使用 Apache Spark 管理、部署和扩展机器学习管道 (十一)

写在前面:
大家好,我是强哥,一个热爱分享的技术狂。目前已有 12 年大数据与 AI 相关项目经验, 10 年推荐系统研究及实践经验。平时喜欢读书、暴走和写作。
业余时间专注于输出大数据、AI 等相关文章,目前已经输出了 40 万字的推荐系统系列精品文章,今年 6 月底会出版「构建企业级推荐系统:算法、工程实现与案例分析」一书。如果这些文章能够帮助你快速入门,实现职场升职加薪,我将不胜欢喜。
想要获得更多免费学习资料或内推信息,一定要看到文章最后喔。
内推信息
如果你正在看相关的招聘信息,请加我微信:liuq4360,我这里有很多内推资源等着你,欢迎投递简历。
免费学习资料
如果你想获得更多免费的学习资料,请关注同名公众号【数据与智能】,输入“资料”即可!
学习交流群
如果你想找到组织,和大家一起学习成长,交流经验,也可以加入我们的学习成长群。群里有老司机带你飞,另有小哥哥、小姐姐等你来勾搭!加小姐姐微信:epsila,她会带你入群。
在上一章中,我们介绍了如何使用 MLlib 构建机器学习管道。本章将重点介绍如何管理和部署你训练的模型。在本章结束时,你将能够使用 MLflow 来追踪、重现和部署 MLlib 模型,以及讨论各种模型部署方案之间的困难和折衷方案,并设计可扩展的机器学习解决方案。但是,在讨论部署模型之前,让我们首先讨论一些模型管理的最佳实践,在进行部署之前将你的模型准备好。
模型管理
在部署机器学习模型之前,应确保可以复制和追踪模型的效果。对我们而言,机器学习解决方案的端到端可重现性意味着我们需要能够再现生成模型的代码,包括用于训练的环境,用于训练的数据以及模型本身。每个数据科学家都喜欢提醒你设置随机数种子,以便你可以重现实验(例如,在使用具有固有随机性的模型(例如随机森林)时进行训练集/测试集拆分)。但是,有许多方面比设置种子更有助于提高可重复性,其中有些方面很微妙。下面有几个例子:
库版本控制
当数据科学家将他们的代码交给你时,他们可能会或者可能不会提及依赖库。虽然你可以通过查看错误消息从而确定需要哪些库,但是不确定它们使用的是哪个库版本,因此你可能会安装最新的库。这样一来,如果他们的代码是建立在库的先前版本上的,则会存在不同版本之间的某些默认行为是不一致的,从而导致不同的结果,因此使用最新版本可能会导致代码中断或结果有所不同(例如,考虑一下 XGBoost 如何更改了 v0.90 版本中处理缺失值的方式)。
数据演进
假设你在 2020 年 6 月 1 日建立模型,并追踪所有超参数、库等。然后你尝试在 2020 年 7 月 1 日重现相同的模型,但是由于基础数据发送变更,所以引起管道中断或结果不同,如果有人在初始构建后添加了额外的列或更多数量级的数据,则可能会发生这种情况。
执行顺序
如果数据科学家将他们的代码交给你,那么你应该能够从上到下运行它而不会出错。但是,数据科学家以无序运行或多次运行同一个有状态单元而臭名昭著,这使得它们的结果很难重现。(他们还可能引入具有与用于训练最终模型的参数不同的超参数的代码副本!)
并行作业
为了最大化吞吐量,GPU 将并行运行许多操作。但是,执行顺序不一定总是得到保证,这可能导致结果的不确定性。这是类似 tf.reduce_sum()函数之类的已知问题,例如在对浮点数进行聚合(精度有限)时:添加它们的顺序可能会产生略有不同的结果,并且在许多迭代中都会加剧这种结果。
无法复制实验通常会阻碍业务部门采用你的模型或将其投入生产。尽管你可以构建自己的内部工具来追踪模型、数据和依赖项版本等,但是它们可能变得过时,脆弱并且需要花费大量的开发工作来维护。同样重要的是要拥有用于管理模型的行业范围的标准,以便可以与合作伙伴轻松共享它们。开源和专有工具都可以通过抽象出许多常见困难来帮助我们重现我们的机器学习实验。本节将重点介绍 MLflow,因为它与当前可用的开源模型管理工具 MLlib 的集成最为紧密。
MLflow
MLflow 是一个开放源代码平台,可帮助开发人员复制和共享实验,管理模型等。它提供 Python,R 和 Java / Scala 的接口,以及 REST API。如图 11-1 所示,MLflow 具有四个主要组件:
Tracking
提供 API 来记录参数,指标,代码版本,模型和其他人工素材(例如图形和文本)。
Projects
打包数据科学项目及其依赖性是一种标准化操作,以便在其他平台上运行。它可以帮助你管理模型训练过程。
Models
通过标准化的方式打包模型以部署到不同的执行环境。它提供了用于加载和应用模型的一致 API,无论用于构建模型的算法或库是什么。
Registry
用于追踪模型演进,模型版本,阶段转换和注释的存储库。
让我们尝试在第 10 章中为重现性而进行的 MLlib 模型实验。然后,当我们讨论模型部署时,我们将看到 MLflow 的其他组件如何发挥作用。要开始使用 MLflow,只需在本地主机上运行 pip install mlflow 即可。
Tracking
MLflow Tracking 是一个日志记录 API,与实际进行训练的库和环境无关。它围绕运行(runs)的概念进行组织,而运行是数据科学代码的执行。将运行汇总到实验中,以便许多运行可以成为给定实验的一部分。
MLflow 追踪服务器可以托管许多实验。你可以使用笔记本(notebooks),本地应用程序或云作业登录到追踪服务器,如图 11-2 所示。
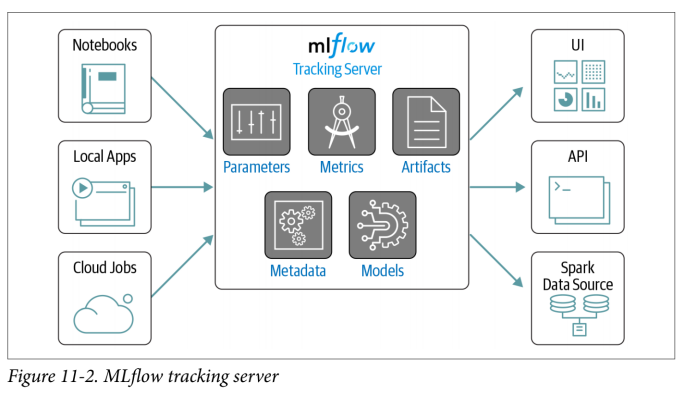
让我们检查一些可以记录到追踪服务器的内容:
参数
你代码的键/值输入,例如,随机森林中的超参数 num_trees 或 max_depth
指标
数值(可以随时间更新),例如,RMSE 或精度值
Artifacts
文件,数据和模型,例如 matplotlib 图像或 Parquet 文件
元数据
有关运行的信息,例如执行运行的源代码或代码的版本(例如,代码版本的 Git 提交哈希字符串)
模型
你训练的模型
默认情况下,追踪服务器会将所有内容记录到文件系统中,但是你可以指定数据库以加快查询速度,例如参数和指标。让我们将 MLflow 追踪添加到第 10 章的随机森林代码中:
In Python
from pyspark.ml import Pipeline
from pyspark.ml.feature import StringIndexer, VectorAssembler
from pyspark.ml.regression import RandomForestRegressor
from pyspark.ml.evaluation import RegressionEvaluator
filePath = """/databricks-datasets/learning-spark-v2/sf-airbnb/
sf-airbnb-clean.parquet"""
airbnbDF = spark.read.parquet(filePath)
(trainDF, testDF) = airbnbDF.randomSplit([.8, .2], seed=42)
categoricalCols = [field for (field, dataType) in trainDF.dtypes
if dataType == "string"]
indexOutputCols = [x + "Index" for x in categoricalCols]
stringIndexer = StringIndexer(inputCols=categoricalCols,
outputCols=indexOutputCols,
handleInvalid="skip")
numericCols = [field for (field, dataType) in trainDF.dtypes
if ((dataType == "double") & (field != "price"))]
assemblerInputs = indexOutputCols + numericCols
vecAssembler = VectorAssembler(inputCols=assemblerInputs,
outputCol="features")
rf = RandomForestRegressor(labelCol="price", maxBins=40, maxDepth=5,
numTrees=100, seed=42)
pipeline = Pipeline(stages=[stringIndexer, vecAssembler, rf])
要开始使用 MLflow 进行记录,你将需要使用开始运行 mlflow.start_run(),而不是显示调用 mlflow.end_run()。本章中的示例将使用一个 with 子句来自动结束运行:
In Python
import mlflow
import mlflow.spark
import pandas as pd
with mlflow.start_run(run_name="random-forest") as run:
Log params: num_trees and max_depth
mlflow.log_param("num_trees", rf.getNumTrees())
mlflow.log_param("max_depth", rf.getMaxDepth())
Log model
pipelineModel = pipeline.fit(trainDF)
mlflow.spark.log_model(pipelineModel, "model")
Log metrics: RMSE and R2
predDF = pipelineModel.transform(testDF)
regressionEvaluator = RegressionEvaluator(predictionCol="prediction",
labelCol="price")
rmse = regressionEvaluator.setMetricName("rmse").evaluate(predDF)
r2 = regressionEvaluator.setMetricName("r2").evaluate(predDF)
mlflow.log_metrics({"rmse": rmse, "r2": r2})
Log artifact: feature importance scores
rfModel = pipelineModel.stages[-1]
pandasDF = (pd.DataFrame(list(zip(vecAssembler.getInputCols(),
rfModel.featureImportances)),
columns=["feature", "importance"])
.sort_values(by="importance", ascending=False))
First write to local filesystem, then tell MLflow where to find that file
pandasDF.to_csv("feature-importance.csv", index=False)
mlflow.log_artifact("feature-importance.csv")
让我们检查一下 MLflow UI,你可以通过在终端中运行 mlflow ui 并导航到 http://localhost:5000/来访问它。图 11-3 显示了 UI 的屏幕截图。
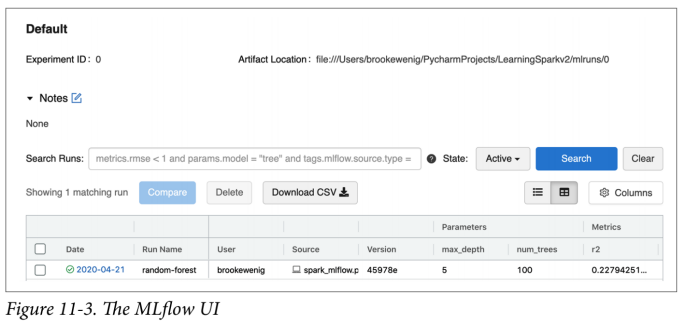
UI 会存储给定实验的所有运行任务。你可以搜索所有运行任务,筛选满足特定条件的运行任务信息,并排比较运行等。如果需要,还可以将内容导出为 CSV 文件以在本地进行分析。在用户界面中点击运行任务"random-forest"。你应该看到如图 11-4 所示的面板。
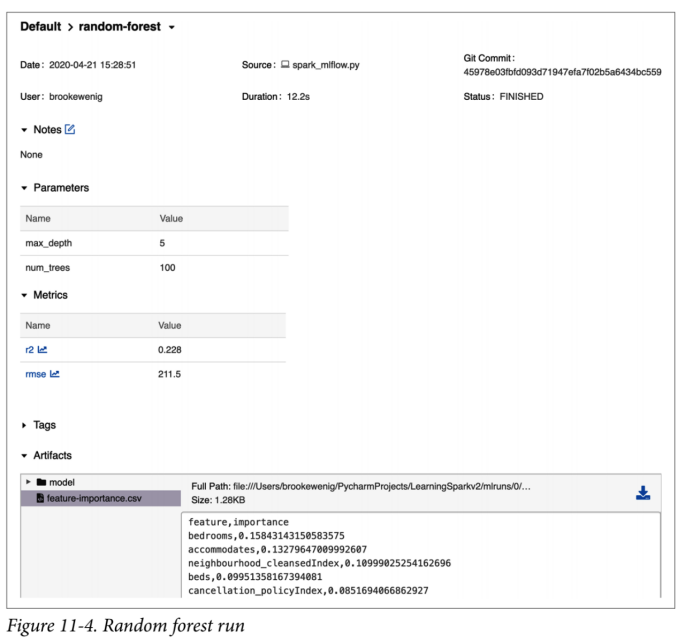
你会注意到,它追踪用于此 MLflow 运行的源代码,并存储所有相应的参数,指标等。你可以自由地在文本和标签中添加有关此运行的注释。运行完成后,你将无法修改参数或指标。
你还可以使用 MlflowClient 或 REST API 查询追踪服务器:
In Python
from mlflow.tracking import MlflowClient
client = MlflowClient()
runs = client.search_runs(run.info.experiment_id,
order_by=["attributes.start_time desc"],
max_results=1)
run_id = runs[0].info.run_id
runs[0].data.metrics
这将产生以下输出:
{'r2':0.22794251914574226,'rmse':211.5096898777315}
我们将本书这部分的代码作为 MLflow 项目托管在 GitHub 仓库中,所以你可以尝试用不同的超参数值如 max_depth 和 num_trees 来运行它。MLflow 项目中的 YAML 文件指定了库依赖关系,因此该代码可以在其他环境中运行:
In Python
mlflow.run(
"https://github.com/databricks/LearningSparkV2/#mlflow-project-example",
parameters={"max_depth": 5, "num_trees": 100})
Or on the command line
mlflow run https://github.com/databricks/LearningSparkV2/#mlflow-project-example
-P max_depth=5 -P num_trees=100
现在,你已经追踪并复制了实验,让我们讨论 MLlib 模型可用的各种部署选项。
MLlib 的模型部署选项
部署机器学习模型对于每个组织和应用场景而言意味着不同的东西。业务约束将对延迟,吞吐量,成本等权衡指标提出不同的要求,这些要求决定了哪种模型部署模式适合手头的任务——无论是批处理,流计算,实时还是移动/嵌入式任务。在移动/嵌入式系统上部署模型超出了本书的范围,因此我们将主要关注其他方面。表 11-1 显示了这三种用于生成预测的部署选项的吞吐量和延迟权衡。我们同时关心并发请求的数量和这些请求的大小,并且最终的解决方案看起来会大不相同。

批处理会定期生成预测,并将结果写到持久性存储中,以供其他地方使用。它通常是最便宜和最简单的部署选项,因为你只需要在计划的运行期间为计算付费。批处理在每个数据点上的效率更高,因为在所有预测中进行摊销时,你可以累积较少的开销。对于 Spark 尤其如此,因为在驱动程序和执行程序之间来回通信会产生开销,因此你不想一次做出一个数据点的预测!但是,它的主要缺点是延迟高,因为通常将其设定为数小时或数天以生成下一批预测。
流提供了吞吐量和延迟之间的良好折衷。你将不断对数据的微批次进行预测,并在数秒至数分钟内获得你的预测。如果你使用的是结构化流,则几乎所有代码都将与批处理用例相同,从而可以轻松地在这两个选项之间来回切换。使用流传输时,你将需要为用来持续保持运行状态的 VM 或计算资源付费,并确保已正确配置流以使其具有容错能力,并在传入数据中出现峰值时提供缓冲。
实时部署优先考虑延迟而不是吞吐量,并在几毫秒内生成预测。你的基础架构将需要支持负载平衡,并且在需求激增的情况下(例如,假期期间的在线零售商)能够扩展到许多并发请求。有时,当人们说“实时部署”时,它们的意思是实时提取预先计算的预测,但是这里我们指的是实时进行模型预测。实时部署是 Spark 唯一无法满足延迟要求的选项,因此要使用它,你需要将模型导出到 Spark 之外。例如,如果你打算使用 REST 端点进行实时模型推断(例如,在 50 毫秒内计算预测),则 MLlib 不满足该应用程序所需的等待时间要求,如图 11-5 所示。你需要准备好你的特征并在 Spark 之外进行建模,因为用 Spark 建模可能既费时又困难。
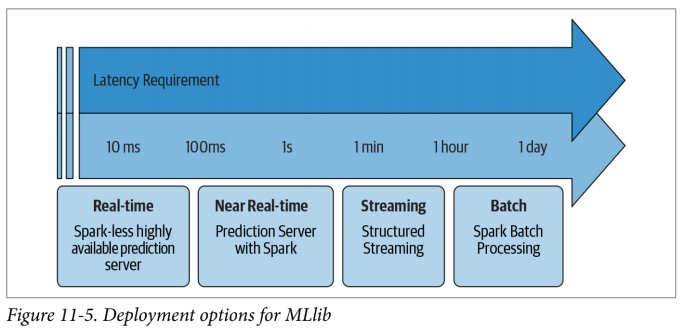
在开始建模过程之前,需要定义模型部署需求。MLlib 和 Spark 只是你工具箱中的一些工具,你需要了解应在何时何地应用它们。本节的其余部分将更深入地讨论 MLlib 的部署选项,然后我们将考虑针对非 MLlib 模型的 Spark 部署选项。
批
批处理部署代表了部署机器学习模型的大多数情形,并且可以说这是最容易实现的选择。你将运行常规作业以生成预测,并将结果保存到表,数据库,数据湖等中,以供下游使用。实际上,你已经在第 10 章中使用 MLlib 生成了如何生成批量预测。MLlib 的 model.transform()会将模型并行应用于 DataFrame 的所有分区:
In Python
Load saved model with MLflow
import mlflow.spark
pipelineModel = mlflow.spark.load_model(f"runs:/{run_id}/model")
Generate predictions
inputDF = spark.read.parquet("/databricks-datasets/learning-spark-v2/
sf-airbnb/sf-airbnb-clean.parquet")
predDF = pipelineModel.transform(inputDF)
批处理部署要记住的几件事是:
你将多久生成一次预测?
在延迟和吞吐量之间需要权衡。你将获得更高的吞吐量,将许多预测分批处理,但是接收任何单个预测所花费的时间将更长,从而延迟了你对这些预测采取行动的能力。
你将多久重新训练一次模型?
与 sklearn 或 TensorFlow 之类的库不同,MLlib 不支持在线更新或热启动。如果你想重新训练模型以合并最新数据,则必须从头开始重新训练整个模型,而不是利用现有参数。就重新训练的频率而言,有些人将建立一个常规工作来对模型进行再次训练(例如,每月一次),而其他人将积极地监视模型漂移以确定什么时候需要重新训练。
你将如何对模型进行版本控制?
你可以使用 MLflow 模型注册表来追踪所使用的模型,并控制它们如何在暂存区,生产和归档之间进行转换。你可以在图 11-6 中看到 Model Registry 的屏幕截图。你也可以将 Model Registry 与其他部署选项一起使用。
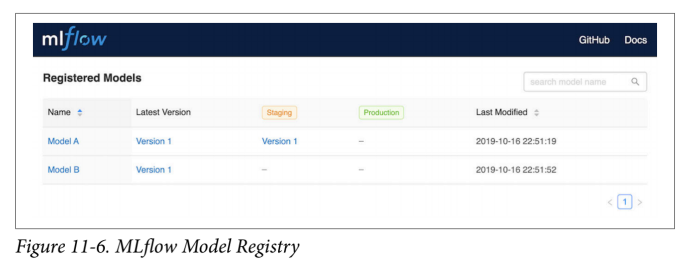
除了使用 MLflow UI 来管理模型外,你还可以通过编程方式来管理它们。例如,一旦你注册了生产模型,那么它就具有一个一致的 URI,可用于检索最新版本:
Retrieve latest production model
model_production_uri = f"models:/{model_name}/production"
model_production = mlflow.spark.load_model(model_production_uri)
流
无需等待每小时或每晚的工作来处理数据并生成预测,结构化流可以连续对传入数据执行推断。尽管这种方法比批处理解决方案的成本更高,因为你必须不断地为计算时间付费(并获得较低的吞吐量),但是你可以获得更多的好处,即可以更频繁地生成预测,从而可以更快地对它们进行操作。通常,流处理解决方案比批处理解决方案维护和监视更为复杂,但是它们提供了较低的延迟。
使用 Spark 可以很容易地将批处理预测转换为流式预测,并且几乎所有代码都是相同的。唯一的区别是,在读取数据时,你需要使用 spark.readStream()而不是 spark.read(),并更改数据源。在以下示例中,我们将通过在 Parquet 文件目录中进行流传输来模拟流数据的读取。你会注意到我们指定了一个 schema,即使我们正在处理 Parquet 文件。这是因为在处理流数据时,我们需要先定义数据结构。在此示例中,我们将使用在上一章的 Airbnb 数据集上训练的随机森林模型来执行这些流预测。我们将使用 MLflow 加载保存的模型。我们已将源文件划分为一百个小型 Parquet 文件,因此你可以看到输出在每个触发间隔处都在变化:
In Python
Load saved model with MLflow
pipelineModel = mlflow.spark.load_model(f"runs:/{run_id}/model")
Set up simulated streaming data
repartitionedPath = "/databricks-datasets/learning-spark-v2/sf-airbnb/
sf-airbnb-clean-100p.parquet"
schema = spark.read.parquet(repartitionedPath).schema
streamingData = (spark
.readStream
.schema(schema) # Can set the schema this way
.option("maxFilesPerTrigger", 1)
.parquet(repartitionedPath))
Generate predictions
streamPred = pipelineModel.transform(streamingData)
生成这些预测后,你可以将它们写到任何目标位置以供以后检索(有关结构化流技巧,请参见第 8 章)。如你所见,批处理和流传输方案之间的代码几乎没有变化,这使得 MLlib 成为这两种方案的理想解决方案。但是,根据任务的延迟要求,MLlib 可能不是最佳选择。使用 Spark 时,在生成查询计划以及在驱动程序和工作节点之间传递任务和结果时会涉及大量开销。因此,如果你需要真正的低延迟预测,则需要从 Spark 导出模型。
近实时
如果你的用例需要数百毫秒到几秒钟的预测,则可以构建一个使用 MLlib 生成测的预测服务器。尽管这对于 Spark 来说不是理想的用例,因为你正在处理的数据量非常小,但是与流或批处理解决方案相比,你将获得更低的延迟。
用于实时推理的模型导出模式
在某些需要实时推理的场景中,包括欺诈检测,广告推荐等。虽然使用少量记录进行预测可能会实现实时推理所需的低延迟,但是你将需要应对负载平衡(处理许多并发请求)以及对延迟至关重要的任务中的位置定位。有流行的托管解决方案,例如 AWS SageMaker 和 Azure ML,它们提供了低延迟模型服务解决方案。在本节中,我们将向你展示如何导出 MLlib 模型,以便将其部署到那些服务中。
从 Spark 中导出模型的一种方法是用 Python、C 等原生地重新实现模型,虽然提取模型的系数看起来很简单,但导出所有的特征工程和预处理步骤(OneHot Encoder, VectorAssembler 等),很快就会遇到麻烦,并且非常容易出错。有一些开源库,例如 MLeap 和 ONNX,可以帮助你自动导出 MLlib 模型的受支持子集,以消除它们对 Spark 的依赖。但是,在撰写本文时,开发 MLeap 的公司已不再支持它。MLeap 也不支持 Scala 2.12 / Spark 3.0。
另一方面,ONNX(开放神经网络交换)已成为机器学习互操作性的事实上的开放标准。你们中的某些人可能还记得其他 ML 互操作性格式,例如 PMML(预测模型标记语言),但是这些格式从未像现在的 ONNX 一样吸引人。ONNX 在深度学习社区中非常流行,它是一种允许开发人员轻松在库和语言之间进行切换的工具,并且在撰写本文时,它已提供对 MLlib 的实验性支持。
除了导出 MLlib 模型之外,还有其他一些与 Spark 集成的第三方库,这些第三方库可以方便地在实时场景中进行部署,例如 XGBoost 和 H2O.ai 的 Sparkling Water(其名称源自 H2O 和 Spark 的组合) 。
XGBoost 是针对结构化数据问题的 Kaggle 竞赛中最成功的算法之一,它是数据科学家中非常受欢迎的库。尽管从技术上讲 XGBoost 不是 MLlib 的一部分,但是 XGBoost4J-Spark 库允许你将分布式 XGBoost 集成到 MLlib 管道中。XGBoost 的一个好处是易于部署:训练了 MLlib 管道后,你可以提取 XGBoost 模型并将其另存为非 Spark 模型以供在 Python 中使用,如下所示:
// In Scala
val xgboostModel =
xgboostPipelineModel.stages.last.asInstanceOf[XGBoostRegressionModel]
xgboostModel.nativeBooster.saveModel(nativeModelPath)
In Python
import xgboost as xgb
bst = xgb.Booster({'nthread': 4})
bst.load_model("xgboost_native_model")
在撰写本文时,分布式 XGBoost API 仅在 Java / Scala 中可用。
本书的 GitHub repo 中包含了完整的示例。
现在,你已经了解了导出用于实时服务环境的 MLlib 模型的不同方法,让我们讨论如何将 Spark 应用于非 MLlib 模型。
利用 Spark 处理非 MLlib 模型
如前所述,MLlib 并不是总是能满足你的机器学习需求的最佳解决方案。它可能无法满足超低延迟推理需求,或者对你要使用的算法需要内置支持。对于这些情况,你仍然可以利用 Spark,但不能利用 MLlib。在本节中,我们将讨论如何使用 Spark 使用 Pandas UDF 执行单节点模型的分布式推理,执行超参数调整以及缩放特征工程。
Pandas UDF
虽然 MLlib 非常适合用于模型的分布式训练,但你不仅限于使用 MLlib 来通过 Spark 进行批处理或流式预测,还可以创建自定义函数来大规模应用预训练的模型,称为用户定义函数(UDF,在第 5 章中有介绍)。一个常见的用例是在单台机器上(也许在数据的一部分上)构建 scikit-learn 或 TensorFlow 模型,但使用 Spark 在整个数据集上进行分布式推理。
如果你定义自己的 UDF 以将模型应用于 Python 中的 DataFrame 的每个记录,请选择 Pandas UDF 以优化序列化和反序列化,如第 5 章中所述。但是,如果你的模型很大,那么 Pandas UDF 要在同一 Python 工作进程中为每个批次重复加载相同的模型,会产生很高的开销。在 Spark 3.0 中,Pandas UDF 可以接受 pandas.Series 的迭代器,或者 pandas.DataFrame,因此你只需要加载一次模型就可以了,而不是为迭代器中的每个系列加载一次模型。有关带有 Pandas UDF 的 Apache Spark 3.0 中新增功能的更多详细信息,请参见第 12 章。
如果工作节点在第一次加载模型权重后对其进行缓存,则随后对具有相同模型加载的相同 UDF 的调用将变得更快。
在以下示例中,我们将使用 Spark 3.0 中引入的 mapInPandas(),将 scikit-learn 模型应用于 Airbnb 数据集。mapInPandas()接受 pandas.DataFrame 的迭代器作为输入,并输出的另一个迭代器 pandas.DataFrame。如果你的模型需要所有列作为输入,它很灵活且易于使用,但是需要对整个 DataFrame 进行序列化/反序列化(将他传递给输入)。你可以通过 spark.sql.execution.arrow.maxRecordsPerBatch 的配置来控制每个 pandas.DataFrame 的大小。本书的 GitHub 仓库中提供了用于生成模型的代码的完整副本,但是在这里,我们仅专注于从 MLflow 加载保存的 scikit-learn 模型并将其应用于我们的 Spark DataFrame:
In Python
import mlflow.sklearn
import pandas as pd
def predict(iterator):
model_path = f"runs:/{run_id}/random-forest-model"
model = mlflow.sklearn.load_model(model_path) # Load model
for features in iterator:
yield pd.DataFrame(model.predict(features))
df.mapInPandas(predict, "prediction double").show(3)
+-----------------+
| prediction|
+-----------------+
| 90.4355866254844|
|255.3459534312323|
| 499.625544914651|
+-----------------+
除了使用 Pandas UDF 大规模应用模型外,你还可以使用它们并行化构建许多模型的过程。例如,你可能想为每种 IoT 设备类型构建模型以预测故障时间。你可以针对这样的任务使用 pyspark.sql.GroupedData.applyInPandas()(Spark 3.0 中引入)。该函数处理 pandas.DataFrame 并返回另一个 pandas.DataFrame。本书的 GitHub 仓库包含完整的代码示例,用于按 IoT 设备类型构建模型并使用 MLflow 追踪各个模型。为了简洁起见,这里只选取一个代码片段:
In Python
df.groupBy("device_id").applyInPandas(build_model,
schema=trainReturnSchema)
groupBy()将导致你的数据集被重新打散,并且你需要确保每个组的模型和数据都可以放在同一台计算机上。你们中有些人可能很熟悉 pyspark.sql.GroupedData.apply()(例如 df.groupBy("device_id").apply(build_model)),但该 API 将在 Spark 的未来版本将会被废弃,取而代之的是 pyspark.sql.GroupedData.applyInPandas()。
既然你已经了解了如何应用 UDF 执行分布式推理和并行化模型构建,那么让我们看一下如何使用 Spark 进行分布式超参数调整。
用于分布式超参数调整的 Spark
即使你不打算进行分布式推理或不需要 MLlib 的分布式训练功能,你仍然可以利用 Spark 进行分布式超参数调整。本节将特别介绍两个开源库:Joblib 和 Hyperopt。
Joblib
根据其文档,Joblib 是“一组在 Python 中提供轻量级管道处理的工具。” 它具有一个 Spark 后端,可以在 Spark 集群上分发任务。Joblib 可用于超参数调整,因为它会自动将数据副本广播给所有 worker,然后 worker 将在其数据副本上创建具有不同超参数的自己的模型。这使你可以并行训练和评估多个模型。你仍然有一个基本限制,即单个模型和所有数据都必须放在一台机器上,但是你可以简单地并行化超参数搜索,如图 11-7 所示。
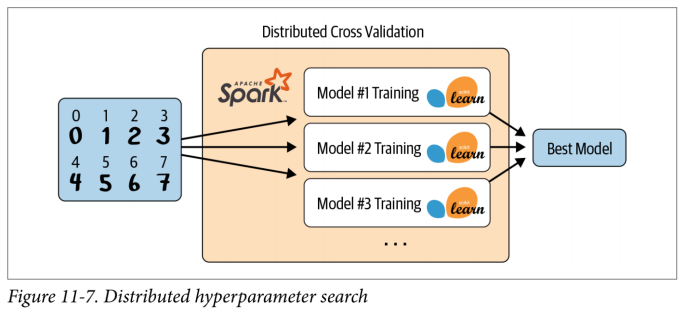
要使用 Joblib,请通过 pip install joblibspark 安装它。确保你使用的 scikit-learn 是 0.21 或更高版本以及 pyspark v2.4.4 或更高版本。此处显示了如何进行分布式交叉验证的示例,并且相同的方法也适用于分布式超参数调整:
In Python
from sklearn.utils import parallel_backend
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import train_test_split
from sklearn.model_selection import GridSearchCV
import pandas as pd
from joblibspark import register_spark
register_spark() # Register Spark backend
df = pd.read_csv("/dbfs/databricks-datasets/learning-spark-v2/sf-airbnb/
sf-airbnb-numeric.csv")
X_train, X_test, y_train, y_test = train_test_split(df.drop(["price"], axis=1),
df[["price"]].values.ravel(), random_state=42)
rf = RandomForestRegressor(random_state=42)
param_grid = {"max_depth": [2, 5, 10], "n_estimators": [20, 50, 100]}
gscv = GridSearchCV(rf, param_grid, cv=3)
with parallel_backend("spark", n_jobs=3):
gscv.fit(X_train, y_train)
print(gscv.cv_results_)
有关从交叉验证器返回的参数的说明,请参见 scikit-learn GridSearchCV 文档。
Hyperopt
Hyperopt 是一个 Python 库,用于“在笨拙的搜索空间上进行串行和并行优化,其中可能包括实值,离散值和条件维。” 你可以通过 pip install hyperopt 安装它。使用 Apache Spark 扩展 Hyperopt 的主要方法有两种:
将单机 Hyperopt 与分布式训练算法(例如 MLlib)一起使用
使用分布式 Hyperopt 和包含 SparkTrials 类单机训练算法
对于前一种情况,你不需要进行任何配置就可以将 MLlib 与 Hyperopt 以及其他任何库一起使用。因此,让我们看一下后一种情况:具有单节点模型的分布式 Hyperopt。不幸的是,在撰写本文时,你无法将分布式超参数评估与分布式训练模型结合在一起。可以在本书的 GitHub repo 中找到用于并行化 Keras 模型的超参数搜索的完整代码示例;此处仅包含一个片段以说明 Hyperopt 的关键组件:
In Python
import hyperopt
best_hyperparameters = hyperopt.fmin(
fn = training_function,
space = search_space,
algo = hyperopt.tpe.suggest,
max_evals = 64,
trials = hyperopt.SparkTrials(parallelism=4))
fmin()生成新的超参数配置供你使用 training_function,并将它们传递给 SparkTrials。SparkTrials 在每个 Spark 执行器上将这些训练任务的批处理作为一个单任务 Spark 作业并行运行。Spark 任务完成后,它将结果和相应的损失返回给驱动程序。Hyperopt 使用这些新结果来为将来的任务计算更好的超参数配置。这允许超参数调整的大规模扩展。MLflow 还与 Hyperopt 集成,因此你可以在超参数调整中追踪已训练的所有模型的结果。SparkTrials 的一个重要参数是 parallelism。用于确定要同时评估的最大试验次数,也就是并行度。如果为 parallelism=1,则你将按顺序训练每个模型,但是通过充分利用自适应算法可能会得到更好的模型。如果你设置了 parallelism=max_evals(要训练的模型总数),那么你只是在进行随机搜索。处于 1 和 max_evals 之间的任意数字允许你可以在可伸缩性和适应性之间进行权衡。默认情况下,parallelism 设置为 Spark 执行程序的数量。你还可以指定一个超时时间(timeout)来限制 fmin()允许的最大秒数。即使 MLlib 不适合你的问题,也希望你能在任何机器学习任务中看到使用 Spark 的价值。
Kaolas
Pandas 是 Python 中非常流行的数据分析和操作库,但仅限于在一台机器上运行。Koalas 是一个开放源代码库,它在 Apache Spark 之上实现了 Pandas DataFrame API,从而简化了从 Pandas 到 Spark 的过渡。你可以用命令 pip install koalas 进行安装,然后只需将 pd 代码中的任何(Pandas)逻辑替换为 ks(Koalas)。这样,你可以使用 Pandas 扩展分析,而无需完全重写 PySpark 中的代码库。这是一个如何将 Pandas 代码更改为 Koalas 的示例(你需要已安装 PySpark):
In pandas
import pandas as pd
pdf = pd.read_csv(csv_path, header=0, sep=";", quotechar='"')
pdf["duration_new"] = pdf["duration"] + 100
In koalas
import databricks.koalas as ks
kdf = ks.read_csv(file_path, header=0, sep=";", quotechar='"')
kdf["duration_new"] = kdf["duration"] + 100
虽然 Koalas 的目标是最终实现所有 Pandas 功能,但尚未全部实现。如果你有 Koalas 无法提供的某些功能,则可以随时通过调用切换到使用 Spark API kdf.to_spark()。另外,你可以通过调用 kdf.to_pandas()并使用 Pandas API 将数据带到驱动程序中(请注意数据集不能太大,否则将导致驱动程序崩溃!)。
小结
在本章中,我们介绍了用于管理和部署机器学习管道的各种最佳实践。你了解了 MLflow 如何帮助你追踪和重现实验以及打包代码及其依赖项以将其部署到其他地方。我们还讨论了主要的部署选项(批处理,流和实时)及其相关的权衡取舍。MLlib 是用于大规模模型训练和批处理/流式使用案例的绝佳解决方案,但对于小数据集的实时推理,相对于单节点模型就没什么优势。你的部署需求直接影响你可以使用的模型和框架的类型,因此在开始模型构建过程之前,讨论这些需求至关重要。
在下一章中,我们将重点介绍 Spark 3.0 中的一些关键新功能,以及如何将其合并到 Spark 工作负载中。
版权声明: 本文为 InfoQ 作者【数据与智能】的原创文章。
原文链接:【http://xie.infoq.cn/article/73b89875bb8578326eaea4f5c】。文章转载请联系作者。

还未添加个人签名 2018.05.14 加入
公众号【数据与智能】主理人,个人微信:liuq4360 12 年大数据与 AI相关项目经验, 10 年推荐系统研究及实践经验,目前已经输出了40万字的推荐系统系列精品文章,并有新书即将出版。








评论