EasyDL 的数据集、模型与代码的版本管理:灵活管理效率提升
随着人工智能技术赋能各行各业,AI模型开发的流程化、自动化、组件化需求越发迫切。作为AI模型开发持续集成与交付的基石,数据集、模型与代码的版本管理贯穿了模型数据准备、训练与评估、服务部署等几乎所有开发流程。面对数据集的不断更新删补,模型的数次迭代和代码的修改调试,如何让用户能够轻松有序进行不同版本的管理、避免误操作,优化使用体验,不仅是界面需要简洁明了,背后同样需要相应的功能逻辑设计,让用户得以享受到数据集、模型与代码版本的灵活管理,便于回溯与调整。EasyDL基于飞桨深度学习平台,帮助企业级用户高效定制业务专属AI模型,在数据、模型与代码版本管理问题上,提供了稳健灵活的数据集版本、模型版本与代码版本控制系统,支撑数十万用户定制化开发模型与管理代码。
数据集版本管理
在数据管理中,采集、清洗与标注等功能,用户可以使用EasyDL中的EasyData智能数据服务平台进行。EasyData是百度大脑在今年4月推出的业内首个提供软硬一体、端云协同的智能数据采集服务的平台。在数据采集上,支持从摄像头直接采集图片数据,通过平台提供的SDK直接上传,也支持通过云服务接口采集数据;在数据标注上,预置了丰富的标注模版,支持智能标注;在数据清洗上,支持去模糊、去重复、批量剪裁与旋转功能,覆盖了数据管理的各种需求,帮助用户减轻数据处理负担,并且支持无缝对接到EasyDL,直接使用处理好的数据进行训练。在上述丰富的数据功能之外,还有不容小觑的数据集版本管理功能。
在面对数据集的版本管理问题上,许多开发者表示,既希望能够灵活修改数据集,方便模型的训练迭代;也希望能够保证训练数据集具有相对稳定性,不会因为误操作,如增减数据而发生变化,以此保证产出的结果具有可以复现,再次验证。这两个需求看似矛盾,在实际应用中却非常普遍。为解决这一对问题,EasyData平台引入了数据集的版本管理。
在EasyData中,各个版本的数据是通过“数据集组”来管理的。在同一个组中,数据的类型需要保持一致,即需要都是图片,或都是文本。在新增数据版本的时候,可以选择从数据组中已有的版本中继承数据,也可以选择创建全新版本自己导入新数据。如下图所示,在实际使用中,各个数据版本之间的关系是一个有向图,EasyData的后台也记录了各个版本之间的关系,可以很容易地进行回溯生成历史。
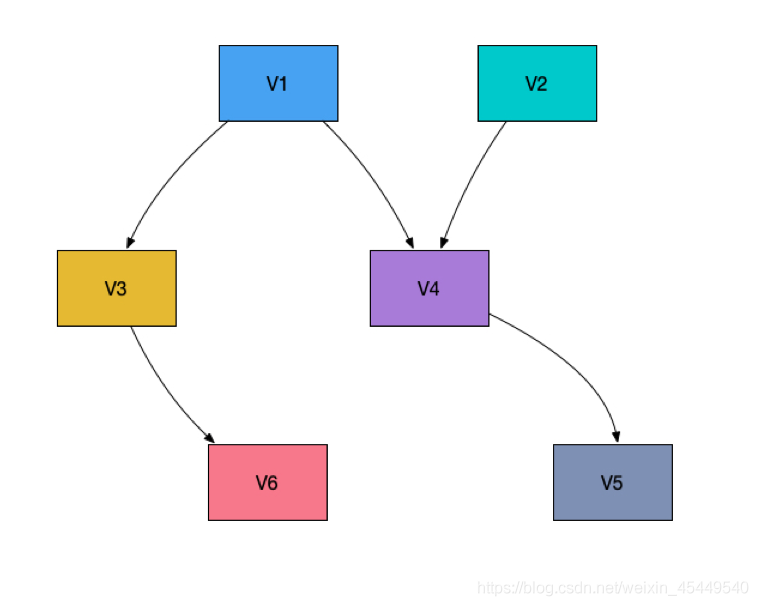
其中,“发布”是一个很重要的概念。在EasyData中,数据集可以有两个状态:已发布与未发布。数据一旦发布,其属性将不可变,用户不能对该版本的数据进行增删改操作。这一动作可以帮助模型进行复现,使用同一个已发布的数据版本,总能训练出效果相对一致的模型。发布的版本保障了数据的稳定性,同时也为用户的数据回滚提供了便利。用户也可以通过继承发布的版本来生成新的数据集,倘若因为错误操作,误删了很多实例样本,这时完全不用为删除的实例样本捶胸顿足,因为EasyData依然支持从发布版本中重新导入数据。与发布版本对应的是未发布版本,这一版本允许用户对其进行各种修改,可以灵活地处理数据,进行标注、清洗等操作。


数据集的发布与否,用户可以根据自己的需求自行选择。如果用户希望能够固化自己的数据集,通过已经固定的数据集获得稳定的训练模型,可以选择将数据集进行发布,此后不能对数据集进行更改。而如果用户希望能够不断对现有数据集进行增添、删除,或对数据进行标注、清洗等行为来达到优化模型效果的目的,可以选择使用未发布版本训练模型。已发布与未发布的数据集,也都支持直接通过【去训练】按钮进入EasyDL平台进行模型训练,也均可通过EasyDL进行查看。
模型版本管理
在结束数据的管理之后,用户可以通过EasyData中的“去训练”按钮跳转到EasyDL进入模型训练等步骤。
在缺乏模型版本管理的开发流程中,任何版本相关的问题都会拖垮开发效率:算法工程师往往难以追溯历史模型网络结构与对应的训练代码和模型超参,陷入模型效果难以复现的尴尬境地;在特定版本模型与特定版本预测代码引发模型推理失败时,原因定位和排查极为困难;此外,当一个模型在多个系统和平台流转时,难以统一模型版本容易导致冗余的模型存储和严重的业务模块耦合。
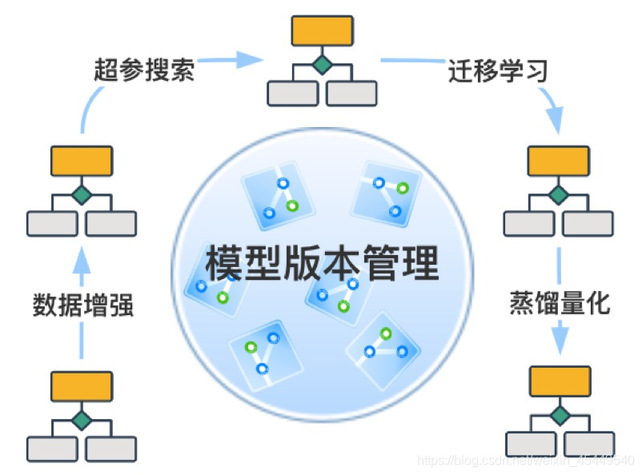
针对以上提到的问题,EasyDL模型版本管理能够做到对模型迭代流程生命周期的一站式、全覆盖追踪,包括模型的效果优化、蒸馏、量化、剪枝等各类迭代变更历史。EasyDL对模型迭代版本统一管理,以可拔插的方式支持百度云BOS对象存储、HDFS等多种存储系统;跟踪模型生命周期的资源和元数据,方便模型溯源和效果复现;支持模型、数据、代码的关联关系维护,并允许自定义模型元数据信息;支持自动识别并可视化模型网络结构,能够有效降低算法开发成本。
代码版本管理
对于有一定深度学习基础,希望对模型进行代码级修改的用户,在缺乏代码版本管理的开发流程中,代码版本相关的问题同样严重影响开发效率:训练代码需要用户手动从外部导入,或选择平台有限的几份预置代码,灵活度不够;代码的改动没有版本控制,用户无法对代码进行回溯、比对,从而无法记录代码的改动对模型训练效果的影响。
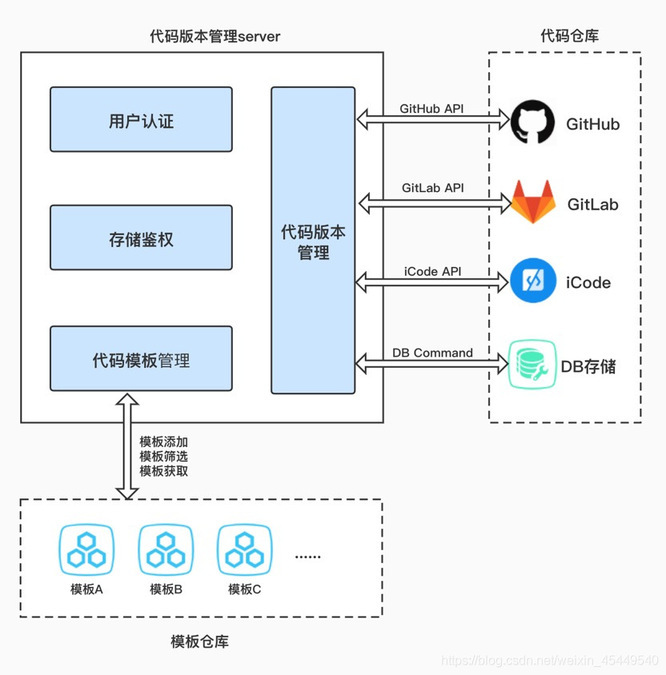
EasyDL代码版本管理支持用户级的训练代码模板的发布、获取、筛选等操作,方便用户快速匹配到所需的训练代码并导入;在开发过程中,用户每一次的代码提交会生成一个代码版本,记录了此次代码提交所做的修改,后续能够查询用户在对应项目下的代码历史提交记录,并可以对代码进行回溯、比对;可以将特定版本的代码关联到特定版本的数据与模型,帮助开发者提升开发与部署效率。
EasyDL代码版本管理的内部存储分别对接了GitHub、GitLab等主流代码仓库及公司内部的Icode,用户无需登录上述代码仓库,即可直接在平台上对上述仓库中的代码进行操作;对于无需对接上述代码仓库的用户,支持以DB的方式为用户建立平台内部代码库存储,灵活度较高。
在模型开发的全流程中,无论是数据准备、模型迭代、代码修改,用户会从多个角度对模型进行调整,以获得更优秀的模型效果。使用EasyDL平台的开发者可以对于不同环节中产生的多个数据集、模型与代码版本,通过进行精细化的管理,简便地进行回溯比对与错误定位。灵活高效进行业务AI模型的定制与开发,快速解决业务问题。
立刻尝试EasyDL:https://ai.baidu.com/easydl/

用科技让复杂的世界更简单 2020.07.15 加入
百度大脑是百度技术多年积累和业务实践的集大成,包括视觉、语音、自然语言处理、知识图谱、深度学习等 AI 核心技术和 AI 开放平台。 即刻获取百度AI相关技术,可访问 ai.baidu.com了解更多!









评论