
云原生时代数据库技术趋势与场景选型
在 10 月 26 日 2022 全球分布式云大会上,OceanBase 架构师 郑赫扬发表了题为《小就是大,OceanBase 单机到分布式一体化与最佳实践》的精彩演讲,分享了云原生时代数据库技术趋势与场景选型,单机一体化核心设计理念及实践。
以下为演讲实录。
云原生 大势所趋
云原生-技术变革,一定是思想先行
第一个话题,未来的趋势是云原生,我理解技术变革一定是思想先行,稳定的 IT 到现在的敏捷态 IT、DevOps。云原生技术变革,从过去大型的单机应用到第二代微服务,到未来的 Serverless、微服务的粒度隔离、资源池化、服务敏捷部署,这是未来云原生的发展趋势。
云原生 CloudNative,我理解是一套技术体系和方法论,Cloud 是应用和数据都不在数据中心,而在云中;Native 设计之初考虑云环境进行构造,以云的最佳姿态运行。资源池化,弹性和分布式是核心优势。非原生到云原生的转化概念,一是 DevOps 迭代与运维自动化,弹性伸缩、动态调度、资源利用;二是微服务,Service mesh、声明式 API 和 OAM 模型定义组建;三是容器化类似 Docker+K8s.四是持续交付,快速交付、快速反馈。
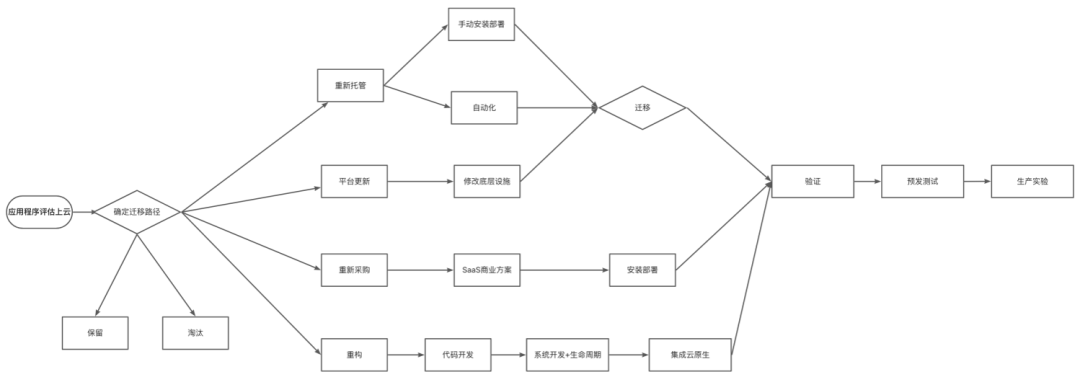
企业上云的六大策略,重新托管、平台更新、SaaS 化采购、重构、淘汰、保留,淘汰和保留是不讨论的,正常重新托管相当于做云管理人员要写一套新的组件组建。平台更新是修改底层设施,SaaS 化采购直接购买云厂商服务。重构涉及到代码开发、系统开发、生命周期。最后集成云原生一套完整的体系。
云原生数据库趋势与技术流派
什么是云原生数据库?
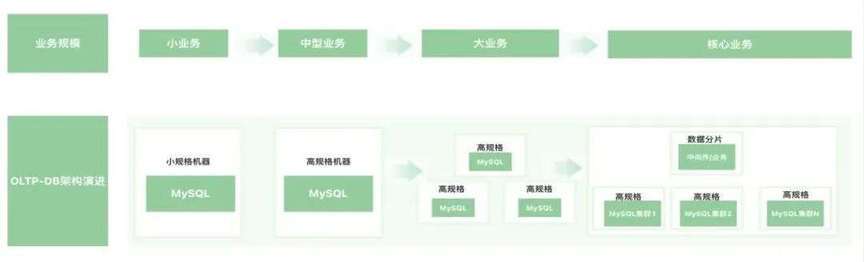
传统的单机关系型数据库,MySQL、PostgreSQL,面对海量的数据和并发常见方式只有两种,“加”和“拆”,加就是升级 CPU、磁盘、内存,单机规模提高;拆就是读写分离、分库分表。这些是基于上一个时代的策略,缺点也很明显,成本不友好,资源浪费;再者对开发和运维的负担过大,分库分表、数据量级治理、资源瓶颈扩容、业务拆分,每次资源扩容工作量极大。业务规模从 MySQL 到小规机器格到高规格分库分表。
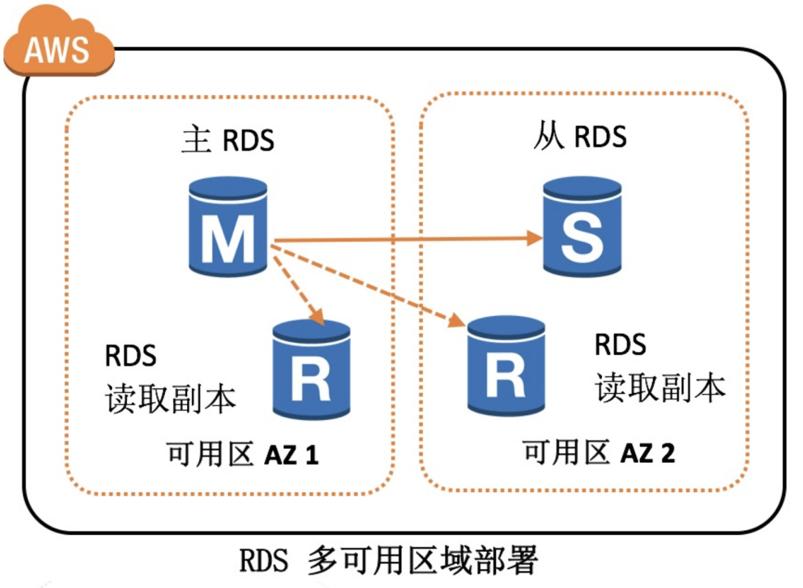
到了下一代云上 PaaS 数据库,相当于直接把数据库搬到云上方便使用。2019 年 AWS 发布的 RDS,云上 RDS 的缺点是不能发挥云的优势,利用率低,且维护成本高,本质上是厂商帮用户维护了一个 MySQL;不过,RDS 是多可用区部署,可以解决多地域部署的问题。
下一阶段的云原生数据库,核心特性包括资源池化(资源的时分复用,大体量下的成本节约)、弹性(业务按需付费和无缝扩缩容)。代表产品有 OceanBase、PolarDB、TiDB、Amazon Aurora 以及 snowflake。
云原生数据库技术流派
Share-nothing
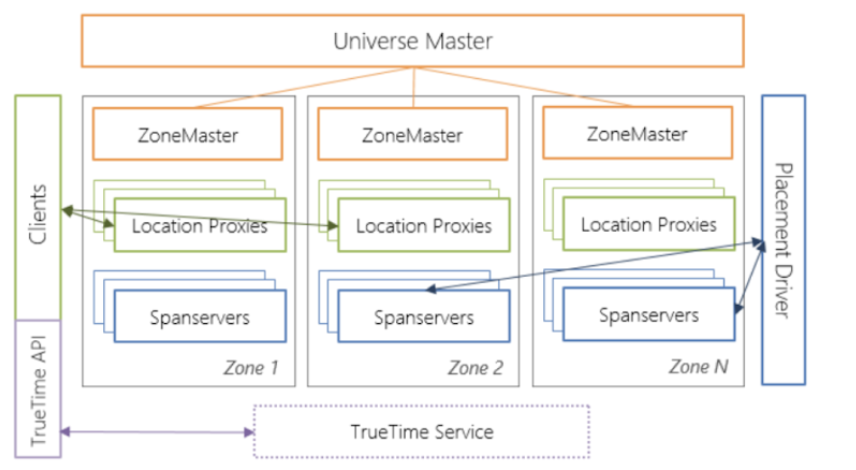
早期 Google 产品 Spanner,无限弹性水平扩展,包括分布式事务支持,跨数据中心级别容灾,几台机器一个软件就可以搞定一个云原生数据库。这一类技术流派代表性主流产品有 OceanBase、CockroachDB、TiDB 等。
Share-storage
AWS Aurora、PolarDB 是云上的 SaaS 化数据库,存算分离。上层是计算层,负责业务的访问,下层是分布存储层,一个大的存储资源池+分布式文件系统,形成一个下面存数据上面计算的架构。存算分离,计算和存储层要交换数据所以对网络带宽要求很高,一般存算分离的都是公有云产品.不足之处是私有云入手成本很高,还是要维护存储层分布式文件系统.
核心设计理念
AWS Aurora
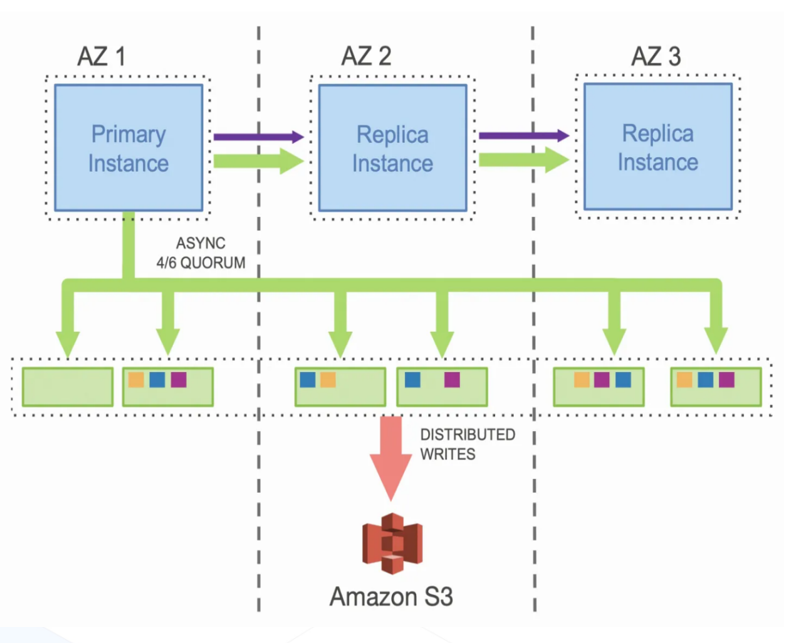
AWS Aurora 云上构建数据库,核心理念是减少网络传输量,实例与存储交互通过网络所以瓶颈在网络。核心优化通过云上部署 IO flow 通过 Redo log 做复制,减少 IO 链路;日志复制变少,IO 变少,网络包变小让吞吐效率提升;主副实例共享一套数据,增加实例副本 0 存储成本即可提高扩展性;存储节点跨 AZ 高可用。
TiDB
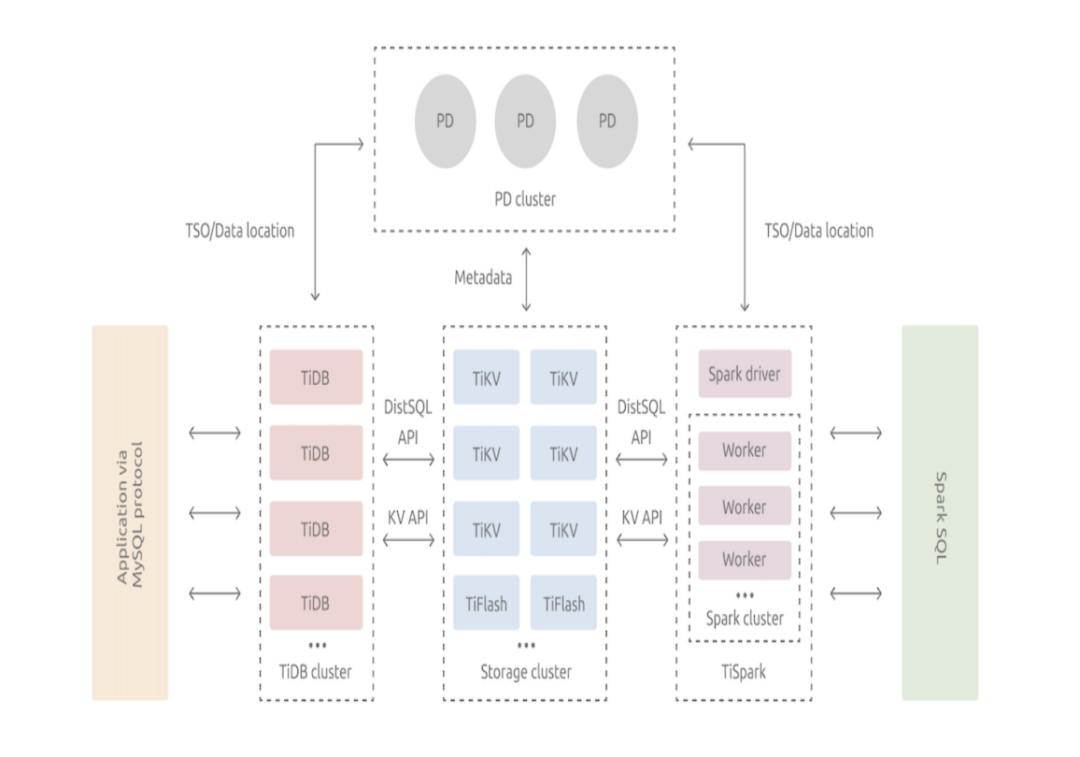
TiDB 核心理念是高度解耦、高度弹性、组件模块化,是纯分布式架构,各个组件都是模块化的,Raft 协议,自动数据均衡,周边生态丰富,不足是分布式事务+高解耦网路交互多,网络通讯可能过多。
SnowFlake
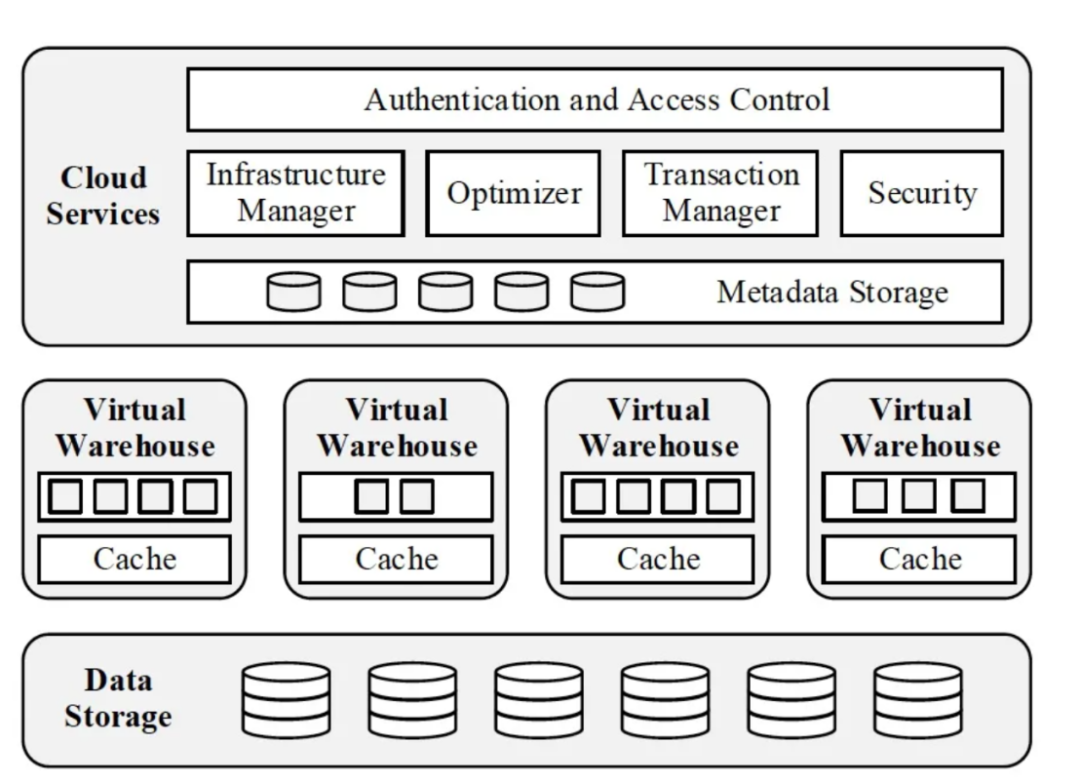
Snowflake 的核心理念是 multi-cluster + shared data,核心特点是多租户,弹性;计算层 share nothing cluster;存储层 S3 块存储,可用性持久性好,延迟高,吞吐大,成本低;少量配置和用户运维,私有度高。
OceanBase 的云原生设计理念
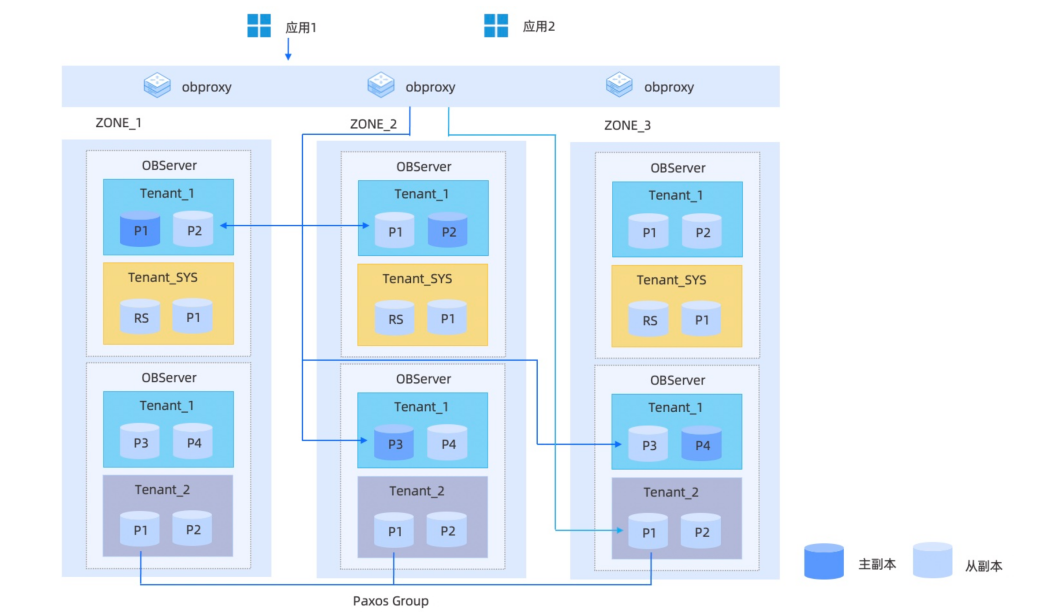
OceanBase 是一款 Share-nothing 产品,资源池化+数据库内多租户,相当于把云交给用户,私有云部署机器资源放在 OceanBase 形成资源池,相当于在内部形成了云的资源概念,多租户划分资源并且随时可"弹"。OceanBase 核心特点包括资源池化、多租户、paxos 协议、高性能、高可用、低成本,私有云、混合云、公有云都可以部署。
OceanBase 的内核:Paxos 协议+无共享架构+分区级高可用
多副本:部署为三个或五个 Zone,每个 Zone 由多个数据库节点(OBServer)组成;
全对等节点:每个数据库节点均有自己的 SQL 引擎和存储引擎,各自管理不同的数据分区,完全对等;
无共享:数据分布在各个节点上,不基于任何共享存储结构(share-nothing);
分区级可用性:可靠性与扩展性的基本单元,自动流量路由、负载均衡、故障转移;
高可用 + 强一致:多副本 + Paxos 分布式选举协议的金融级实现, 保证数据(日志)持久化到多数派节点。
核心设计理念-线性扩展
方式一: 扩容 Zone 内节点数
只要在 OceanBase 集群内添加服务器,加入资源池里,修改租户的 Unit 数,数据就会自动均衡,可以提升集群数据存储容量、可提升集群计算和负载能力,集群读写吞吐量提升百分比≈新增节点 CPU 核数/现有集群 CPU 总核数。
方式二:扩容 Zone 个数
集群级别追加 zone,数据自动进行复制,自动选出 Leader,可提升集群容灾能力水平(容忍更多副本故障)、可提升集群计算/负载能力,集群读吞吐量提升百分比≈新增节点 CPU 核数/现有集群 CPU 总核数。
OceanBase 采用线性设计,三副本、五副本,多加两个中心,五副本架构就可以保证每个区域的机房是不会宕机,蚂蚁支付宝内部是三地五中心的架构。
核心设计理念-多租户隔离
OceanBase 和所有数据库都不太一样的地方,是数据库内实现多租户隔离的。带来的好处一是大集群,将长尾应用的多实例 MySQL/Oracle 统一进行管理,有效提高资源密度,消除存储碎片。 二是多租户实现数据库内核级虚拟化,满足数据安全隔离的同时,提供基于业务画像的可伸缩计算资源,做到内核级虚拟化和 CPU 内存隔离,即将发布的 OceanBase 4.0 做到 IOPS 隔离,全资源池化与弹性化。
图为 OCP 的实际应用图,通过 OCP 管理平台管理 A 业务和 B 业务的库相对应的资源池,在平台上简单操作或者设定预先的阈值即可达到自动弹性扩缩容。
核心设计理念-Partition 分区与多副本类型
OceanBase 根据业务特性对数据分区,可以通过 PG(Partition Group 进行最佳业务模型优化),把选择交给了业务与 DBA;内涵全能型副本,只读副本等四种类型副本满足数据安全/性能伸缩/可用性/成本等各方面需求,业务根据需求自由选择。
核心设计理念-数据编码与压缩
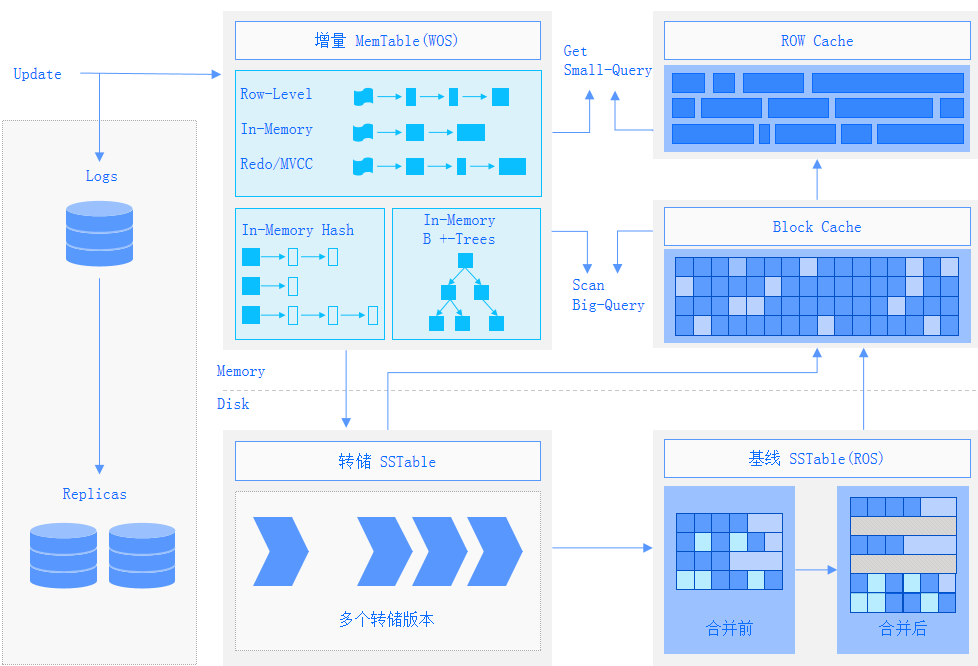
LSM 存储引擎,分为基线数据+增量数据两部分。对比 MySQL 能减少三分之二的存储成本;也可以选择其他压缩算法,根据业务场景的数据解压缩速率要求,OceanBase 把所有的选择权交给用户,可以实现极致场景下的极致性能。
核心设计理念-单机分布式一体化
OceanBase 4.x 时代实现了从 5%的分布式场景扩展到了 100%的 HTAP 场景,特性即可分布式也可单机版小型化,最小规格是 4C8G,和 MySQL 的 TP 性能一致,AP 和存储成本比 MySQL 有极大优势。这样带来的好处是业务量小的时候可以用 OB 的小型化单机部署;随着业务量扩张,只要增加机器,就可以平滑过渡成分布式,OLTP 场景或 HTAP 场景都可以使用,一次性解决"加和拆"的所有痛点!
同事新一版的 OceanBase 的 4.X RTO 基于全新的选举与探活机制由 30 秒优化到 8 秒。
功能完善方面,OB4.x 做为分布式数据库具备原生主备库能力,类似 MySQL 的主从,可以解决多机房多云跨地部署的延时场景。
OceanBase 带来的是 HTAP 全场景覆盖,所有的核心系统,无论是大中小型企业都可以开箱即用,成本骤减,同时管理运维用 OCP 就足够了。
性能提升方面,OceanBase 4.0 读写相比之前 3.x 提升了 50%,如果单纯看写,提升了大概 80%,对日志流也做了极大的优化。
易用性方面,增加了全链路追踪能力,可以帮助业务迅速定位问题根因,支持粒度到 SESSION 级别诊断。
支付宝 OceanBase 大规模实践
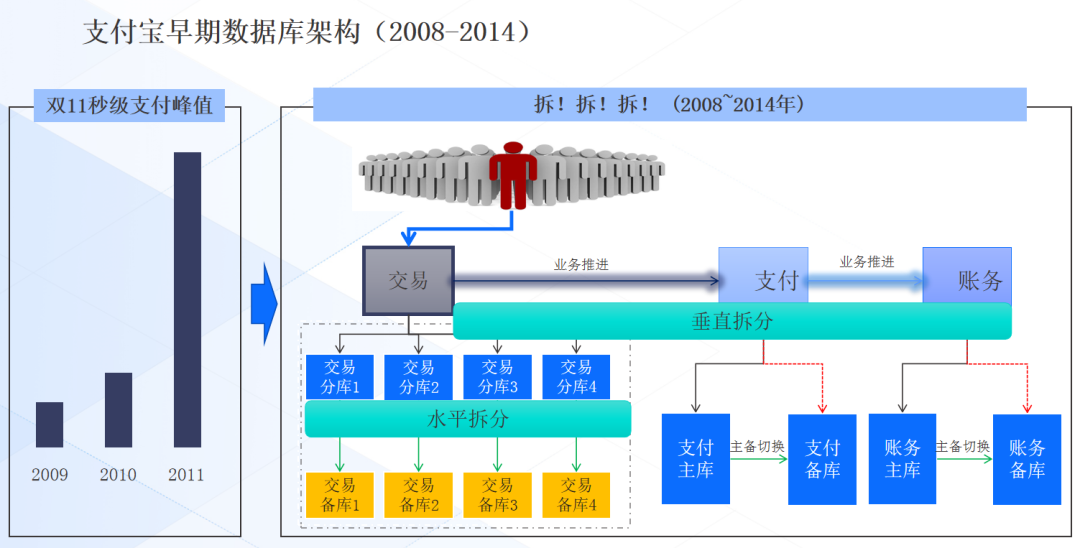
支付宝是国内早期大规模使用 MySQL 的企业,当时“加和拆”是最常用的手段,刚开始加机器,数据量大了就得拆,拆了以后交易库和支付库还要做主备切换、数据验证,痛点很多。支付宝巅峰时候大概十万套 MySQL 集群,使用极不方面。
针对蚂蚁集团替换 MySQL 的痛点和需求。
现有架构 MySQL 老牌 OLTP,技术熟悉,稳定可靠,有二十多年历史,InnoDB 存储引擎,生态也很稳定,场景也丰富。但这套架构痛点很多,或者说 MySQL 本身很脆弱,主备集群方面会切换丢失,老牌技术 MHAGTID 模式也有源码缺陷,MGR 网络环境抖动,同城和异地容灾切换数据丢失;分库分表上,基于中间件入侵 DBA,不基于中间件入侵业务,人力成本投入非常高。
最后经过整理,蚂蚁内部认为需要这样一个数据库:
1.原生支持三地多中心架构;2.原生支持高可用,45 秒 RTO,0 RPO;3.性能线性扩展 ;4.数据库内多租户隔离,一个大部门一个数据库集群就可以解决资源冗余问题;5.Partition 分区,不造成业务入侵解决分库分表问题;6.提供轻量 HTAP 能力,降本增效;7.DDL 对业务无感,可随时执行。
OceanBase 出生就具备了这些特性,解决痛点同时保证核心场景稳定运行。
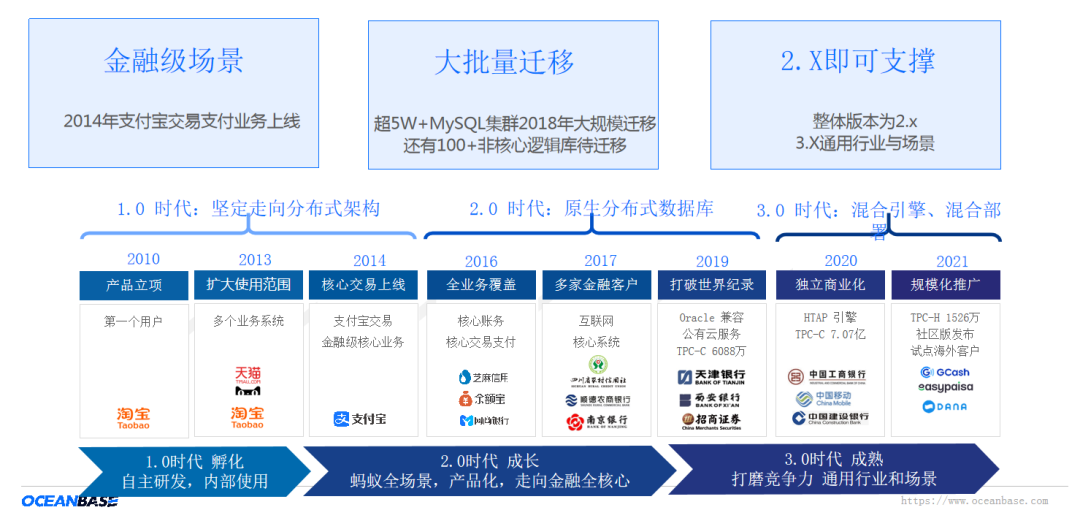
OceanBase 诞生之后,在支付宝经过了十年打磨,2014 年支付宝的核心交易系统在 OceanBase 上线,2018 年底,约有十万多套 MySQL 迁移,最新的进展还有 100 个非核心 MySQL 库待迁移,内部使用的一直是 2.X 版本;3.X 更具有行业通用性质。马上与大家见面的 4.0 版本目前蚂蚁集团已经开始使用。OceanBase 现在目前最大规模达到数据节点 1500➕,单个库 6PB, QPS 6100W,这是经过核心场景验证的 OceanBase 可支撑能力。
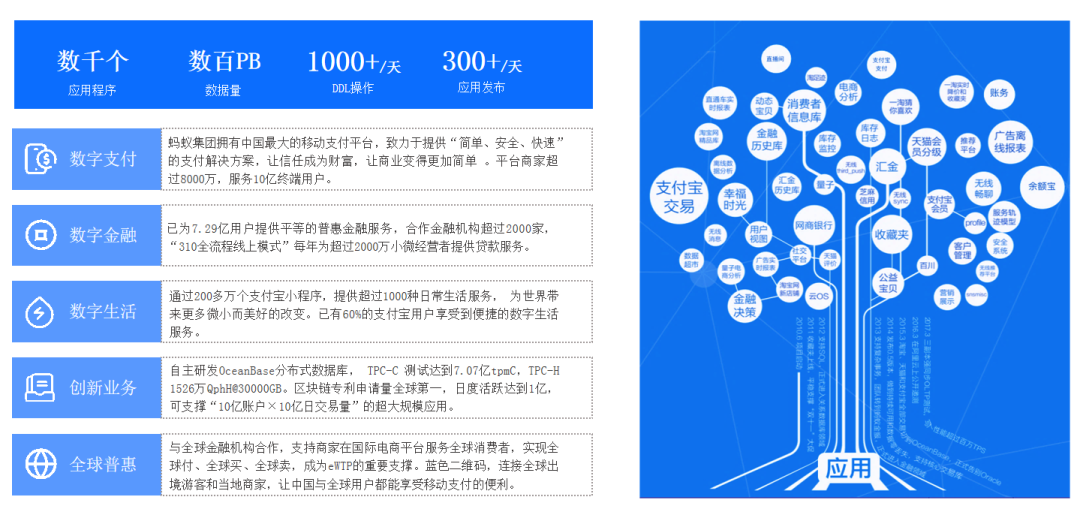
OceanBase 现在承载了蚂蚁集团 100%的核心业务,数千个应用程序,数百 PB 数据量,1000+DDL 操作,300+天应用发布,支付宝和蚂蚁集团所有的数据都是在 OceanBase 上,每天都有海量的业务在跑,稳定性和场景的验证性是毋庸置疑的。
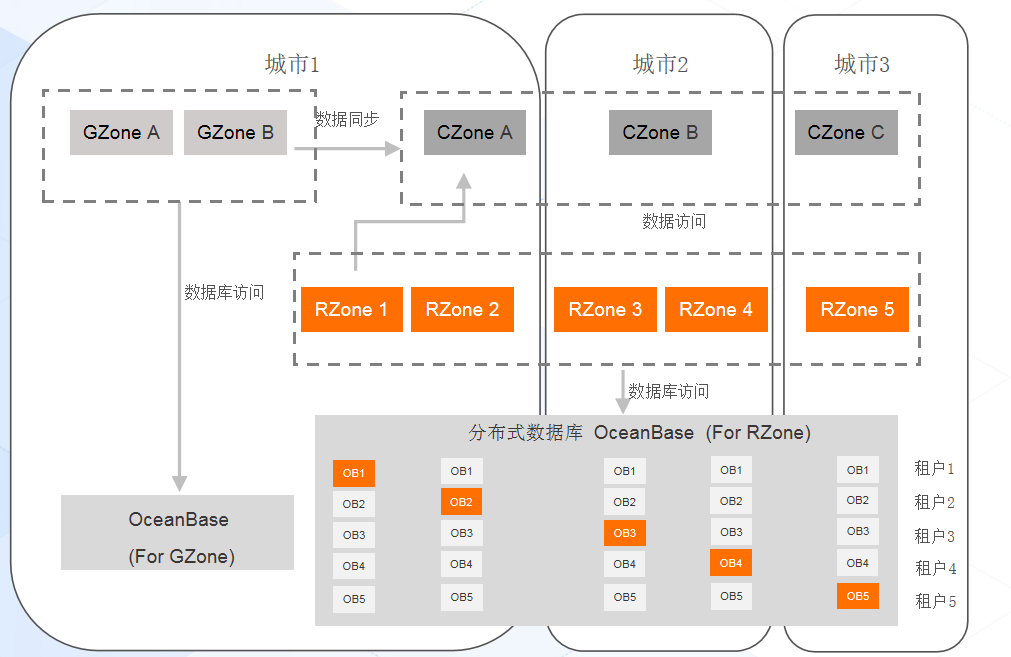
上图是蚂蚁集团内部的 LDC 单元化部署架构,数据分三份,Gzone 和 Czoen 和 RZone。蚂蚁集团典型的支付宝是三地五中心架构,一个 zone 有 20%的服务流量,如果在三点凌晨交易系统交易卡了几秒,是因为内部有混沌工程实验,其规模相当于突然爆破了一整个城市,导致整个城市机房不可用后 OB 高可用快速恢复。对于三地五中心场景,每个月都有真实的场景去演练进行效果验证。
OceanBase 尽管已经在内部研发十年,但商业化的时间只有两年,金融方面,中国人寿、建行、工行、浦发银行、海底捞、理想、携程、星巴克等都是 OceanBase 的用户。开源方面,OceanBase 300 万行代码都是开源的,连接的用户 33000 家,客户包括快手、贝壳、携程、浦发银行等等,很多客户在使用 OceanBase 的时候,基本上是企业版和社区化一起用。
OceanBase 的定义就是企业级原生分布式数据库,支持私有云部署。OceanBase 对于公有云,如果从 RDS 迁到 OceanBase 节省成本将超过 30%。
演讲最后,郑赫扬老师总结说,云原生大势所趋,是下一代的技术方向。云原生数据库为企业未来的资源池化+弹性+容灾等等提供了数据底座。数据库的云原生,核心思想与技术选型决定了产品核心特性。
无论是 share-nothing,share-storage 都是基于不同的对云原生理解衍生出的数据产品。但目前对数据产品和场景选型来说,暂时没有银弹,场景为王,匹配企业云原生技术架构与场景的数据库就是好数据库。

企业级原生分布式数据库 2020-05-06 加入
github:https://github.com/oceanbase/oceanbase 欢迎大家








评论