线程池 ThreadPoolExecutor 原理及源码笔记
前言
前面在学习 JUC 源码时,很多代码举例中都使用了线程池
ThreadPoolExecutor,并且在工作中也经常用到线程池,所以现在就一步一步看看,线程池的源码,了解其背后的核心原理。
介绍
什么是线程池
线程池(英语:thread pool):一种线程使用模式。线程过多会带来调度开销,进而影响缓存局部性和整体性能。而线程池维护着多个线程,等待着监督管理者分配可并发执行的任务。这避免了在处理短时间任务时创建与销毁线程的代价。线程池不仅能够保证内核的充分利用,还能防止过分调度。可用线程数量应该取决于可用的并发处理器、处理器内核、内存、网络sockets等的数量。
>
—— 维基百科
为什么要使用线程池
降低资源消耗:通过池化技术重复利用已创建的线程,降低线程创建和销毁造成的损耗。
提高响应速度:任务到达时,无需等待线程创建即可立即执行。
提高线程的可管理性:线程是稀缺资源,如果无限制创建,不仅会消耗系统资源,还会因为线程的不合理分布导致资源调度失衡,降低系统的稳定性。使用线程池可以进行统一的分配、调优和监控。
如何使用线程池
线程池使用有很多种方式,不过按照《Java 开发手册》描述,尽量还是要使用 ThreadPoolExecutor 进行创建。

代码举例:
那创建线程池的这些构造参数有什么含义?线程池的运行原理是什么?下面则开始通过源码及作图一步一步的了解。
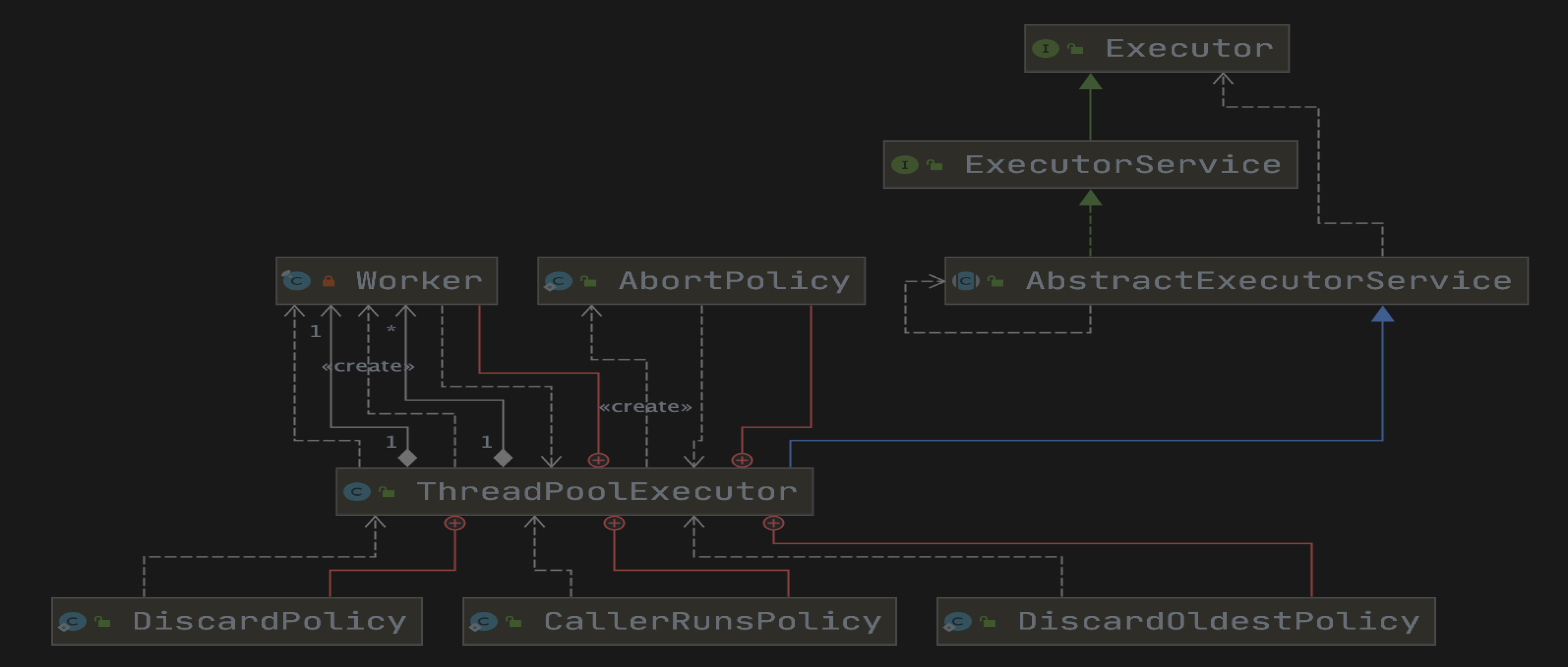
源码分析
参数介绍
构造参数及含义
参数说明:
corePoolSize - 核心线程数,提交任务时,如果当前线程池的数量小于 corePoolSize,则创建新线程执行任务。
maximumPoolSize - 最大线程数,如果阻塞队列已满,并且线程数小于 maximumPoolSize,则会创建新线程执行任务。
keepAliveTime - 当线程数大于核心线程数时,且线程空闲,keepAliveTime 时间后会销毁线程。
unit - keepAliveTime 的时间单位。
workQueue - 阻塞队列,当线程数大于核心线程数时,用来保存任务。
threadFactory - 线程创建的工厂。
handler - 线程饱和策略。
线程池执行流程
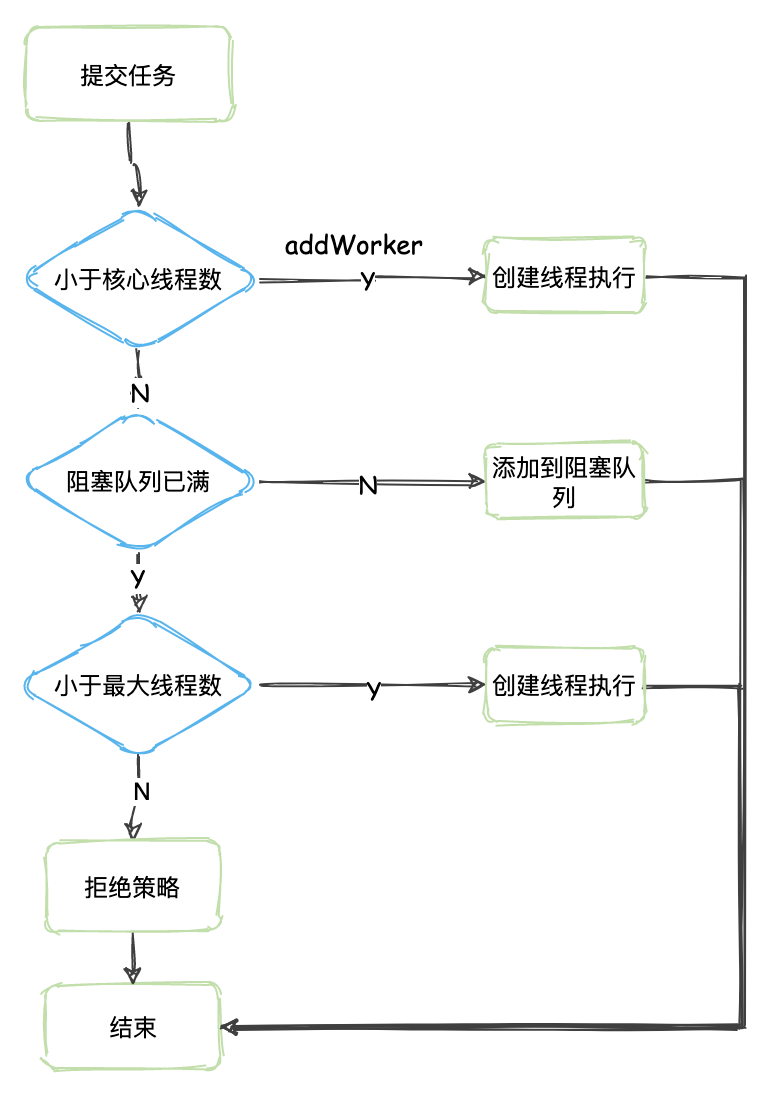
execute 源码
execute 方法流程和流程图画的相同,值得注意的是:
当前线程数小于核心线程数,则会创建新线程,这里
即使是核心线程数有空闲线程也会创建新线程!。而核心线程里面的空闲线程会不断执行阻塞队列里面的任务。
workQueue阻塞队列:
ArrayBlockingQueue: 是一个基于数组结构的有界阻塞队列,此队列按 FIFO(先进先出) 原则对元素进行排序。
LinkedBlockingQueue: 一个基于链表结构的阻塞队列,此队列按 FIFO(先进先出) 排序元素,吞吐量通常要高于ArrayBlockingQueue。静态工厂方法Executors.newFixedThreadPool()使用了这个队列。
SynchronousQueue: 一个不存储元素的阻塞队列。每个插入操作必须等到另一个线程调用移除操作。否则插入操作一直处于阻塞状态,吞吐量通常要高于LinkedBlockingQueue,静态工厂方法Executors.newCachedThreadPool使用了这个队列。
PriorityBlockingQueue: 一个具有优先级的无限阻塞队列。
线程工厂:
一般创建工厂,是为了更好的排查问题,也建议使用工厂指定线程名字。
handler线程拒绝策略:
当线程池达到最大线程数,并且队列满了,新的线程要采取的处理策略。
AbortPolicy 拒绝新任务并抛出RejectedExecutionException异常。
CallerRunsPolicy 直接在调用程序的线程中运行。
DiscardOldestPolicy 放弃最早的任务, 即队列最前面的任务。
DiscardPolicy 丢弃,不处理。
addWorker 源码
addWorker 代码比较长,主要分为两部分:
双重循环,使用 CAS 增加线程数。
创建工作线程 Worker ,并使用独占锁,将其添加到线程池,并启动。
总结
Q&A
Q: 线程池的原理及相关参数?
A: 主要参数为核心线程数、阻塞队列、最大线程数、拒绝策略。
Q: 线程池的线程是怎么回收的?
A: 线程被创建之后,如果 task == null 或者调用 getTask 获取任务为 null,则调用 processWorkerExit 对线程执行清理工作。
清理时只是从 HashSet<Worker> workers 中移除该 Worker,之后该线程会被 JVM 自动回收。
Q: 核心线程是不是就不可以回收了?
A: 核心线程数只会增加,而又没有回收,这时候假如线程池没有任务,就会一直维持核心线程。
当然也可以通过调用 allowCoreThreadTimeOut 方法,设置是否允许回收核心线程。
结束语
通过阅读 ThreadPoolExecutor 了解线程池的基本结构和原理,至于其他的更多扩展,文章篇幅有限,就需要小伙伴们自己阅读了。
相关推荐
版权声明: 本文为 InfoQ 作者【程序员小航】的原创文章。
原文链接:【http://xie.infoq.cn/article/4b735fe6683aabc5a345a732f】。
本文遵守【CC-BY 4.0】协议,转载请保留原文出处及本版权声明。

个人公众号:『 程序员小航 』 2020.07.30 加入
某不知名互联网公司 Java 程序员一枚。记录工作学习中的技术、开发及源码笔记;分享生活中的见闻感悟。








评论