技术选型之缓存、队列、负载均衡
缓存
缓存是介于数据访问者和数据源之间的一种高速存储,当数据需要多次读取的时候,用于加快读取的速度。缓存一般采用哈希表来存储,哈希表本质是一个数组,根据首地址和偏移量(也即 key 的 hashcode 对数组长度取模)即可快速读取。而我们在使用缓存的时候,命中率是我们衡量缓存效果好与坏的关键指标,影响命中率的因素有如下几个:
缓存键集合大小:键数量越小,命中率越高
缓存可使用内存空间:物理上能缓存的对象越多,命中率越高
缓存对象的生存时间:缓存对象时间越长,命中率越高
缓存可以分两类:一类是通读缓存,即给客户端返回缓存资源,并在请求未命中缓存时获取实际数据,客户端连接的是通读缓存而不是生成响应的原始服务器,如代理缓存、反向代理缓存、CDN 都属于通读缓存。另一类是旁路缓存,旁路缓存通常是一个独立的键值对存储,如浏览器缓存、本地对象缓存、分布式对象缓存。
我们在使用分布式缓存的时候,常常需要考虑伸缩性的问题,比如增加一个节点或者下掉一个节点,怎么来保证较高的命中率。如果我们采用 hash 取模的方式路由到缓存节点,当增加一个节点的时候(如从 3 台增加到 4 台),会有 75%的键都会失效,这是不能忍受的。所以提出了一致性 hash 的解决方案,将节点 hash 值放到一个一致性 hash 环中,然后 key 也算出 hash 值在同一个一致性 hash 环中顺时针寻找最近的一个节点,如下图所示
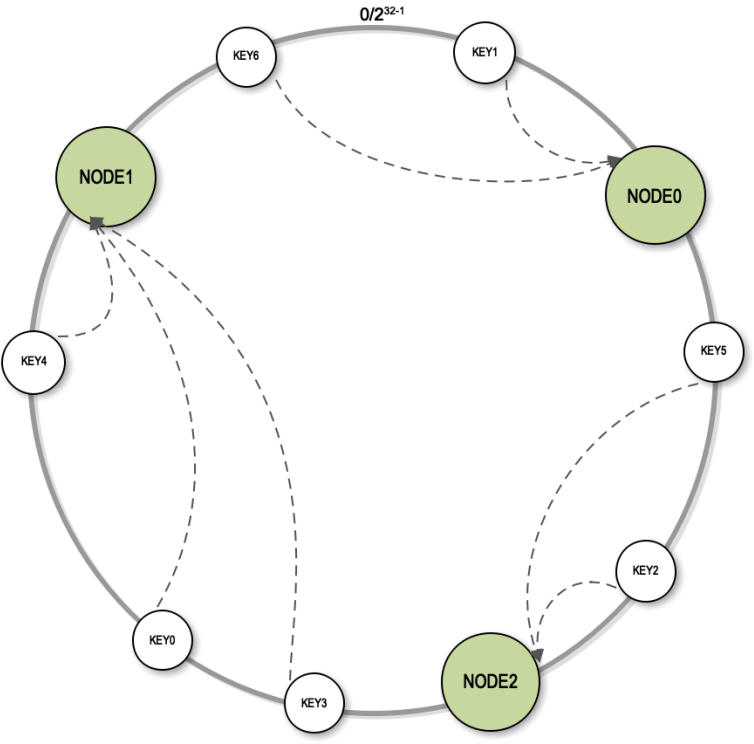
这样的话,当节点从 3 台扩到 4 台,只会有 25%的键失效,如下图所示
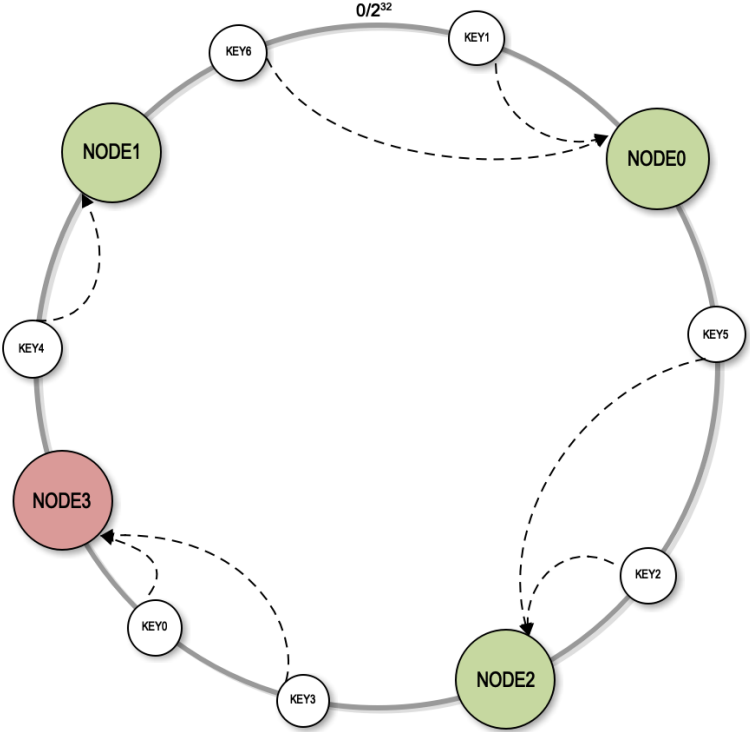
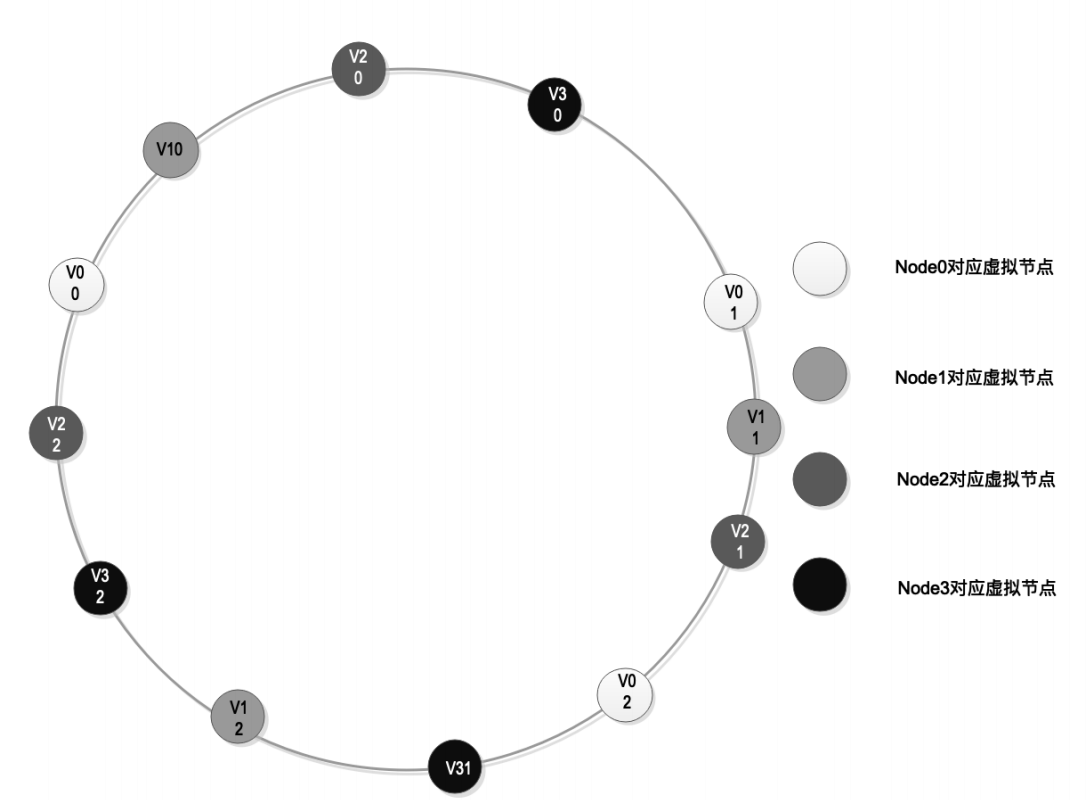
但是一致性 hash 也会存在一个问题,就是数据倾斜,比如节点 1 承载了太多数据,而节点 2 承载的数据比较少,这个时候又提出了虚拟节点的解决方案,就是每一个实际的节点都会映射 100 甚至 200 个虚拟节点,虚拟节点也会放在同一个 hash 环中,这样就能保持数据均衡,解决数据倾斜的问题。如下图所示:
缓存是我们提升系统性能的银弹,但是使用缓存也会带来很多问题:
无热点访问:缓存大量无效 key,浪费存储。
数据不一致:因为缓存会有失效时间,会因为缓存更新不及时,所以必然会带来数据的不一致。
缓存雪崩:当缓存服务崩溃的时候,会导致数据库崩溃,进而导致所有服务不可用。
缓存穿透:当某个 key 不存在时,而客户端又频繁的访问这个 key,就会导致所有请求都会回源。
缓存击穿:当某个 key 失效后,大量请求会访问这个 key,会导致数据库压力过大。
消息队列
消息队列是一种进程间通信或同一进程的不同线程间的通信方式。消息队列主要采用先进先出的队列这种数据结构,生产者生产消息往队列里放,消费者从队列里消费消息。
消息队列的两种模式,一种是点对点模型,生产者生产消息放到队列中,只有一个消费者能够消费这条消息。另一种是发布/订阅模型,生产者将消息发布到 topic 中,订阅了这个 topic 的消费者都可以消费这条消息。而目前的消息中间件基本上都采用了发布/订阅模型。
消息队列带来的好处:
异步,提升性能。比如写多的应用,可以将请求先写入队列,然后消费者消费后写入存储系统,典型的比如开源产品中 Skywalking 在接收到打点数据后写入 ES 之前就采用消息队列来做一层处理。
解耦,比如注册用户后,需要给用户发送激活邮件。当用户数据写入库后,直接发一个消息出去。由邮件系统消费消息后发送邮件给用户。这样即使邮件系统有问题,也不会导致用户注册失败,只不过邮件会晚点发出来,所以系统之间不会强依赖。
限流削峰,比如秒杀抢购的场景,避免流量过大导致系统挂掉
消息驱动架构
常见 MQ 产品比较
RabbitMQ:性能好,社区活跃,但使用 Erlang 开发,不利于维护。
ActiveMQ:遵从 JMS 协议,跨平台,Java 开发。但社区活跃度不高,会丢消息。
RocketMQ:阿里开源,性能好,可靠性高,Java 开发。
Kafka:LinkedIn 出品,分布式伸缩性好,Scala 开发。不利于过多的队列。
负载均衡
负载均衡是用来在在多个计算机、网络或者其他资源中分配负载,以达到最优资源使用,最大化吞吐量,最小化响应时间,同时避免过载。在互联网架构中主要是用来提高性能和可用性,通过负载均衡将流量分发到多个服务器,同时多服务器能够消除这部分的单点故障。负载均衡有软件(如 LVS)和硬件(F5)。
负载均衡的实现方案可以分成两个部分,一个是根据负载均衡算法算出要转发的服务器地址;另一个
如何将请求发送到服务器上。
负载均衡的实现方案:
HTTP 重定向负载均衡,有一台单独的服务器来计算真实服务器地址,缺点是需要请求两次。
DNS 负载均衡,在域名服务中配置多个服务器,域名解析的同时进行负载均衡的处理,缺点是真实服务器如果下线,域名服务器不能及时更新,导致访问失败
反向代理负载均衡,直接在反向代理服务器中(如 nginx)完成负载均衡的处理,缺点是反向代理服务器容易成为性能瓶颈
IP 负载均衡,在网络层通过修改请求目标地址进行负载均衡,优点是性能好,缺点是因为响应包都需要经过该负载均衡服务,所以网络带宽会成为性能瓶颈
数据链路层负载均衡,在数据链路层修改 mac 地址进行负载均衡,响应数据可以直接回到客户端,不需要再经过负载均衡服务,所以性能最好
负载均衡算法
轮询:所有请求被依次分发到每台应用服务器上
加权轮询:按照权重将请求分发到每台应用服务器
随机:随机将请求分发到各个应用服务器
最少连接:将请求分发到连接数最少的应用服务器
原地址散列:根据 IP 或者 URL 进行 Hash 取模后的应用服务器
版权声明: 本文为 InfoQ 作者【olderwei】的原创文章。
原文链接:【http://xie.infoq.cn/article/56fe446df6915d9f08964a777】。文章转载请联系作者。

还未添加个人签名 2018.04.26 加入
还未添加个人简介









评论