

架构师训练营第十三周作业
你所在的行业,常用的数据分析指标有哪些?请简述。
常用的数据分析指标包括:
新增用户数
用户留存率
活跃用户数
PV
GMV
转化率
Google 搜索引擎是如何对搜索结果进行排序的?(请用自己的语言描述 PageRank 算法。)
PageRank 算法目的就是要找到优质的网页,这样 Google 的排序结果不仅能找到用户想要的内容,而且还会从众多网页中筛选出权重高的呈现给用户。
一个网页的影响力 = 所有入链集合的页面的加权影响力之和,出链会给被链接的页面赋予影响力,当我们统计了一个网页链出去的数量,也就是统计了这个网页的跳转概率。u 为待评估的页面,Bu 为页面 u 的入链集合。针对入链集合中的任意页面 v,它能给 u 带来的影响力是其自身的影响力 PR(v) 除以 v 页面的出链数量,即页面 v 把影响力 PR(v) 平均分配给了它的出链,这样统计所有能给 u 带来链接的页面 v,得到的总和就是网页 u 的影响力,即为 PR(u)。
等级泄露(Rank Leak):如果一个网页没有出链,就像是一个黑洞一样,吸收了其他网页的影响力而不释放,最终会导致其他网页的 PR 值为 0。
等级沉没(Rank Sink):如果一个网页只有出链,没有入链,计算的过程迭代下来,会导致这个网页的 PR 值为 0。
为了解决简化模型中存在的等级泄露和等级沉没的问题,拉里·佩奇提出了 PageRank 的随机浏览模型。他假设了这样一个场景:用户并不都是按照跳转链接的方式来上网,还有一种可能是不论当前处于哪个页面,都有概率访问到其他任意的页面,比如说用户就是要直接输入网址访问其他页面,虽然这个概率比较小。
所以他定义了阻尼因子 d,这个因子代表了用户按照跳转链接来上网的概率,通常可以取一个固定值 0.85,而 1-d=0.15 则代表了用户不是通过跳转链接的方式来访问网页的,比如直接输入网址。
其中 N 为网页总数,这样我们又可以重新迭代网页的权重计算了,因为加入了阻尼因子 d,一定程度上解决了等级泄露和等级沉没的问题。
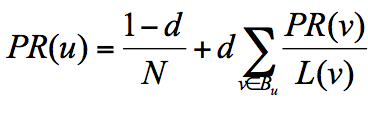
版权声明: 本文为 InfoQ 作者【James-Pang】的原创文章。
原文链接:【http://xie.infoq.cn/article/3772e5993178967f1f3696594】。未经作者许可,禁止转载。

不忘初心 2018.11.08 加入
还未添加个人简介










评论