
人工智能顶会 AAAI 2023 放榜!网易伏羲 7 篇论文入选

近日,第 37 届国际顶级人工智能学术会议 AAAI Conference on Artificial Intelligence(简称 AAAI)揭晓了论文接收结果,网易伏羲实验室共有 7 篇论文入选。作为人工智能领域公认的权威性顶级学术会议,其收录论文代表着国际人工智能研究领域的最高水准,因此受到国内外人工智能领域学者和厂商的关注。

本届 AAAI 共收到有效稿件 8777 篇,录用论文 1721 篇,接收率为 19.6%。网易伏羲入选的论文方向覆盖游戏虚拟角色、文本生成、异常检测、强化学习的应用研究,本次入选代表了网易伏羲实验室在人工智能领域的研究成果再次获得全球同行的广泛认可,以下为其中三篇论文概要。
1
StyleTalk: One-shot Talking Head Generation with Controllable Speaking Styles
风格化的表情动画合成在游戏剧情生产中具有极高的应用价值。本论文提出一个新的任务,即合成风格可控的人脸表情动画,并进一步将表情动画渲染成说话人脸视频。
传统的情绪化表情合成工作主要关注不同情绪的表情差异性,却忽略了同种情绪下不同人之间的差异性。我们将这种交谈过程中不同人的面部运动差异性概括为“说话风格”。文中通过给定一段参考说话视频或者参考表情动画,从中提取出参考片段的说话风格,然后将说话风格嵌入到语音驱动的表情动画合成系统,从而实现风格可控的表情动画合成。
为了实现上述目标,论文提出了以下方案:
首先,设计一个风格化特征向量编码器,从输入的时序表情动画中提取表示表情运动模式的风格化特征向量;
通过基于风格化特征向量的动态解码器,从语音特征中合成对应风格的三维人脸表情参数。由于固定的网络参数很难处理多样化的说话风格,我们设计了一个风格化自适应网络层,通过输入的风格特征向量来改变网络层中的权重参数,从而使得网络能够支持多样化的风格化特征向量;
使用一个图像渲染器将动画参数渲染成视频;
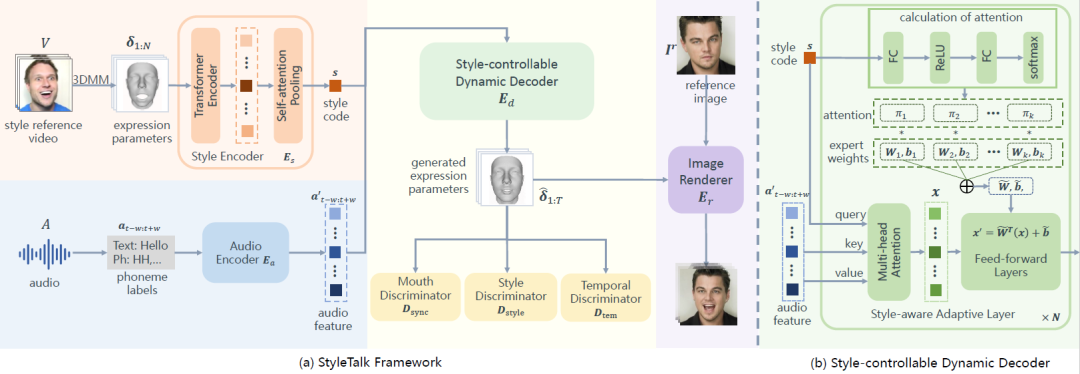
该方法提出了新的任务,并实现了更高质量的情绪化表情动画合成效果。该研究工作能够产生高质量的表情动画,在游戏、元宇宙、虚拟人相关的应用场景中具有广泛应用。
2
FlowFace: Semantic Flow-guided Shape-aware Face Swapping
人脸替换技术,俗称"换脸",目标是将输入源人脸的身份信息转移到目标人脸,同时保持目标人脸的各种属性(表情、姿势、头发、光照和背景等)。该技术在影视制作、个性化游戏 CG、个性化虚拟形象等领域有着广泛的应用,具有巨大的产业价值。然而,现有的人脸替换方法大多只能迁移人脸的五官特征而无法改变其面部轮廓,大大降低了人脸替换的相似度。
为解决这一问题,文章提出了一种语义流引导的人脸替换模型(FlowFace),实现了既可以转换五官也能改变脸型的换脸算法。FlowFace 通过两个阶段实现人脸替换:脸型迁移阶段和五官迁移阶段。
在脸型迁移阶段(Face Reshaping Network),我们借助三维人脸模型估计脸型变换语义流(Semantic Flow),实现对目标人脸形状的显性变形,实现从源人脸到目标人脸的脸型迁移。
在五官迁移阶段(Face Swapping Network),我们采用人脸掩码自动编码器(MAE) 将源人脸和目标人脸编码到特征空间,并设计了一种交叉注意力融合模块(Cross- Attention Fusion Module)自适应地将源人脸的身份特征与目标人脸的属性特征融合,进而解码出高保真高身份相似度的人脸替换结果。
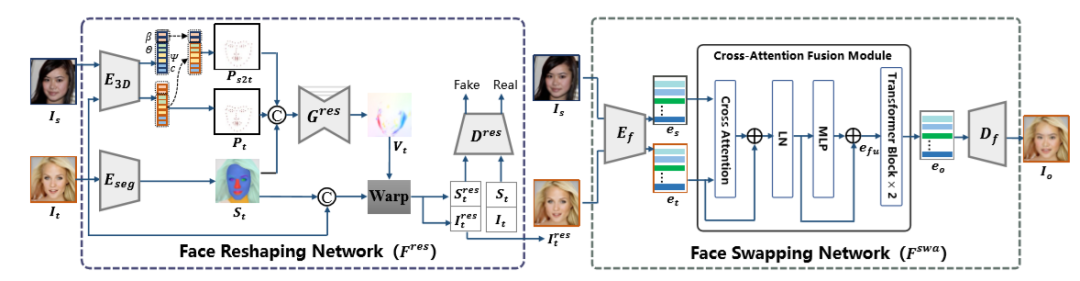
基于我们的设计,FlowFace 在脸型迁移和五官迁移效果上达到了目前最先进的人脸替换效果。同时该文章还可用于游戏 CG 角色换脸,减少人工捏脸的工作量,对比已有方法,该工作在效果上更有优势。

未来,团队将继续探索该项技术在个性化虚拟形象、个性化游戏 CG 等领域落地。
3
Generating Coherent Narratives by Learning Dynamic and Discrete Entity States with a Contrastive Framework
近年来,生成流畅文本方面的研究与实践取得了飞速发展,该技术在游戏内的剧情生成、对话生成等方面有着广泛应用。然而当生成故事等叙事性文本时,现有的预训练模型对涉及到的实体容易生成不一致的事件序列。本文中认为:这些问题是由于简单用单词的静态向量表征实体导致的,从而忽略了建模随着文本展开实体携带信息的不断变化。
基于以上思考,网易伏羲实验室和清华大学黄民烈老师团队合作提出了以下方案:
提出了一个新颖的用对比框架学习动态的和离散的状态表示的生成模型。我们给文本解码器配备了一个额外的注意力层用来应用实体状态指导解码过程。
设计了对比学习框架让实体状态在表示空间靠近于实体附属的事件状态。并且实验表明对比框架学到了一系列符合不同事件簇的实体状态向量,相比基线模型我们的模型能生成更一致和更有信息量的文本。
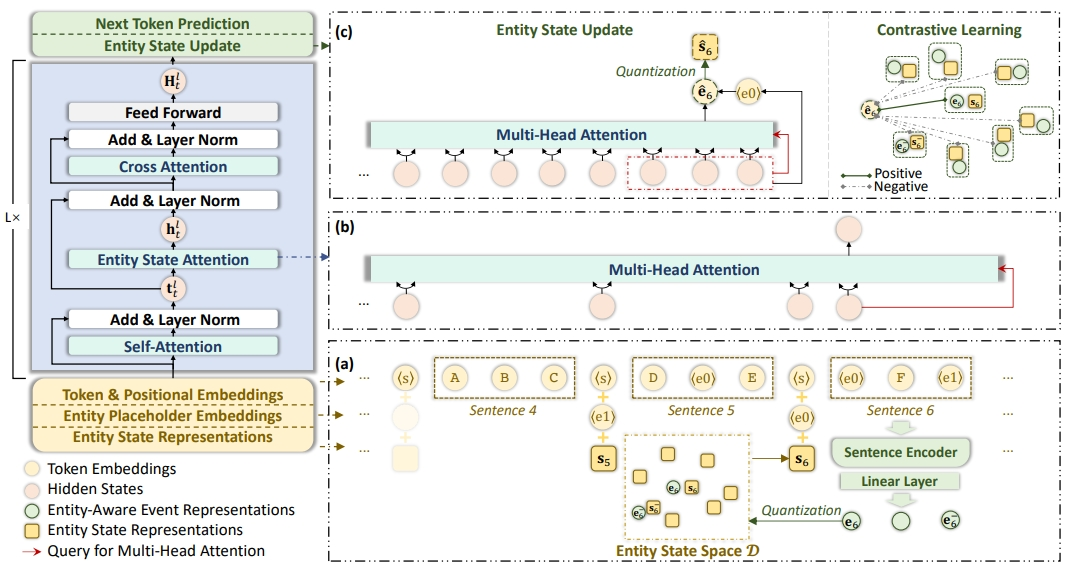
该研究成果未来可以应用在文本生成领域,有助于游戏内故事生成、对话生成的场景落地。两个叙事性文本数据集上的实验表明,我们的模型比在实体状态指导的强大基线下,可以产生更多连贯和多样化的叙述。
⽹易伏羲作为专业从事游戏与泛娱乐 AI 研究和应⽤的顶尖机构,坚持将 AI 技术与游戏领域相结合,通过科技创新持续助力游戏行业的发展。
版权声明: 本文为 InfoQ 作者【网易伏羲】的原创文章。
原文链接:【http://xie.infoq.cn/article/3702b462dcb492b44a898ade3】。文章转载请联系作者。

还未添加个人签名 2018-12-18 加入
还未添加个人简介







评论