

平均响应 1000ms 到 200ms,PHP 和 Go 那家强?

可能有点标题党,结果和语言相关度不大,反而有一个有趣的现象,在我们线上环境中,移动端采集的数据在响应时间上并没有明显差异,PHP表现更好。整个过程的体会:
从APP视角出发,全链路是更好体现用户体验的方式
语言之争只是噱头,宏观是建立在大规模微观设计上的,语言能力的发挥基于团队能力和业务特点
300ms和500ms的目标来自行业白皮书
宏观数据的进步都是因为优化了系统级别的关键点
微观数据逃不掉,完整的用户体验需要将慢接口逐个击破
原因且看分析。
先说背景,服务器平均响应时间是个综合指标,体现了业务设计、架构和基础组件的质量。从用户体验出发,我们17年接入了听云(文中所有图示数据均来自听云),从客户端进行用户侧的采集,平均响应这项数据就覆盖了全链路,不只是服务器的内部处理时间,客户端的网络设计和网络链路质量都涵盖在内。
从1s下降到200ms以下,大的阶梯共有四次。
一、httpdns(1s->700ms)
切换为httpdns初衷是为了解决我们在某省非常严重的劫持情况,在使用https后,甚至443端口也无法被解析了。启用httpdns后,除了解决了劫持问题,访问失败率也大幅下降,同时平均时延也减少了。详情参见《移动环境弱联通性的方案》。
下述两图是某个接口在不同访问方式下的对。当时标注为网络时延的一项,现在调整为了客户端的等待。这两种方式接近50%的访问差异,体现在首包和客户端等待上,理解为采样插值和网络设计上的影响。
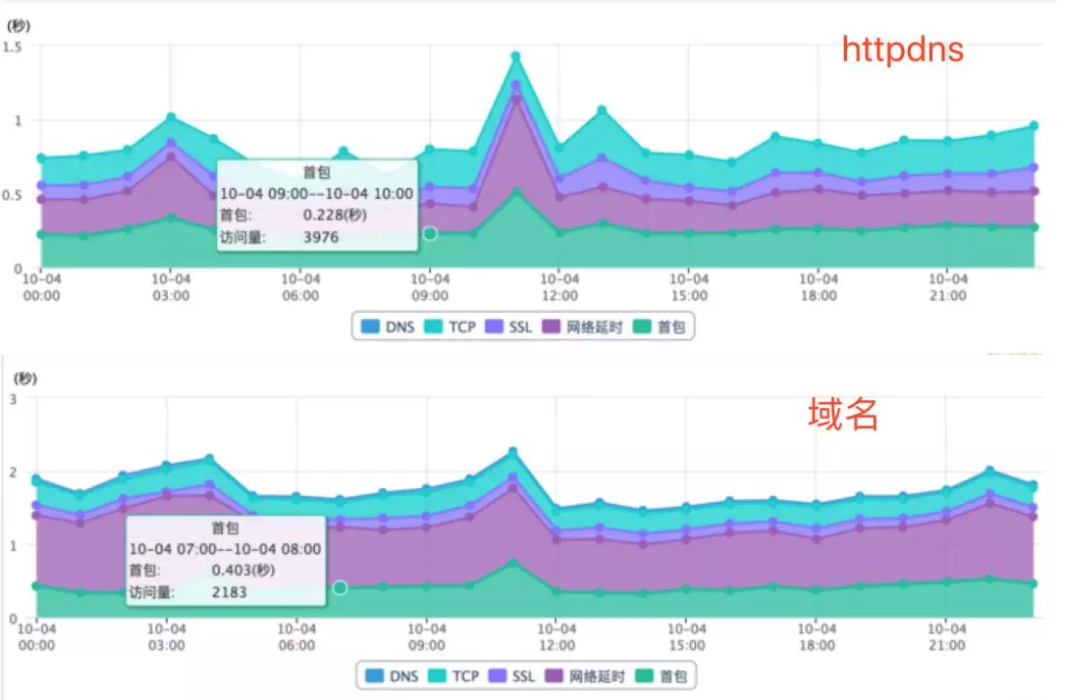
二、http2.0(700ms->430ms)
从上述两图可看出,建联开销和首包时间占了两个大头,工作重点也围绕着这两项展开。首先还是从老本行下手,逐个处理慢接口。但是在优化过程发现,当接口数据较小同时服务器响应也较低时,网络(或者说协议的设计)的影响对于平均响应是决定性的。
如下图,服务器响应低于50ms,包体大小0.5K,在客户端仍有2s以上的响应采集,而且波动也非常大。
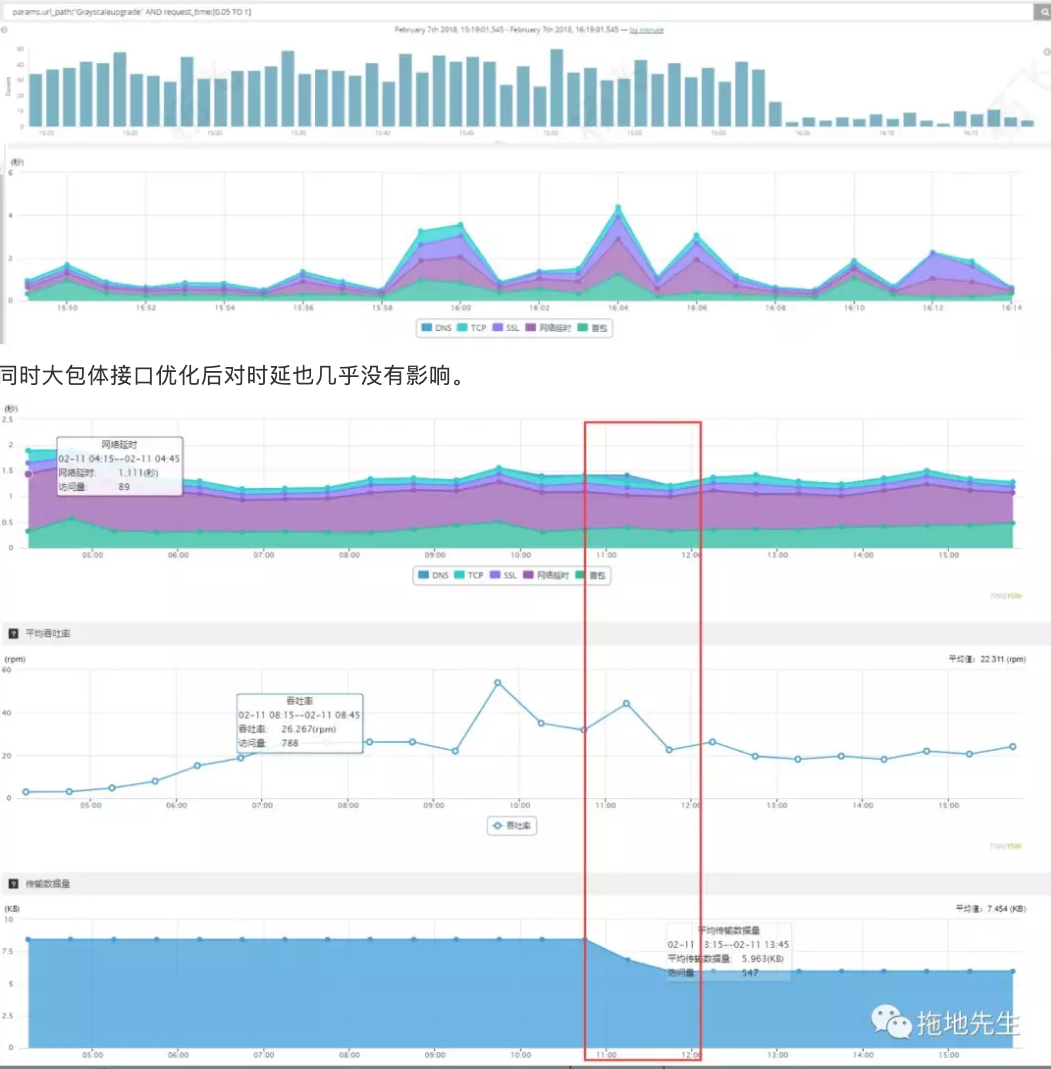
同时大包体接口优化后对时延也几乎没有影响。
因此,将重心转为降低建联开销。考虑了长连接+自定义协议、动态加速等方案,最终http2的优越特性和现网的低改动成为了选型依据。详细可见《HTTP响应太慢?那是没有找到网络优化的正确姿势》。
优化后结果非常亮眼,不但多路复用真正节省掉了tcp、ssl时间,也消除了客户端网络设计带来的延迟。剩余的绝大部分时间都是首包,也就是服务器处理和网络传输这两部分。
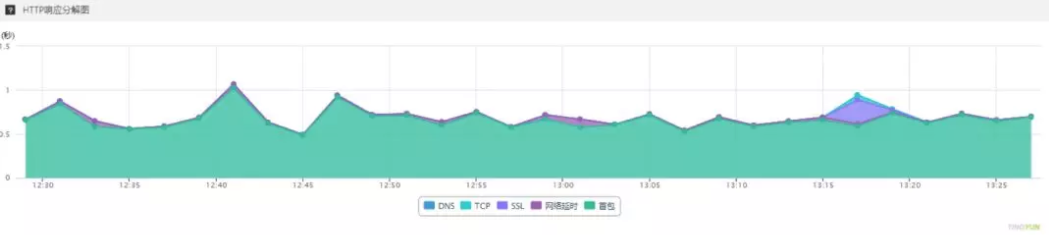
三、php7+opcache (430ms->300ms)
将建联这部分开销优化完成后,工作重心彻底回到了服务器设计本身。为了能体现每一点工作的价值,将目标转为了中间指标:接口慢响应比例。慢响应的定义也来自听云2017年白皮书并参照了一些互联网企业的内部信息。
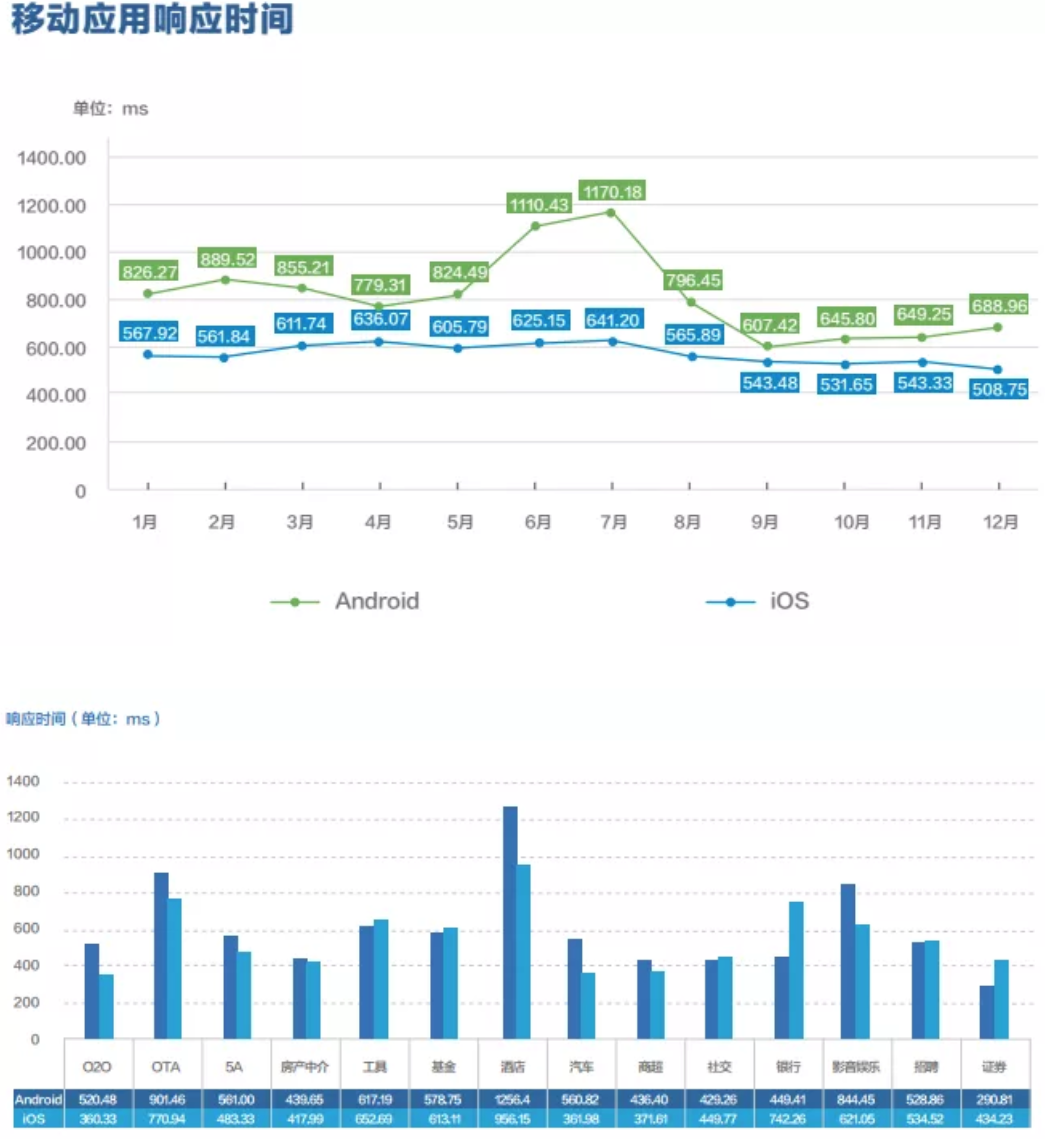
从上述两图可以看出,500ms是平均时间,300ms是可信头部。因此我们把最初的指标定为了500ms慢响应比例。
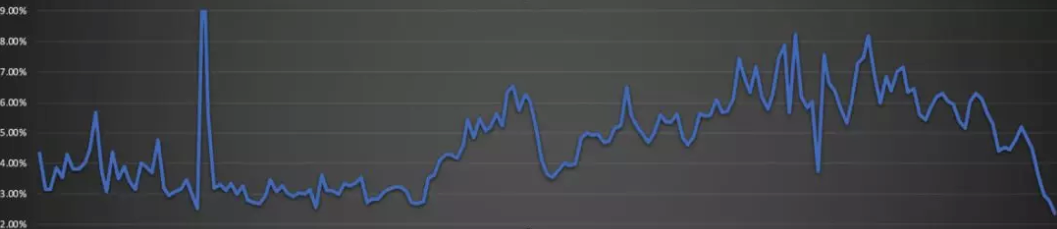
上图是18年的统计信息,约7%的慢响应比例,数百个接口需要优化,每天大幅波动。业务快速频繁迭代老功能,技术优化的不如新增的快,似乎是一个难以触摸的目标。
面对这种情况,借着业务独立拆解的组织架构变革,我们也启动了微服务化的工作,尝试将PHP的单体设计,按组织调整和业务迭代,逐步拆分成以go为技术栈的服务。一是适应组织调整、灵活迭代;二是借此清理技术债务,提升团队代码设计的意识。
自此,php等组件调优、慢查询优化、慢响应优化、服务化多项手段并行。同时,在500ms慢响应比例下降后,将目标提升为300ms,起步点是15%并且波动剧烈。
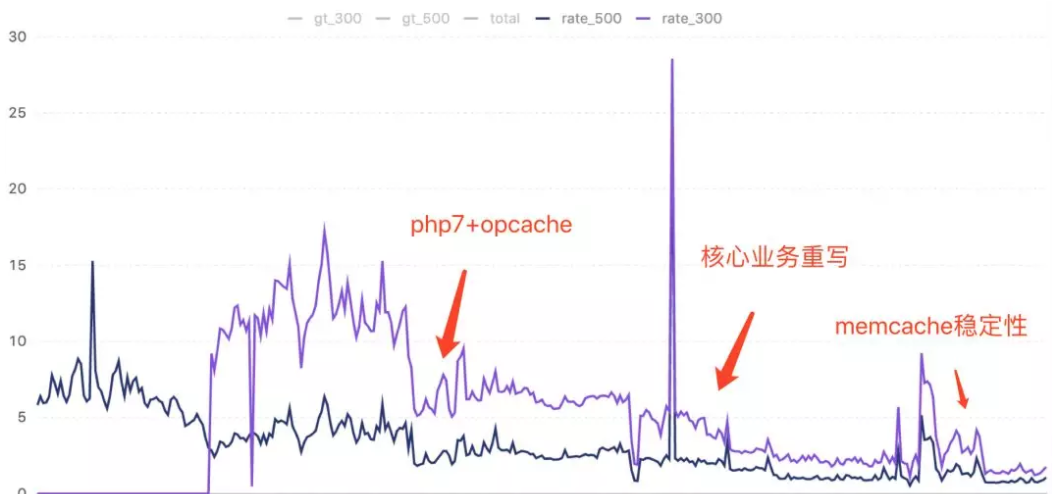
关于php调优,早先已经在海外组做了尝试,由5.6升级至7。出乎意料的是,整体性能并没有官方宣称的数倍,甚至没有明显的提升。猜测由于业务复杂度的差异,加上opcache对脚本解析开销的明确影响,将线上的PHP升级为7.2并且进行了参数的调优。参见《PHP7升级的性能提升》。
升级的好处显而易见,慢响应比例减少了一半。同时,服务器的CPU开销大幅降低,机器的资源节省了近7倍。每天慢响应不再大幅波动,同时晚高峰响应时间增加的现象也消除了。移动端的平均响应时间降为300ms左右,用户侧体验和IT成本都带来了很大的收益。
四、核心模块服务化,优化数据库设计,异步队列延迟处理(300ms->250ms)
随着目标的明确,优化的手段也逐步丰富。
团队在服务化上的锻炼足够后,将涉及多个接口和数据库表的核心业务进行了重新设计和服务化。对一些流水性质的接口引入队列服务异步处理,参见《kafka 基本介绍与常见问题》。通过xhprof的分析,每个版本都逐步进行针对的优化。慢响应比例稳步下降,平均延迟也降低至250ms。
五、云服务(缓存)的稳定性(250ms->200ms)
在九月初,按日的统计出现了大幅的波动。从日志系统搜集的PHP慢日志中看到,大量的mencache服务调用出现。由于该服务是早期购买阿里云的服务,工单反馈说时延已无法保证。
由于缓存数据不能自动迁移,只能购买了新服务并进行了缓存的迁移。通过近半个月的迁移后切换了服务,慢日志中的memcache调用消失,而慢响应比例再次降低,同时平均时延也降低至200ms以下。
在近期的VPC迁移中,可以看到新虚机的性能较三年前也有大幅提升,同时价格还有所降低。买新不买旧,续费时升级是在公有云上运行的一项必备工作。
小结

体现在中间指标的300ms慢响应比例为2%,客户端平均响应为200ms-,不过服务器侧的平均时间已下沉至40ms~60ms之间,并且是可以向20ms进军的。同时120ms左右的网络开销,也是一个可以探索优化的方向。
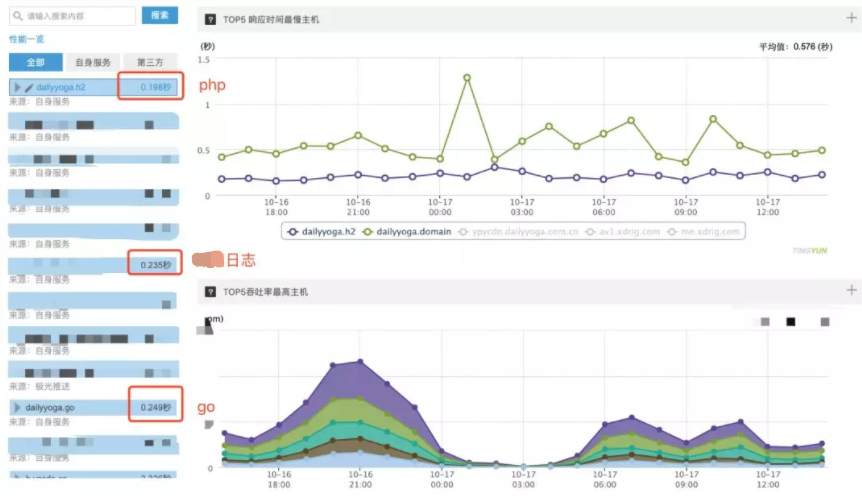
回到开题的讨论,当前的数据如上图,PHP栈的平均响应要低于日志上报,而go栈的平均响应则是最大的。
并不是语言的问题,仅仅是go服务的占比还小,没有享受到http2带来的优势,仍有部分建联开销。同时,某些重接口的设计,也拉高了平均时间。在gatway建设后,建联问题就会解决。
整体的结果可以总结为几点:
1.肉眼可见的响应降低及用户体验提升
2.数倍的服务器资源节省
3.建立团队啃硬骨头的信心
4.战中练,以数据指标反映实现质量的一面,落地代码规范并提升开发质量
后记
在整个指标下降到比较低的状态时,随着分析的深入,对系统各个细节都加入监控(php慢日志、机器CPU/负载、数据库慢查询、接口响应等等),将关注点拆小也提升了指标敏感度。
任何一个小问题都会随时暴露,可以及时发现和处理,团队的每个人都直面问题的刺刀见血,也避免演化为用户侧感知的事故。
在整个过程中,实战团队的代码设计技巧,倒推能力提升和方法论沉淀,让拿结果和能力成长并重。
拖地先生,从事互联网技术工作,一起聊聊日常的技术点滴和管理心得。欢迎关注公众号《拖地先生》~

版权声明: 本文为 InfoQ 作者【拖地先生】的原创文章。
原文链接:【http://xie.infoq.cn/article/513daa0ffd9bfd98f4b5a61ba】。
本文遵守【CC-BY 4.0】协议,转载请保留原文出处及本版权声明。

探寻本质。 2018.06.21 加入
从事互联网技术管理工作,公众号《拖地先生》每周两篇实践沉淀~










评论 (1 条评论)