hbase 运维故障案例分析
在实际运维 HBase 集群时,各位小伙伴总会遇到 RegionServer 异常宕机、业务写入延迟增大甚至无法写入等类似问题。本章结合笔者的经验、列举真实生产线环境常见的几个问题,并介绍这些地问题的基本排查思路。同时,重点对 HBase 系统中的日志进行梳理介绍,最后对如何通过监控、日志等工具进行问题排查进行总结,形成问题排查套路,方便读者进行实践。
regionserver 宕机
案例一: 长时间 GC 导致 Regionserver 宕机
长时间 FullGC 是 RegionServer 宕机最常见的原因.分析这类问题,可以遵循如下排错过程:
现象:收到 Regionserver 进程退出的报警。
宕机原因定位
步骤 1: 通常在监控上看不出,需要到事发的 RegionServer 日志直接搜索 2 类关键字---a long garbage collecting pause 或 ABORTING region server。对于长时间 Full GC 的场景,搜索第一个关键字会检索到:
步骤 2: 通常 CMS GC 策略会在 2 种场景下产生严重的 Full GC ,1. Concurrent Mode Failure 2. Promotion Failure。
现在基本可以确认是由于 concurrent mode failure 模式的 CMS GC 导致长时间应用程序暂停。
2. 宕机原因分析
故障因果分析: JVM 触发的 concurrent mode failure 模式的 CMS GC 会产生长时间的 stop the world,上层应用因此长时间暂停。进一步导致 RegionServer 与 Zookeeper 之间建立的 session 超时。session 一旦超时,Zookeeper 就会通知 Master 将此宕机 RegionServer 踢出集群。
什么是 concurrent mode failure 模式的 GC?为什么会造成长时间暂停?假设 HBase 系统正在执行 CMS 回收老年代空间,在回收的过程中恰好从年轻代晋升了一批对象进来,不巧的是,老年代此时已经没有空间再容纳这些对象了。这种场景下,CMS 收集器会停止工作,系统进入 stop-the-world 模式,并且回收算法会退化为单线程复制算法,重新分配整个堆内存的存活对象到 SO 中,释放所有其他空间。很显然,整个过程会比较漫长。
3. 解决方案
既然是老年代来不及 GC 导致的问题,那只需要让 CMS 收集器更早一点回收就可以大概率避免这种情况发生。
JVM 提供了参数 XX:CMSInitiatingOccupancyFraction=N 来设置 CMS 回收的时机, N 表示当前老年代已使用内存占年轻代总内存的比例, 可以将值改得更小使回收更早进行,比如 60
另外建议在处理时关注下系统 BlockCache 是否开启了 offheap 模式,还有 JVM 启动参数是否合理,JVM 堆内存管理是否未合理使用堆外内存。
案例二: 系统严重 Bug 导致 Regionserver 宕机
大字段 scan 导致 RegionServer 宕机
现象: RegionServer 进程退出
宕机原因定位
步骤 1: 日志。先检查 GC 相关,如果没有再继续搜索关键字“abort”,查到可疑日志“java.lang.OutOfMemoryError: Requested array exceeds VM limit"
步骤 2: 源码确认。看到带堆栈的 FALTAL 级别日志,定位到源码或者根据在关键字在网上搜索,确认该异常发生在 scan 结果数据在回传给客户端时,由于数据量太大导致申请的 array 大小超过 JVM 规定的最大值(Interge.Max_Value-2)
2. 故障因果分析
因为 HBase 系统自身的 bug,在某些场景下 scan 结果数据太大导致 JVM 在申请 array 时抛出 OutOfMemoryError,造成 RegionServer 宕机
3. 本质原因分析
造成这个问题可以认为是 HBase 的 bug,不应该申请超过 JVM 规定阈值的 array。另一方面,也可以认为是业务方用法不当。
表列太宽,并且对 scan 结果没有做列数据限制,导致一行数据就可能因为包含大量列而超过 array 阈值
KeyValue 太大,并且没有对 scan 的返回做限制,导致返回数据结果大小超过 array 阈值。
4. 解决方案
可以在服务端做限制 hbase.server.scanner.max.result.size 大小也可以在客户端访问的时候对返回结果大小做限制(scan.setMaxResultSize)
hbase 写入异常
案例:HDFS 缩容导致部分写入异常
现象:业务反馈部分写入请求超时异常。此时 HBase 在执行 HDFS 集群多台 DataNode 退役操作。
写入异常原因定位
步骤 1: 理论上平滑退役不会造成上层业务感知
步骤 2: 排查 HBase 节点集群监控, 发现退役操作期间节点 IO 负载较高
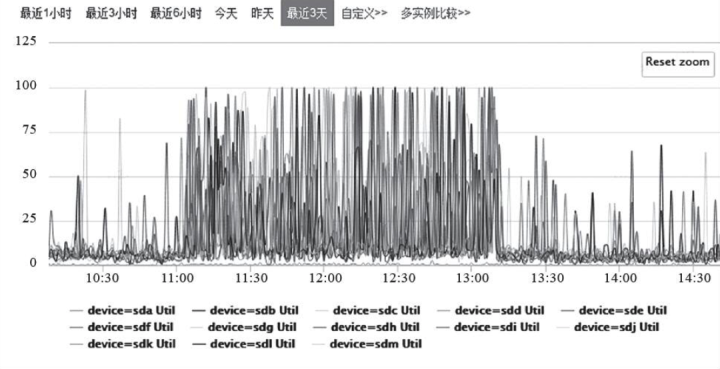
初步判断写入异常和退服期间 IO 负载较高有一定关系。
步骤 3:在相关时间点查看 RegionServer 日志,搜索“Exception”,得到关键的 2 行:
HLog 执行 sync 花费时间太长(13924ms), 写入响应阻塞。
步骤 4: 进一步查看了 DataNode 日志发现刷盘很慢,有异常信息
2. 写入异常原因分析
多台 DataNode 同时退役,过程中 copy 大量数据块会导致集群所有节点的带宽和 IO 压力陡增。
节点 IO 负载很高导致 DataNode 执行数据块落盘很慢,进而导致 HBase 中 HLog 刷盘超时异常,在集群写入压力较大的场景下会引起写入堆积超时
3. 解决方案
运维应在业务低峰期执行 DataNode 退役操作
不能同时退役多台 DataNode,以免造成短时间 IO 压力急剧增大,改成依次退役。
hbase 运维时问题分析思路
生产线问题是系统运维工程师的导师。之所以这样说,是因为对问题的分析可以让我们积累更多的问题定位手段,并且让我们对系统的工作原理有更加深入的理解,甚至接触到很多之前不可能接触到的知识领域。就像去一个 未知的世界探索一个未知的问题,越往里面走,就越能看到别人看不到的世界。所以生产线上的问题发生了,一定要抓住机会,追根溯源。毫不夸张地说,技术人员的核心能力很大部分表现在定位并解决问题的能力上。
实际上,解决问题只是一个结果。从收到报警看到问题的那一刻到最终解决问题,必然会经历三个阶段: 问题定位,问题分析,问题修复。 问题定位是从问题出发通过一定的技术手段找到触发问题的本质,问题分析是从原理上对整个流程脉络梳理清楚,问题解决依赖于问题分析,根据问题分析的结果对问题进行针对性修复或全局修复。
问题定位
定位问题的触发原因是解决问题的关键。问题定位的基本流程如图:
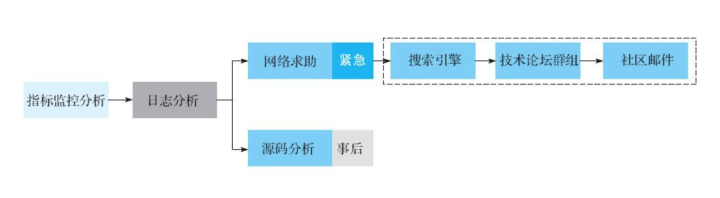
指标监控分析。很多问题都可以直接在监控界面上直观地找到答案。比如业务反馈在某一时刻后读延迟变得非常高。第一反应是去查看系统 IO、CPU 或者带宽是不是有任何异常,如果看到 IO 利用率在对应时间点变得异常高,就基本可以确认读性能下降就是由此导致。虽说 IO 利用率不是本质原因,但这是问题链上的 重要一环,接下来探究为什么 IO 利用率在对应时间点异常。
对问题定位有用的监控指标非常多,宏观上看可以分为系统基础指标和业务相关指标两大类。系统基础指标包括系统 IO 利用率、CPU 负载、带宽等;业务相关指标包括 RegionServer 级别读写 TPS、读写平均延迟、请求队列长度/Compaction 队列长度、MemStore 内存变化、BlockCache 命中率等。
日志分析。对于系统性能问题,监控指标或许可以帮忙,但对于系统异常类型的问题,监控指标可能看不到端倪。这个时候 HBase 系统相关日志最核心的有 RegionServer 日志和 Master 日志,另外 GC 日志、HDFS 相关日志(NameNode 日志和 DataNode 日志)以及 Zookeeper 日志在特定场景下对分析问题都有帮助。
对于日志分析并不需要将日志从头到尾读一遍,可以直接搜索类似于“Exception”,“ERROR”,甚至“WARN”关键字,再结合时间段对日志进行分析。
网络求助。经过监控指标分析和日志分析后,运维人员通常都会有收获。也有部分情况下,我们能看到了"Exception",但不明白具体含义。此时需要去网络上求助。首先在搜索引擎上根据相关日志查找,大多数情况下都能找到相关的文章说明,因为你遇到的问题很大概率别人也会遇到。如果没有线索,接着去各个专业论坛查找请教,比如 stackoverflow、hbase-help.com 以及各种 HBase 相关交流群组。最后,还可以发邮件到社区请教社区技术人员。
源码分析。在问题解决之后,建议通过源码对问题进行再次确认
2. 问题分析
解决未知问题就像一次探索未知世界的旅程。定位问题的过程就是向未知世界走去,走得越远,看到的东西越多,见识到的世面越大。然而眼花缭乱的景色如果不仔细捋一捊,一旦别人问起那个地方怎么样,必然会无言以对。
问题分析是问题定位的一个逆过程。从问题的最本质原因出发,结合系统的工作原理,不断推演,最终推演出系统的异常行为。要把这个过程分析的清清楚楚,不仅仅需要监控信息、异常日志,更需要结合系统工作原理进行分析。所以回过头来看,只有把系统的原理理解清楚,才能把问题分析清楚。
3. 问题修复
如果能够把问题的来龙去脉解释清楚,相信就能够轻而易举地给出针对性解决方案。这应该是整个问题探索中最轻松的一个环节。没有解决不了的问题,如果有,那就是没有把问题分析清楚。
参考: 《HBase 原理与实践》
作者:许佳宾|Growing 运维实施工程师
专注于平台实施、sla 管理/工具建设、Devops 开发
版权声明: 本文为 InfoQ 作者【GrowingIO技术专栏】的原创文章。
原文链接:【http://xie.infoq.cn/article/6e503abb903231b976e52a78e】。
本文遵守【CC-BY 4.0】协议,转载请保留原文出处及本版权声明。

GrowingIO 技术团队经验分享 2020.05.09 加入
GrowingIO(官网网站www.growingio.com)的官方技术专栏,内容涵盖微服务架构,前端技术,数据可视化,DevOps,大数据方面的经验分享。 公众号:GrowingIO技术团队









评论