Linux 角度仰视 Goroutine 的 GMP

golang 的调度在现在的计算机发展中, 有着开创的意义,依靠于 linux kernel 的调度基础,设计出了 gmp 来供语言级的协程调度,在生产与性能方面,有着卓越的优势
知识回顾
Linux 调度
调度策略
Linux 从 2.6.23 版本开始,将 CFS(Completely Fair Scheduler)默认的调度器。在 CFS 中实际上维护了一个红黑树(在底层维护的一个 sched_entity 的结构体对象), 把 CPU 当做一种资源,并记录下每一个进程对该资源使用的情况,在调度时,调度器总是选择消耗资源最少的进程来运行。这就是所谓的“完全公平”。
在 Linux 内核中还存在其他 4 中调度器:Stop 调度器、deadline 调度器、RT 调度器和 IDLE-Task 调度器。
实现原理
在实现层面,Linux 通过引入 virtual runtime(vruntime)来完成上面的设想,具体的,我们来看下从实际运行时间到 vruntime 的换算公式
vruntime = 实际运行时间 * 1024 / 进程权重
Linux 所谓的调度就是调度(进程/线程)
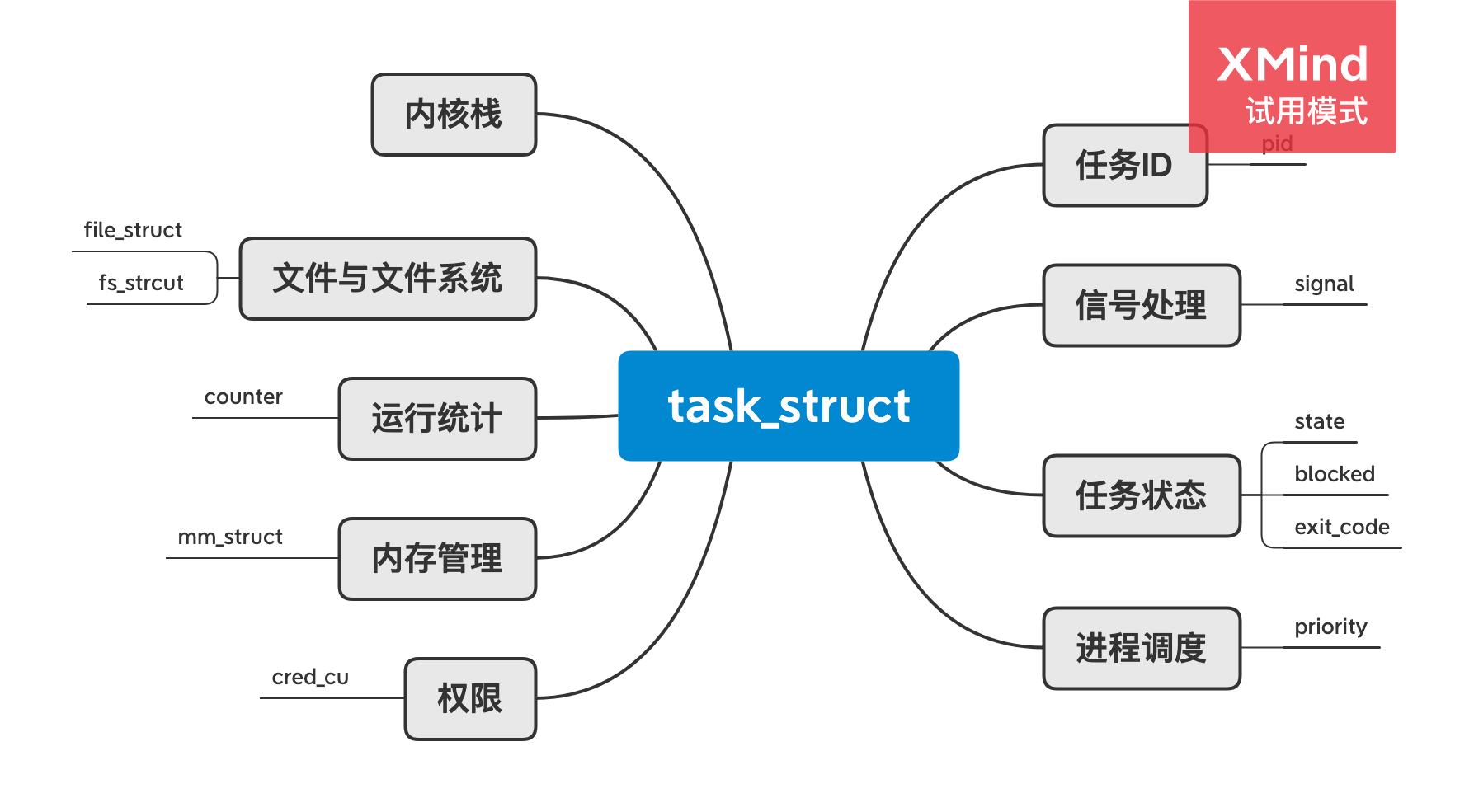
进程控制块
由于 Linux 调度器实际是识别 task_struct 进行调度,而在 Linux 系统中task_struct就是进程控制块(PCB),基本数据结构如下:(由于线程又叫做轻量级进程(light-weight process LWP),也有 PCB,创建线程使用的底层函数和进程底层一样,都是 clone。所以线程的数据结构不再重复复述。)
可以看出成员变量不少,我提炼一下关键的几个字段作用:
Api:
system() 启动一个新进程
exec() 以替换当前进程映像的方式启动一个新进程
fork() 以复制当前进程映像的方式启动一个新进程,除了 task_struct 和堆栈,子进程和父进程共享所有的资源,相当于复制了一个父进程,但是由于 linux 采用了写时复制技术,复制工作不是立即就执行,提高了效率。
wait() 父进程挂起,等待子进程结束。
clone() 创建一个线程与当前的进程共享
pthread_create() 创建一个用户线程,底层实际上调用 clone(),并把开辟一个 stack 作为参数 thread 建立 , 同步销毁等由线程库负责。
这里补充:提到线程,这里顺便以 Java 为例子:每个 Java 线程一对一映射到 Solaris 平台上的一个本地线程上,并将线程调度交由本地线程的调度程序。由于 Java 线程是与本地线程是一对一地绑在一起的,而在调 Java 的 SDKsetPriority()也不能百分百的修改线程的优先级;
runqueue 运行队列
Linux 内核使用 struct_rq 结构来描述运行队列,结构体如下:
rq 的基本职责就是:在每一个 CPU 中都有一个自己的运行队列,当一个 CPU 接受到一个 task 的时候,就会以 sched_entity 的实体丢入队列中,最后选择使用的调度器来进行调度;具体如流程如下图:
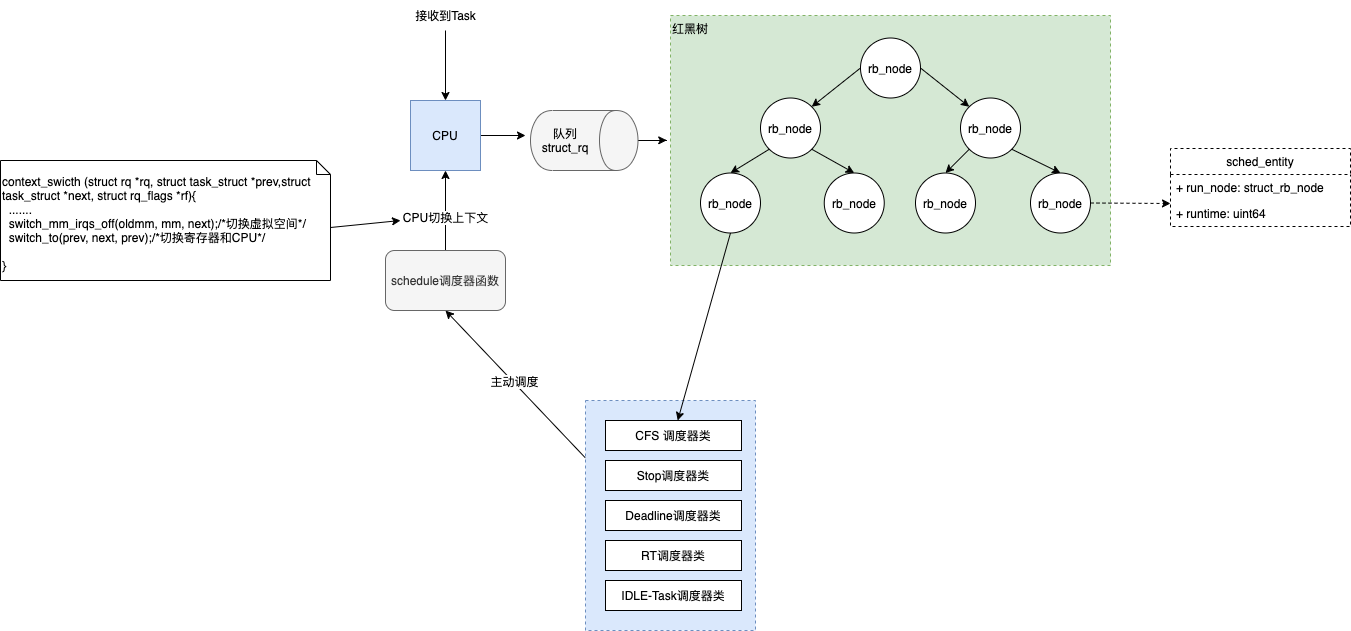
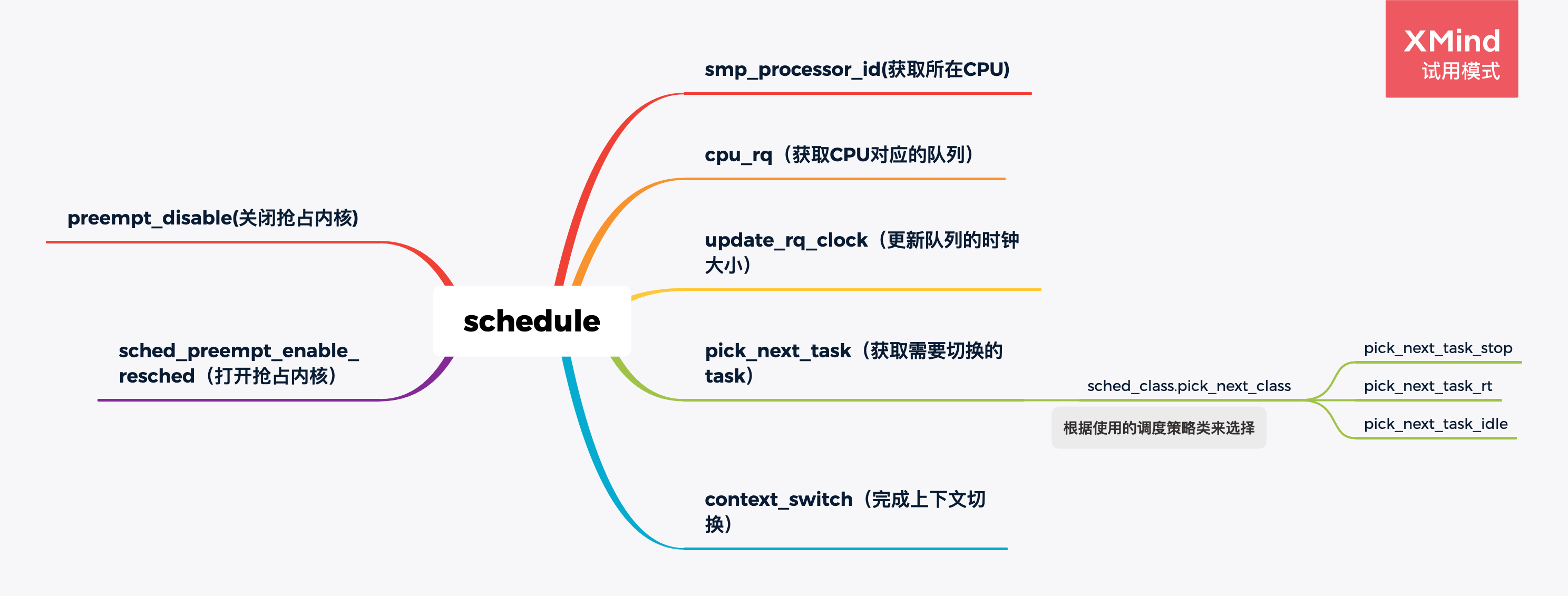
Schedule 函数
在上图中存在一个 schedule 的主程序入口,具体的功能如下:
Java 的线程调度
做过 Java 的开发项目的同学也许查看某个 webServer 或者 Rpc 的 Server 时候会发现经常 pid 有两个(如下图):其实一个是父进程,另一个就是子进程,更新专业的说一个是 LWP 也就是轻量级的线程。:

用一张图来描述 cpu 的线程调度和进程的关系:
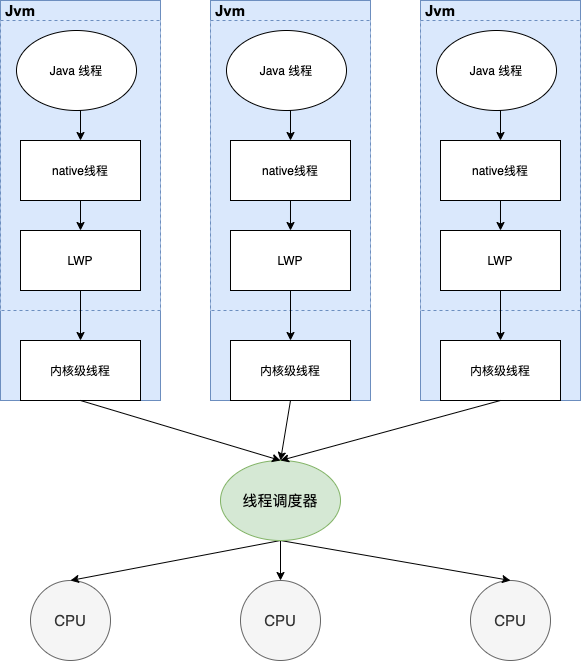
在 Java 的线程调度中,我们可以发现其实即便 Jvm 开启的线程,但是本质上最终还是绑定内核态的一个线程,所以对于一个大型程序,我们可以开辟的线程数量至少等于运行机器的 cpu 内核数量。java 程序里我们可以通过下面的一行代码得到这个数量:
所以最小线程数量即时 cpu 内核数量。
如果所有的任务都是计算密集型的,这个最小线程数量就是我们需要的线程数。开辟更多的线程只会影响程序的性能,因为线程之间的切换工作,会消耗额外的资源。如果任务是 IO 密集型的任务,我们可以开辟更多的线程执行任务。
当一个任务执行 IO 操作的时候,线程将会被阻塞,处理器立刻会切换到另外一个合适的线程去执行。如果我们只拥有与内核数量一样多的线程,即使我们有任务要执行,他们也不能执行,因为处理器没有可以用来调度的线程。
如果线程有 50%的时间被阻塞,线程的数量就应该是内核数量的 2 倍。如果更少的比例被阻塞,那么它们就是计算密集型的,则需要开辟较少的线程。如果有更多的时间被阻塞,那么就是 IO 密集型的程序,则可以开辟更多的线程。于是我们可以得到下面的线程数量计算公式:
线程数量 = 内核数量 / (1 - 阻塞率)
Golang 调度模型
通过 Java 的线程调度,我们可以发现其实线程分为用户态和内核态的,在 Java 中只不过是一个用户态线程通过 native 的线程映射到一个 LWP 线程(前文提到的轻量级线程,作用域通过内核态支持用户态线程),最终绑定了一个内核态的线程。而 Golang 恰巧利用了这一点,就是自己组织调度用户态的线程,因为 CPU 最终只关注内核态的线程,于是协程就诞生了。
在转 Golang 之前,一直停其他开发同学说:Golang 比较牛逼就是协程,一种跟轻量级的东西,比线程占用的内存更小,切换的时候,说消耗的 CPU 更小。眼见为实,耳听为虚。 眼见不一定为实,耳听不一定为虚。本质上协程是用户态的线程的一种调度管理,简单点来说就是:Golang 通过 goruntime(协程)这种东西,在内部维持一个固定线程数的线程池,进行合理的调度,使得每一个线程上执行更多的工作来降低操作系统和硬件的负载。
脑洞开始了
N:1 模式
既然可以自行的管理用户线程,那么我们可以开启 N 个 goruntime 然后通过调度器来最终绑定一个内核态的线程。这样协程在用户态线程即完成切换,不会陷入到内核态,这种切换非常的轻量快速。具体如下:
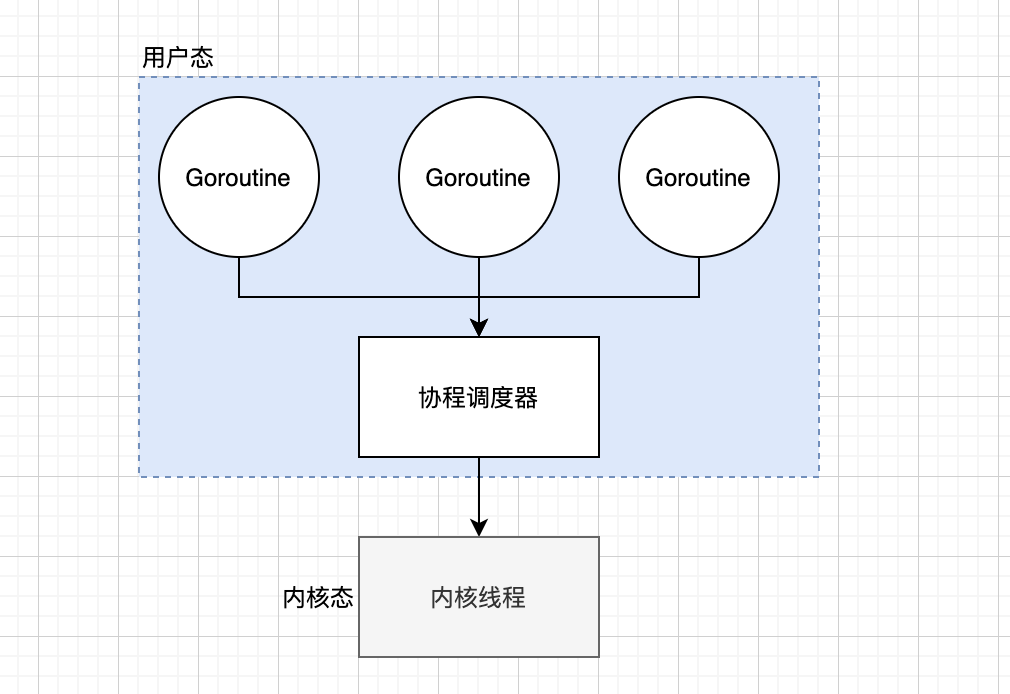
在这种情况很快发现了缺点,所以的线程都绑定一个线程上,如果某一个协程阻塞了,那么其他的整个线程就阻塞了。
N:M 模式
基于上述的情况,我们可以考虑让一组线程绑定到一组线程,这样的话,就不会因为一个协程阻塞而导致其他的协程阻塞。 具体如下:
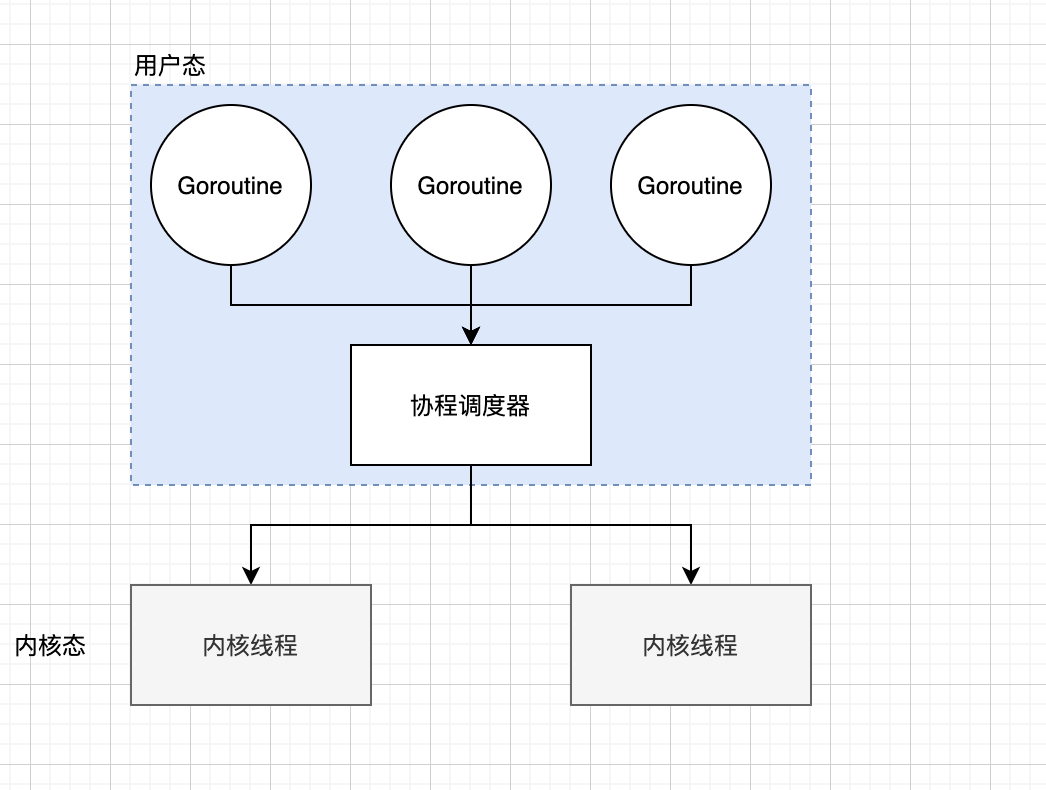
但是在协程的调取器问题依旧存在:
中创建、销毁、调度 goruntime 都需要每个线程获取锁,这就形成了激烈的锁竞争。
线程转移 goruntime 会造成延迟和额外的系统负载。+ 系统调用(CPU 在线程之间的切换)导致频繁的线程阻塞和取消阻塞操作增加了系统开销。
GMP 模式
基于上述问题,Golang 设计了一套新的协程调度模式:GMP 模式,即在原来 M(thread 线程)和 G(goruntime)中引入了 P(processor);
Processor,它包含了运行 goroutine 的资源,如果线程想运行 goroutine,必须先获取 P,P 中还包含了可运行的 G 队列。
GMP 流程图:
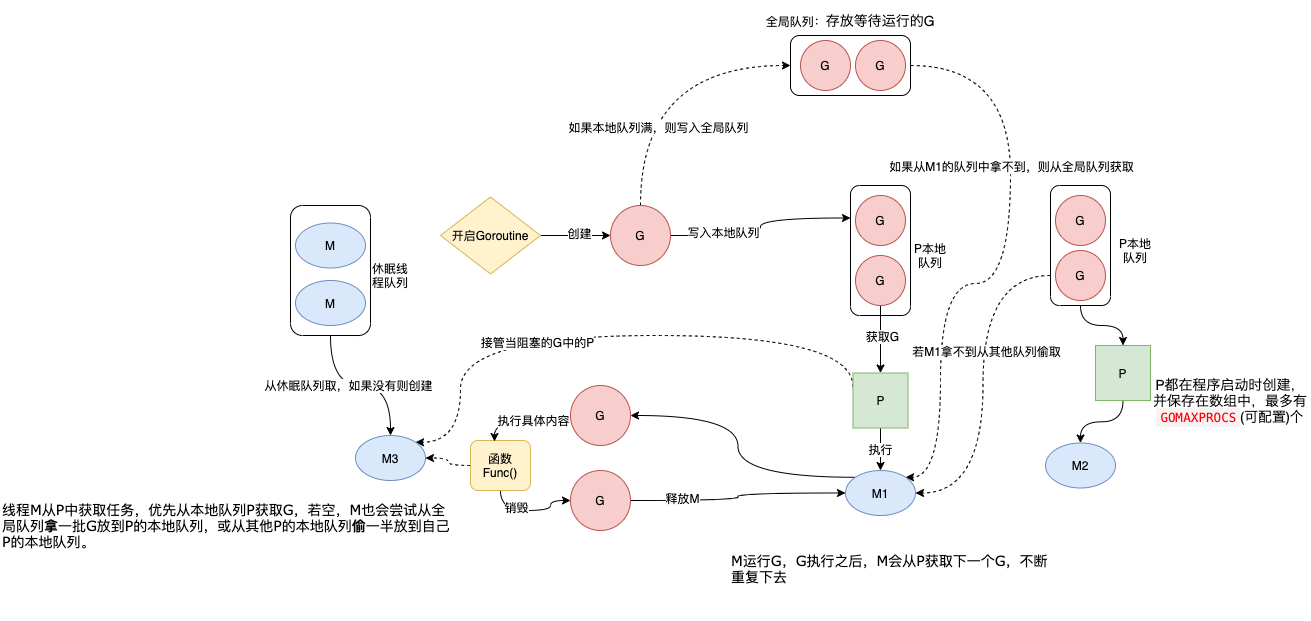
流程文字描述:
通过 go func()来创建一个 goroutine;
有两个存储 G 的队列,一个是局部调度器 P 的本地队列、一个是全局 G 队列。新创建的 G 会先保存在 P 的本地队列中,如果 P 的本地队列已经满了就会保存在全局的队列中;
G 只能运行在 M 中,一个 M 必须持有一个 P,M 与 P 是 1:1 的关系。M 会从 P 的本地队列弹出一个可执行状态的 G 来执行,如果 P 的本地队列为空,就会想其他的 MP 组合偷取一个可执行的 G 来执行;
一个 M 调度 G 执行的过程是一个循环机制;
当 M 执行某一个 G 时候如果发生了 syscall 或则其余阻塞操作,M 会阻塞,如果当前有一些 G 在执行,runtime 会把这个线程 M 从 P 中摘除(detach),然后再创建一个新的操作系统的线程(如果有空闲的线程可用就复用空闲线程)来服务于这个 P;
当 M 系统调用结束时候,这个 G 会尝试获取一个空闲的 P 执行,并放入到这个 P 的本地队列。如果获取不到 P,那么这个线程 M 变成休眠状态, 加入到空闲线程中,然后这个 G 会被放入全局队列中。
上代码,用实践证明
Go code:
下面我们借 Go tool 的 trace 功能来看看程序的结果:



我们再通过 debug 清晰的分析,这里不禁想起了看 Java 的 GClog 日志:
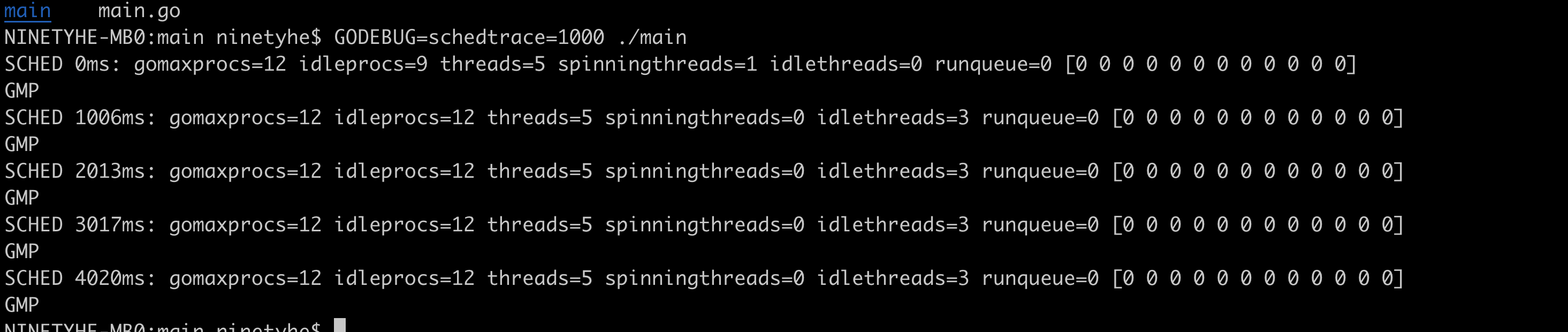
我们挑上述图中关键点来简单说明一下:
gomaxprocs: gomaxprocs=12 默认是 cpu 的核数,这里测试的是 CPU12 核,通过 GOMAXPROCS 来设置;
idleprocs: 处于 idle 状态的 P 的数量;通过 gomaxprocs 和 idleprocs 的差值,我们就可知道执行 go 代码的 P 的数量;
threads: os threads/M 的数量,包含 scheduler 使用的 m 数量,加上 runtime 自用的类似 sysmon 这样的 thread 的数量;
spinningthreads: 处于自旋状态的 os thread 数量;
idlethread: 处于 idle 状态的 os thread 的数量;
runqueue=0: 即对应了前面的 Scheduler 全局队列中 G 的数量;
[0 0 0 0 0 0 0 0]: 貌似是本地 local queue 中的 G 的数组长度,但是理论上都是 0,这里自己也太清晰。
总结
从 linux 的系统调度,借鉴了 Java 的线程调度,最终可以看到 Go 里 GMP 的模式巧妙借助了用户态的线程,让 Goroutine 实现了占用更小的内存,降低了 CPU 的切换次(注意并没有消除了上下文切换,毕竟最终还是依赖内核线程调度)。
版权声明: 本文为 InfoQ 作者【ninetyhe】的原创文章。
原文链接:【http://xie.infoq.cn/article/72b45c9c7bb24037896d7ba5b】。文章转载请联系作者。

Technology Enthusiast 2019.08.20 加入
腾讯后端开发工程师









评论