Kafka 系列 9:面试题是否有必要深入了解其背后的原理?我觉得应该刨根究底(上)

前言
在本文开始之前,作者一直有个疑惑,就是面试题是只写写问题和答案就草草了事,还是应该深入分析一下其背后发生的一些原理。和朋友探讨以后作者还是决定采用后者的方式,因为我认为不仅要做到知其一,更要知其二,所以我们就用讲解原理的方式来看看 Kafka 常见的面试题吧。另外避免文章过长,我打算接下来使用几篇文章来详解每道题背后的原理。好了废话有点多,直接开干。
文章概览
kafka 如何保证数据的可靠性和一致性?
kafka 为什么那么快?
Kafka 中的消息是否会丢失和重复消费?
为什么要使用 kafka,为什么要使用消息队列?
为什么 Kafka 不支持读写分离?
kafka 如何保证系统的高可用、数据的可靠性和数据的一致性的?
kafka 的高可用性:
Kafka 本身是一个分布式系统,同时采用了 Zookeeper 存储元数据信息,提高了系统的高可用性。
Kafka 使用多副本机制,当状态为 Leader 的 Partition 对应的 Broker 宕机或者网络异常时,Kafka 会通过选举机制从对应的 Replica 列表中重新选举出一个 Replica 当做 Leader,从而继续对外提供读写服务(当然,需要注意的一点是,在新版本的 Kafka 中,Replica 也可以对外提供读请求了),利用多副本机制在一定程度上提高了系统的容错性,从而提升了系统的高可用。
Kafka 的可靠性:
从 Producer 端来看,可靠性是指生产的消息能够正常的被存储到 Partition 上且消息不会丢失。Kafka 通过
request.required.acks和min.insync.replicas两个参数配合,在一定程度上保证消息不会丢失。request.required.acks可设置为 1、0、-1 三种情况。
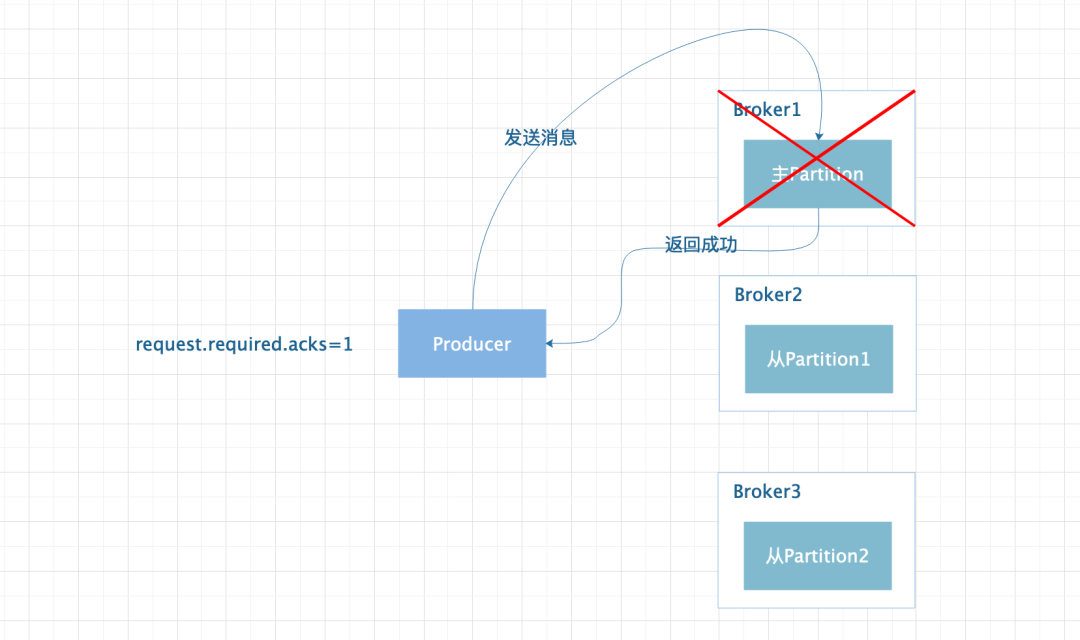
设置为 1 时代表当 Leader 状态的 Partition 接收到消息并持久化时就认为消息发送成功,如果 ISR 列表的 Replica 还没来得及同步消息,Leader 状态的 Partition 对应的 Broker 宕机,则消息有可能丢失。
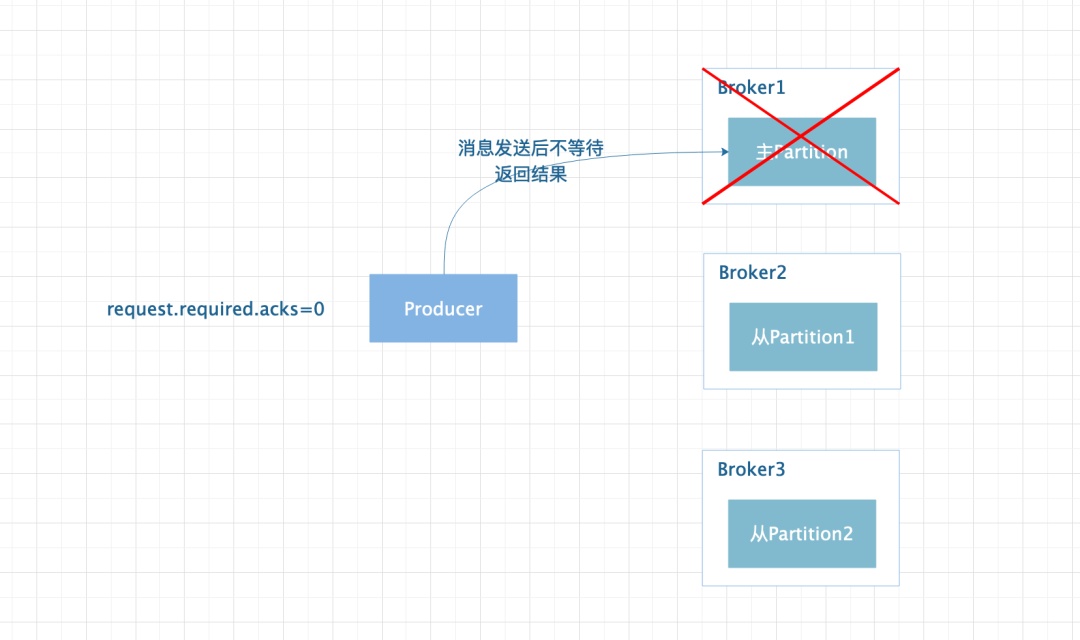
设置为 0 时代表 Producer 发送消息后就认为成功,消息有可能丢失。
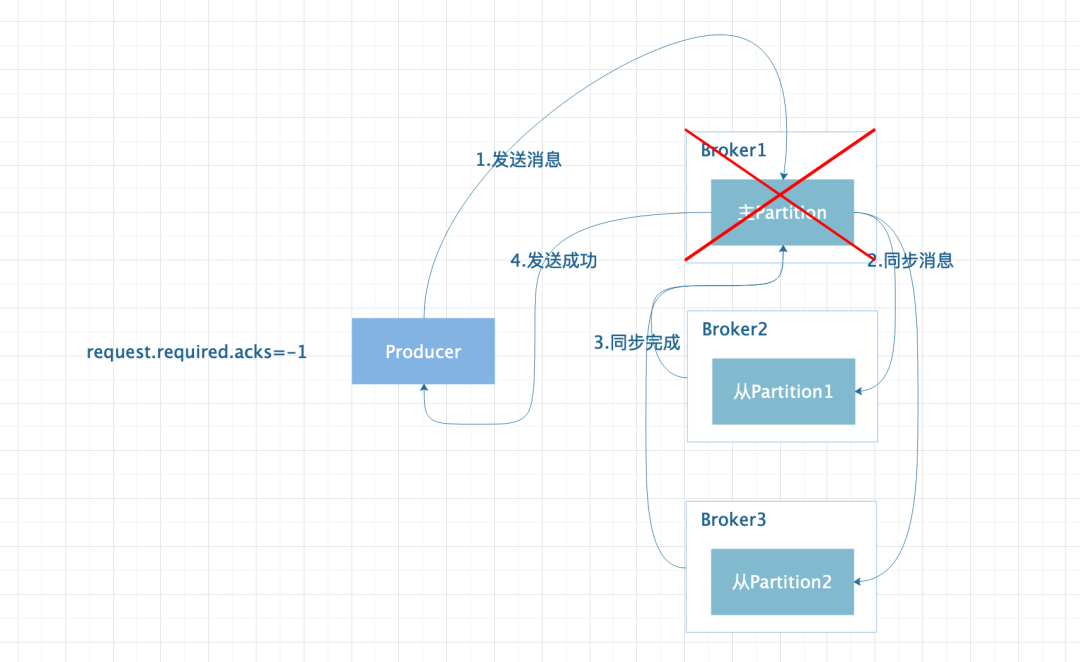
设置为-1 时,代表 ISR 列表中的所有 Replica 将消息同步完成后才认为消息发送成功;但是如果只存在主 Partition 的时候,Broker 异常时同样会导致消息丢失。所以此时就需要min.insync.replicas参数的配合,该参数需要设定值大于等于 2,当 Partition 的个数小于设定的值时,Producer 发送消息会直接报错。
上面这个过程看似已经很完美了,但是假设如果消息在同步到部分从 Partition 上时,主 Partition 宕机,此时消息会重传,虽然消息不会丢失,但是会造成同一条消息会存储多次。在新版本中 Kafka 提出了幂等性的概念,通过给每条消息设置一个唯一 ID,并且该 ID 可以唯一映射到 Partition 的一个固定位置,从而避免消息重复存储的问题(作者到目前还没有使用过该特性,感兴趣的朋友可以自行在深入研究一下)。
Kafka 的一致性:
从 Consumer 端来看,同一条消息在多个 Partition 上读取到的消息是一直的,Kafka 通过引入 HW(High Water)来实现这一特性。
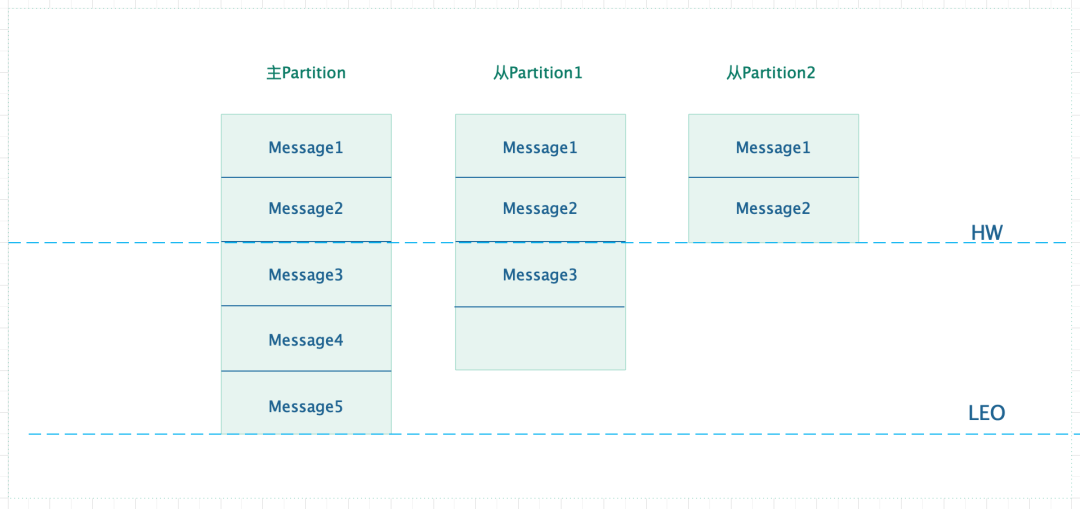
从上图可以看出,假设 Consumer 从主 Partition1 上消费消息,由于 Kafka 规定只允许消费 HW 之前的消息,所以最多消费到 Message2。假设当 Partition1 异常后,Partition2 被选举为 Leader,此时依旧可以从 Partition2 上读取到 Message2。其实 HW 的意思利用了木桶效应,始终保持最短板的那个位置。
从上面我们也可以看出,使用 HW 特性后会使得消息只有被所有副本同步后才能被消费,所以在一定程度上降低了消费端的性能,可以通过设置replica.lag.time.max.ms参数来保证消息同步的最大时间。
kafka 为什么那么快?
kafka 使用了顺序写入和“零拷贝”技术,来达到每秒钟 200w(Apache 官方给出的数据) 的磁盘数据写入量,另外 Kafka 通过压缩数据,降低 I/O 的负担。
顺序写入
大家都知道,对于磁盘而已,如果是随机写入数据的话,每次数据在写入时要先进行寻址操作,该操作是通过移动磁头完成的,极其耗费时间,而顺序读写就能够避免该操作。
“零拷贝”技术
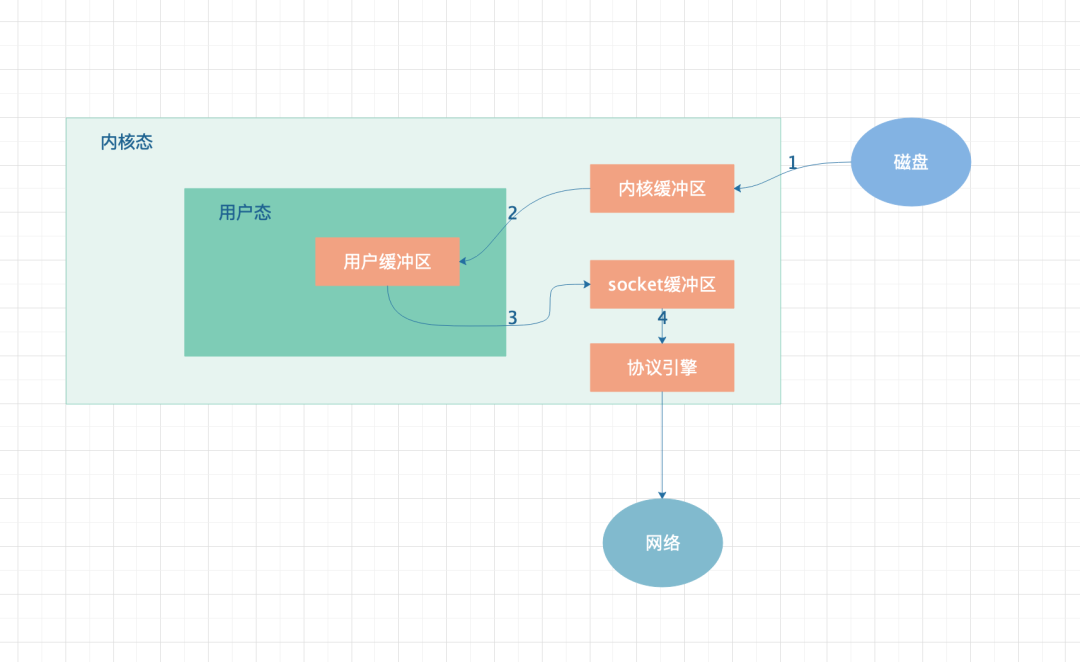
普通的数据拷贝流程如上图所示,数据由磁盘 copy 到内核态,然后在拷贝到用户态,然后再由用户态拷贝到 socket,然后由 socket 协议引擎,最后由协议引擎将数据发送到网络中。
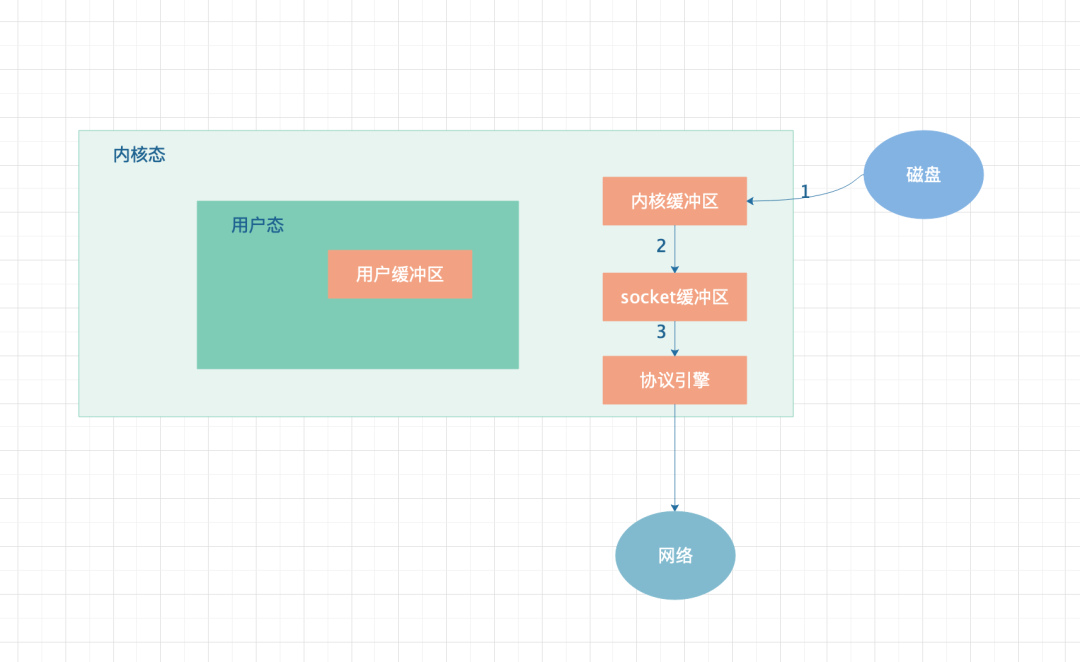
采用了“零拷贝”技术后可以看出,数据不在经过用户态传输,而是直接在内核态完成操作,减少了两次 copy 操作。从而大大提高了数据传输速度。
压缩
Kafka 官方提供了多种压缩协议,包括 gzip、snappy、lz4 等等,从而降低了数据传输的成本。
Kafka 中的消息是否会丢失和重复消费?
Kafka 是否会丢消息,答案相信仔细看过前面两个问题的同学都比较清楚了,这里就不在赘述了。
在低版本中,比如作者公司在使用的 Kafka0.8 版本中,还没有幂等性的特性的时候,消息有可能会重复被存储到 Kafka 上(原因见上一个问题的),在这种情况下消息肯定是会被重复消费的。
这里给大家一个解决重复消费的思路,作者公司使用了 Redis 记录了被消费的 key,并设置了过期时间,在 key 还没有过期内,对于同一个 key 的消息全部当做重复消息直接抛弃掉。 在网上看到过另外一种解决方案,使用 HDFS 存储被消费过的消息,是否具有可行性存疑(需要读者朋友自行探索),读者朋友们可以根据自己的实际情况选择相应的策略,如果朋友们还有其他比较好的方案,欢迎留言交流。
为什么要使用 kafka,为什么要使用消息队列?
先来说说为什么要使用消息队列?
这道题比较主观一些(自认为没有网上其他文章写得话,轻喷),但是都相信大家使用消息队列无非就是为了 解耦、异步、消峰。
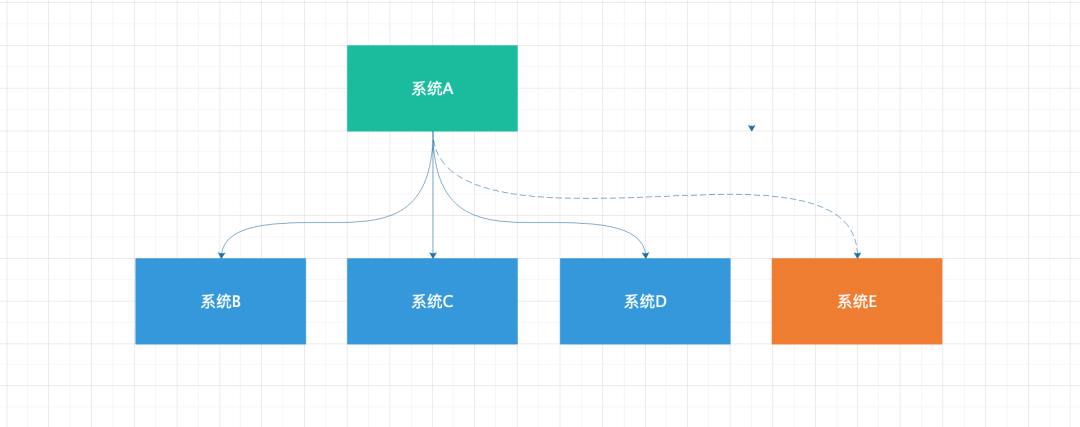
随着业务的发展,相信有不少朋友公司遇到过如上图所示的情况,系统 A 处理的结构被 B、C、D 系统所依赖,当新增系统 E 时,也需要系统 A 配合进行联调和上线等操作;还有当系统 A 发生变更时同样需要告知 B、C、D、E 系统需要同步升级改造。
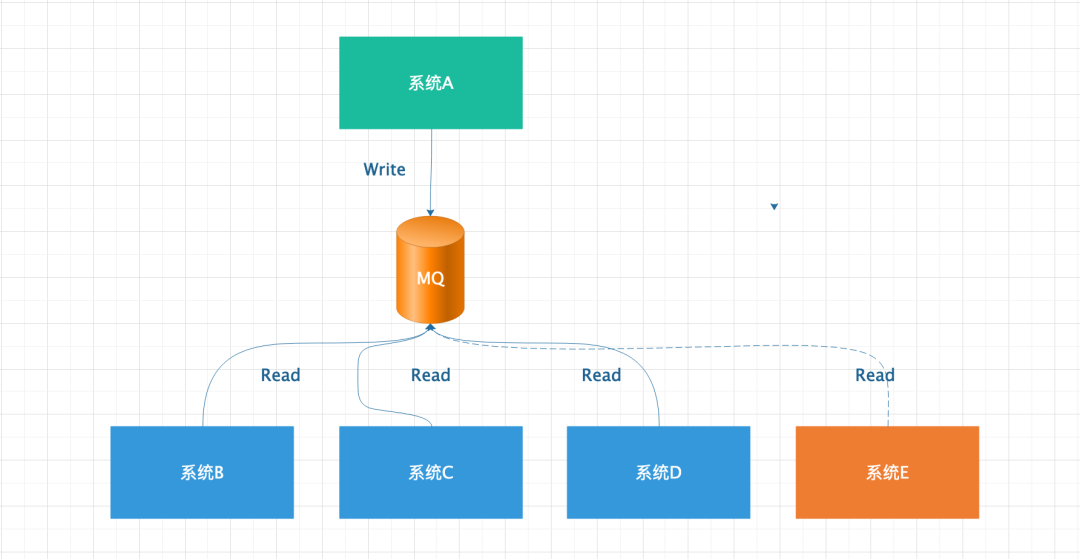
引入消息队列后有两个好处:
各个系统进行了解耦,从上图也可以看出,当系统 A 突然发生热点事件时,同一时间产生大量结果,MQ 充当了消息暂存的效果,防止 B、C、D、E 系统也跟着崩溃。
当新系统 E 需要接入系统 A 的数据,只需要和 MQ 对接就可以了,从而避免了与系统 A 的调试上线等操作。
引入消息队列的坏处:
万事皆具备两面性,看似引入消息队列这件事情很美好,但是同时也增加了系统的复杂度、系统的维护成本提高(如果 MQ 挂了怎么办)、引入了一致性等等问题需要去解决。
为什么要使用 Kafka?
作者认为采用 Kafka 的原因有如下几点:
Kafka 目前在业界被广泛使用,社区活跃度高,版本更新迭代速度也快。
Kafka 的生产者和消费者都用 Java 语言进行了重写,在一定程度降低了系统的维护成本(作者的主观意见,因为当下 Java 的使用群体相当庞大)。
Kafka 系统的吞吐量高,达到了每秒 10w 级别的处理速度。
Kafka 可以和很多当下优秀的大数据组件进行集成,包括 Spark、Flink、Flume、Storm 等等。
为什么 Kafka 不支持读写分离?
这个问题有个先决条件,我们只讨论 Kafka0.9 版本的情况。对于高版本,从 Partition 也可以承担读请求了,这里不多赘述。
Kafka 如果支持读写分离的话,有如下几个问题。
系统设计的复杂度会比较大,当然这个比较牵强,毕竟高版本的 Kafka 已经实现了。
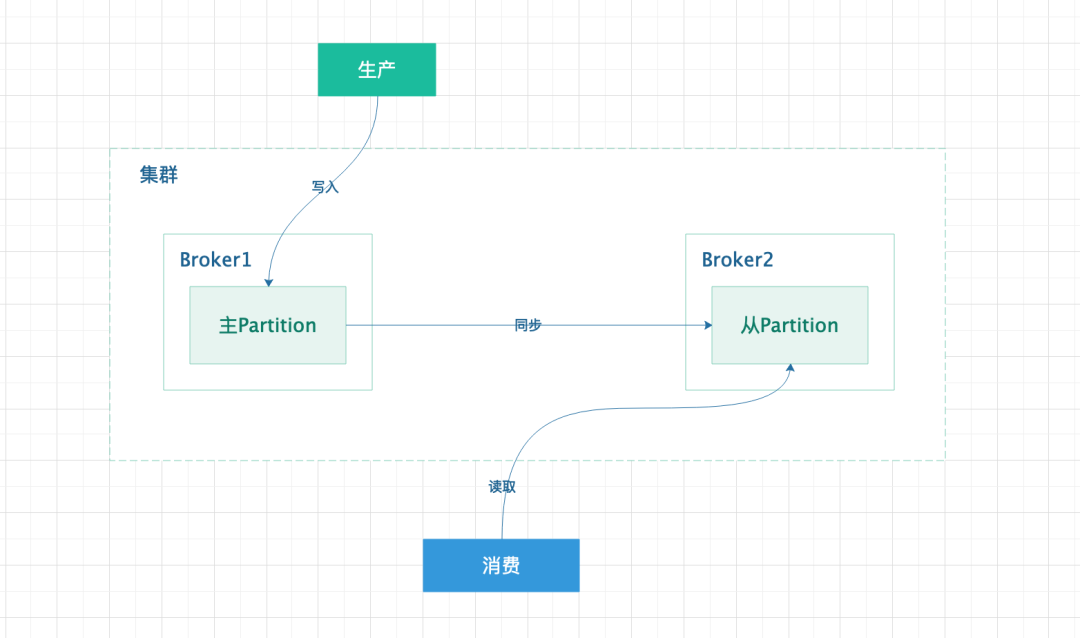
从上图可以看出,从从 Partition 上读取数据会有两个问题。一、数据从主 Partition 上同步到从 Partition 有数据延迟问题,因为数据从生产到消费会经历 3 次网络传输才能够被消费,对于时效性要求比较高的场景本身就不适合了。二、数据一致性问题,假设主 Partition 将数据第一次修改成了 A,然后又将该数据修改成了 B,由于从主 Partition 同步到从 Partition 会有延迟问题,所以也就会产生数据一致性问题。
分析得出,通过解决以上问题来换取从 Partition 承担读请求,成本可想而知,而且对于写入压力大,读取压力小的场景,本身也就没有什么意义了。
总结
本文介绍了几个常见的 Kafka 的面试题,下篇文章我们分析一下延迟队列及其实际落地场景的使用问题,敬请期待
历史精彩文章推荐:
文章参考:
https://www.cnblogs.com/binyue/p/10308754.html
https://www.cnblogs.com/yoke/p/11477167.html
微信公众号搜索【z小赵】,更多系列精彩文章等你解
版权声明: 本文为 InfoQ 作者【z小赵】的原创文章。
原文链接:【http://xie.infoq.cn/article/49a133ad2b2f2671aa60706b0】。文章转载请联系作者。

高并发系统、大数据技术栈、研究框架源码 2018.09.17 加入
擅长高并发系统设计,熟悉大数据生态圈及框架的使用,喜欢研究优秀框架设计原理和源码学习









评论 (4 条评论)