

我来聊聊模型驱动的前端开发

如果把「客户端」想成是楼,把「数据」想成是水——「Model」就是这幢楼的蓄水池,提供充足的水源;「ViewModel」是将蓄水池里的水进行净化等加工的地方,然后输送给挨家挨户;「View」部分的每个 UI 组件就是「挨家挨户」,对水进行消费的地方。
一切皆为模型
模型是人们根据事物特征将它们分类并抽象后的结果,建模是人们认知世界的一种方式。
模型驱动
数字世界这种虚拟空间,里面本无一物,是个需要被人开垦的空虚的世界。那么人该如何打造数字世界呢?
就像《圣经》里描述的——上帝按照自己的样子创造了亚当这个世上第一个人类,又从他身上取下一根肋骨创造了夏娃这个世界上第二个人类。在这里,上帝将自己作为参照提取特征抽象出祂所认为的「人」的模型,并根据这个模型创造出「亚当」和「夏娃」。
人在打造数字世界时必然会参照自己所存在的并且是自己所认知的世界,因为人不可能想像出自己无法认知的事物。人们所抽象的现实世界的事物的模型,就成了建设数字世界的基础,而数据则为构造数字世界的基本单元,数字世界成了现实世界的映射。
模型是数字世界万物的概念,程序是将概念具像化的工具,打造数字世界需从建模开始。
领域驱动
上面说了在打造数字世界时首先要建立模型,然后以模型为中心开始建造。那么要怎样进行建模呢?
至今为止,软件工程发展这么多年,产生了很多方法论,其中「领域驱动设计」在构建大型软件时是被广泛采纳的实践方法。它的核心就是针对问题域分析并建立领域模型,理出模型间的关系及业务逻辑。
领域驱动设计最常用在商业层面的模型上,如:包含名称、编号、规格、出厂日期等信息的商品模型;同时也可以用在技术层面的模型上,如:包含名称、编码、字段、关系、约束等用来描述模型的信息的模型。前者称之为「业务模型」,后者则是「元模型」。业务模型可以被元模型描述。
如果把模型映射为数据库表,那么元模型所对应的表中的每条记录都是元数据,业务模型所对应的表中的每条记录都是业务数据。
MVVM 架构
标准的 MVVM 架构是 Model-View-ViewModel 三部分:
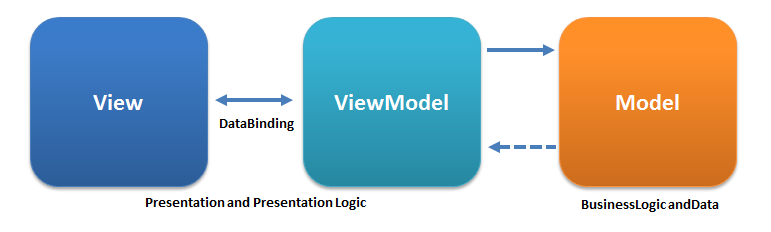
而这里所说的如下图所示:
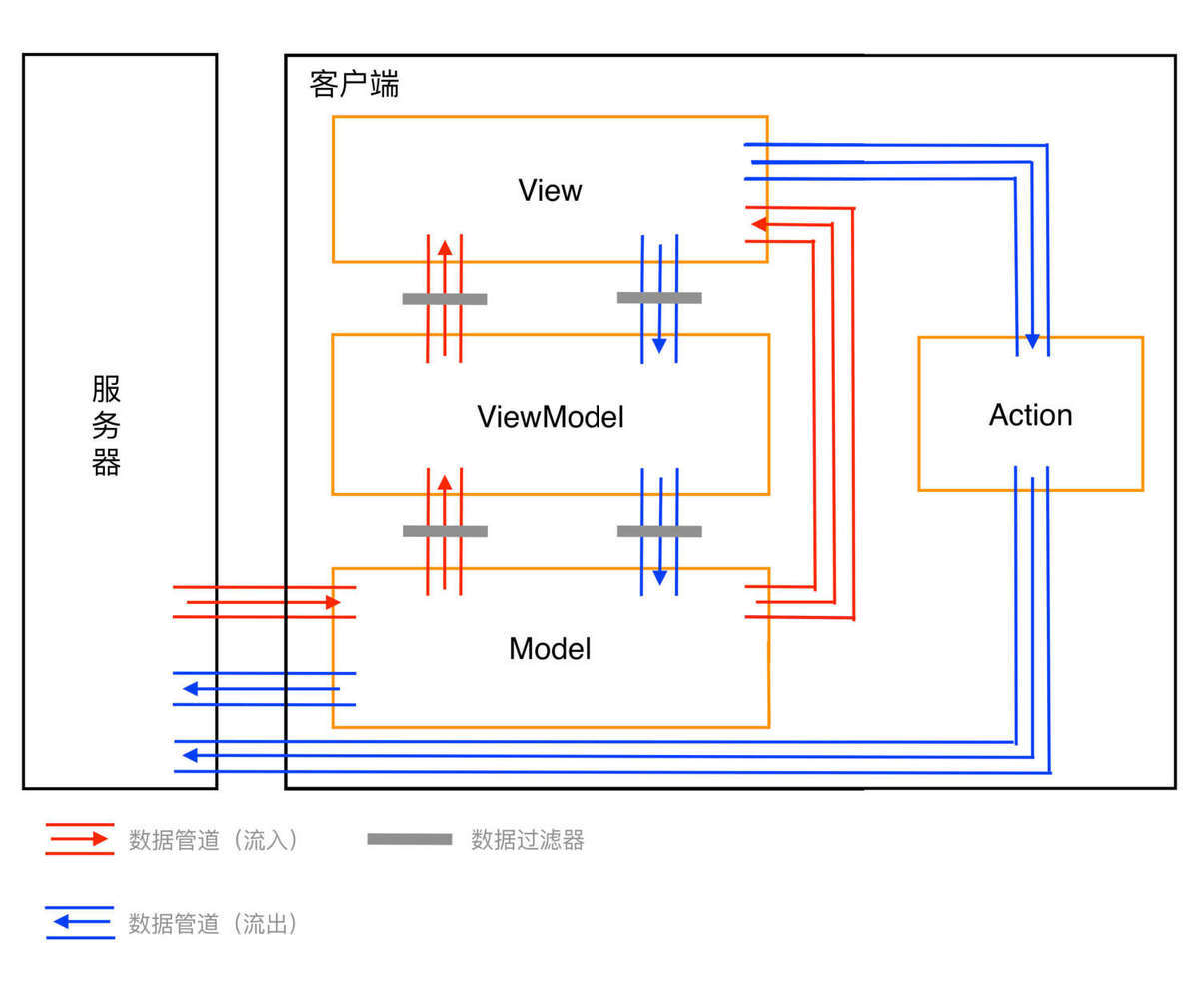
从图中可以看到,多了个「Action」,所以实际上应该是 Model-View-ViewModel-Action 四部分。它们之间彼此分离,以组合的方式协同工作。
为了讲究对称美,将这种架构简称为「MVAVM」。
模型
模型的主要职责是前、后端协议处理,以及对数据进行读写操作。
前、后端协议的处理包括元数据适配和 HTTP 请求构造。与后端对接的工作都控制在这一层,其他层的运作都基于这层适配后的结果。
在这层中进行读写的数据,既有业务数据又有元数据。元数据只加载一次,将适配后的结果进行缓存;业务数据只暂时缓存尚未持久化的处于草稿状态的记录,持久化之后会将其删除。
ViewModel
VM 的职责很单纯,就是处理业务数据流转相关的逻辑,即数据的分发、汇总与联动。理论上,在这层不直接进行任何与请求服务、执行动作相关的处理。
正如文章开头所说——在一个应用中,数据是像水一样不断流动的,在此过程中,VM 应该起到铺设输送管线与在特定节点对数据进行处理的作用。根据这一特点,可以考虑采用管道和过滤器模式:
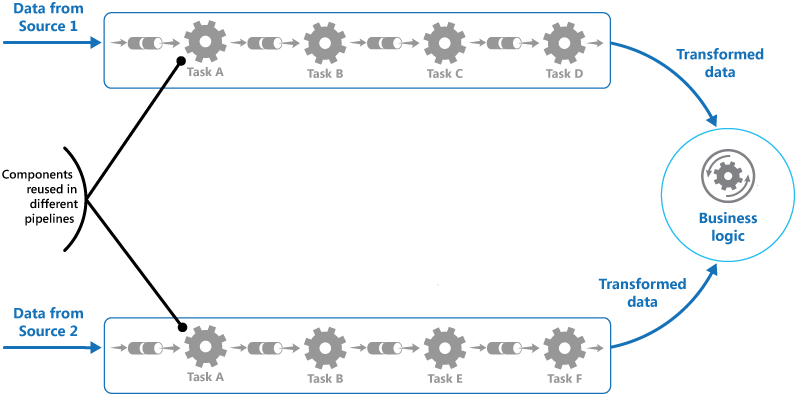
实例与数据的关系
每个 VM 实例都来源于数据,是数据的变形,是具备能力的数据。
根据数据源的形态,VM 实例大致分为列表、对象和值三种。如果值是布尔、数字、字符串等简单类型,那就即刻终止;若值为对象、列表等复杂类型,则要递归下去,直到末端为简单类型。
需要注意的是,VM 实例与数据一一对应,其实质就是数据本身,而不是数据的容器。也就是说,VM 实例不是装水的瓶子,不能把已经装的水倒掉换些水进来,而是一起丢弃。
生命周期
任何对象的生命周期都可粗略地分为初始化、活动中与销毁三个阶段。
在初始化时根据策略获取自身数据源,与上级 VM 实例创建的流进行对接形成数据管道,然后创建向外推送自身变化的流。
活动期间就是不断地与外界进行数据交换:
视图输入变化时,通过对应的 VM 实例提交自身的数据变更
在处理被提交的输入数据时会对其进行保留,并发出有数据提交的信号
自身的数据变化会通过数据管道流向下级 VM 实例
外部(主要是上级)接收到信号后会做些后续处理
销毁时做些清理、善后的工作,如:移除子 VM 引用,取消订阅等。
数据流转
在活动期间,数据在各层 VM 实例所连通的数据管道中流转时会发生变化,为了方便在不同场景下对数据进行处理,需要在初始化 VM 实例时将数据源进行备份,并生成几个拷贝:初始值(initial value)、默认值(default value)、原始值(data source)和当前值(current value)。
其中,初始值是获取到数据源那一刻的值,默认值在没有指定的情况下与初始值相同,它们都是一经初始化就不会改变的;当前值是自身一段时间内的数据变更,是最新的但不确定的值,可以理解为是一种草稿状态的值;原始值只有在上级当前值变动,接收到下级提交的数据或强制更新时才会更新,它是阶段性的确定值,可以看作是可靠的数据。
「原始值」中的「原始」也许会容易让人误解。在这里,它的含义是相对于「当前值」来说,它是「原始」的,可以拿来作为参考的,而不是「最初的值」。表达「最初的值」的含义的是「初始值」。
原始值与当前值的区别与特点是:
原始值是确定的,当前值是不确定的;
原始值是纯的,当前值是脏的;
通过「提交(commit)」操作对各级的原始值、当前值进行同步;
当前值的「版本」始终不落后于原始值;
有些场景下原始值与当前值始终相同。
数据在流转时遵循以下几个原则:
自身的原始值变动会引起自身的当前值以及子孙级的原始值和当前值变动,子孙可以定义抛弃变动的规则;
自身的当前值变动在没提交时不会影响自身的原始值,会引起子孙级的原始值和当前值变动,子孙可以定义抛弃变动的规则;
将自身的当前值提交到上级后,不会引起回流,兄弟 VM 实例也不会发生变化。
总的来说,只有在上级引发数据变动的情况下,才会发生上到下的数据流动。
各层级 VM 实例之间数据的传递过程大致如下:
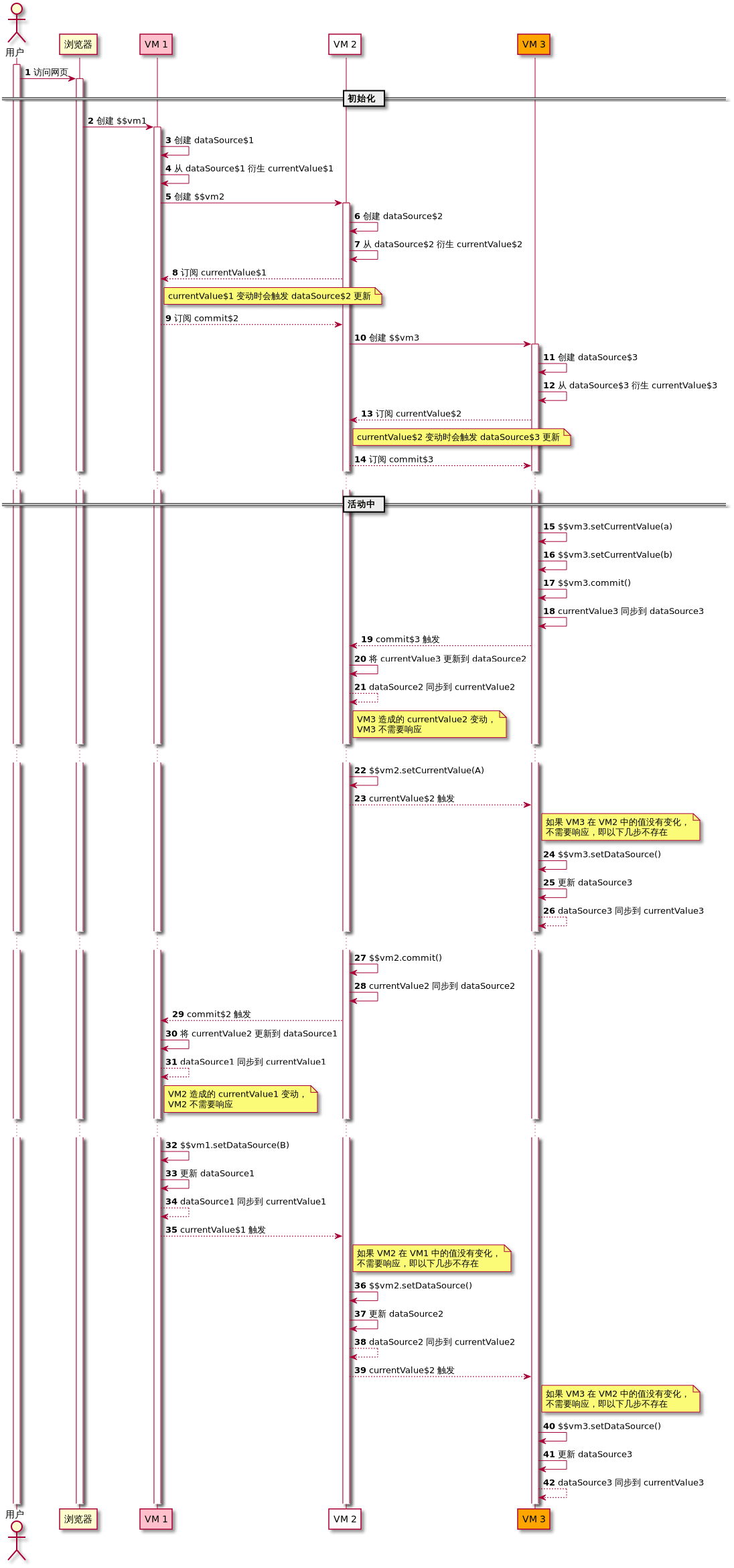
过滤器
在数据通过上下级 VM 实例之间所连通的数据管道,即数据的分发与汇总时,会经过一系列相对独立的逻辑的处理,如:数据的裁剪、变形、校验等。每一段处理逻辑就是一个「过滤器」,每个过滤器都可以抛出异常终止后续的操作。
与视图的交互
每个 VM 实例都会提供一些供视图进行状态同步、数据联动等的接口:
动作
关于「动作」是什么,在之前的文章《我来聊聊配置驱动的视图开发》中已经提及——
「动作」是一段完整逻辑的抽象,与函数相当,用来描述且只描述「做什么事」,不描述「长什么样」。一个可复用的动作应该是原子化的。
根据逻辑的定义、执行所在位置,可以分为客户端动作(广义)与服务端动作:客户端动作(广义)是定义并且执行在前端;服务端动作是定义并且执行在后端。
客户端动作(广义)根据具体场景的用途及特性,又可分为以下几种动作:
路由动作
CRUD 动作
客户端动作(狭义)
组合动作
其中,路由动作的作用是进行页面跳转;CRUD 动作是对数据进行操作;客户端动作(狭义)是单纯的一段逻辑,可以简单理解为是一个 JS 函数;组合动作用于将其他类型的动作「打包」处理,就像一个调用了其他函数的函数。
服务端动作可以简单粗暴地理解为是非常规 CRUD 的后端接口。
除了客户端动作(狭义)需要自己写逻辑之外,其他的都是完全根据元数据执行。
路由动作是进行页面跳转的动作,这里的「页面」是广义的,根据情景,可以理解为是浏览器窗口中的整个页面,也可以理解为是某个视图所在的宿主。在这个体系里,将视图跳转的动作称为「视图动作」,跳转到当前应用之外的页面的叫做「页面动作」。
既然组合动作是将其他类型的动作「打包」处理的动作,那么它就得具备调整被「打包」的动作的执行顺序及如果某个动作执行失败要终止后续处理等的控制能力。实现方式可以参考 continuation 在 JS 中的实践应用。
视图
解析视图描述信息,并根据注入的 VM 实例所携带的数据进行渲染。
视图中可以自己发请求,但理论上只能发获取数据的请求,不能发修改数据的,修改数据需要通过 VM 实例或动作去处理。
视图这部分又细分为描述层、包装层和渲染层:
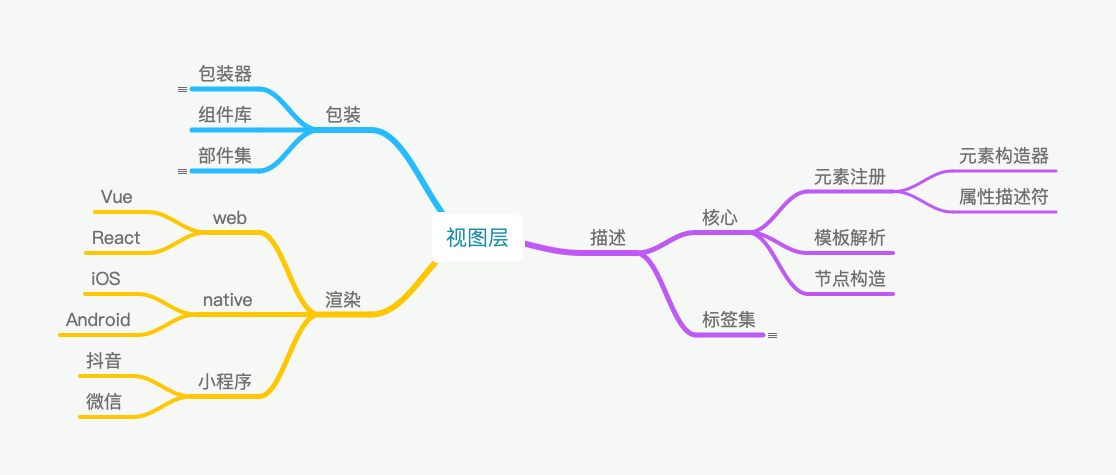
「描述层」即「DSL 层」,通过内部定义的 XML 标签集去描述一个界面中的 UI 元素、数据等信息,是一种相较于 JSON 来说更符合直觉,更容易理解的界面配置。
包装层的作用是将描述层的标签转换为实际渲染的部件,渲染层则是具体的运行时环境。不像描述层那样相对独立,包装层和描述层可以说是不能分离的,包装层在将描述层的标签转换为实际渲染的部件时需要渲染层的支撑。
包装层的包装器与描述层的标签集里的标签可以说是一一对应的,标签通过包装器转换为部件集里的部件,但部件却不一定与包装器一一对应,很可能一个包装器对应多个同类别的部件。
描述层
在 web 前端开发中,HTML 是一种 DSL,CSS 也是一种 DSL。在这个模型驱动的体系里,内部定义的用来描述一个界面中的 UI 元素、数据等信息的 XML 标签集就是 DSL。
描述层是运行时无关的,能够在任何平台及运行时库中运行。
日常工作交流中常会说到「模板」,这个词在不同语境中代表着不同的东西。在这个体系中,当在开发的语境里时,如果没带任何修饰词,应该就是指「一段描述界面配置的标签」,如:
模板如果不去解析,它就只是一段普通的文本,没有任何作用。
要对模板进行解析,得有一套对应模板上标签的标签集,还需有能将纯文本的模板借助标签集转换成 JS 对象的解析器。
标签集中的每个标签,也可以称为「元素」。考虑到扩展性,需要有元素注册的机制,这有助于元素属性等的规范和管理。
在注册元素时,需要指定一些关键信息,如:元素名、标签名、属性描述符、行为。「属性描述符」主要是用来声明该元素所支持的属性及其值的类型;「行为」则用来告知该元素在解析后是作为父节点的子节点还是属性存在。
所有作为子节点存在的元素,基本都对应一个具体的部件。从表意上来说,这些元素分为两类:一类是较为抽象的,另一类是较为具象的。较为抽象的元素只有一个,它仅单纯地表达是「部件」这个含义,并没有更具体地体现出是干嘛的;其他的元素都是具象的,像 <view>、<field> 等,从命名就知道是用于哪方面的。
所谓「节点」,就是将模板中的元素编译解析后所转换成的 JS 对象。整个模板会解析成一个树状结构的 JS 对象,也就是「节点树」。每个节点可以有一些方法,用来新增子节点、删除自身、获取或修改自身信息等。
包装层
包装层的作用是将描述层的产物,即节点,转换为部件。在 DSL 节点与部件之间起到桥梁作用的,就是「包装器」。
包装器里面汇集了描述层所产出的一些信息,如:要生成到界面中的节点的属性及其对应部件的配置等。会根据节点所对应的元素所引用的部件的标识符去查找相应的部件,如果没指定引用则使用默认的,并将其他属性及相关联部件的配置作为部件的属性进行传递。
渲染层
简单来说,渲染层就是像 Vue、React、iOS、Android、微信小程序之类的库/框架、平台的运行时环境。进行实际渲染的组件、部件及作为桥梁的包装器都对其依赖,这就需要在每个运行环境下都得有一套包装器、组件和部件的封装。
思想总结
模型驱动架构正符合我在《前端有架构吗?》所提到的架构设计的首要核心原则——以不变为中心。
在这个体系中,根据不同层、不同角色的设计目标,需要采用适合的编程范式,而不局限于一种。如:模型主要用 OOP,VM 使用 OOP 和 FRP,动作用到 FP。
合理且完善的模型驱动架构的设计与实现,能够很好地支撑企业业务的变化,快速搭建新的应用。
数据处理相关的架构设计就到这里。
以上。
欢迎关注微信公众号以及时阅读最新的技术文章

版权声明: 本文为 InfoQ 作者【欧雷】的原创文章。
原文链接:【http://xie.infoq.cn/article/34eaf7888bc5538261cba7637】。
本文遵守【CC BY-NC】协议,转载请保留原文出处及本版权声明。

多面玩家 2016.11.07 加入
「反混沌」计划(https://ntks.ourai.ws)发起人,致力于前端标准化、工业化,使前端开发更加有序且可快速装配,为新型开发方式及协作模式做支撑。









评论