scrapy 学习之爬虫练习平台 3
本文首发于个人博客,文章链接为:https://blog.d77.xyz/archives/6f6e2126.html
前言
上一篇文章爬取了爬虫练习平台的 spa 部分,有 Ajax 和接口加密,没有涉及到登录,都是 GET 请求。
本篇文章继续爬后面的 login 部分,涉及到了登录和验证。
环境准备
考虑到抓取数据字段的多样性,本次爬取将数据库换成了 Mongo,不需要每次都新建字段,加快抓取速度。
新建一个名为 test 的数据库,其他环境和设置不变。
开始爬取
login1
login1 说明如下:
模拟登录网站,登录时用户名和密码经过加密处理,适合 JavaScript 逆向分析。
是一个需要登录的网站,而且有加密,需要逆向 JS。我提前分析了一下,由于登录之后并没有跳转到实际可以爬取的页面,所以就不写 scrapy 的代码了,只分析登录请求所涉及到的加密算法。

抓包分析,老方法,打开控制台,打 xhr 断点,随便输入账号密码,点击登录按钮,触发登录请求。

断在了老地方 send 方法上,顺着调用栈往上找,找找疑似在构造 data 的地方。
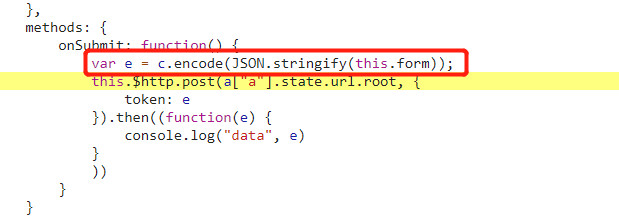
找到了一处,看起来是将 form 表单进行编码后传给 token,然后通过 post 函数发送出去。打断点,重新登录。
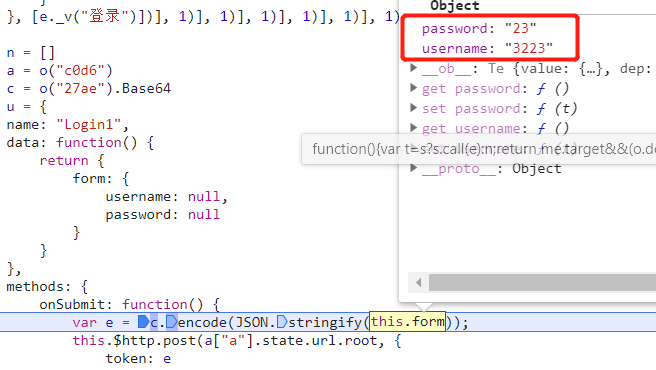
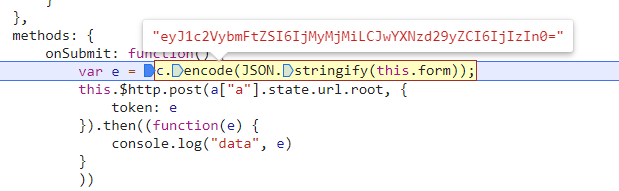
看起来是将随便输入的账号密码传入到 c.encode 这个函数中进行编码之后就得到了 token 参数,单步跟进去看看。
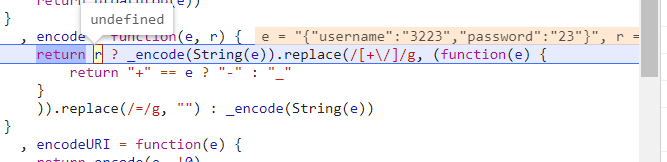
遇到一些 get 方法直接步出就好,直到这里,是一个三元运算符,r 为 undefined,所以会执行下边的 _encode(String(e)) 方法,单步往下走。
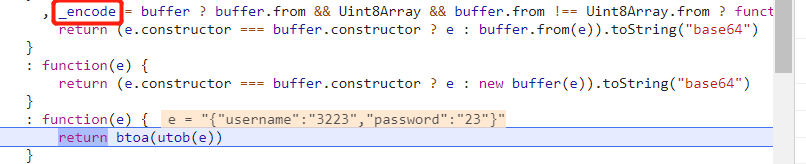
到了这里,往上看,_encode 也是个三元运算符,还是好几个嵌套的那种。utob 函数只是进行了正则替换,真正的编码函数是 btoa 函数,单步进入。

调用了系统的 btoa 函数,而 btoa 函数就是用来将字符串进行 base64 编码的。
所以,结论就是,账号密码被 base64 编码后赋值给了 token,然后提交给了服务器,代码如下:
代码中用的是 GET 请求(因为 GET 请求才可以成功获取服务器响应),但是在网页上用的是 POST 请求,实际测试发现 POST 请求服务器会返回 405 错误,猜测可能是后端服务没有指定请求方式的原因,不指定的话默认只接收 GET 请求。🤣🤣🤣
其实如果有点经验的人可以更快的解决问题,因为看到 token 这种大小写加数字的字符串基本上都会试一下 base64,如果不行的话再尝试逆向。
login2
login2 说明如下:
对接 Session + Cookies 模拟登录,适合用作 Session + Cookies 模拟登录练习。
无反爬,需要登录,网页结构和之前的没有区别。scrapy 中起始请求需要改成 POST 请求,并且需要通过表单提交账号密码数据,所以写法要稍微改变一下。完整代码如下:
稍微改变一下写法,在 start_requests 中进行登录动作,scrapy 会自动处理 cookie,所以在回调函数中进行正常的翻页爬取就可以了。后面的代码都是一样的,只是数据库更改成了 Mongo。
完整代码详见https://github.com/libra146/learnscrapy/tree/login2
login3
login3 说明如下:
对接 JWT 模拟登录方式,适合用作 JWT 模拟登录练习。
用到了 JWT,打开控制台开始抓包。

一共三个 xhr 请求,一个登录请求,一个 301 跳转,一个获取数据的请求,先看登录请求。
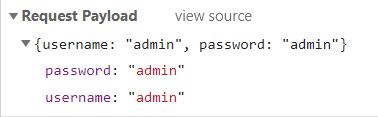
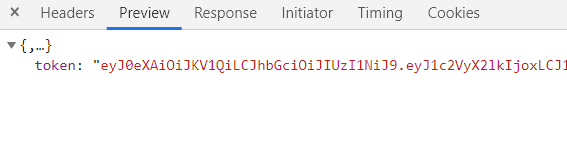
同样的 form 表单提交账号密码,提交后服务器返回了一个超长的 token,看字符串结构(三段式,用两个 . 隔开)返回的是 JWT 没错了。
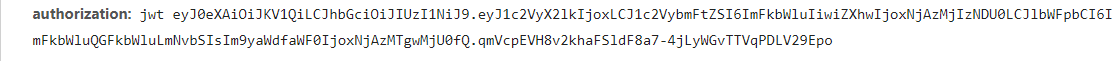
看下一个请求,JWT 被放在了请求头中,按照格式在中间件中修改请求头即可。
和 login2 一样使用 FormRequest 提交表单,在回调函数中解析 JWT,保存起来,然后正常翻页爬取,别忘记计算偏移和更新偏移。
接下来的每个请求都需要在请求头中添加 JWT 参数,所以需要在下载中间件中为每个请求添加请求头,别忘了在设置中启用下载中间件。
设置好一切之后就可以正常爬取了。
完整代码详见https://github.com/libra146/learnscrapy/tree/login3
总结
以上为三个需要登录的网站使用 scrapy 爬取的案例,通过案例可以学习到使用 scrapy 登录的方法和 scrapy 可以自动处理 cookie,并且可以通过中间件来修改每个请求的请求头,其中还有一个网站涉及到了 JS 逆向的内容。
参考链接
https://docs.scrapy.org/en/latest/index.html
版权声明: 本文为 InfoQ 作者【LLLibra146】的原创文章。
原文链接:【http://xie.infoq.cn/article/5efb3d842c9f0493958842a8e】。未经作者许可,禁止转载。

还未添加个人签名 2018.09.17 加入
还未添加个人简介









评论