第十三周总结
1. Spark
1.1 Spark为什么比MapReduce快
Spark 和 MapReduce 进行逻辑回归机器学习的性能比较,Spark 比 MapReduce 快 100 多倍。
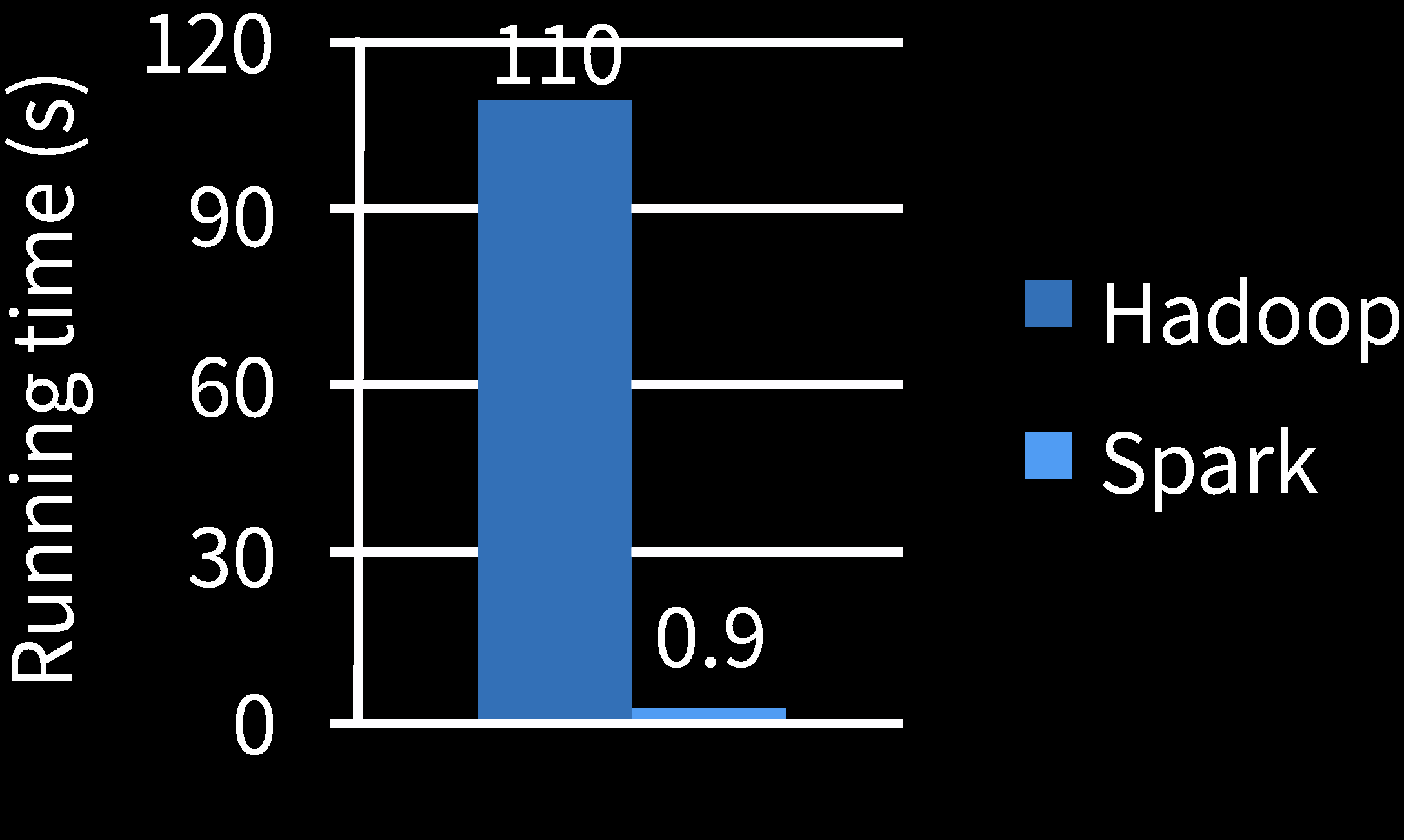
主要原因:
DAG切分的多阶段计算过程更快速
使用内存存储中间计算结果更高效
RDD的编程模型更简单
类比一下:MapReduce更像是面向过程的大数据计算(我们需要思考如何将计算逻辑用 Map 和 Reduce 两个阶段实现,map 和 reduce 函数的输入和输出是什么),而Spark更像是面向对象的大数据计算(我们需要思考的是一个 RDD 对象需要经过什么样的操作,转换成另一个 RDD 对象)。
1.2 Spark生态体系

SparkSQL:支持 SQL 语句的操作(类似Hive)
Spark Streaming:支持流计算(类似Storm)
MLlib:支持机器学习
GraphX:支持图计算
1.3 Spark架构原理
Spark 可以根据应用的复杂程度,分割成更多的计算阶段(stage),这些计算阶段组成一个有向无环图 DAG,Spark 任务调度器可以根据 DAG 的依赖关系执行计算阶段。
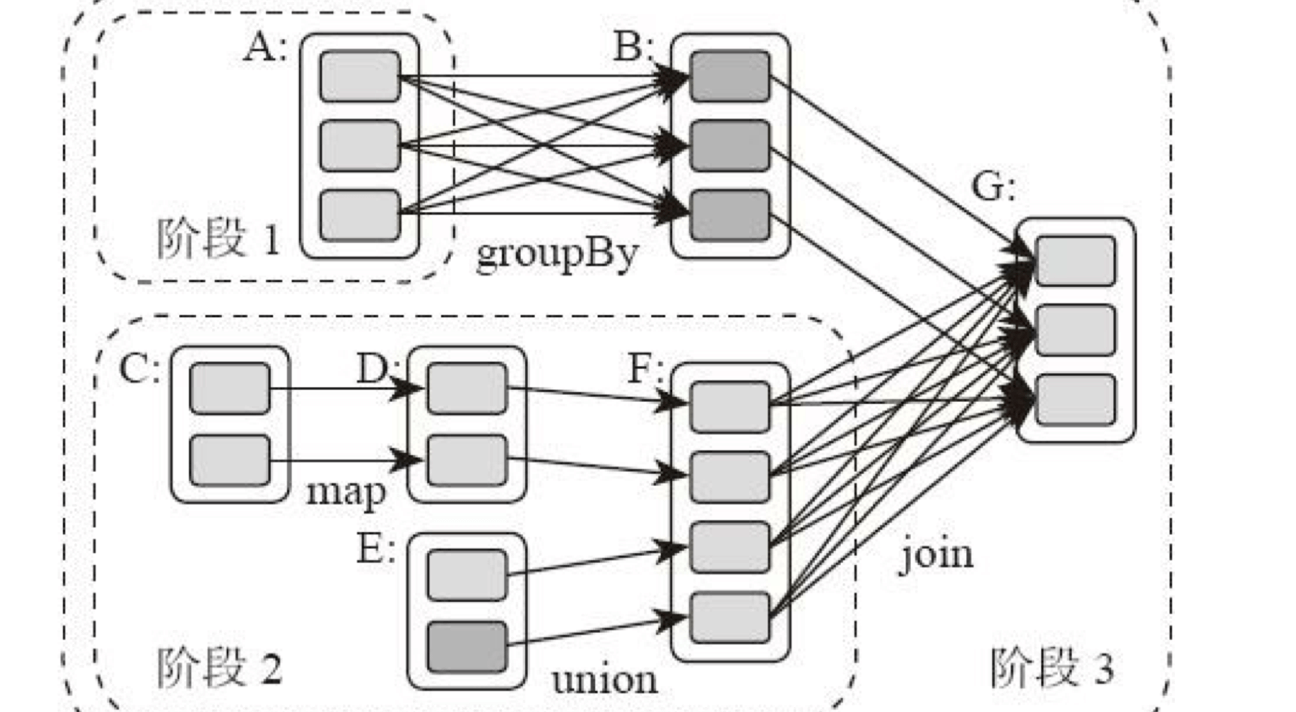
Spark 在执行调度的时候,先执行阶段 1 和阶段 2,完成以后,再执行阶段 3。
Spark 通过 shuffle 将数据进行重新组合,相同 Key 的数据放在一起,进行聚合、关联等操作,因而每次 shuffle 都产生新的计算阶段。
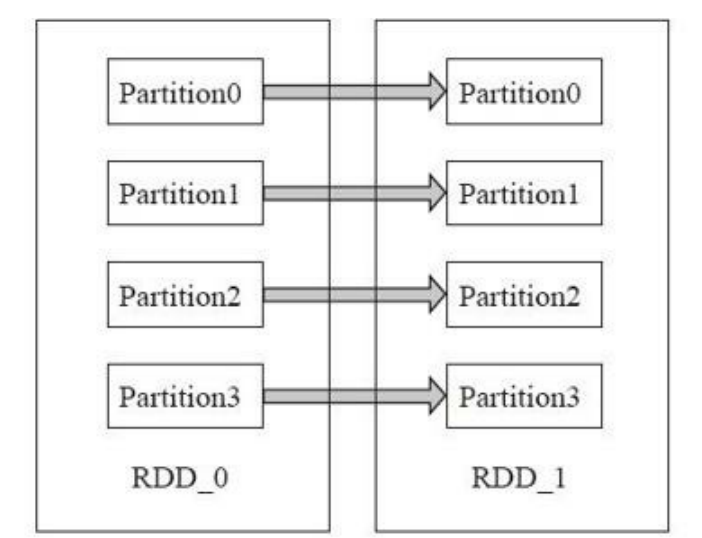
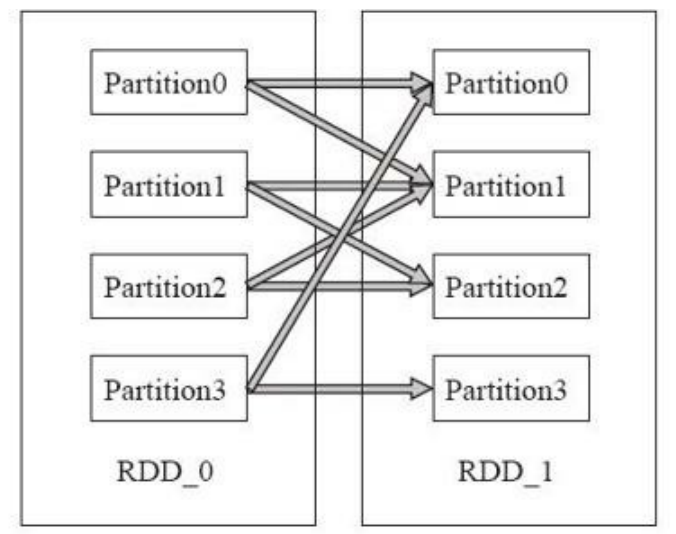
不需要进行 shuffle 的依赖,在 Spark 里被称作窄依赖;需要进行 shuffle 的依赖,被称作宽依赖。
窄依赖:
宽依赖:
1.4 Spark执行过程
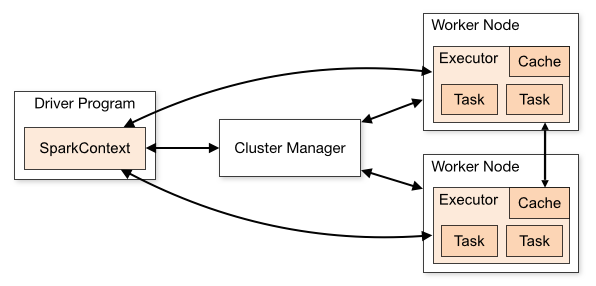
2. 流计算
2.1 什么是流计算
大数据实时处理跟大数据批处理计算最大的不同就是这类数据跟存储在 HDFS 上的数据不同,是实时传输过来的,或者形象地说是流过来的,所以针对这类大数据的实时处理系统也叫大数据流计算系统。
大数据流计算框架有 Storm、Spark Streaming、Flink。
主要特点:
低延迟
高性能
分布式
可伸缩
高可用
2.2 Storm
Storm架构:
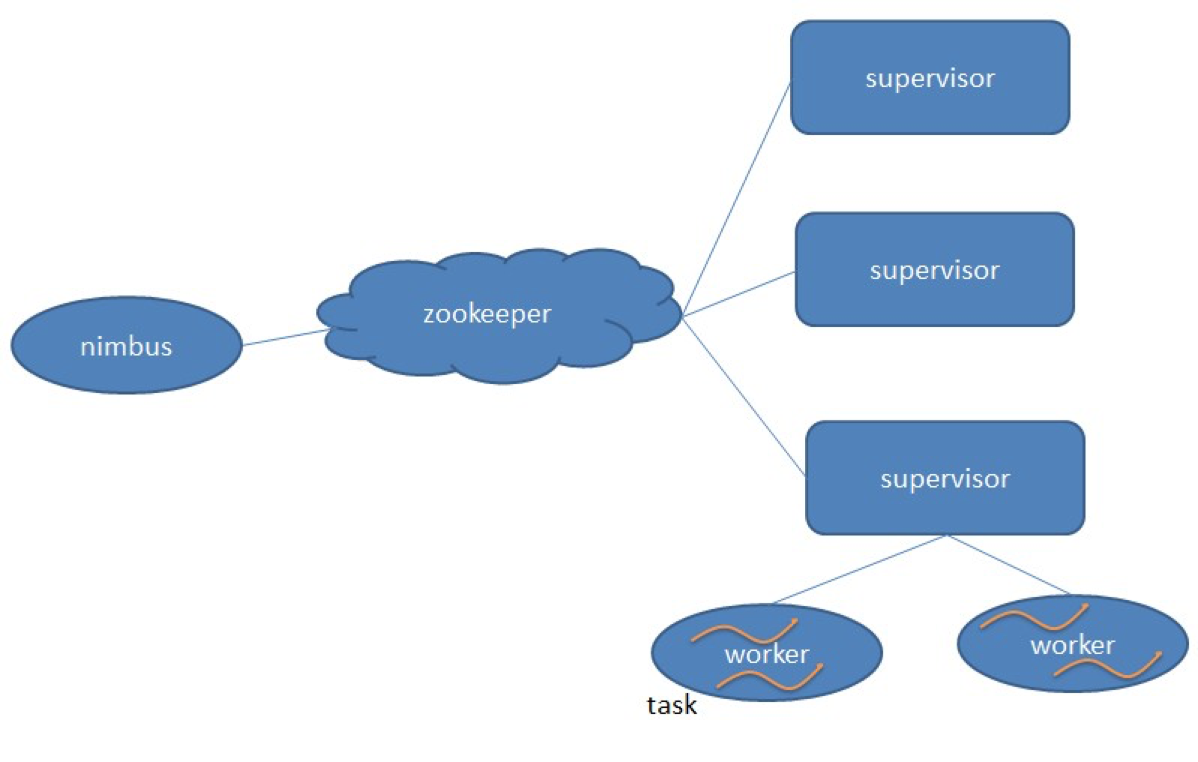
nimbus 是集群的 Master,负责集群管理、任务分配等。
supervisor 是 Slave,是真正完成计算的地方,每个 supervisor 启动多个 worker 进程,每个 worker 上运行多个 task,而 task 就是 spout 或者 bolt。
supervisor 和 nimbus 通过 ZooKeeper 完成任务分配、心跳检测等操作。
2.3 Spark Streaming
Spark Streaming 巧妙地利用了 Spark 的分片和快速计算的特性,将实时传输进来的数据按照时间进行分段,把一段时间传输进来的数据合并在一起,当作一批数据,再去交给 Spark 去处理。

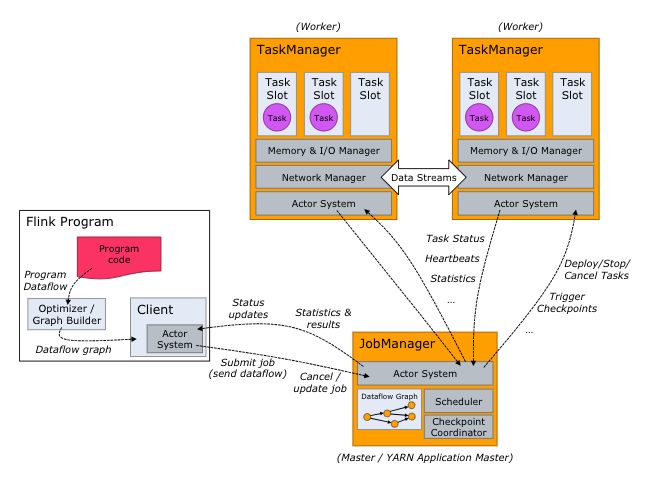
2.4 Flink
Flink 处理实时数据流的方式跟 Spark Streaming 也很相似,也是将流数据分段后,一小批一小批地处理。流处理算是 Flink 里的“一等公民”,Flink 对流处理的支持也更加完善,它可以对数据流执行 window 操作,将数据流切分到一个一个的 window 里,进而进行计算。
3. 数据分析
3.1 互联网运营常用的数据指标
新增用户数
用户留存率
用户流失率
活跃用户数
PV
GMV(Gross Merchadise Volume 成交总金额)
转化率
3.2 数据展示形式
折线图
散点图
热力图
漏斗图
4. 数据挖掘与机器学习
4.1 网页排名PageRank算法
参考作业:https://xie.infoq.cn/article/abb9eb25741332e166962ffeb
4.2 分类算法
KNN分类算法
贝叶斯分类算法
K-means聚类算法
SVM
4.3 推荐引擎算法
基于人口统计的推荐
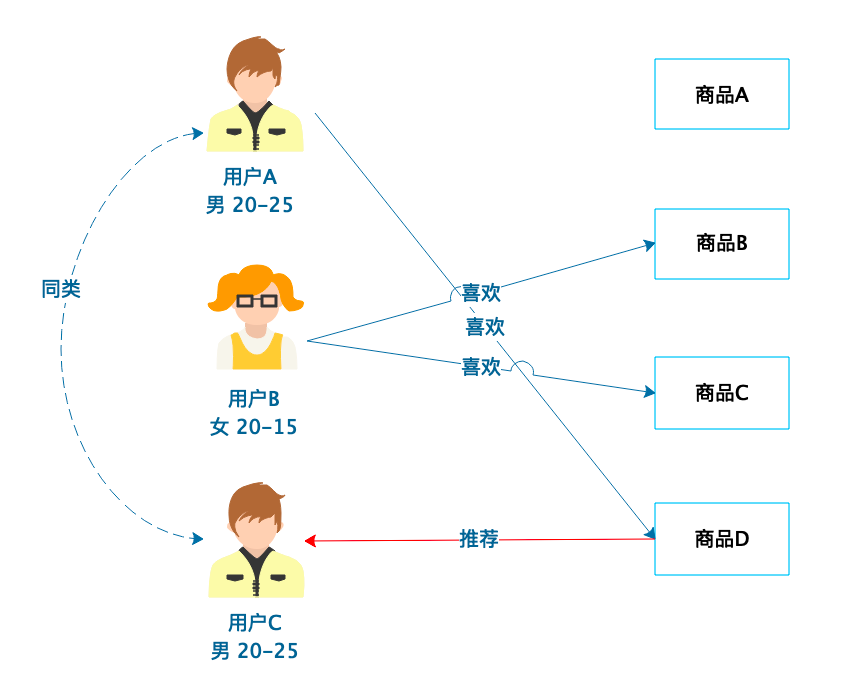
基于商品属性的推荐
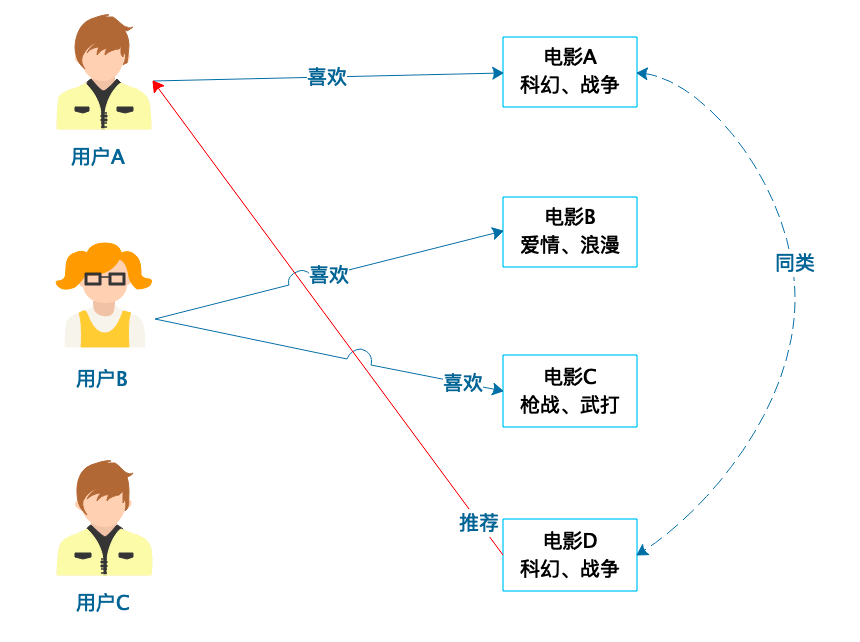
基于用户的协同过滤推荐
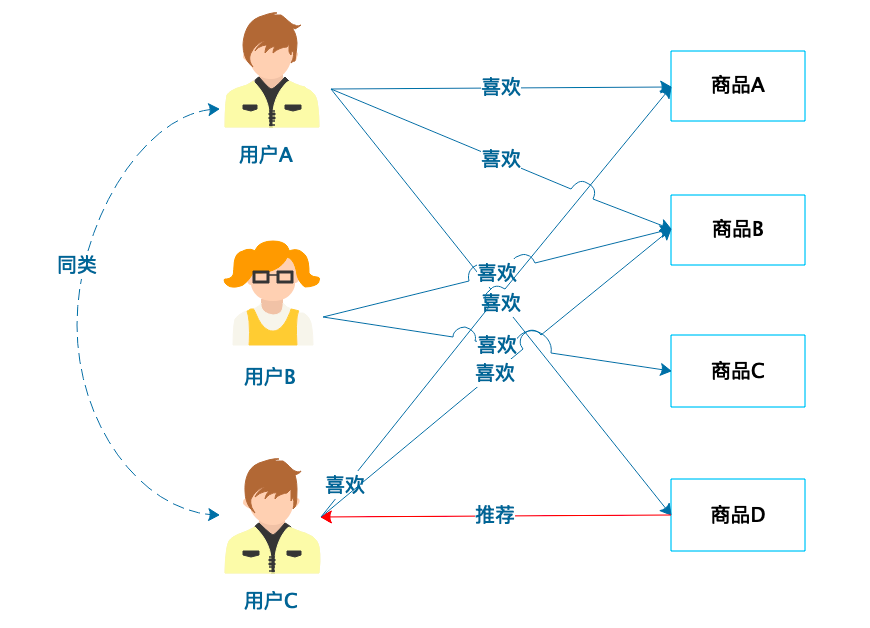
基于商品的协同过滤推荐
4.4 机器学习系统架构
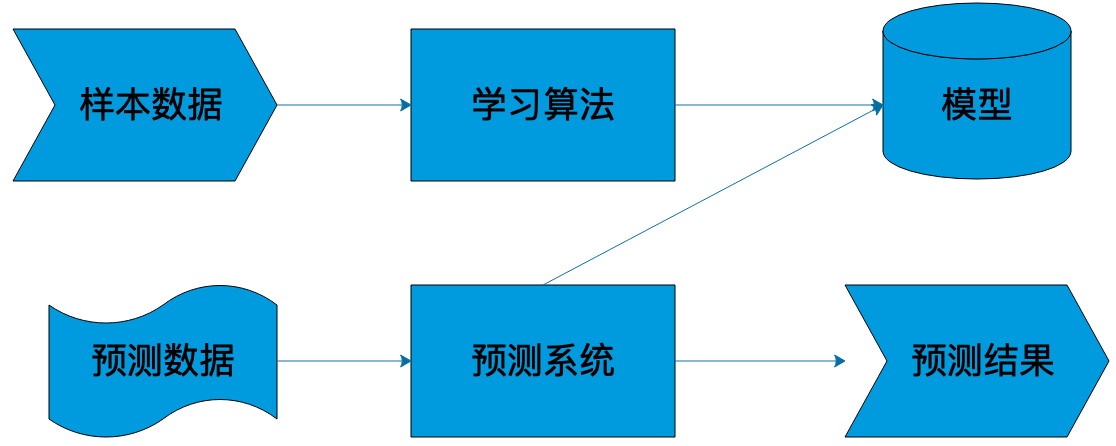
主要概念:
样本
模型
算法
感知机
神经网络
5. 总结
大数据处理分为批量数据处理和实时流处理,这个是由具体的业务决定的。大数据的主要应用场景分为数据分析和数据挖掘。大数据本身不产生价值,但是数据分析和数据挖掘的结果,却可能影响业务,赋能产业。

还未添加个人签名 2018.04.30 加入
还未添加个人简介









评论