分布式集群如何实现高效的数据分布

一、前言
随着互联网的发展,用户产生的数据越来越多,企业面临着庞大数据的存储问题,目前市面上主流的分布式大数据文件系统,都是对数据切片打散,通过离散方法将数据散列在集群的所有节点上,本文将带你了解 DHT(Distributed Hash Table):分布式哈希表是如何实现数据的分布式离散存储的。
DHT(Distributed Hash Table):分布式哈希表
二、技术背景
互联网发展早期,数据通常存储在单个服务器上,初期数据增长较为缓慢,可以通过提升单机的存储能力满足数据的增长需求;随着互联网普及程度的推进,用户数、用户产生和访问的数据呈指数增长;单机已无法存储用户需要的数据。为此,迫切需要多个服务器共同协作,存储量级更大的数据。
三、传统 Hash
传统 Hash 通过算法 hash()=X mod S 来对数据进行分散,在元数据比较分散的情况下,数据能够很好的散列在集群节点中。由于 S 代表了集群的节点数,当进行集群的扩容缩容时,S 的变化会影响到历史数据的命中问题,因此为了提高数据命中率,会产生大量测数据迁移,性能较差。
四、一个简单的 DHT
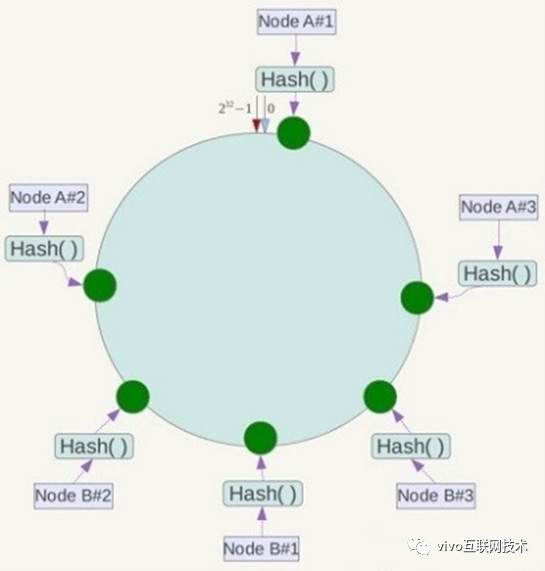
分布式 Hash 通过构造一个长度为 2 的 32 次方(ipv4 地址的数量)的环,将节点散列在 Hash 环上,根据不同的 Hash 算法计算出来的 Hash 值有所不同,本文采用 FNV Hash 算法来计算 Hash 值。
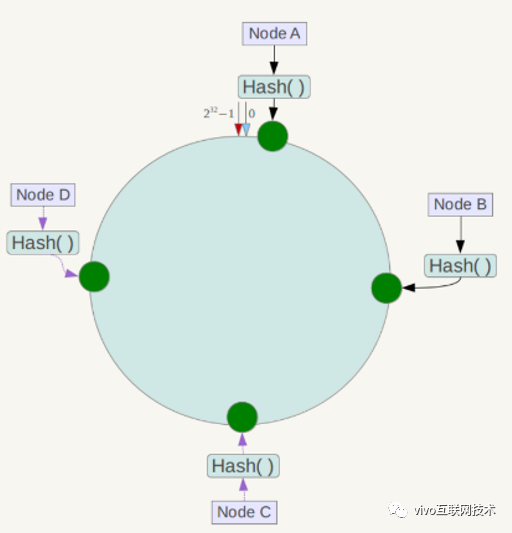
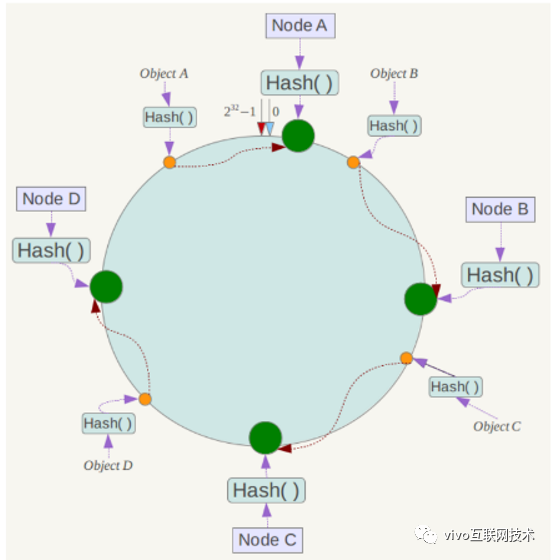
如图所示,先将存储节点通过 Hash 计算后添加到 DHT 环上,每个节点距离上一个节点间的这段区间,作为该节点的数据分区,Hash 值落在这个分区的数据将存储到这个节点上;
然后将数据通过 Hash 算法散列到 DHT 环上,数据落到 DHT 环上后,按照顺时针方向找到离自己最近的节点作为数据存储节点,如下所示,数据 ObjectA 落到节点 NodeA 上,数据 ObjectB 落到节点 NodeB 上;
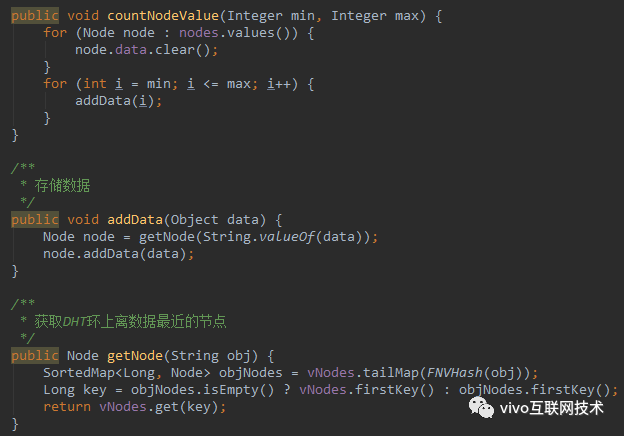
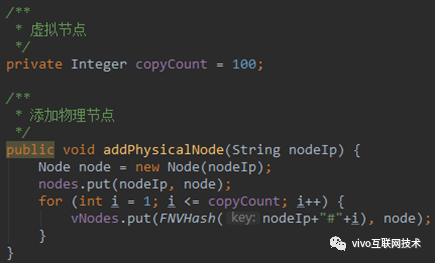
初始化 DHT 的源码如下:
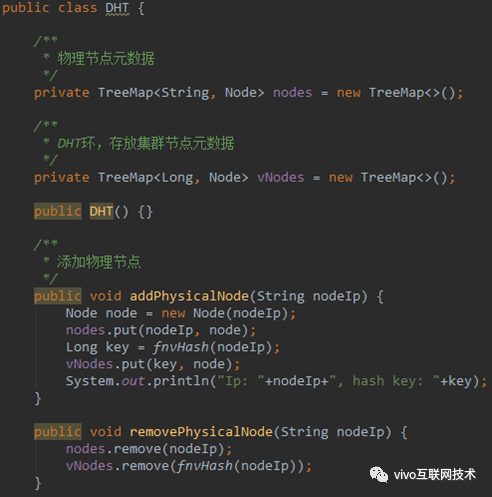
首先定义了一个存放集群节点元数据的 Map,用来存储接入到 DHT 环中的物理节点数据。然后定义了一个 DHT 环——vNodes,用来存储 DHT 环中的节点位置信息。这样我们就实现了一个简单的 DHT 环,通过 addPhysicalNode 方法可以模拟集群节点的加入。加入时会计算节点的 Hash 值并存放到 vNodes 中。
初始化 4 个存储节点。
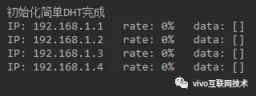
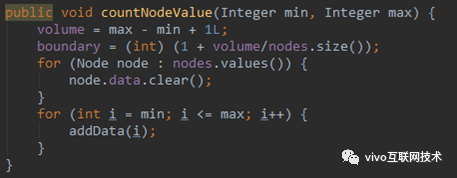
通过 countNodeValue 方法插入 100 条数据,在写数据的过程中,根据数据的 Hash 值找到 DHT 环上最近的一个节点,然后将数据写入该节点中。
插入 100 条数据后,各个节点的数据分布如下,可以看见 4 个节点的数据并不均匀,只有一个节点分配到了数据(这与写入的数据也有一定关系)。

插入 100 万条数据后,各个节点的数据分布如下,虽然每个节点都分配到了数据,但仍然出现了较大的数据倾斜。这将导致 99%的请求都会由 Node3 进行处理,出现一核有难三核围观的情况。

出现如上问题是什么原因呢?通过查看 DHT 环上各节点的 hash 值不难看出,各节点间距不均匀,插入的数据按顺时针查找节点时都找到了 Node3,因此数据都写到了 Node3 里面,所以节点区间不均匀会使某些节点能覆盖更多的数据,导致数据不均衡。
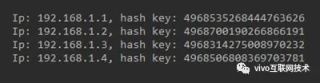
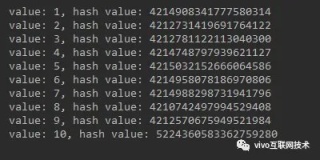
说了一个简单 DHT 环的基本原理后,再来思考一个问题:简单的 DHT 环数据离散,但仍然存在数据倾斜的情况,还不如用传统的 hash 方式分配数据。
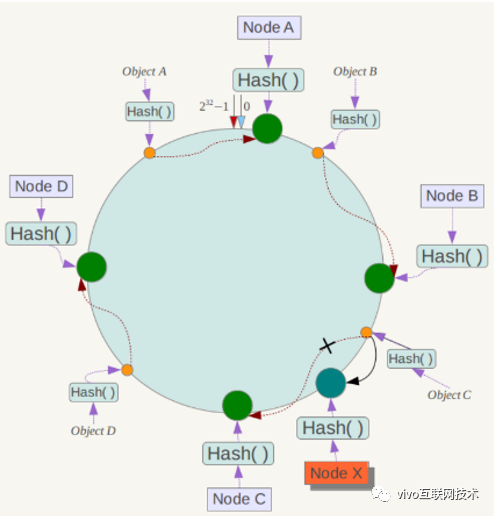
前面提到传统的 hash 方式在当时在节点故障后,整个集群的数据会进行大量的迁移,影响集群性能,那么 DHT 能解决这一问题吗?
我们还是用之前分配好的 100 万条数据,模拟节点 4 故障,如下图所示,Node4 上的数据只迁移到了 Node1,对 Node2 和 Node3 不产生数据迁移,从而降低了节点故障导致每个节点都需要进行数据迁移带来的影响。

五、DHT 的改进
1、虚拟节点
大家思考一下,解决数据倾斜的问题可以如何解决?
通过增加集群节点的方式最简单直接,目的是将更多的节点散列到 DHT 环上,使得环上所有节点分布更加均匀,节点间的区间间隔尽可能的均衡,以下是 10 个节点和 20 个节点集群的数据分布情况。
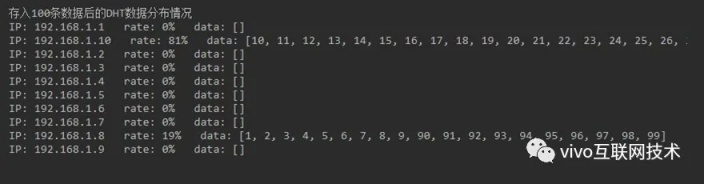
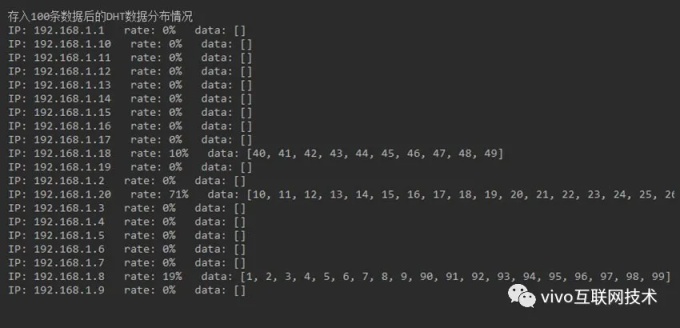
可以发现,通过增加节点的方式,仍然无法从根本上解决数据倾斜的问题。并且增加节点会提高集群的设备成本和维护成本。同时,这种方案还引出了一个严重的问题,如果 Node20 故障了,那么 Node20 的数据会全数迁移到下一个节点上,最终导致集群出现数据倾斜,数据较多的节点还将处理更多的 IO 请求,容易形成数据热点,成为性能瓶颈,引发集群整体的性能下降。

(2) 引入虚拟节点
为了解决数据倾斜的问题,引入了虚拟节点的概念。虚拟节点也就是真实节点的一个逻辑副本,如图所示,对节点 NodeA 进行 3 次虚拟节点 hash 分布,形成了虚拟节点 NodeA1、NodeA2、NodeA3。当 NodeA 故障后,指向 NodeA 的数据会指向 NodeB、NodeC。
当引入虚拟节点数量为 100 时,数据已经分散在各个节点上了,如果虚拟节点足够多,最终将达到数据均衡的状态。

虚拟节点数据 1 万时的数据分布:

虚拟节点数量为 100 万时的数据分布:

当 Node3 故障后,Node3 上的数据被均匀的分散到其他节点上,不会出现数据倾斜的情况。

2、负载边界因子
这样就完美了吗?我们初始化一个 4 个节点的 DHT 环,虚拟节点设置为 100,然后插入 100 条数据,并打印 DHT 环的元数据信息如下:

可以发现,虽然设置的虚拟节点,但是仍然无法均衡的将节点散列到 DHT 环上,导致 Node2 过载,Node 空闲。我们再思考一种极端场景,当我们的数据恰好计算 hash 值后都在区间 A,而这个区间只有 NodeA,那么仍然出现了数据倾斜。如何解决这个问题呢,这里我们引入一个叫负载边界因子的概念。DHT 环部署了 4 个节点,总共有 100 条数据要插入,那么平均下来每个节点的权重就是 100/4+1=26,当数据映射过程中达到了该节点的权重,则映射到下一个节点,下面是代码实现。
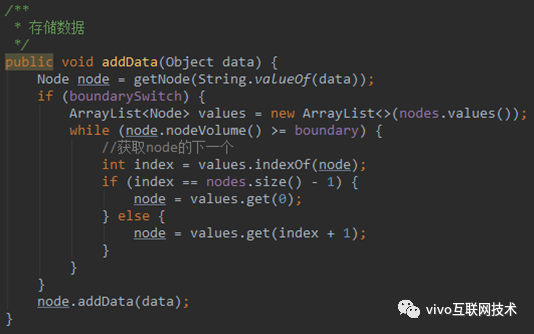
打开负载边界因子开关的情况:

在打开负载边界因子开关后,数据得到了较好的均衡。
六、DHT 引发的思考
上述的只是一个简单的 DHT,数据也做了简化,数据的存储和读取都需要查询 DHT 环,如何提升 DHT 的读写性能?如何提升 DHT 的高可靠?当节点故障后,如何将故障节点的数据迁移到新的节点?如何做好数据备份?如何保证副本数据不集中在一个节点上?也是需要去思考的,本文只是抛砖引玉简单的介绍了 DHT 基本的思想,更多生产环境面临的挑战,在此不做展开。
可以看到,DHT 提供了一种负载均衡的思路。利用 hash 算法的特性,将数据或业务请求分散到集群中的各个节点上,提高系统容错性。
vivo 用户运营开发团队
版权声明: 本文为 InfoQ 作者【vivo互联网技术】的原创文章。
原文链接:【http://xie.infoq.cn/article/43cb6e704b69fa7d1ab9add3e】。文章转载请联系作者。

官方公众号:vivo互联网技术,ID:vivoVMIC 2020.07.10 加入
分享 vivo 互联网技术干货与沙龙活动,推荐最新行业动态与热门会议。









评论 (3 条评论)