
支持向量机 - 二分类 SVC 中的样本不均衡问题:重要参数 class_weight
样本不均衡是指在一组数据集中,标签的一类天生占有很大的比例,但我们有着捕捉出某种特定的分类的需求的状况。比如,我们现在要对潜在犯罪者和普通人进行分类,潜在犯罪者占总人口的比例是相当低的,也许只有 2%左右,98%的人都是普通人,而我们的目标是要捕获出潜在犯罪者。这样的标签分布会带来许多问题。
首先,分类模型天生会倾向于多数的类,让多数类更容易被判断正确,少数类被牺牲掉。因为对于模型而言,样本量越大的标签可以学习的信息越多,算法就会更加依赖于从多数类中学到的信息来进行判断。如果我们希望捕获少数类,模型就会失败。
其次,模型评估指标会失去意义。这种分类状况下,即便模型什么也不做,全把所有人都当成不会犯罪的人,准确率也能非常高,这使得模型评估指标 accuracy 变得毫无意义,根本无法达到我们的“要识别出会犯罪的人”的建模目的。
所以现在,我们首先要让算法意识到数据的标签是不均衡的,通过施加一些惩罚或者改变样本本身,来让模型向着捕获少数类的方向建模。然后,我们要改进我们的模型评估指标,使用更加针对于少数类的指标来优化模型。对于支持向量机这个样本总是对计算速度影响巨大的算法来说,我们不想轻易地增加样本数量。况且,支持向量机中地决策仅仅受到决策边界的影响,而决策边界又仅仅受到参数 C 和支持向量的影响,单纯地增加样本数量不仅会增加计算时间,可能还会增加无数对决策边界无影响的样本点。因此在支持向量机中,我们要大力依赖我们调节样本均衡的参数:SVC 类中的 class_weight 和接口fit 中可以设定的 sample_weight。在 SVM 中,我们的分类判断是基于决策边界的,而最终决定究竟使用怎样的支持向量和决策边界的参数是参数 C,所以所有的样本均衡都是通过参数 C 来调整的。
SVC 的参数:class_weight
可输入字典或者"balanced”,可不填,默认 None 对 SVC,将类 i 的参数 C 设置为class_weight [i] * C。如果没有给出具体的class_weight,则所有类都被假设为占有相同的权重 1,模型会根据数据原本的状况去训练。如果希望改善样本不均衡状况,请输入形如{"标签的值1":权重1,"标签的值2":权重2}的字典,则参数 C 将会自动被设为:标签的值1的C:权重1 * C,标签的值2的C:权重2*C或者,可以使用“balanced”模式,这个模式使用 y 的值自动调整与输入数据中的类频率成反比的权重为n_samples/(n_classes * np.bincount(y))
说一下 np.bincount,计数非负整数数组中每个值的出现次数。
import numpy as np a = [1,2,3,5,1,3,1,1,9] b = np.bincount(a) b --- array([0, 4, 1, 2, 0, 1, 0, 0, 0, 1], dtype=int64)对于它的返回值,一维 array 的索引和索引对应的元素值组成一对,例如上例,b[0]=0,即在 a 中数值 0 出现的次数为 0 次;b[1]=4,即在 a 中数值 1 出现的次数为 4 次注意只能接收非负整数,其余值报错因此对于我们“balanced”模式中
n_samples/(n_classes * np.bincount(y)),其实也是一个类似字典的对象,key 就是索引,value 就是元素值
SVC 的接口fit 的参数:sample_weight
数组,结构为 (n_samples, ),必须对应输入fit 中的特征矩阵的每个样本每个样本在fit 时的权重,让权重 * 每个样本对应的C值来迫使分类器强调设定的权重更大的样本。通常,较大的权重加在少数类的样本上,以迫使模型向着少数类的方向建模
通常来说,这两个参数我们只选取一个来设置。如果我们同时设置了两个参数,则 C 会同时受到两个参数的影响,即class_weight中设定的权重 * sample_weight中设定的权重 * C
利用数据集,观察使用 class_weight 前后的效果
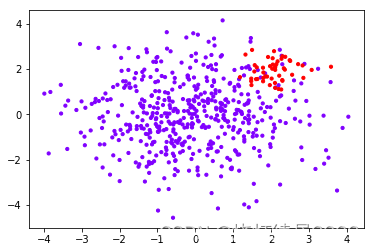
分别建模并比较
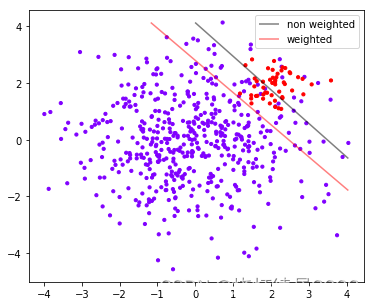
从图像上可以看出
灰色是我们做样本平衡之前的决策边界。灰色线上方的点被分为一类,下方的点被分为另一类。可以看到,大约有一半少数类(红色)被分错,多数类(紫色点)几乎都被分类正确了。
红色是我们做样本平衡之后的决策边界,同样是红色线上方一类,红色线下方一类。做了样本平衡后,少数类几乎全部都被分类正确了,但是多数类有许多被分错了。
再根据之前 score 的值,我们可以得出结论,不做样本平衡的时候准确率反而更高,做了样本平衡准确率反而变低了。这是因为做了样本平衡后,为了要更有效地捕捉出少数类,模型误伤了许多多数类样本,而多数类被分错的样本数量 > 少数类被分类正确的样本数量,使得模型整体的精确性下降。现在,如果我们的目的是模型整体的准确率,那我们就要拒绝样本平衡,使用 class_weight 被设置之前的模型。
a.collections # 返回一个惰性对象,是一个列表,列表里面有一条线,因为上面levels=[0]代表只绘制一条线,这条线代表高度值为0 --- <a list of 1 mcoll.LineCollection objects> [*a.collections] # 里面就是等高线例所有的线的列表 --- [<matplotlib.collections.LineCollection at 0x1d71110b5c0>] # 现在我们只有一条线,所以我们可以使用索引0来锁定这个对象 a.collections[0]
然而在现实中,我们往往都在追求捕捉少数类,因为在很多情况下,将少数类判断错的代价是巨大的。比如我们之前提到的,判断潜在犯罪者和普通人的例子,如果我们没有能够识别出潜在犯罪者,那么这些人就可能去危害社会,造成恶劣影响,但如果我们把普通人错认为是潜在犯罪者,我们也许只是需要增加一些监控和人为甄别的成本。所以对我们来说,我们宁愿把普通人判错,也不想放过任何一个潜在犯罪者。
视频作者:菜菜TsaiTsai链接:【技术干货】菜菜的机器学习sklearn【全85集】Python进阶_哔哩哔哩_bilibili
版权声明: 本文为 InfoQ 作者【烧灯续昼2002】的原创文章。
原文链接:【http://xie.infoq.cn/article/430303c2411598277a90d1d20】。
本文遵守【CC-BY 4.0】协议,转载请保留原文出处及本版权声明。

跃入人海 2022-09-14 加入
还未添加个人简介








评论