week06 学习总结
分布式数据库
Mysql复制
主从复制
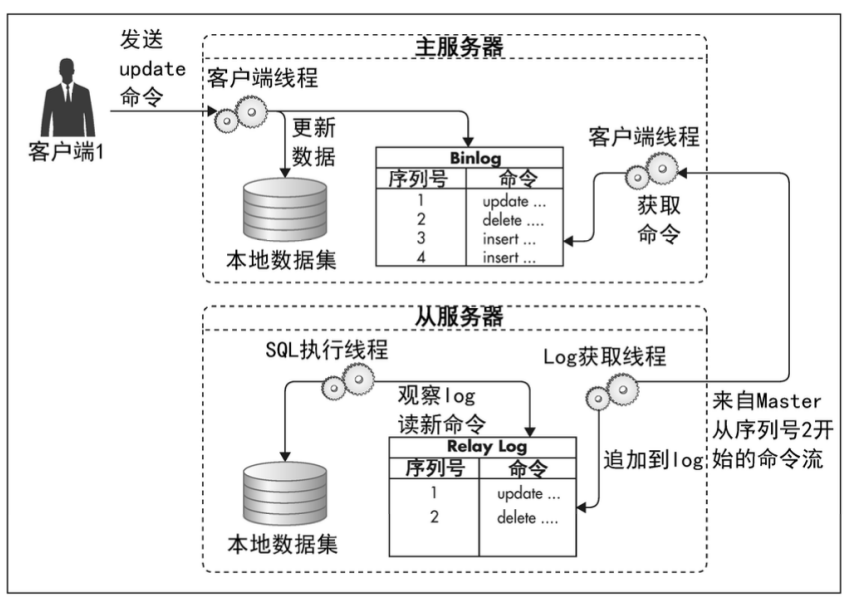
一主多从复制
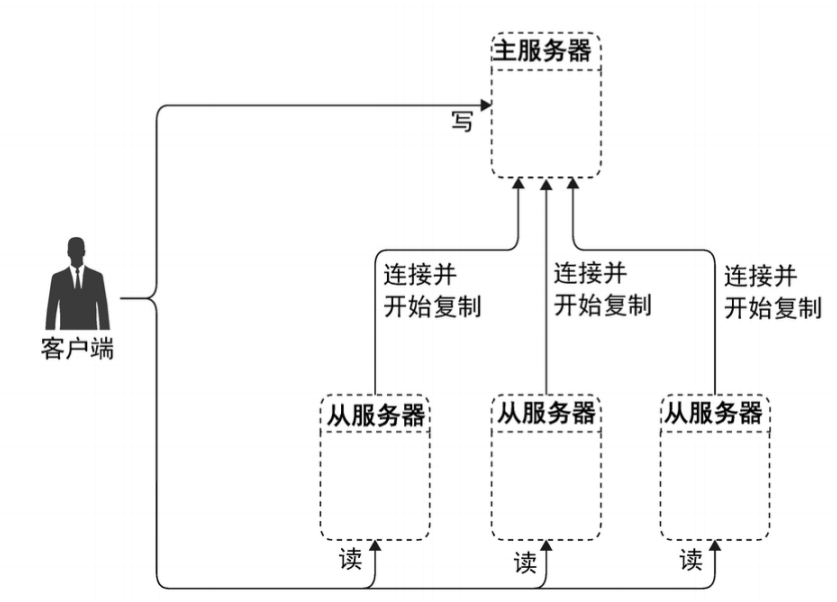
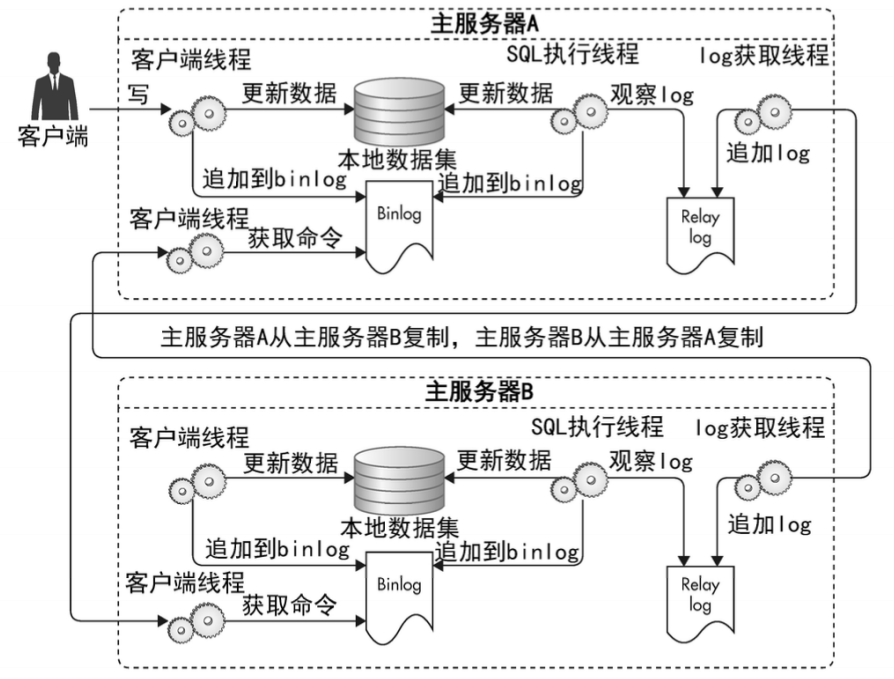
主主复制
主主失效恢复
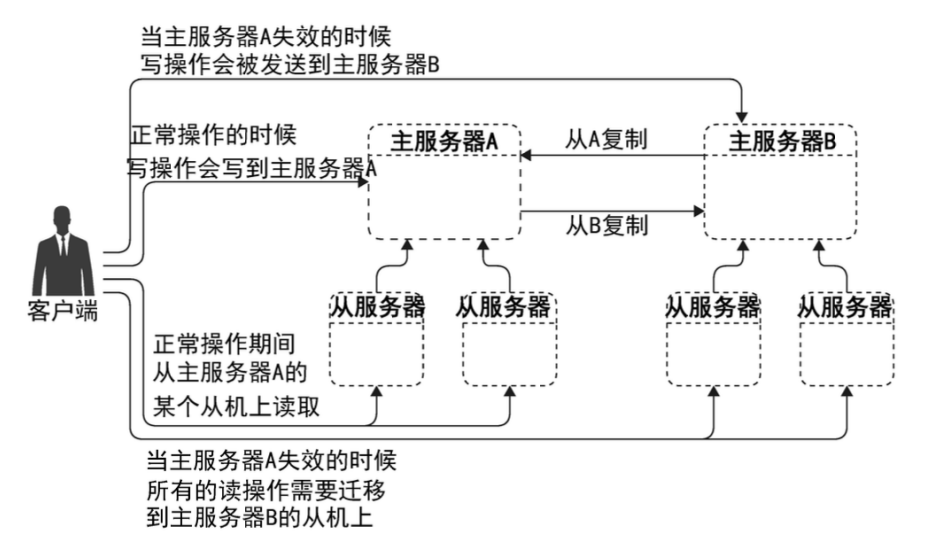
注意要点
主主复制的两个数据库不能并发写入。
复制只是增加了数据的读并发处理能力,没有增加写并发能力和存储能力。
更新表结构会导致巨大的同步延迟。
数据分片
数据分片挑战
• 需要大量的额外代码,处理逻辑因此变得更加复杂。
• 无法执行多分片的联合查询。
• 无法使用数据库的事务。
• 随着数据的增长,如何增加更多的服务器。
数据分片中间件
mycat
cobar
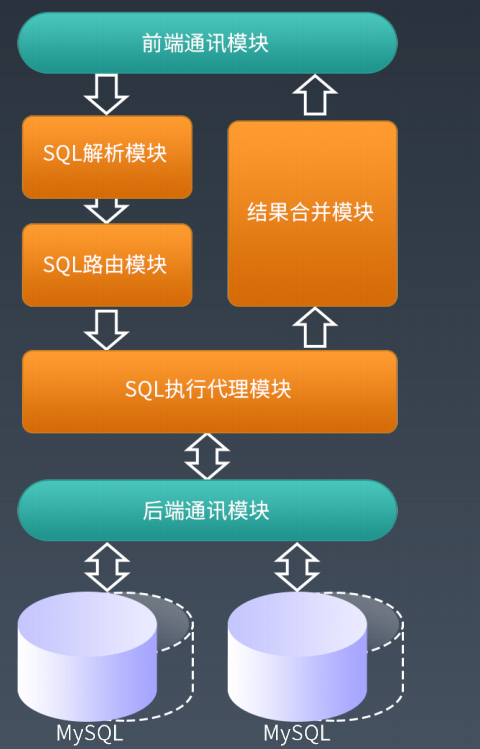
shardingSphere
CAP
一致性Consistency
一致性是说,每次读取的数据都应该是最近写入的数据或者返回一个错误(Every read
receives the most recent write or an error),而不是过期数据,也就是说,数据是一致
的。
可用性Availability
可用性是说,每次请求都应该得到一个响应,而不是返回一个错误或者失去响应,不过
这个响应不需要保证数据是最近写入的(Every request receives a (non-error)
response, without the guarantee that it contains the most recent write),也就是说系
统需要一直都是可以正常使用的,不会引起调用者的异常,但是并不保证响应的数据是
最新的。
分区耐受性Partition tolerance
分区耐受性说,即使因为网络原因,部分服务器节点之间消息丢失或者延迟了,系统依
然应该是可以操作的(The system continues to operate despite an arbitrary number of
messages being dropped (or delayed) by the network between nodes)。
BASE
基本可用(Basically Available)
系统在出现不可预知故障时,允许损失部分可用性,如响应时间上的损失或功能上的损失。
Soft state(弱状态)软状态
指允许系统中的数据存在中间状态,并认为该中间状态的存在不会影响系统的整体可用性,即允许系统在不同节点的数据副本之间进行数据同步的过程存在延时。
Eventually consistent(最终一致性)
指系统中所有的数据副本,在经过一段时间的同步后,最终能够达到一个一致的状态,因此最终一致性的本质是需要系统保证数据能够达到一致,而不需要实时保证系统数据的强一致性。
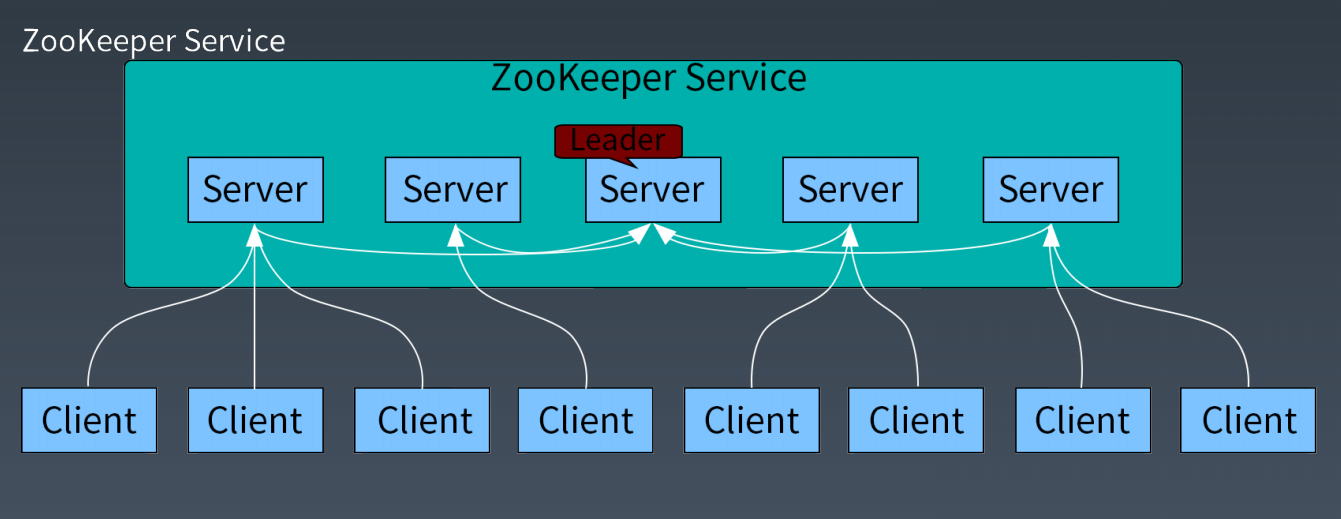
Zookeeper
分布式一致性算法 Paxos
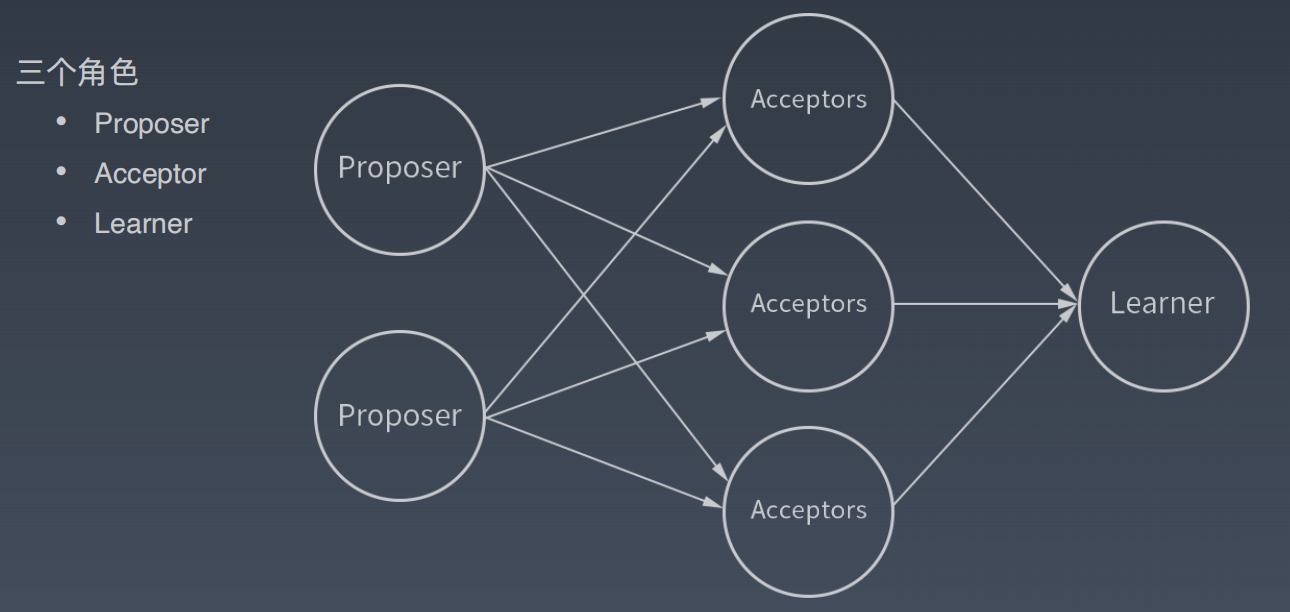
第一阶段:Prepare 阶段。
Proposer 向 Acceptors 发出 Prepare 请求,Acceptors 针对收到的 Prepare 请求进行 Promise 承诺。
第二阶段:Accept 阶段。
Proposer 收到多数 Acceptors 承诺的 Promise 后,向Acceptors 发出 Propose 请求,Acceptors 针对收到的 Propose 求进行 Accept 处理。
第三阶段:Learn 阶段。
Proposer 在收到多数 Acceptors 的 Accept 之后,标志着本次Accept 成功,决议形成,将形成的决议发送给所有 Learners。
Proposer 生成全局唯一且递增的 Proposal ID (可使用时间戳加Server ID),向所有Acceptors 发送 Prepare 请求,这里无需携带提案内容,只携带 Proposal ID 即可。
Acceptors 收到 Prepare 和 Propose 请求后
不再接受 Proposal ID 小于等于当前请求的 Prepare 请求。
不再接受 Proposal ID 小于当前请求的 Propose 请求
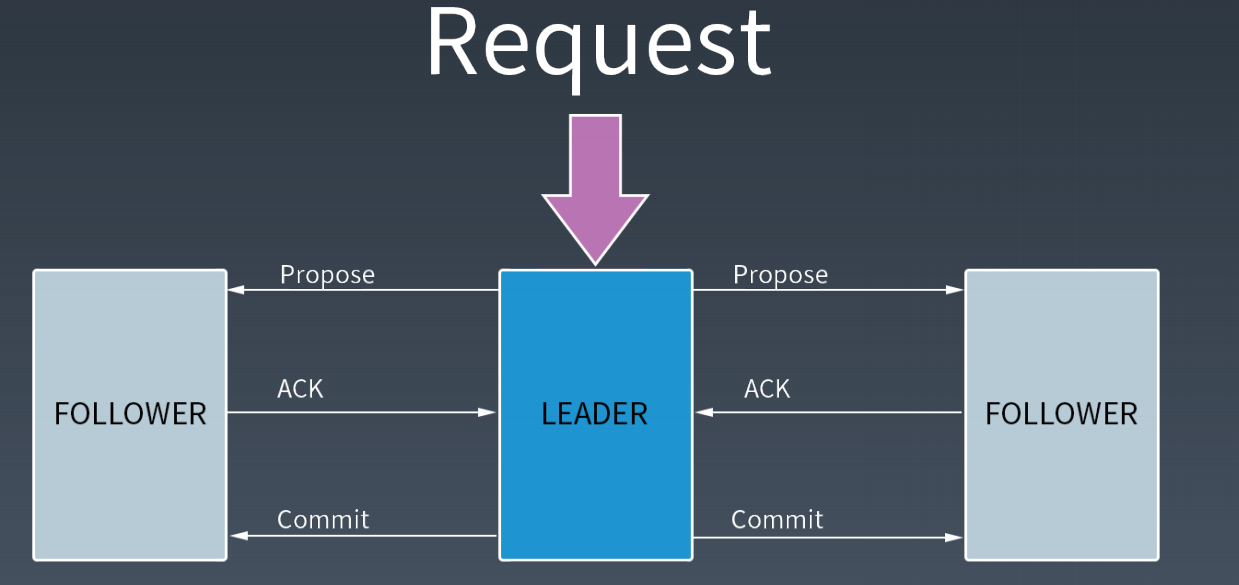
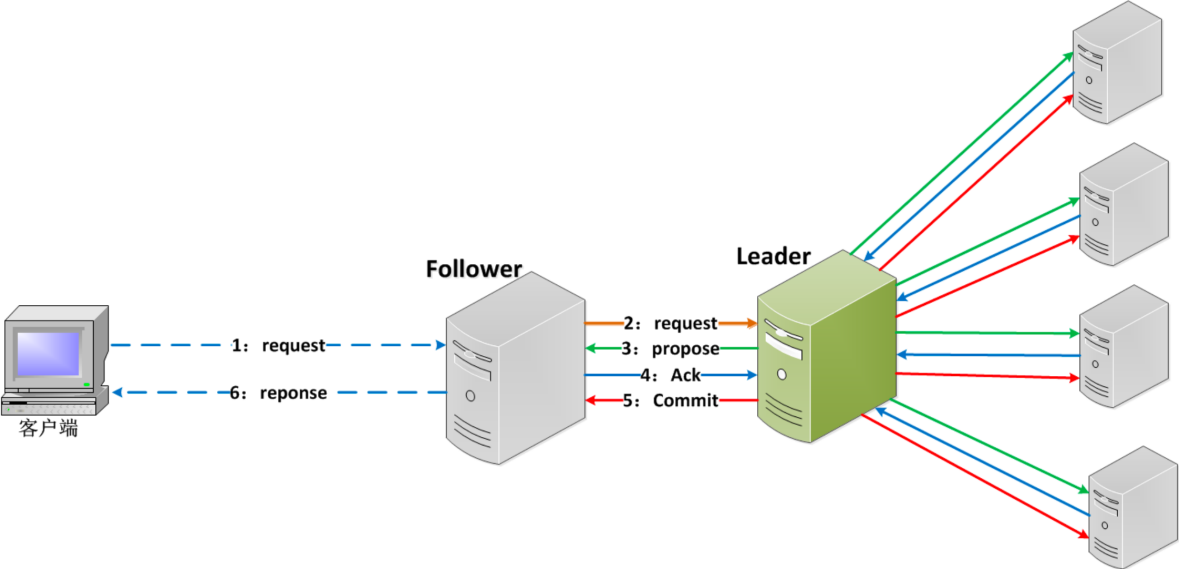
Zab 协议
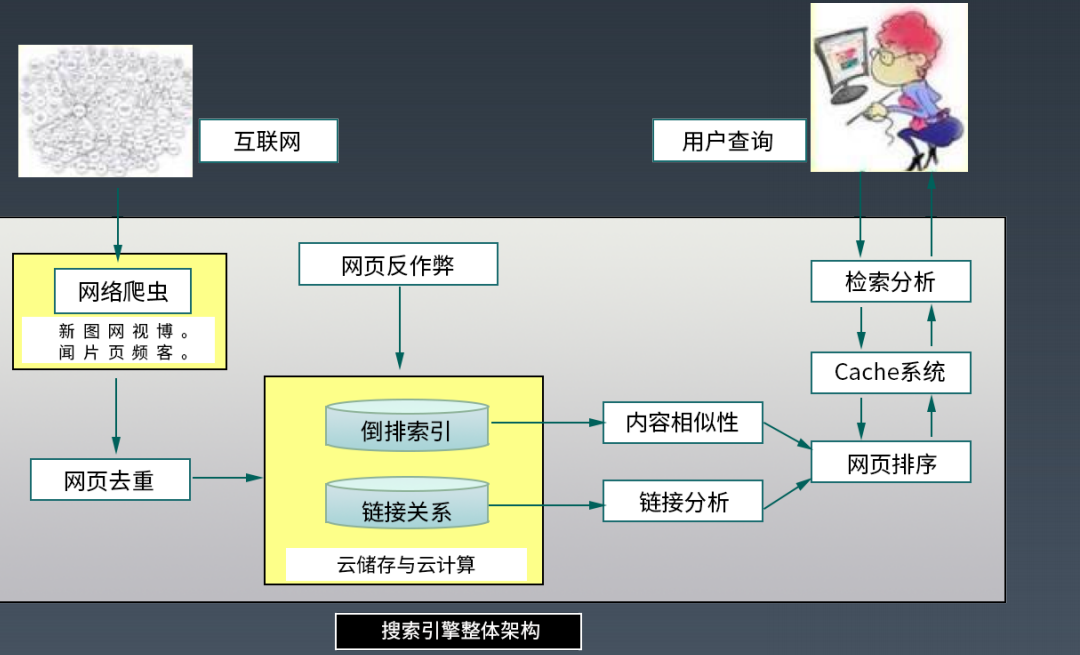
搜索引擎
互联网搜索引擎整体架构
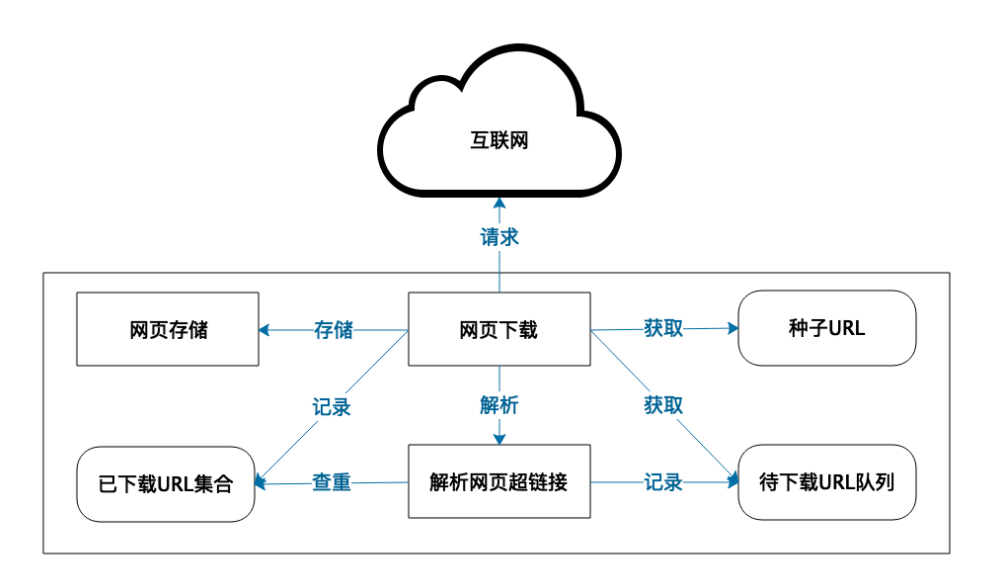
爬虫系统架构
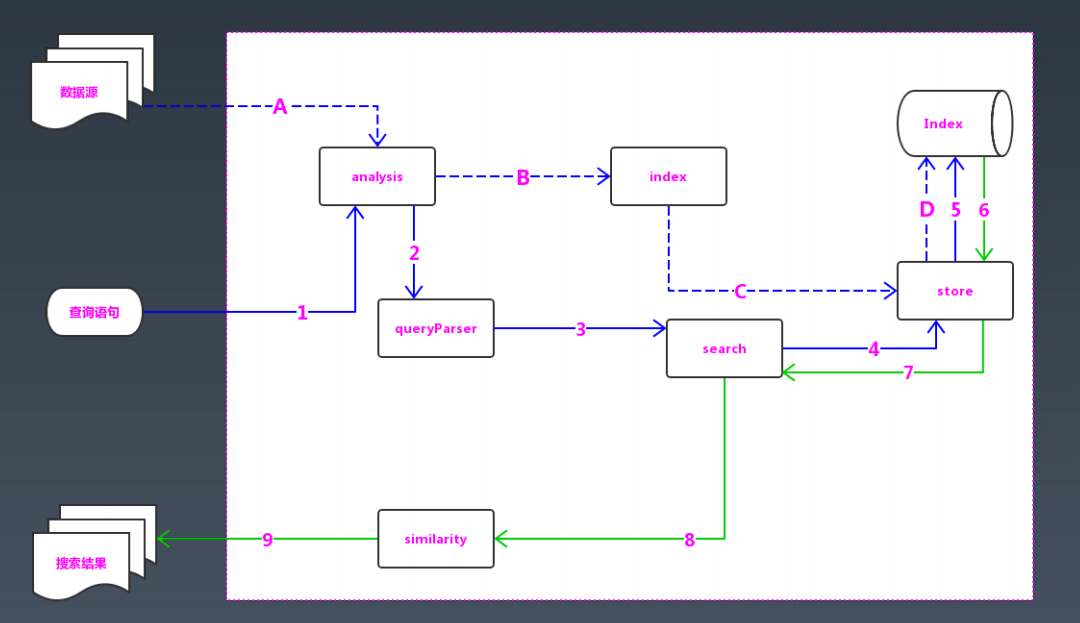
Lucene 架构
Lucene 索引文件准实时更新
索引有更新,就需要重新全量创建一个索引来替换原来的索引。这种方式在数据量很大时效率很低,并且由于创建一次索引的成本很高,性能也很差。
Lucene 中引入了段的概念,将一个索引文件拆分为多个子文件,每个子文件叫做段,每个段都是一个独立的可被搜索的数据集,索引的修改针对段进行操作。
新增:当有新的数据需要创建索引时,原来的段不变,选择新建一个段来存储新增的数据。
删除:当需要删除数据时,在索引文件新增一个 .del 的文件,用来专门存储被删除的数据ID。当查询时,被删除的数据还是可以被查到的,只是在进行文档链表合并时,才把已经删除的数据过滤掉。被删除的数据在进行段合并时才会被真正被移除。
更新:更新的操作其实就是删除和新增的组合,先在 .del 文件中记录旧数据,再在新段中添加一条更新后的数据。
为了控制索引里段的数量,我们必须定期进行段合并操作
ElasticSearch 架构
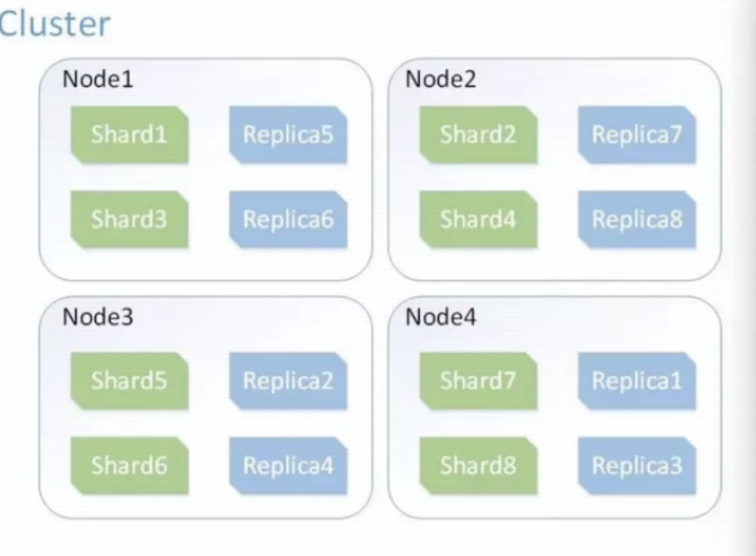
索引分片,实现分布式
索引备份,实现高可用
API 更简单、更高级

还未添加个人签名 2018.01.08 加入
还未添加个人简介









评论