
大数据 ELK(十):使用 VSCode 操作猎聘网职位搜索案例

猎聘网职位搜索案例
一、需求
本次案例,要实现一个类似于猎聘网的案例,用户通过搜索相关的职位关键字,就可以搜索到相关的工作岗位。我们已经提前准备好了一些数据,这些数据是通过爬虫爬取的数据,这些数据存储在 CSV 文本文件中。我们需要基于这些数据建立索引,供用户搜索查询。
数据集介绍
二、创建索引
为了能够搜索职位数据,我们需要提前在 Elasticsearch 中创建索引,然后才能进行关键字的检索。这里先回顾下,我们在 MySQL 中创建表的过程。在 MySQL 中,如果我们要创建一个表,我们需要指定表的名字,指定表中有哪些列、列的类型是什么。同样,在 Elasticsearch 中,也可以使用类似的方式来定义索引。
1、创建带有映射的索引
Elasticsearch 中,我们可以使用 RESTful API(http 请求)来进行索引的各种操作。创建 MySQL 表的时候,我们使用 DDL 来描述表结构、字段、字段类型、约束等。在 Elasticsearch 中,我们使用 Elasticsearch 的 DSL 来定义——使用 JSON 来描述。例如:

2、字段的类型
在 Elasticsearch 中,每一个字段都有一个类型(type)。以下为 Elasticsearch 中可以使用的类型:
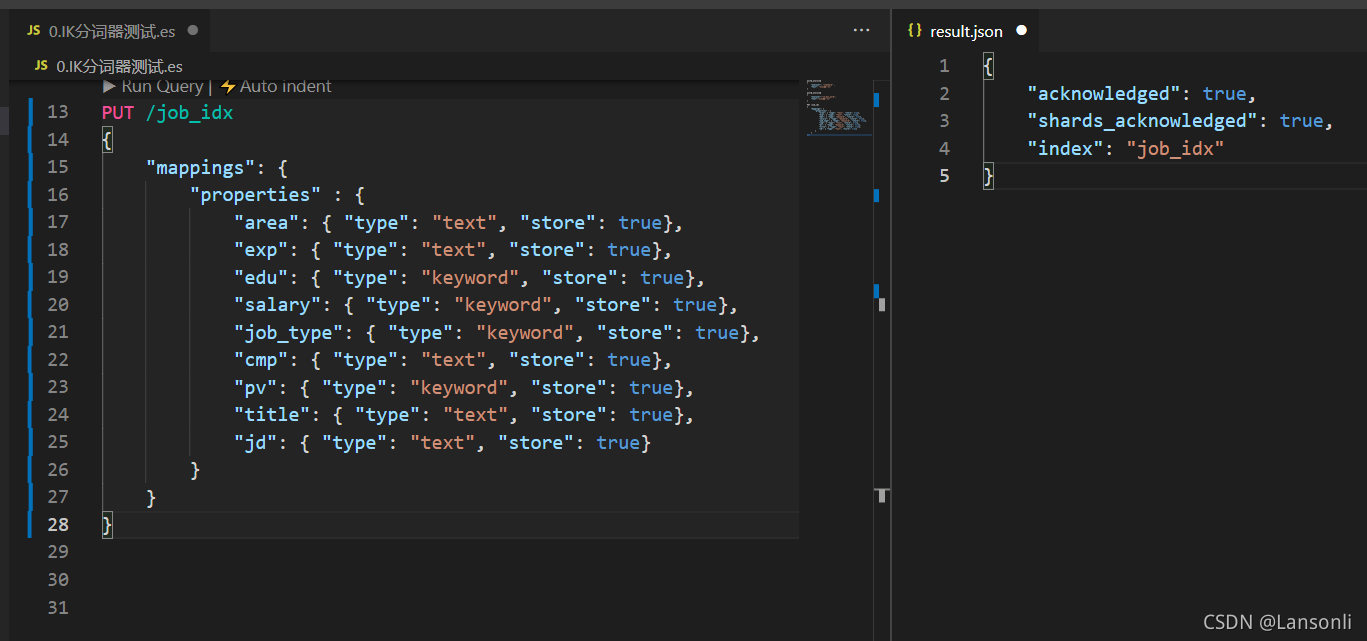
3、创建保存职位信息的索引
使用 PUT 发送 PUT 请求
索引名为 /job_idx
判断是使用 text、还是 keyword,主要就看是否需要分词
创建索引:
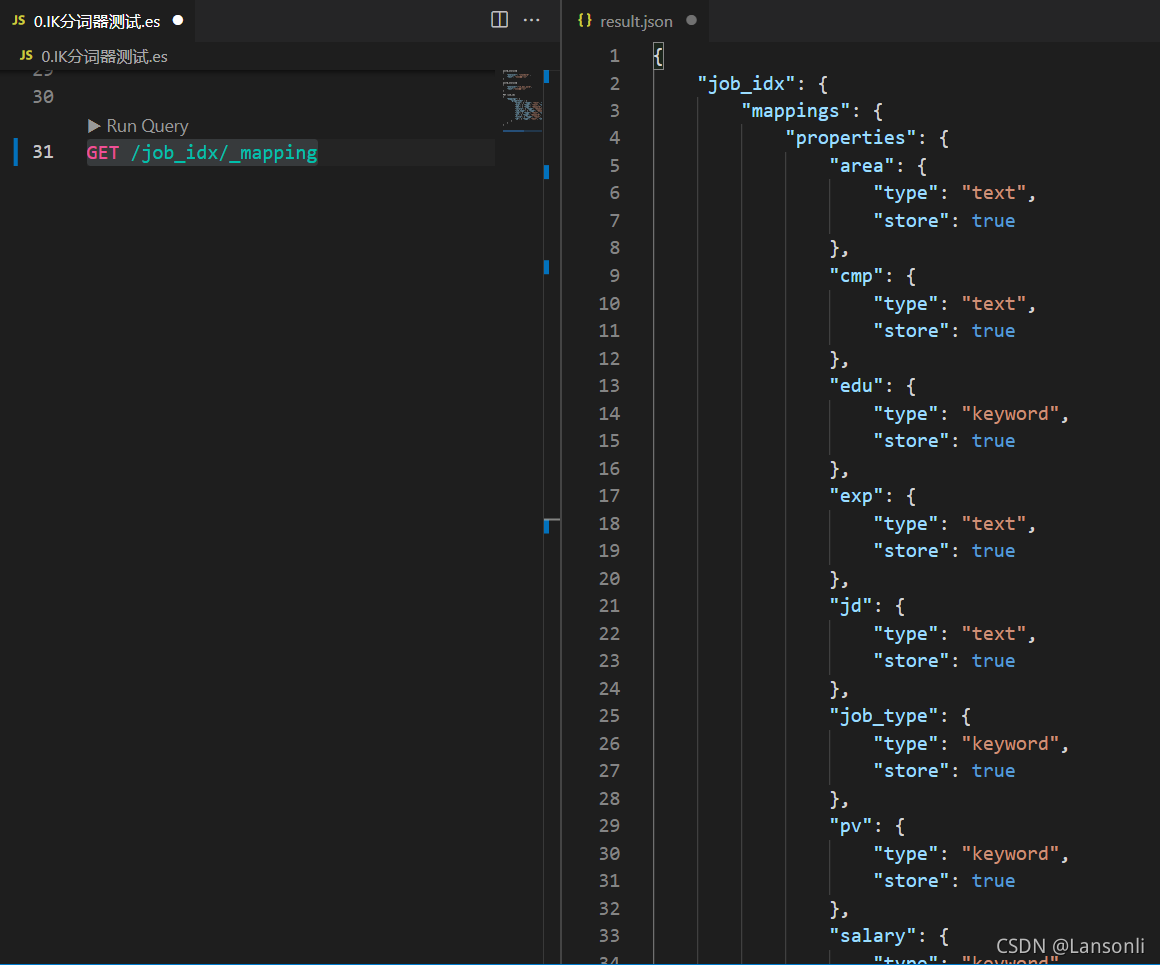
4、查看索引映射
使用 GET 请求查看索引映射
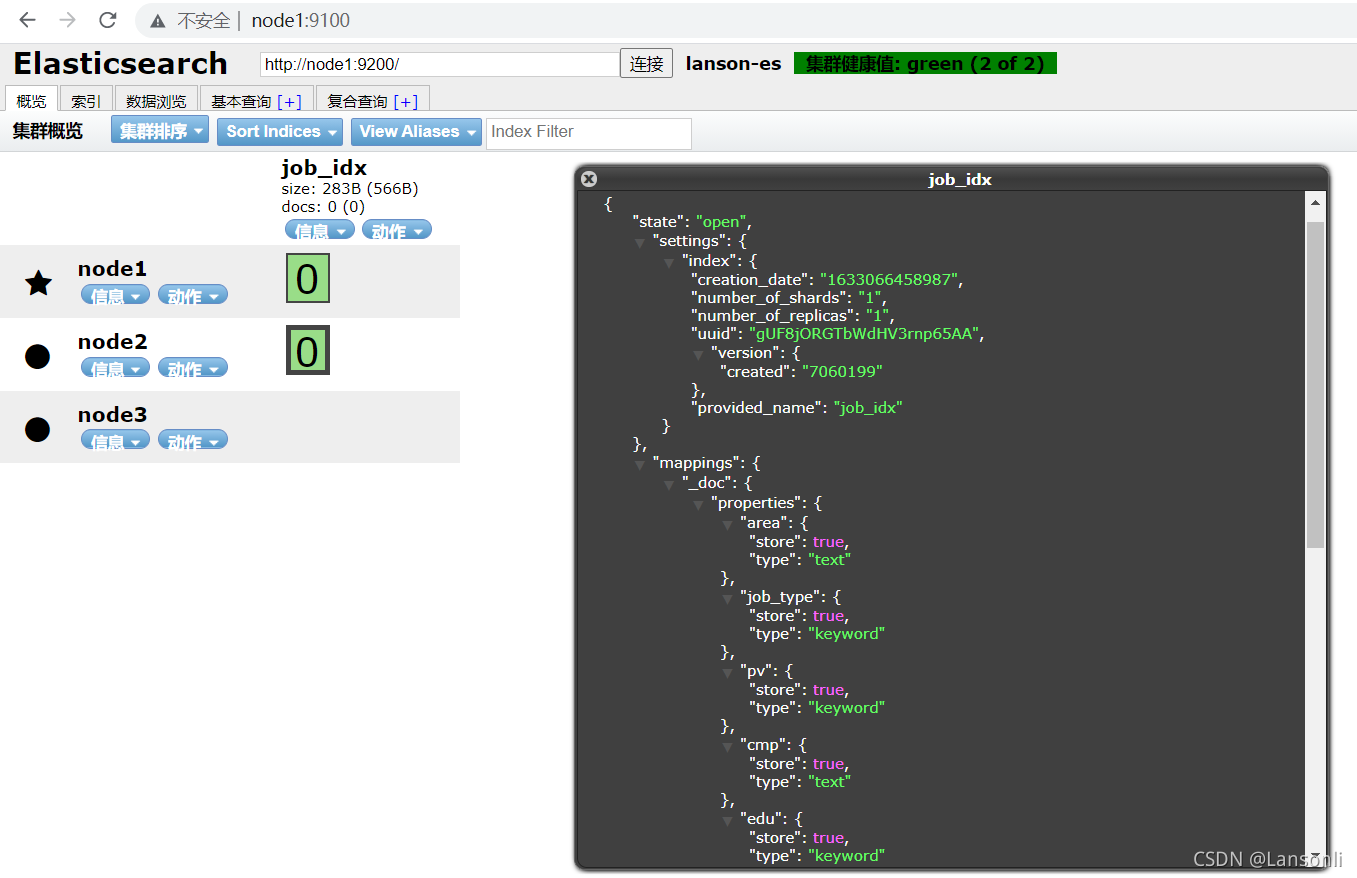
使用 head 插件也可以查看到索引映射信息
5、查看 Elasticsearch 中的所有索引
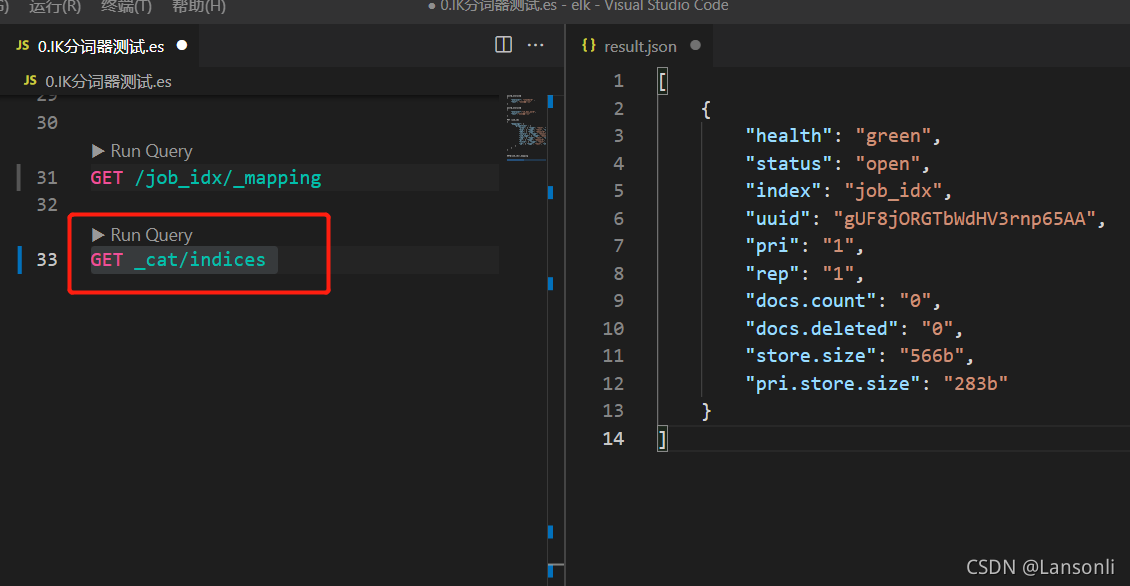
6、删除索引

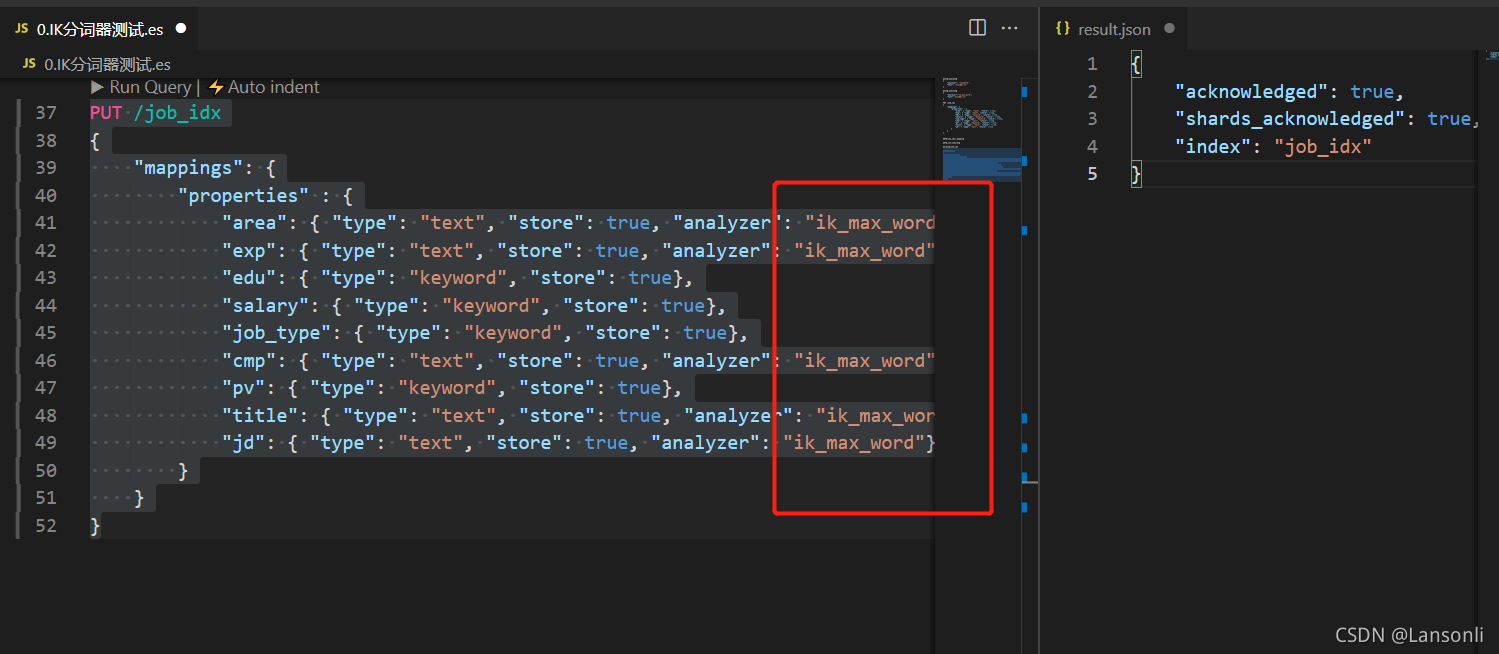
7、指定使用 IK 分词器
因为存放在索引库中的数据,是以中文的形式存储的。所以,为了有更好地分词效果,我们需要使用 IK 分词器来进行分词。这样,将来搜索的时候才会更准确。
三、添加一个职位数据
1、需求
我们现在有一条职位数据,需要添加到 Elasticsearch 中,后续还需要能够在 Elasticsearch 中搜索这些数据。
| 29097, 工作地区:深圳-南山区, 1 年经验, 大专以上, ¥ 6-8 千/月, 实习, 乐有家, 61.6 万人浏览过 / 14 人评价 / 113 人正在关注, 桃园 深大销售实习 岗前培训, 【薪酬待遇】 本科薪酬 7500 起 大专薪酬 6800 起 以上无业绩要求,同时享有业绩核算比例 55%~80% 人均月收入超 1.3 万 【岗位职责】 1.爱学习,有耐心: 通过公司系统化培训熟悉房地产基本业务及相关法律、金融知识,不功利服务客户,耐心为客户在房产交易中遇到的各类问题; 2.会聆听,会提问: 详细了解客户的核心诉求,精准匹配合适的产品信息,具备和用户良好的沟通能力,有团队协作意识和服务意识; 3.爱琢磨,善思考: 热衷于用户心理研究,善于从用户数据中提炼用户需求,利用个性化、精细化运营手段,提升用户体验。 【岗位要求】 1.18-26 周岁,自考大专以上学历; 2.具有良好的亲和力、理解能力、逻辑协调和沟通能力; 3.积极乐观开朗,为人诚实守信,工作积极主动,注重团队合作; 4.愿意服务于高端客户,并且通过与高端客户面对面沟通有意愿提升自己的综合能力; 5.愿意参加公益活动,具有爱心和感恩之心。 【培养路径】 1.上千堂课程;房产知识、营销知识、交易知识、法律法规、客户维护、目标管理、谈判技巧、心理学、经济学; 2.成长陪伴:一对一的师徒辅导 3.线上自主学习平台:乐有家学院,专业团队制作,每周大咖分享 4.储备及管理课堂: 干部训练营、月度/季度管理培训会 【晋升发展】 营销【精英】发展规划:A1 置业顾问-A6 资深置业专家 营销【管理】发展规划:(入职次月后就可竞聘) 置业顾问-置业经理-店长-营销副总经理-营销副总裁-营销总裁 内部【竞聘】公司职能岗位:如市场、渠道拓展中心、法务部、按揭经理等都是内部竞聘 【联系人】 小明主任 15888888888(微信同号) |
|:----|
2、PUT 请求
前面我们已经创建了索引。接下来,我们就可以往索引库中添加一些文档了。可以通过 PUT 请求直接完成该操作。在 Elasticsearch 中,每一个文档都有唯一的 ID。也是使用 JSON 格式来描述数据。例如:
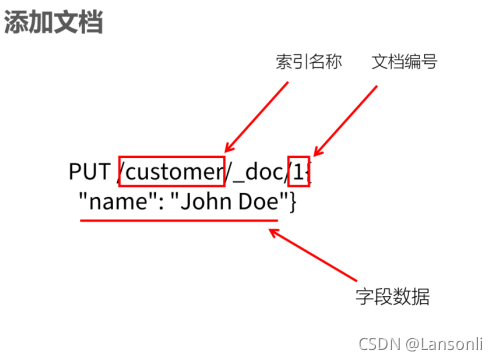
如果在 customer 中,不存在 ID 为 1 的文档,Elasticsearch 会自动创建
3、添加职位信息请求
Elasticsearch 响应结果:
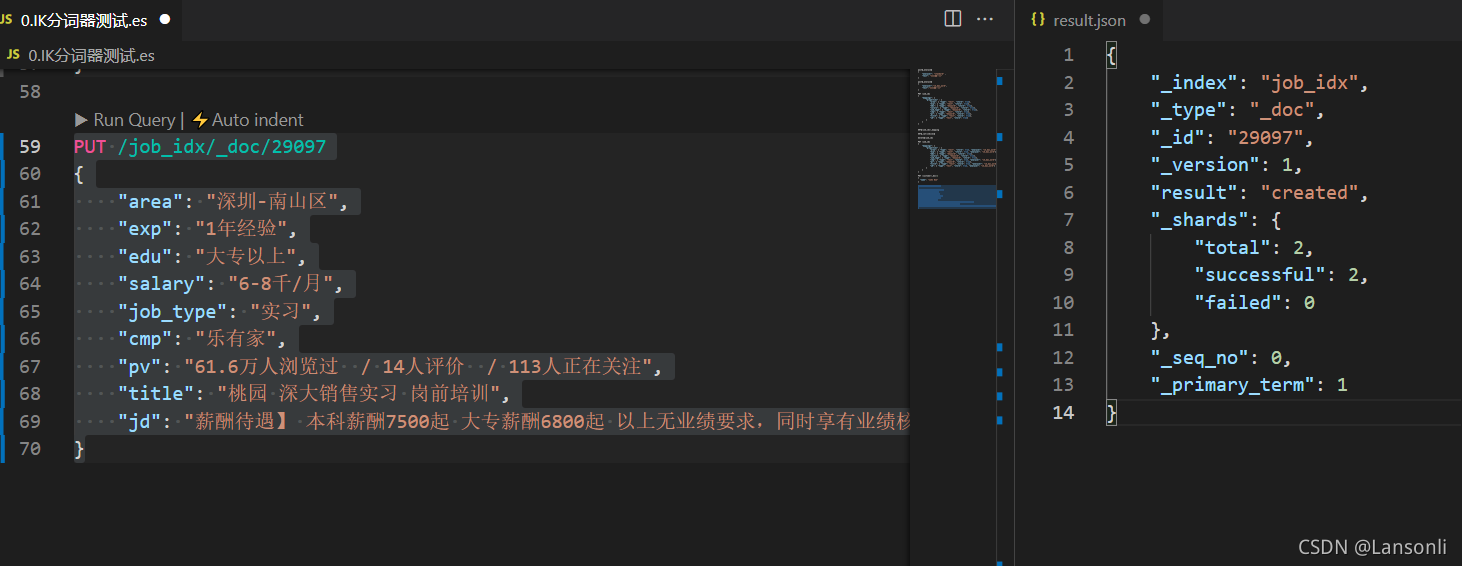
使用 ES-head 插件浏览数据:
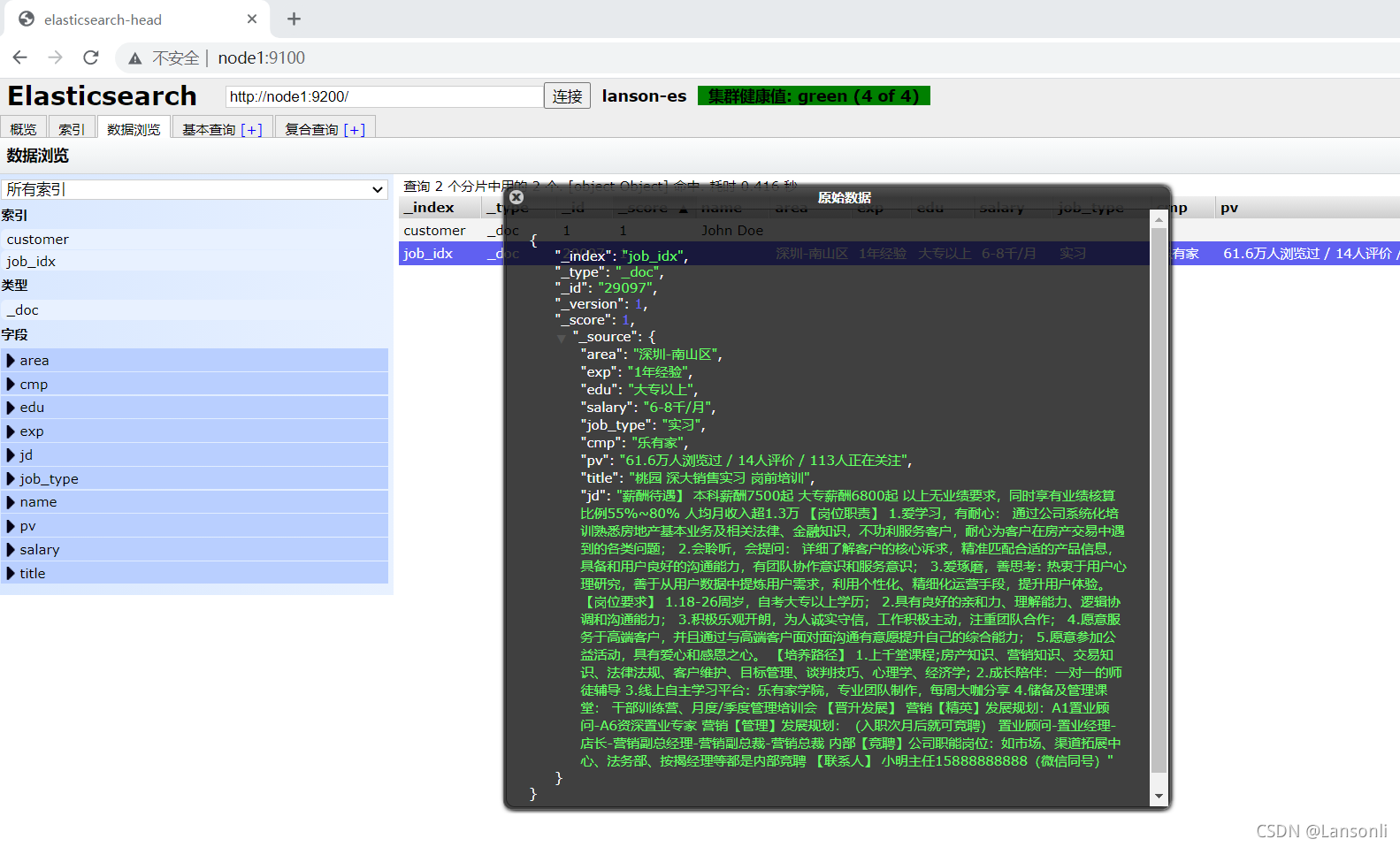
四、修改职位薪资
1、需求
因为公司招不来人,需要将原有的薪资 6-8 千/月,修改为 15-20 千/月
2、执行 update 操作
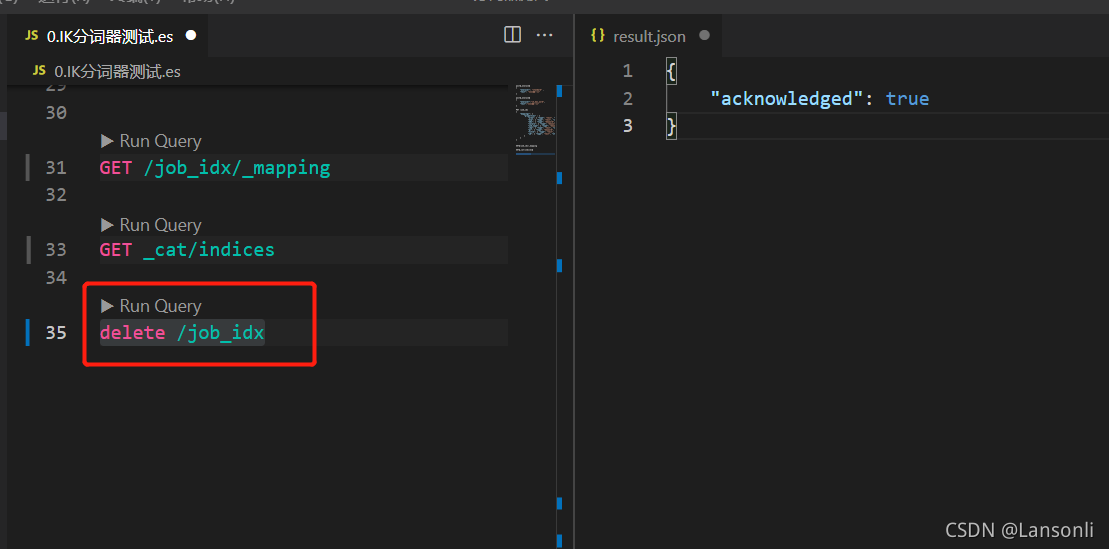
五、删除一个职位数据
1、需求
ID 为 29097 的职位,已经被取消。所以,我们需要在索引库中也删除该岗位。
2、DELETE 操作
六、批量导入 JSON 数据
1、bulk 导入
为了方便后面的测试,我们需要先提前导入一些测试数据到 ES 中。在资料文件夹中有一个 job_info.json 数据文件。我们可以使用 Elasticsearch 中自带的 bulk 接口来进行数据导入。
上传 JSON 数据文件到 Linux
执行导入命令
2、查看索引状态
通过执行以上请求,Elasticsearch 返回数据如下:
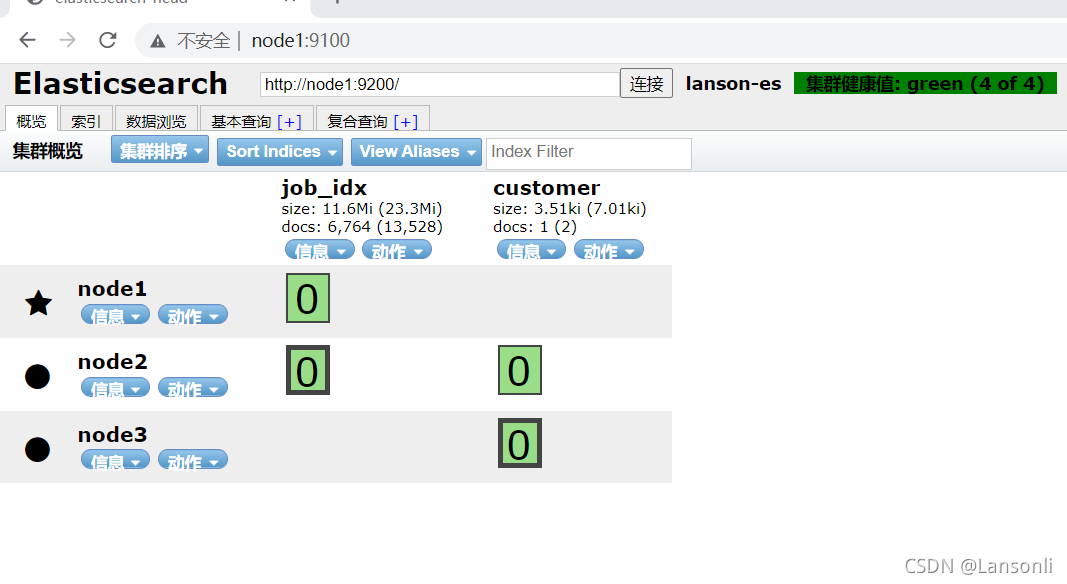
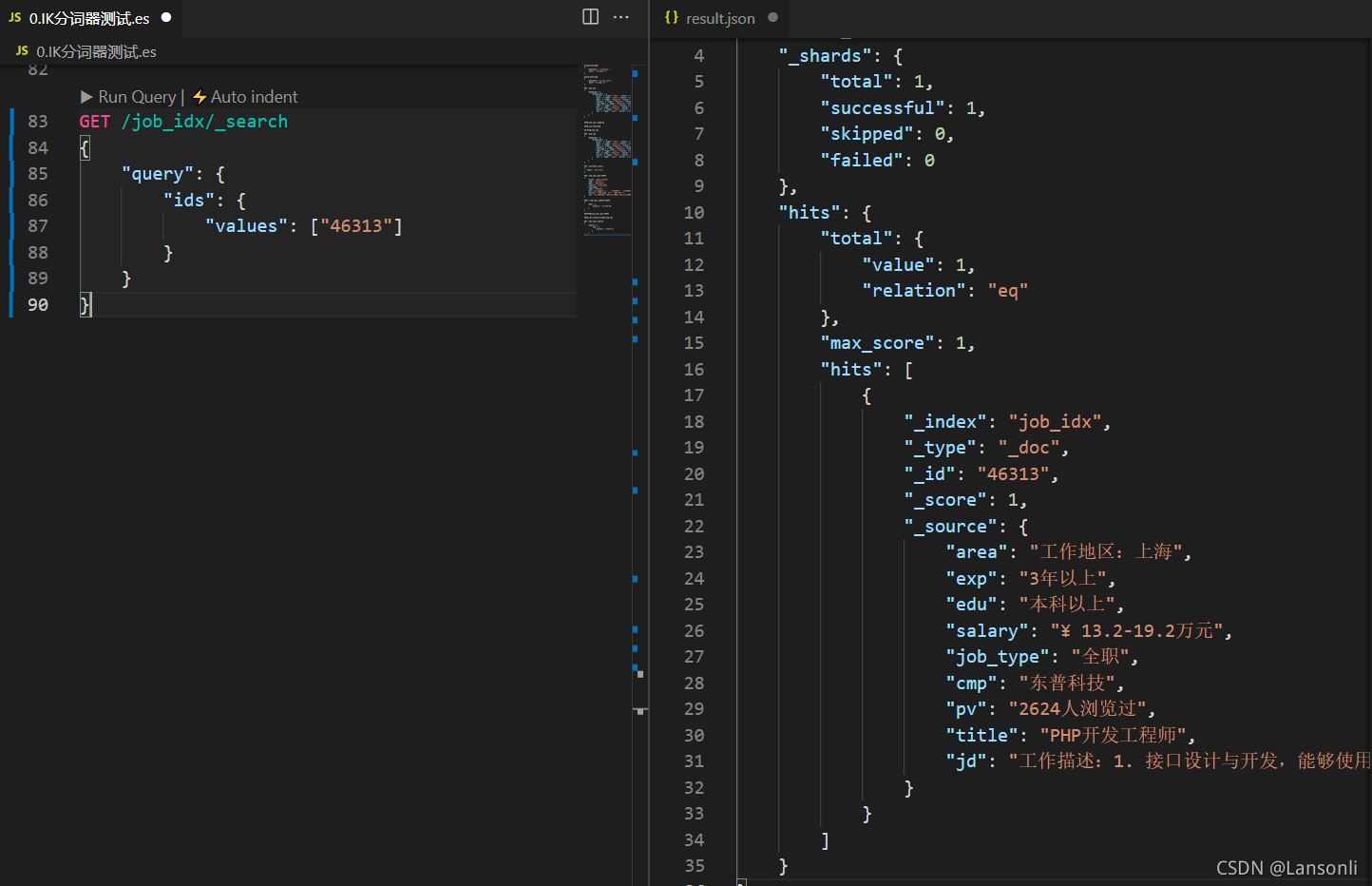
七、根据 ID 检索指定职位数据
1、需求
用户提交一个文档 ID,Elasticsearch 将 ID 对应的文档直接返回给用户。
2、实现
在 Elasticsearch 中,可以通过发送 GET 请求来实现文档的查询。

八、根据关键字搜索数据
1、需求
搜索职位中带有「销售」关键字的职位
2、实现
检索 jd 中销售相关的岗位
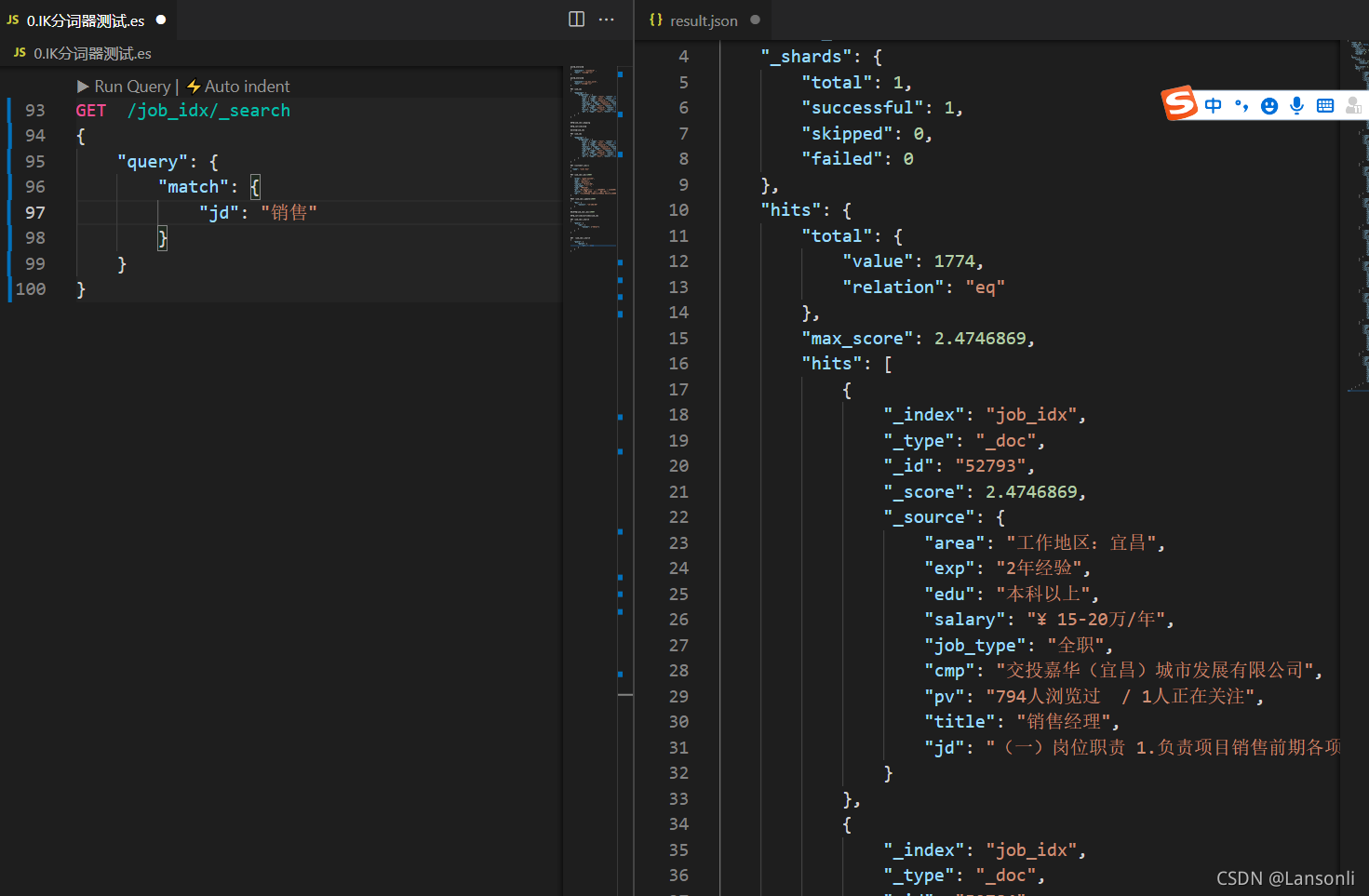
除了检索职位描述字段以外,我们还需要检索 title 中包含销售相关的职位,所以,我们需要进行多字段的组合查询。
更多地查询:
官方地址:开始使用 Elasticsearch | Elastic Videos
九、根据关键字分页搜索
1、使用 from 和 size 来进行分页
在执行查询时,可以指定 from(从第几条数据开始查起)和 size(每页返回多少条)数据,就可以轻松完成分页。
from = (page – 1) * size
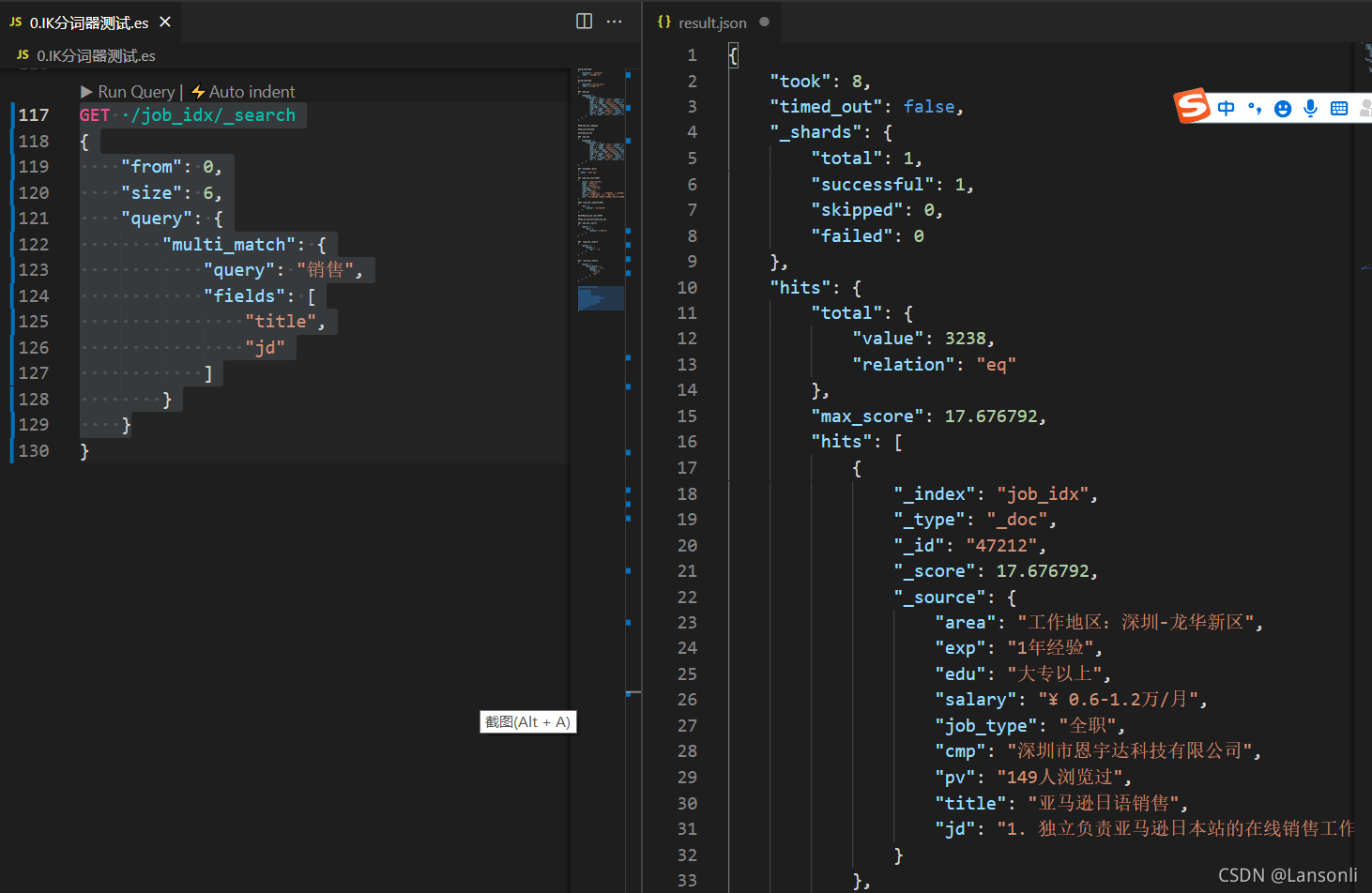
2、使用 scroll 方式进行分页
前面使用 from 和 size 方式,查询在 1W-5W 条数据以内都是 OK 的,但如果数据比较多的时候,会出现性能问题。Elasticsearch 做了一个限制,不允许查询的是 10000 条以后的数据。如果要查询 1W 条以后的数据,需要使用 Elasticsearch 中提供的 scroll 游标来查询。
在进行大量分页时,每次分页都需要将要查询的数据进行重新排序,这样非常浪费性能。使用 scroll 是将要用的数据一次性排序好,然后分批取出。性能要比 from + size 好得多。使用 scroll 查询后,排序后的数据会保持一定的时间,后续的分页查询都从该快照取数据即可。
1)第一次使用 scroll 分页查询
此处,我们让排序的数据保持 1 分钟,所以设置 scroll 为 1m
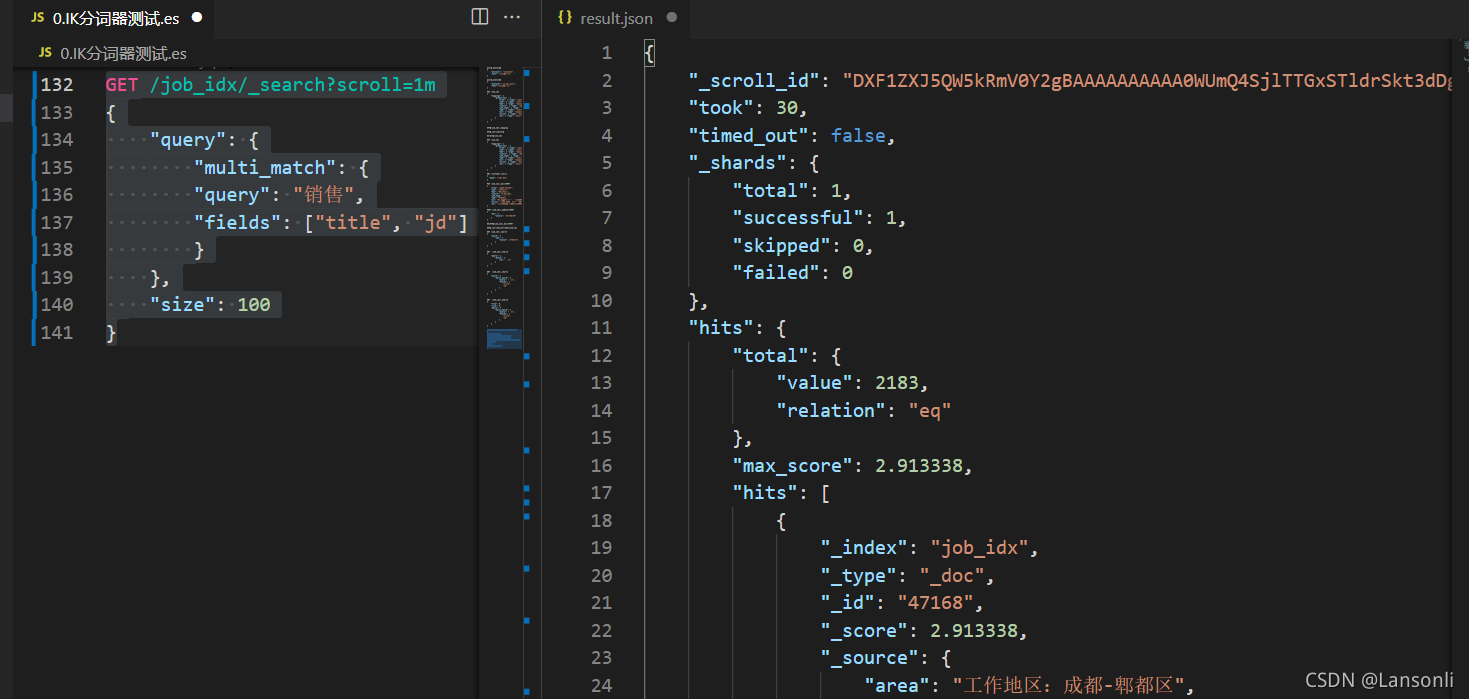
执行后,我们注意到,在响应结果中有一项:
"_scroll_id": "DXF1ZXJ5QW5kRmV0Y2gBAAAAAAAAAA0WUmQ4SjlTTGxSTldrSkt3dDg1eHRuQQ=="
后续,我们需要根据这个_scroll_id 来进行查询
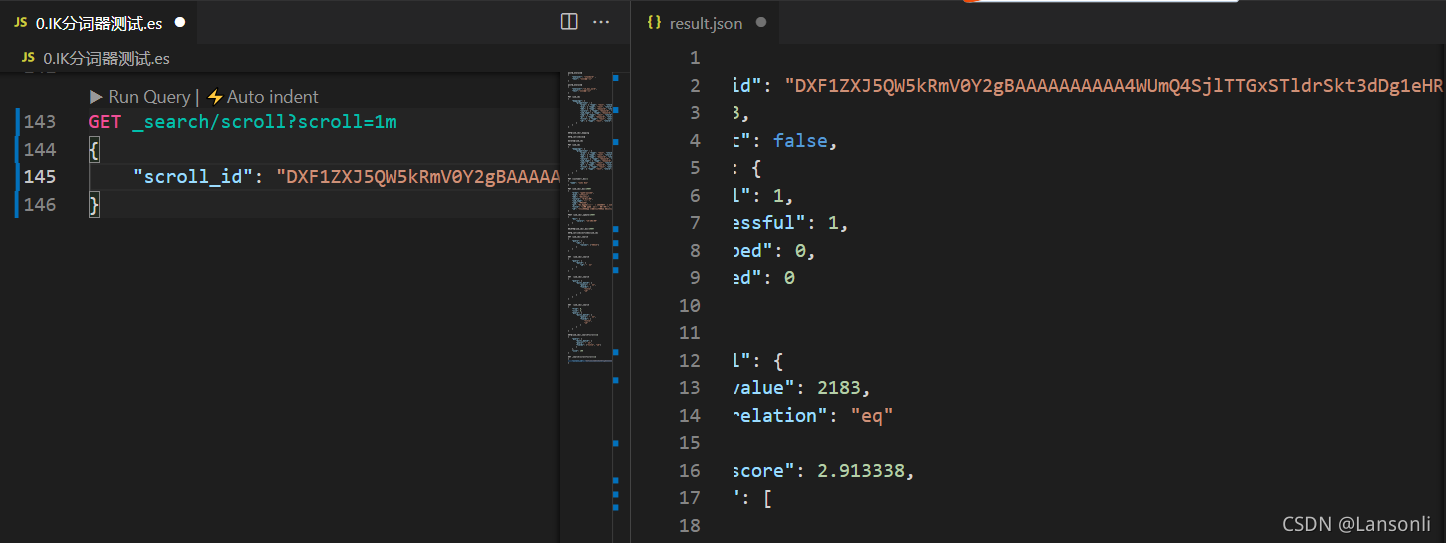
2)第二次直接使用 scroll id 进行查询
字数: 8125 / 50000
版权声明: 本文为 InfoQ 作者【Lansonli】的原创文章。
原文链接:【http://xie.infoq.cn/article/45f6ebb9b1313e3cd4ac9f002】。文章转载请联系作者。

微信公众号:三帮大数据 2022.07.12 加入
CSDN大数据领域博客专家,华为云享专家、阿里云专家博主、腾云先锋(TDP)核心成员、51CTO专家博主,全网六万多粉丝,知名互联网公司大数据高级开发工程师









评论