Linux 服务器存在某进程 CPU 过高如何追溯其问题根源?

问题描述:
在本人运维的一个省级平台系统中,最近有用户反应系统很卡一直转圈圈. 经初步核查发现某web服务器节点存在JAVA进程cpu占比超过100%的情况。为了不影响用户使用,暂时只能采取简单粗暴的方法"重启服务器"。这其中有如下2个疑问,1 该平台web服务器有7个节点,为何只是其中一个节点无法访问会导致外网用户会觉得系统卡甚至无法访问?2 为啥cpu占比这么高,究竟是是业务的那些代码写的有问题,如何把它揪出来?
带着这两个问题我开始和身边同事沟通已经网上相关知识的搜索。
问题分析:
1 该平台web服务器有7个节点,为何只是其中一个节点无法访问会导致外网用户会觉得系统卡甚至无法访问?
我们采用的是硬件负载的方式,对于负载均衡策略有如下几种方式。
轮循均衡(Round Robin):每一次来自网络的请求轮流分配给内部中的服务器,从1至N然后重新开始。此种均衡算法适合于服务器组中的所有服务器都有相同的软硬件配置并且平均服务请求相对均衡的情况。
我们的业务web服务器都是同样配置的虚拟机,因此,我们采用了该“轮询均衡”策略。除此之外,还有如下其他策略。
权重轮循均衡(Weighted Round Robin):根据服务器的不同处理能力,给每个服务器分配不同的权值,使其能够接受相应权值数的服务请求。例如:服务器A的权值被设计成1,B的权值是 3,C的权值是6,则服务器A、B、C将分别接受到10%、30%、60%的服务请求。此种均衡算法能确保高性能的服务器得到更多的使用率,避免低性能的服务器负载过重。
随机均衡(Random):把来自网络的请求随机分配给内部中的多个服务器。
权重随机均衡(Weighted Random):此种均衡算法类似于权重轮循算法,不过在处理请求分担时是个随机选择的过程。
响应速度均衡(Response Time):负载均衡设备对内部各服务器发出一个探测请求(例如Ping),然后根据内部中各服务器对探测请求的最快响应时间来决定哪一台服务器来响应客户端的服务请求。此种均衡算法能较好的反映服务器的当前运行状态,但这最快响应时间仅仅指的是负载均衡设备与服务器间的最快响应时间,而不是客户端与服务器间的最快响应时间。
最少连接数均衡(Least Connection):客户端的每一次请求服务在服务器停留的时间可能会有较大的差异,随着工作时间加长,如果采用简单的轮循或随机均衡算法,每一台服务器上的连接进程可能会产生极大的不同,并没有达到真正的负载均衡。最少连接数均衡算法对内部中需负载的每一台服务器都有一个数据记录,记录当前该服务器正在处理的连接数量,当有新的服务连接请求时,将把当前请求分配给连接数最少的服务器,使均衡更加符合实际情况,负载更加均衡。此种均衡算法适合长时处理的请求服务,如FTP。
处理能力均衡:此种均衡算法将把服务请求分配给内部中处理负荷(根据服务器CPU型号、CPU数量、内存大小及当前连接数等换算而成)最轻的服务器,由于考虑到了内部服务器的处理能力及当前网络运行状况,所以此种均衡算法相对来说更加精确,尤其适合运用到第七层(应用层)负载均衡的情况下。
DNS响应均衡(Flash DNS):在Internet上,无论是HTTP、FTP或是其它的服务请求,客户端一般都是通过域名解析来找到服务器确切的IP地址的。在此均衡算法下,分处在不同地理位置的负载均衡设备收到同一个客户端的域名解析请求,并在同一时间内把此域名解析成各自相对应服务器的IP地址(即与此负载均衡设备在同一位地理位置的服务器的IP地址)并返回给客户端,则客户端将以最先收到的域名解析IP地址来继续请求服务,而忽略其它的IP地址响应。在种均衡策略适合应用在全局负载均衡的情况下,对本地负载均衡是没有意义的。
2 为啥cpu占比这么高,究竟是是业务的那些代码写的有问题,如何把它揪出来?
在回答这个问题之前,我们先来搞清楚究竟什么是CPU的使用率?
Linux 作为一个多任务操作系统,将每个 CPU 的时间划分为很短的时间片,再通过调度器轮流分配给各个任务使用,因此造成多任务同时运行的错觉。为了维护 CPU 时间,Linux 通过事先定义的节拍率(内核中表示为 HZ),触发时间中断,并使用全局变量 Jiffies 记录了开机以来的节拍数。每发生一次时间中断,Jiffies 的值就加 1。
而我们通常所说的 CPU 使用率,就是除了空闲时间外的其他时间占总 CPU 时间的百分比,用公式来表示就是:
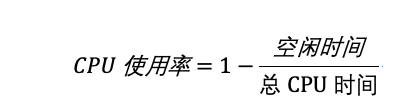
可以从 /proc/stat 中的数据,很容易地计算出 CPU 使用率,这是开机以来的节拍数累加值,所以直接算出来的,是开机以来的平均 CPU 使用率,一般没啥参考价值。
事实上,为了计算 CPU 使用率,性能工具一般都会取间隔一段时间(比如 3 秒)的两次值,作差后,再计算出这段时间内的平均 CPU 使用率,即。

这个公式,就是我们用各种性能工具所看到的 CPU 使用率的实际计算方法。
进程的CPU使用率计算:
跟系统的指标类似,Linux 也给每个进程提供了运行情况的统计信息,也就是 /proc/[pid]/stat。不过,这个文件包含的数据就比较丰富了,总共有 52 列的数据。
是不是说要查看 CPU 使用率,就必须先读取 /proc/stat 和 /proc/[pid]/stat 这两个文件,然后再按照上面的公式计算出来呢?当然不是,各种各样的性能分析工具已经帮我们计算好了。不过要注意的是,性能分析工具给出的都是间隔一段时间的平均 CPU 使用率,所以要注意间隔时间的设置,特别是用多个工具对比分析时,你一定要保证它们用的是相同的间隔时间。
怎么查看 CPU 使用率?
top 和 ps 是最常用的性能分析工具:top 显示了系统总体的 CPU 和内存使用情况,以及各个进程的资源使用情况。ps 则只显示了每个进程的资源使用情况。
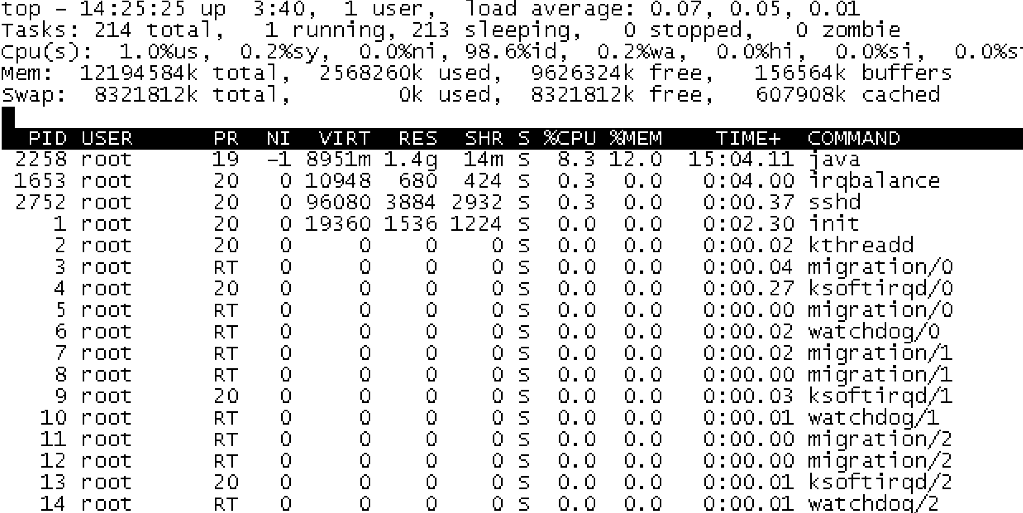
top 默认显示的是所有 CPU 的平均值,这个时候你只需要按下数字 1 ,就可以切换到每个 CPU 的使用率了。
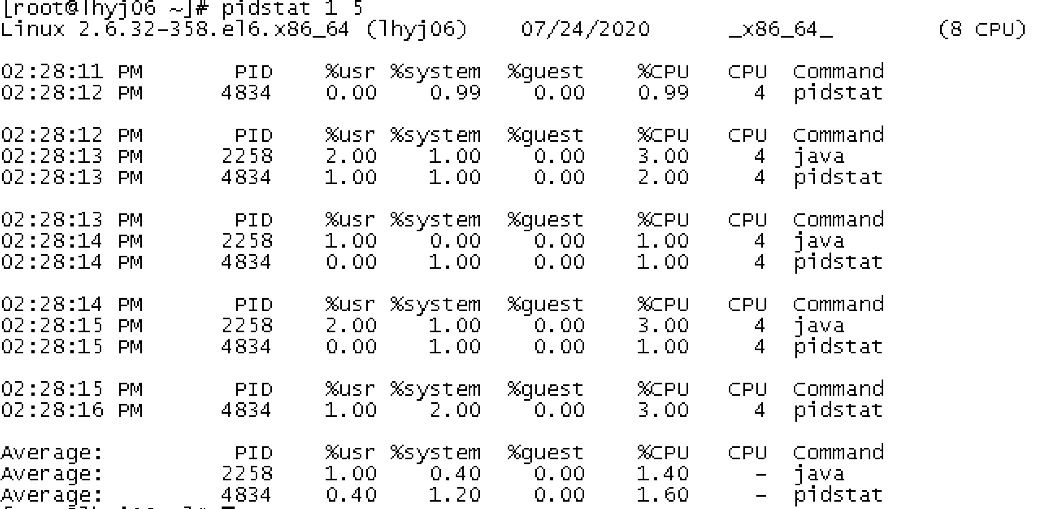
pidstat ,它是一个专门分析每个进程 CPU 使用情况的工具。
用户态 CPU 使用率 (%usr);内核态 CPU 使用率(%system);运行虚拟机 CPU 使用率(%guest);等待 CPU 使用率(%wait);以及总的 CPU 使用率(%CPU)。
最后我们回到问题CPU 使用率过高怎么办?
我们可以轻而易举的就找到那个进程使用率过高,但是到底是那段代码哪个函数导致的?
第一种常见用法是 perf top,类似于 top,它能够实时显示占用 CPU 时钟最多的函数或者指令,因此可以用来查找热点函数,使用界面如下所示:
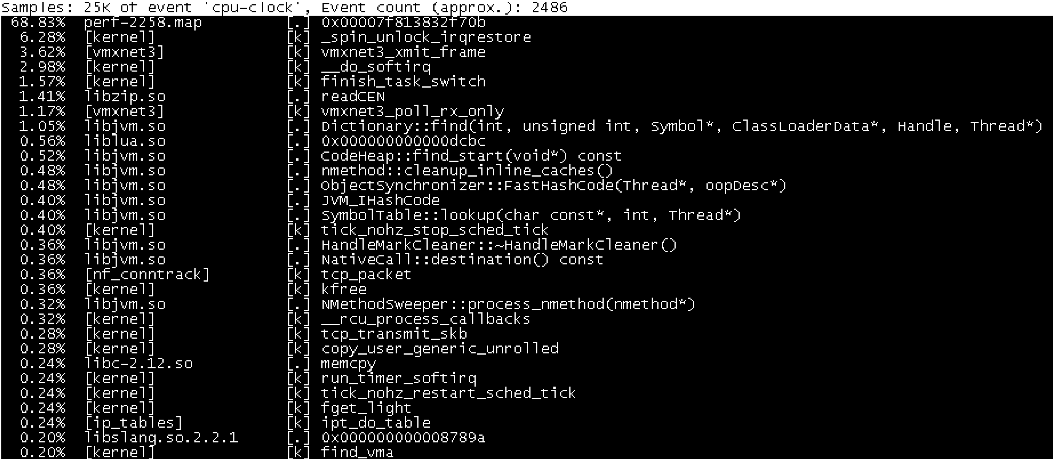
输出结果中,第一行包含三个数据,分别是采样数(Samples)、事件类型(event)和事件总数量(Event count)。
采样数需要我们特别注意。如果采样数过少(比如只有十几个),那下面的排序和百分比就没什么实际参考价值了。
再往下看是一个表格式样的数据,每一行包含四列,分别是:
第一列 Overhead ,是该符号的性能事件在所有采样中的比例,用百分比来表示。
第二列 Shared ,是该函数或指令所在的动态共享对象(Dynamic Shared Object),如内核、进程名、动态链接库名、内核模块名等。
第三列 Object ,是动态共享对象的类型。比如 [.] 表示用户空间的可执行程序、或者动态链接库,而 [k] 则表示内核空间。
最后一列 Symbol 是符号名,也就是函数名。当函数名未知时,用十六进制的地址来表示。
接着再来看第二种常见用法,也就是 perf record 和 perf report。 perf top 虽然实时展示了系统的性能信息,但它的缺点是并不保存数据,也就无法用于离线或者后续的分析。
而 perf record 则提供了保存数据的功能,保存后的数据,需要你用 perf report 解析展示。
总结一下cpu过高分析方法如下:
1 通过top命令 找出cpu使用率过高的进程;
2 centos 下 通过 perf record -g -p <pid> (cpu 使用率过高进程ID),执行一会按ctrl+c停止 ;
3 经过第二步 操作,在当前文件夹下将生成 perf.data文件
4 通过命令perf report 可查看分析报告。
最后我给大家出一道逻辑题让大家来答,答案我将在下一篇文章进行公布。
题目并不难,希望你一定自己做一做。这是一道著名的题,在你漫长的人生路上很有可能还会再次遇到这道题,可是如果你这一次没自己做就知道了答案,到时候你会因为错过了做这道题的体验而感到非常遗憾。请看题。
有一种纸牌,它的正面是一个数字,背面是一种颜色。现在桌面上有四张牌,它们向上的一面分别是 ——

第一张牌是数字 3
第二张牌是数字 8
第三张牌是红色
第四张牌是棕色
好,现在咱们约定一条规则:“如果纸牌正面的数字是偶数,那么背面的颜色就必须是红色”。现在我们想知道桌上这四张牌中有哪些牌违反了这条规则。那请问,你至少需要掀开哪几张牌呢?
这道题英国心理学家彼得·沃森(Peter Cathcart Wason)1966 年发明的,现在叫“沃森选择任务(Wason selection task)”。几十年来,几代心理学家不知道拿这道题做过多少次实验,它是最常用的认知心理学测验题。

参考资料:
倪朋飞的专栏《Linux性能优化实战》
《常用负载均衡策略分析》https://www.jianshu.com/p/d7e173d212a8
万维钢精英日课第四季《我们为什么打比方》
版权声明: 本文为 InfoQ 作者【Nick】的原创文章。
原文链接:【http://xie.infoq.cn/article/3b99c2ad880d7b71f6172bef6】。文章转载请联系作者。

终身学习,向死而生 2020.03.18 加入
得到、极客时间重度学习者,来infoQ 是为了输出倒逼输入









评论