

互联网架构演化
解决的核心问题:高并发
应对互联网高并发的用户请求,要求不断增加计算资源。技术方案两条思路:
垂直伸缩:提升单一服务器的计算能力
水平伸缩:单一服务器计算能力不增强,增加更多服务器,
提升计算能力,应对高并发挑战
现代互联网采用的通用技术方案:水平伸缩----分布式系统
分布式系统是如何设计的?这些服务器如何增加到一个分布式集群中呢?增加进集群的服务器承担什么样的角色?服务器之间的关系是什么?分布式系统经历的怎么样的变化过程?
分布式系统架构演化:
前提假设:应用服务器最高可支持500并发,数据库服务器最高可支持100并发
0阶段:最简单的互联网应用架构
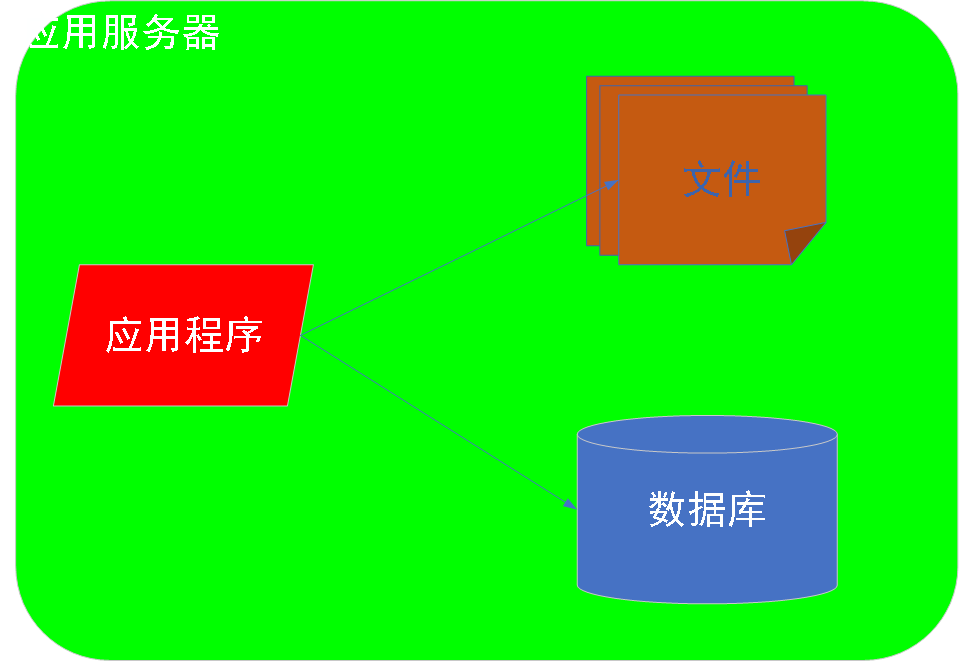
解析:业务比较简单,用户比较少,未来的前景发展不明确---不敢投入过多的资源。
简单架构,开发出简单应用,部署到服务器,看看早期的用户反馈是什么样子的?
如果用户反馈良好(100并发),用户迅速扩散开来,更多的用户访问系统(500并发)。
问题:50并发 =>250并发,服务器反应缓慢:
数据库进行查询操作时,应用程序同时对外处理用户请求计算,这样应用程序和数据库争用CPU资源,争用内存资源,争用IO资源(硬盘)。
同理,文件系统对文件进行读写时,应用程序同时对外处理用户请求计算,应用程序和文件系统争用CPU资源,争用内存资源。
==>应用程序,数据库系统,文件系统三方争用CPU,内存,磁盘等资源。
==>资源争用,导致服务器资源耗尽。
==>当500并发用户访问系统时,因为服务器资源不足,导致响应延迟,甚至服务器崩溃。
焦点:三方争夺资源
方案:数据库系统和文件系统分别部署到不同的服务器,独立独占服务器资源。
1阶段:应用和数据分离
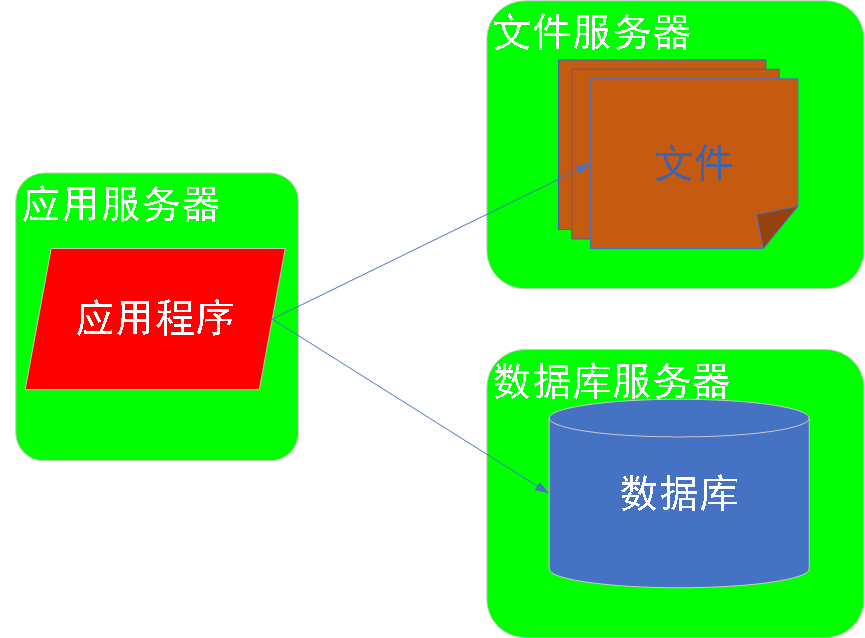
解析:数据库和文件分别部署到不同的服务器上,一台服务器拆分为三台服务器:
文件服务器:文件系统部署一台服务器
数据库服务器:数据库系统部署一台服务器
应用服务器:应用服务部署一台服务器
===>组成了一个比较简单的服务器集群,这个服务器集群对外提供服务。
效果:提供的三倍的计算资源---文件系统,数据库系统,应用程序不再争用CPU,内存,磁盘,各自使用自己服务器资源。
==>集群的处理能力,增加三倍
==>处理的并发用户数,增加三倍
评估:最小的代价(数据库访问localhost更新为IP),换来计算机处理能力的几倍提升==>并发请求数的提升。
互联网架构的核心思路:不断增加服务器,提升服务器的处理能力,增加的服务器分摊一部分现有计算的资源要求和计算需求,
使一部分计算移动转移到其他服务器,减轻当前服务器或者系统的计算压力==>集群获得更高的并发处理能力,服务更多的用户
发展:并发数从250上升到500时,逐渐逼近应用服务器上限
问题:1.数据库服务器最高支持并发100 < 应用服务器并发数500 ==> 假设50%并发请求访问数据库,则500*50%=250并发请求访问数据库。
2.IO低速:数据库读写,是磁盘IO操作(数据文件存储在磁盘上,磁盘低速设备),速率相对应用服务器的CPU和内存来说,要慢很多,
====>数据库成为500并发时的瓶颈,根本原因在于:数据库IO,磁盘速率低==数据库服务器和应用服务器速度不匹配
改进焦点:速率不匹配(应用服务器<====>数据库服务器)
改进方案:引入缓存(应用服务器<==>缓存<==>数据库服务器)
2阶段:使用缓存改善系统性能
高速设备和低速存储设备之间,使用高速的存储服务,即缓存服务,解决速度不匹配的问题。
数据存储在硬盘上,硬盘访问速度比较慢,把频繁访问的数据存放在缓存中。
访问时,先到缓存中访问,如果有,直接返回;
如果没有,再到数据库或者文件系统访问,获取数据后,写入到缓存中。下次访问相同数据时,从缓存中获取。
这些热点数据是从内存中获取的,内存的访问速度,要高于硬盘访问速度。
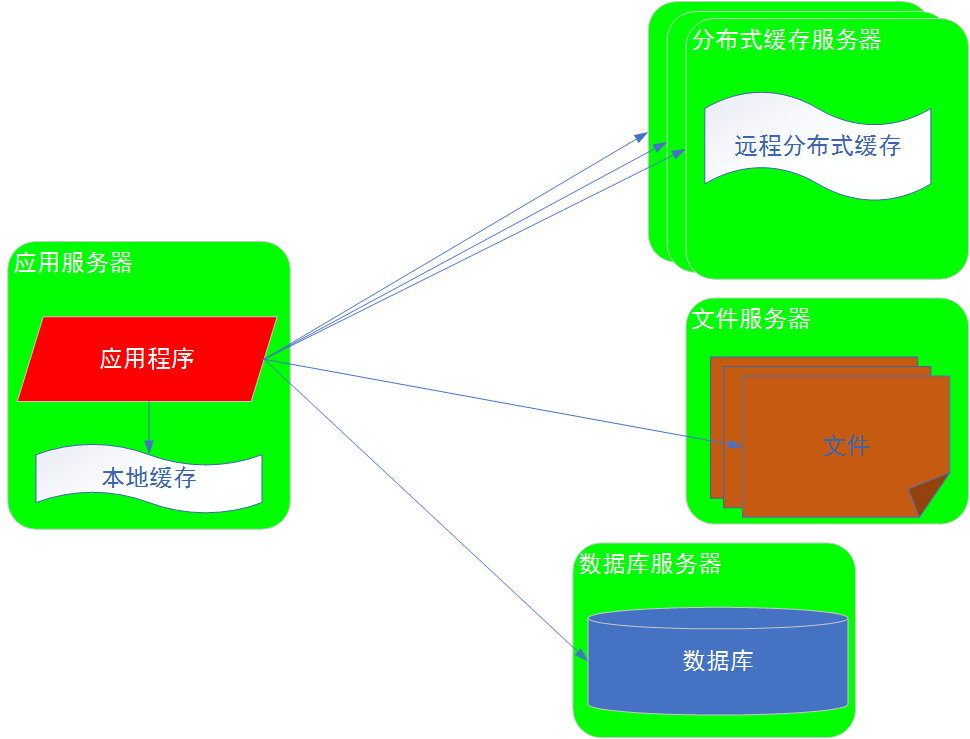
互联网架构缓存:
本地缓存:
远程缓存(分布式):可以构建分布式的缓存服务器集群--有多台缓存服务器,共同存储我们想要的数据,构成集群,提供更大的数据存储能力。
效果评估:
加快了数据访问速度
缓存存储通常是计算后的结果,不需要再次计算,就可以直接得到结果,节约了CPU时间,降低数据库或者文件系统的压力,使数据库或者文件系统能够处理更迫切的一些其他服务。
====>整个系统的处理能力进一步提升,能够处理更高的并发用户数,可以服务更多的用户。
====>量化:应用服务器可以达到并发上限500,读压力主要在缓存上,数据库和文件系统压力相对较小。
发展:并发请求500->5000
单台应用服务器并发请求达到上限,单台应用服务器不能满足5000并发的用户连接。
焦点:高并发时,应用服务器瓶颈。
方案:增加应用服务器,构建应用服务器集群。
3阶段:使用应用服务器集群改善系统的并发处理能力
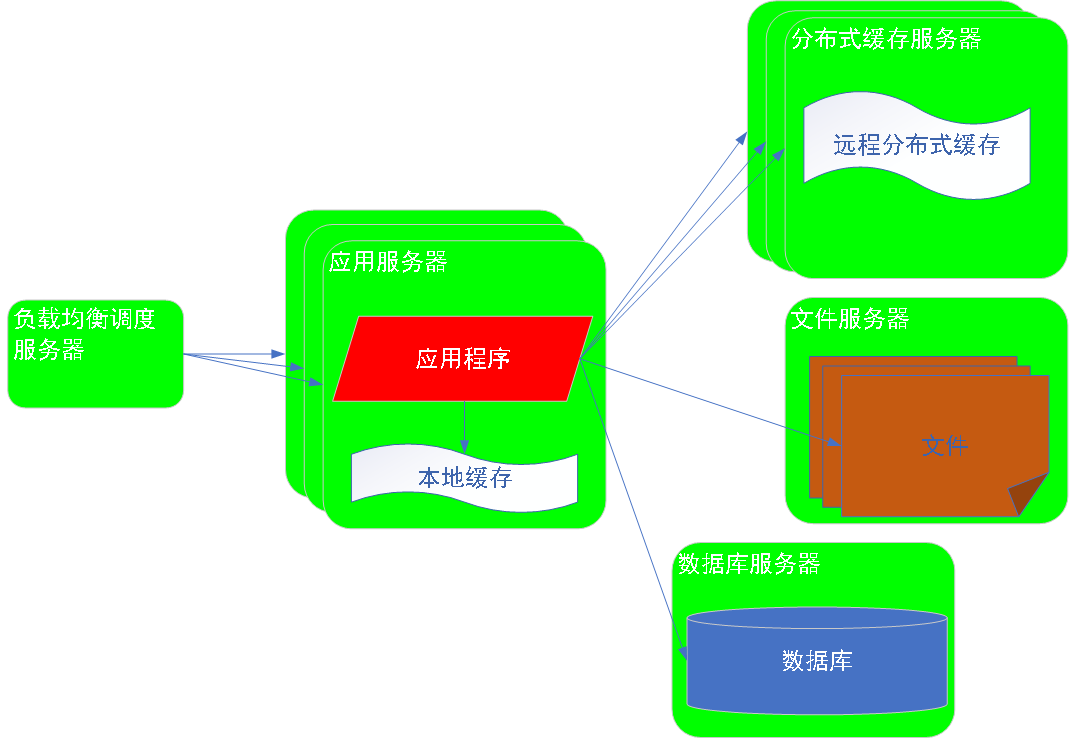
解析:
使用负载均衡服务器,将用户请求分发给不同的应用服务器,每个应用服务器处理一部分用户请求。
高并发用户请求,分发给集群中的若干台服务器上,每台服务器只处理高并发的用户请求中的一部分。
==>高并发请求,分摊在多台应用服务器上,每台服务器处理的并发数并不高,但是整个集群,整个系统能处理的并发数就比较高。
发展:并发请求逼近5000
问题:应用服务器集群可以处理5000并发,假设80%的并发读请求(5000*80%=4000)可以被缓存集群处理;但是仍然有20%的并发读操作(5000*20%=1000),和全部的并发写操作,到达数据库,数据库访问速率比较低。此时,数据库再次成为整个系统并发处理瓶颈。
虽然有很多的应用服务器,可以处理很多的并发用户请求,但是需要等待数据库的处理结果,而数据库如果处理速度比较慢,应用服务器里面的线程不得不阻塞等待数据库的返回结果,==>部分用户请求超时,更糟糕的情况,大量请求超时,系统感觉就像崩溃。
焦点:解决单一数据库服务器压力。
方案:主从分离(读写分离)。
4阶段:数据库读写分离
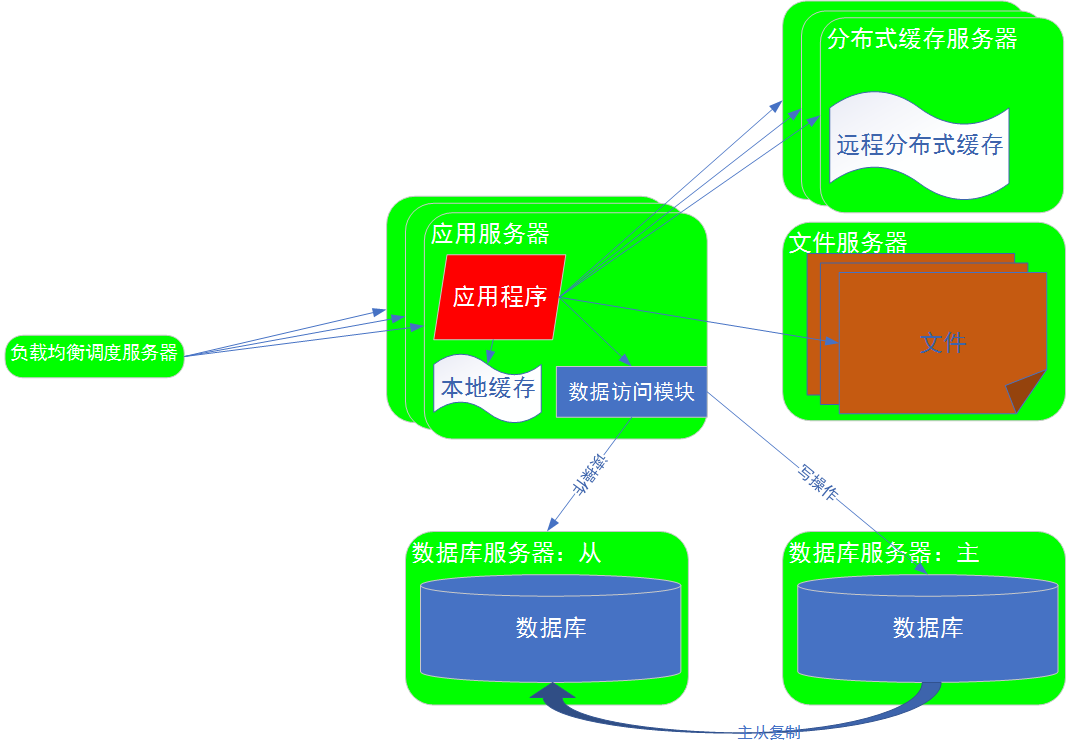
解析:数据库部署为一个主服务器,一个从服务器,实现读写分离。
写操作:写数据时,写入数据到主数据库,然后主从复制,复制数据到从服务器;
读操作:读数据时,从服务器上读取数据。
====>目的:减轻主数据库的压力。
效果:数据库处理能力近似提升一倍。通过数据库的读写分离,提升数据库的处理能力,降低数据处理对整个系统造成的影响,以此来提升整个系统的并发处理能力。
5阶段:使用反向代理和CDN加速网站响应
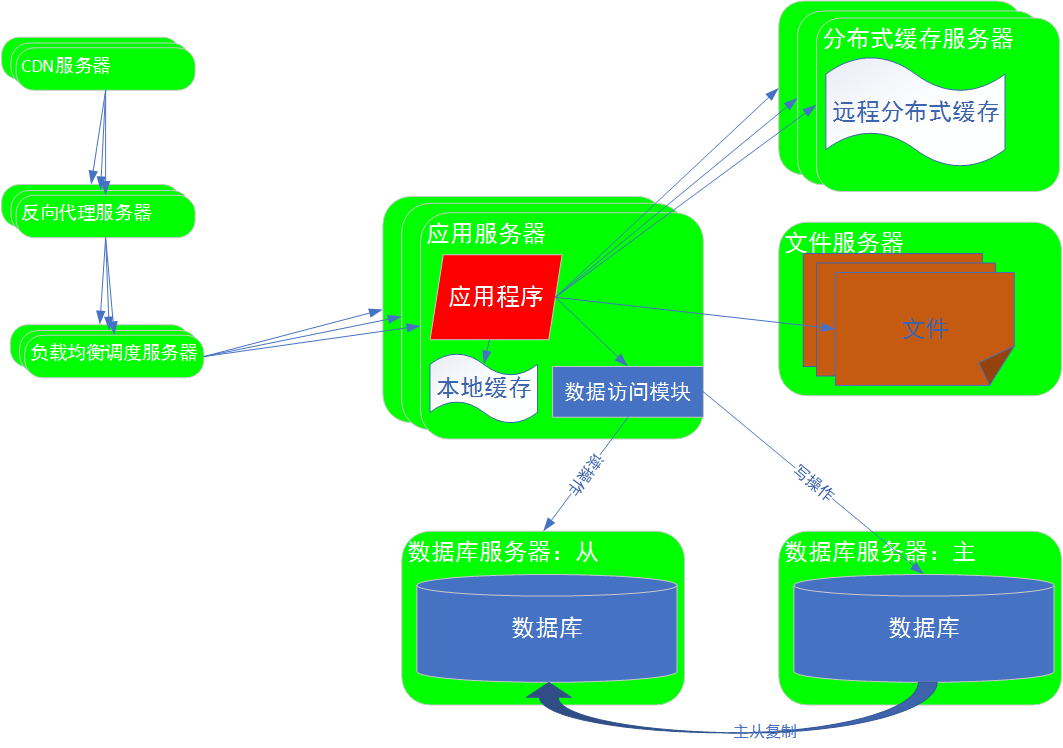
CDN:
内容分发网络(content distrbution network)-----部署在各个网络运营商机房里面的缓冲服务器----通常情况下,CDN服务器里用户最近。
工作原理:用户请求通过网络通信,首先到达网络运营商机房的CDN服务器,可以首先在CDN服务器本地缓存中查询有木有想要的数据,如果有,可以直接返回。
==>可以把部分资源缓存在网络运营商机房的CDN服务器,加速请求响应。
==>缓存的内容通常是静态资源,比如:图片,CSS,JS
示例:淘宝商品查看
用户查看淘宝商品,发起请求
请求通过网络通信到达网络运营商机房的CDN服务器:查询CDN服务器本地缓存的商品图片(CDN缓存img,css,js),如果有商品图片信息,请求直接返回。
效果:用户请求在CDN服务器已经得到处理,加速了请求响应。因为:用户请求还没到达最终目标机房,就已经得到处理。
访问速度更快
对整个网站系统的压力更小---请求不需要到达网站所在机房,在网络运营商CDN服务器端直接就返回。
==>网站系统节约更多的资源==>使用节约的资源,处理更多的并发用户请求==>网站系统能够处理更高的并发用户请求
CDN集群:
大型网站(比如:淘宝,天猫,京东等)会在网络运营商(比如:移动,联通,铁通,电信等)的机房里建立CDN集群,缓存静态资源(图片,视频等),就近服务用户 , 加快访问速度。
80%~90%的网络流量来自于图片视频等静态资源,CDN可以响应80%的网络请求。真正到达淘宝机房的网络流量很少。
如果CDN中没有要请求的数据,请求被继续向下分发到目标机房(比如:淘宝机房)的反向代理服务器,(反向代理:代理整个机房对外提供服务),反向代理查询本地缓存数据,如果有,则直接返回。
如果没有要请求的数据,请求被继续向下分发的负载均衡服务器==>应用服务器==>计算处理。
CND集群和反向代理集群:
可以处理80%左右的大部分请求
少量请求会到达应用服务器。
==>系统整体处理能力增强
==>系统并发处理能力得到大幅提升
发展:并发请求逼近50000
焦点:主库写操作,成为整个系统瓶颈----海量数据---主库存不下一张数据表(表的数据量达到千万级,亿级,亿万级)
方案:分布式数据库
6阶段:分布式数据库和分布式文件系统
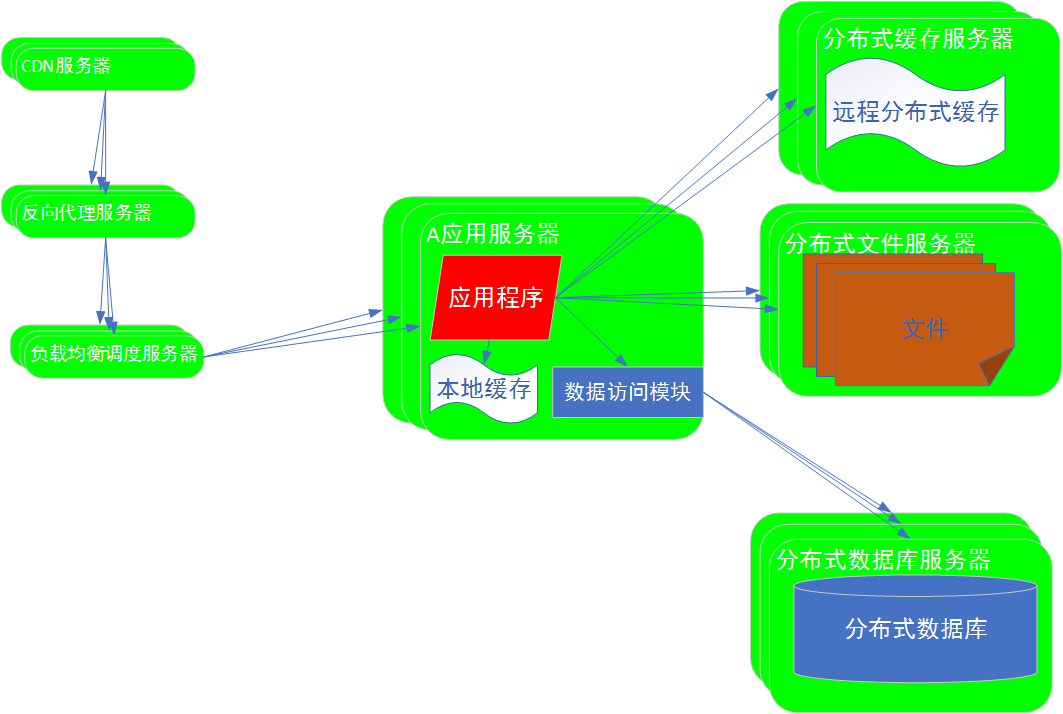
解析:
数据库主从复制:
处理能力的提升是有限的。
存储能力并没有得到提升。主库和从库存储的数据时一样的。
写操作,只能写在主数据库上。==>“写操作”只能在一台服务器上来完成。
假设:
1.存储数据非常多,达到几十亿,几百亿条记录,如果存储到一张数据表上,可能一台服务器无法完成一张数据表的存储。
==>单一服务器无法存储一张表。
2.大量并发写操作,单台服务器无法满足要求。
解决方法:分布式关系数据库
将数据库进行分片处理。比如:十亿条记录,分布在100台服务器上,每台服务器存储1千万条记录。100台服务器构成分布式数据库集群,共同对外提供服务。用户的写操作分摊在一百台服务器上进行处理,数据存储也存储在一百台服务器上,存储能力提升100倍。写操作的并发处理能力提升了100倍。整个系统的并发处理能力得到提升。
当要存储更多的数据的时候,只需要增加更多的分布式数据库服务器。
同理:
分布式文件服务器集群:
将文件分布在一个服务器的集群上,每个服务器上存储一部分的文件,整个集群存储更多的文件。将文件存储的压力分布在了多台服务器上。构建分布式服务集群。整个系统对文件的读写能力得到极大提升。
当有更多的文件需要存储的时候,只需要增加更多的分布式文件服务器
7阶段:使用NoSQL和搜索引擎
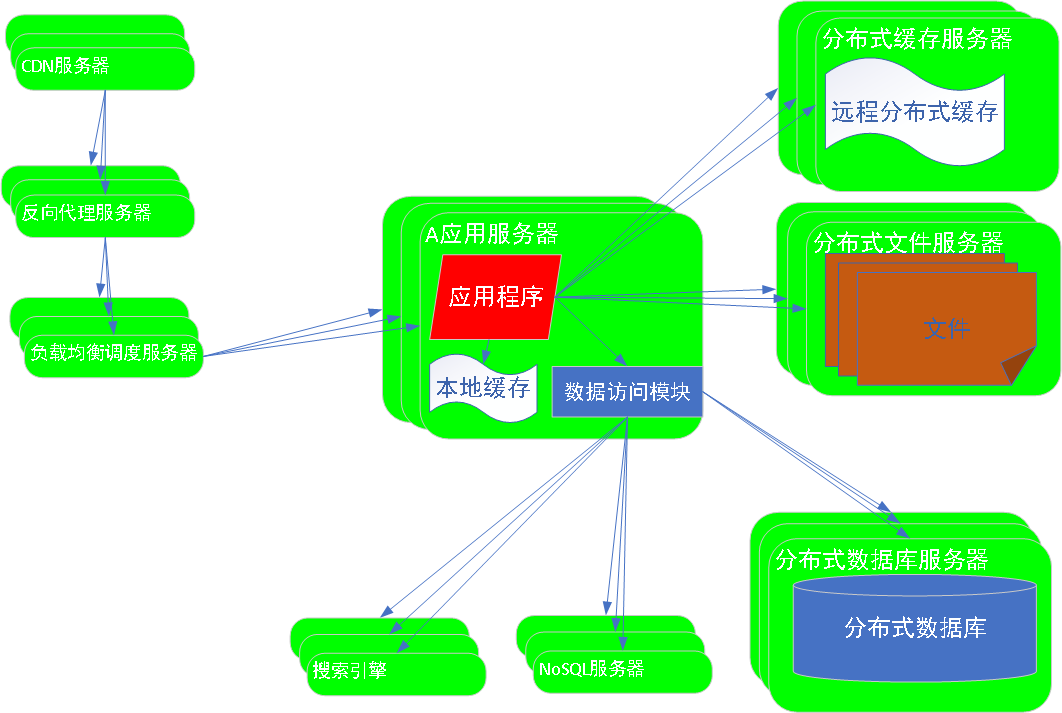
解析:
1.特殊应用场景---关系型数据库无法满足 ==> 使用NoSQL处理非关系型数据 ==>提升数据存储能力
2. 复杂查询操作,处理操作比较慢 ==> 使用搜索引擎完成复杂数据查找==>提升数据查询速度
8阶段:业务拆分
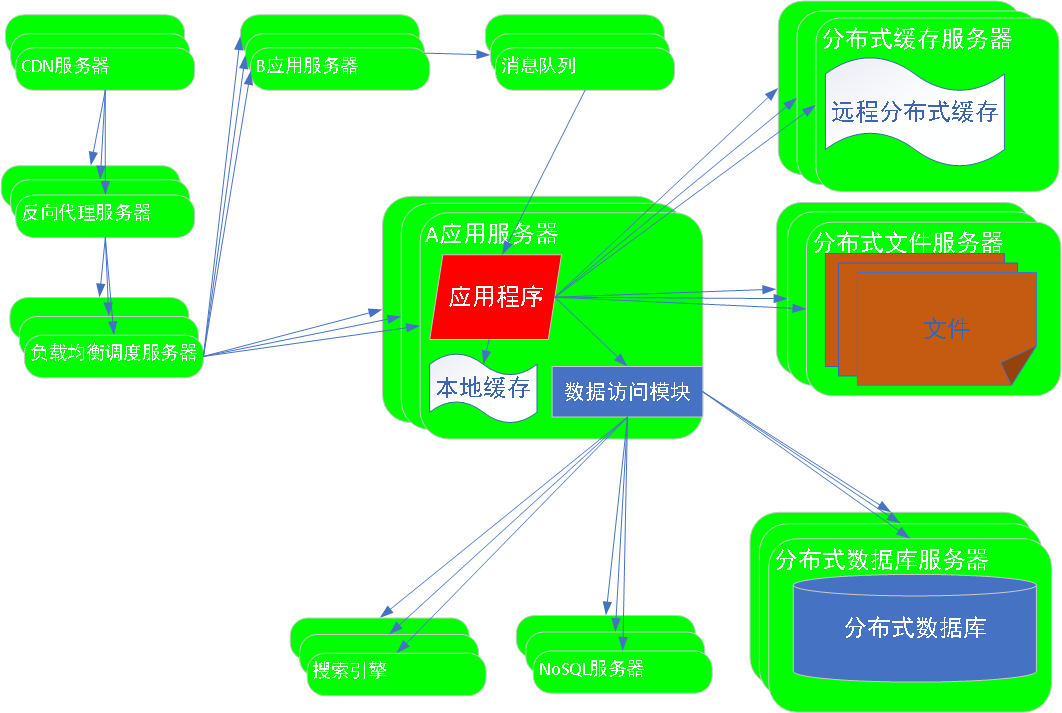
解析:业务功能提出了更多的需求
==>业务越来越复杂
==>功能模块越来越多
==>代码量越来越多
==>系统变得非常庞大
解决方法: 拆分业务。
电商业务拆分:卖家,买家 拆分为不同的应用,部署到不同的应用服务器。
进一步拆分:搜索服务,商品列表服务,商品详情服务,购物车服务,订单服务,支付服务等拆分为不同的业务,部署到不同的服务器。
同步通信:不同应用之间,可以通过RPC方式同步通信,也可以通过消息队列方式异步通信。
异步通信:B应用推送消息到消息队列,A应用从消息队列中获取消息。AB应用,通过消息队列接触耦合。==>实现业务的拆分和依赖。
效果:
拆分后,开发和维护变得更加简单
应用部署在不同的集群上,扩容或者伸缩更加灵活
业务处理能力得到提升,
业务发展更加灵活快速
9阶段:微服务及中台化
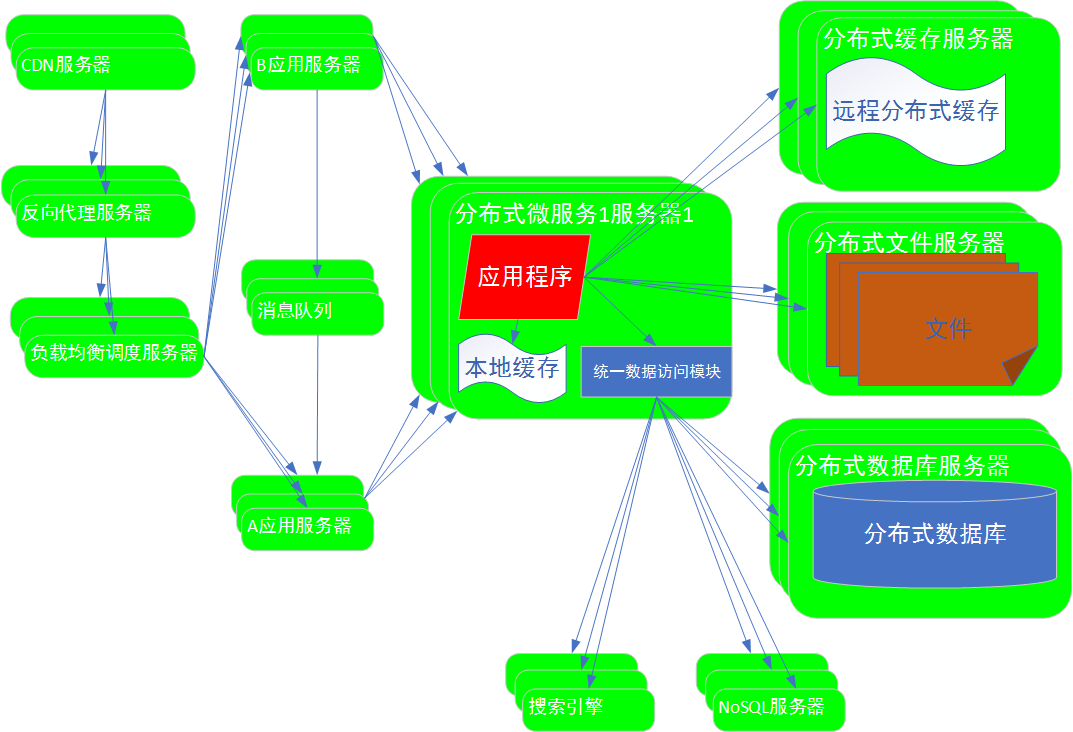
示例:电商中的搜索列表,详情,购物车,订单,不同的应用,依赖用户服务,商品服务等公共服务。
问题:这些功能服务如果在每个应用服务器中都部署,都分别开发,成本比较昂贵,比较复杂
解决办法:公共服务拆分出来,构建一个独立的微服务器集群。公共服务部署到微服务集群,对不同应用提供服务。
A应用需要用户服务时,就会调用用户的微服务服务集群;当需要商品服务时,就调用商品的微服务服务集群。
中台化:微服务集群==>中台化
微服务是目前互联网架构中主要架构模式,
微服务关注点:
1. 微服务本身如何设计---DDD
2. 微服务之间调用如何完成---同步异步
3. 微服务之间的依赖关系如何设计。
4. 微服务如何建模
10阶段:大数据与智能化

还未添加个人签名 2018.05.02 加入
还未添加个人简介










评论