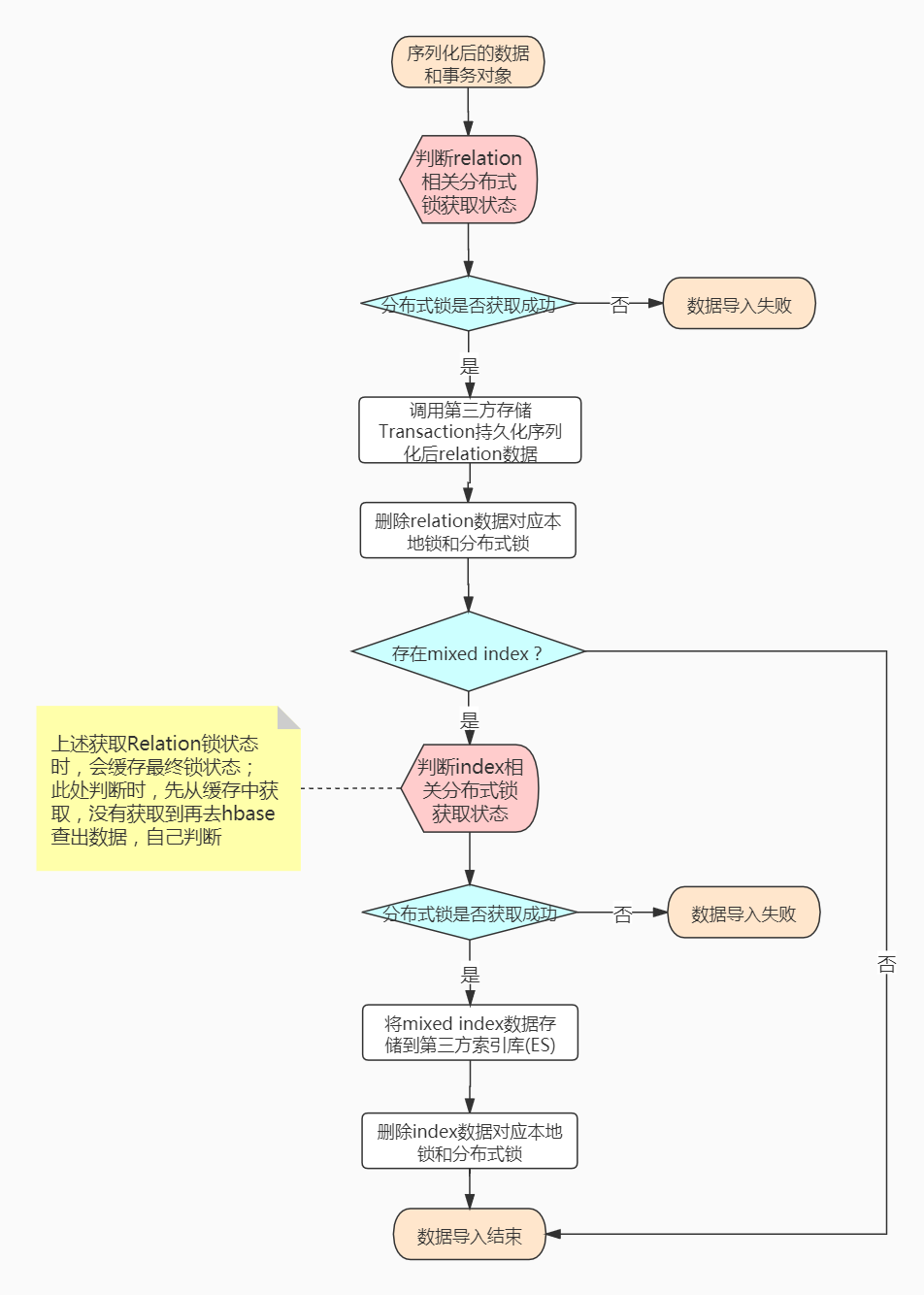
commit阶段
主要是获取本地锁+分布式锁成功后,将对应序列化后的数据添加到对应的backend storage中;完成图数据插入过程! 在此阶段才会对图库中的真实数据开始影响,才会涉及到事务的回滚机制;
过程中包含以下几种作用:
判断分布式锁的状态,获取成功则进行数据持久化;不成功则失败
持久化
relation数据持久化
index数据,包含组合索引存储到第三方存储;mixed index存储到第三方索引库中删除对应的本地锁 和 分布式锁的占用
主要流程如下图:
二:edge数据写流程
针对于edge的写数据流程,整体的流程和vertex节点的数据写入相同,有几点不同,下面一一列出:
1、生成分布式唯一id的过程
导入Edge数据在生成edge的唯一id时,partition id的获取不再是随机获取,而是尝试获取边对应的out vertex的partition id; id的组成部分也不同,没有idPadding部分;
具体解释请看:《JanusGraph-分布式id生成策略》文章
**2、在edge的导入中,没有同vertex数据导入,添加默认的节点是否存在属性和节点和节点对应label的边**
**3、获取edge对应的属性的index update时不同**
在导入vertex数据时,将节点对应的属性作为relation存放在addRelation中,然后收集所有的属性relation循环获取index uodate;如下伪代码:
而在edge数据导入中,只将edge这条边作为relation插入到addRelation中,所以无法获取属性relation,转而通过收集过程中,对每个edge对应的所有属性进行分别获取;如下伪代码:
**4、edge对应的relation数据,也就是当前插入的这个边,需要被序列化两次**
一次是源节点+边关系,一次是目标节点+边关系(因为jansugraph是通过edge cut方式存储图数据的)
**5、edge的数据插入过程中,edge的序列化组成部分不同于vertex的序列化组成部分;**
不同点请看《Janusgraph-存储结构》文章
**6、edge的数据插入中,edge的property和vertex的property组成不同!**
edge中针对于sort key和signature key配置的属性,只将property value存储在对应位置。其他未被配置的属性值包含proeprty key label id + property value;
不同于vertex数据中的属性组成包含:proeprty key label id + property 唯一id +property value
三:源码分析
源码分析已经push到github:https://github.com/YYDreamer/janusgraph
数据写入的流程源码过多,就不在文章中给出分析了,具体请看github中源码分析注释吧
四:应用
基于数据序列化导入的源码博主将图数据的序列化逻辑抽取出来,生成一个工具包;
主要用于图数据的迁移和图数据库的初始化,适用于大数据量的导入,主要流程如下:
生成schema到图中
获取schema信息,缓存到内存中
调用api占用对应的id blocker,用于离线数据的分布式唯一id生成
调用抽取的序列化逻辑序列化节点和边数据
生成Hfile
将hfile导入到Hbase中
上述流程已经经过严格的验证并在生产环境中使用,具体之后会再出一篇文章介绍一下详细的设计与流程
五:总结
对于JanusGraph图数据的写入,主要分为3部分:
schema的创建
vertex节点数据的导入
edge边数据的导入
上述主要分析了vertex和edge的数据导入,大致流程相似;也分析了两部分导入数据的差异;
其中涉及的分布式唯一id的生成逻辑 和 锁机制获取的逻辑,请看《图解Janusgraph系列-Lock锁机制(本地锁+分布式锁)分析》和《图解Janusgraph系列-分布式id生成策略分析》两篇文章!
针对于第三方索引的序列化存储逻辑,逻辑相对简单,此处没有给出,具体读者可以自主分析一下源码
码字不易,求个赞和star~
版权声明: 本文为 InfoQ 作者【洋仔聊编程】的原创文章。
原文链接:【http://xie.infoq.cn/article/7dbd700917b9022bdec40d28c】。
本文遵守【CC-BY 4.0】协议,转载请保留原文出处及本版权声明。

知识是永远的流行色! 2019.07.02 加入
博主分享工作中涉及到的技术知识,包含Java技术干货(JVM+并发+全链路优化)、计算机网络、数据结构、linux等知识,公众号【匠心Java】作者









评论