架构师训练营 第 4 周作业
一个典型的大型互联网应用系统使用了哪些技术方案和手段,主要解决什么问题?请列举描述。
一个典型的大型互联网应用系统架构从纵向角度看,主要由前端架构、网关及应用层架构、服务层架构、存储层架构、后台架构和数据中心机房架构组成,而从横向角度(切面),则包含了安全架构和数据采集与监控架构。本文将以上面的架构分层为基础,针对每一层架构所运用到的技术进行分析。
1. 前端架构:
本章节将从一道典型的面试题:从浏览器地址栏输入一个www.baidu.com发生了什么?,逐步解析前端所运用到的技术方案。
DNS域名解析系统
当用户在浏览器输入www.baidu.com,第一步发生的是进行DNS域名解析。这就引出了前端的第一个技术方案域名系统DNS。为啥要有DNS呢?互联网每台主机的唯一标识是使用IP地址,IP地址由4个点分十进制组成,很难记忆,用户更容易去记住类似www.baidu.com的域名。而这就引出了一个问题?当用户输入www.baidu.com的域名时,如何将域名转换成对应的IP地址呢?在计算机的世界里,答案就是DNS域名系统。
DNS的解析过程如下:
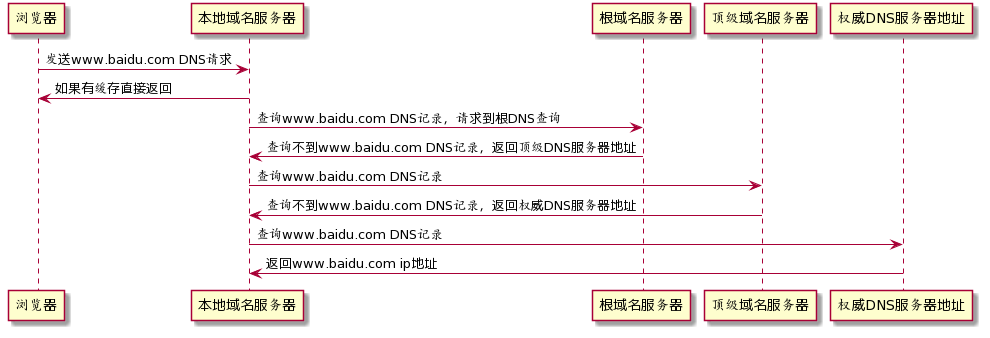
更多DNS域名解析的知识可参考书籍《计算机网络》第六章。
动静分离与CDN
对于一个前端网页,其页面由静态资源和动态请求组成。静态资源主要包括html、js、css、图片资源等,而动态请求主要是请求后端数据的ajax请求。 对于前端的静态资源,其具有请求数据量大且资源版本变动不大的特性,故通常我们可以将静态资源与动态资源进行分离,并且将静态资源进行缓存,这样一方面可以减轻网络请求带宽负载,另一方面可以加速静态资源的请求过程。前端将静态资源进行缓存的常见技术为CDN(内容分发网络)。
加入CDN之后资源的请求过程:
1.当用户输入网址回车后,经过本地DNS系统解析,DNS会将最终的域名解析权交给CNAME 指向的CDN 专用DNS服务器。
2.CDN的DNS服务器将 CDN的全局负载均衡 设备ip 地址返回给浏览器
3.用户向 CDN的全局负载均衡服务器 发起内容url 请求
4.CDN全局负载均衡服务器根据 用户请求的IP地址,url等信息,选择一台用户所属区域的负载均衡设备,告诉用户向这台设备发起请求。
5.CDN区域负载均衡服务器会为用户 选择一台合适的缓存服务器提供服务,选择的依据主要是:离用户距离要近,缓存服务器上是否用户所需内容,以及各个缓存当前的一个负载均衡情况。选择出一个最优的 缓存服务器ip地址。
6.全局负载均衡服务器将 缓存服务器的ip地址给到用户。
7.用户向缓存服务器发起请求。缓存服务器响应用户请求,将用户所需内容传送到用户终端。如果缓存服务器上没有用户想要的内容,那么这台服务器就会向它的上一级缓存服务器请求内容,直至追溯到网站的源服务器,并将内容拉取到本地。
反向代理:
前面说到,DNS域名系统会将域名转换成对应的IP地址,其实这个IP地址通常对应的是一个nginx服务器的公网ip地址,这个nginx服务器充当着反向代理的角色,即将用户的请求转到到内网的ALB服务器或者直接进行负载均衡,转发到对应的应用服务器。同时,针对于静态资源请求,反向代理服务器也可以设置缓存策略,进行静态资源的缓存处理。
2. 网关及应用层架构
对于网关层,主要的功能有服务路由、超时熔断、流量控制、灰度发布、日志、授权、客户端负载均衡、协议转换、跨域转换等。常见API网关有Spring Cloud Gateway和Zuul网关。Spring Cloud Gateway基于Netty服务器,实现了异步非阻塞IO的请求调用,性能较好。而Zuul网关主要基于阻塞IO进行请求调用。
3. 服务层架构
服务层架构主要包含了微服务框架、分布式消息队列、分布式缓存和分布式一致性服务等技术栈。
微服务技术根据业务维度将系统拆分成细粒度的服务模块,如基础原子服务、业务中台服务,提供给前台进行调用编排,可独立部署、独立开发。微服务技术一方面通过沉淀公共服务,避免重复进行造轮子,另一方面通过独占服务器、独占数据库资源,一定程度上缓解了大型互联网系统高并发的压力,并且通过更细粒度的服务隔离能够进行系统之间的故障隔离,降低系统崩溃的风险。
分布式消息队列主要解决两个不同服务之间进行通信的一种技术解决方案。常见的消息队列有Kafaka、RocketMQ、RabbitMQ等。其主要作用有异步、解耦和流量削峰,能很大程序上提高系统的吞吐量和高并发时的性能。
分布式缓存主要用于缓解高并发时数据库IO压力。常见的分布式缓存有Memcached,Redis、Hazelcast等。分布式缓存一般是将数据存储在内存当中,系统可将不常变化的热点数据存储在缓存当中,避免热点数据击穿数据库,造成系统崩溃。引入分布式缓存之后特别需要注意数据的一致性问题。
分布式一致性服务主要用于解决共享资源的控制访问。常见的分布式锁实现方式有基于Redis的分布式锁、基于Zookeper的分布式锁、基于数据库的分布式锁,可结合不同的场景与不同实现方式的优缺点,选择对应的方式。
4. 存储层架构
存储层架构主要包含了分布式文件、分布式关系数据库、NoSQL数据库等技术栈。
分布式文件系统主要解决了海量数据文件的存储和管理的难题。通过分布式文件系统可将固定于某个地点的某个文件系统拓展到任意多个地点/多个文件系统,将众多个节点组成一个文件系统网络。每个节点可以分布在不同的地点,通过网络进行节点间的通信和数据传输。人们在使用分布式文件系统时,无需关心数据是存储在哪个节点上、或者是从哪个节点从获取的,只需要像使用本地文件系统一样管理和存储文件系统中的数据。常见的分布式文件系统有HDFS,HDFS有着高容错性(fault-tolerant)的特点,并且设计用来部署在低廉的(low-cost)硬件上。而且它提供高吞吐量(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。HDFS放宽了(relax)POSIX的要求(requirements)这样可以实现流的形式访问(streaming access)文件系统中的数据。
分布式数据库主要解决了以下问题:
单机数据库容量瓶颈: 随着数据量和访问量的增长,单机数据库会遇到很大的挑战,依赖硬件升级并不能完全解决问题。
单机数据库扩展困难:传统数据库容量扩展往往意味着服务中断,很难做到业务无感知或者少感知。
传统数据库使用成本高: 当业务数据和访问量增加到一定量时,传统数据库需要依赖特定的高端存储和小型机设备,成本曲线快速向上。
常见的分布式数据库有阿里云的DRDS。
NoSQL数据库可分为K-V型数据库、列存储数据库、文档型数据库和图形数据库,K-V型数据库(Redis)可应用于内容缓存,处理大数据高访问负载;列存储型数据库(Hbase)可应用于构建分布式文件系统;文档型数据库(MongoDb)可以进行存储非结构化文档、并且可拓展性好。图形数据库(Neo4j)可应用于社交网络关系的构建。
5. 后台架构
后台架构主要包含了大数据平台、搜索引擎、推荐引擎、数据仓库等技术栈。
大数据平台在聚合数据之后、进行清洗,分析,并使用人工智能算法,可进行产品的优化运营,精准的营销、风控等方面发挥作用。常见的大数据工具有:Hadoop、Spark、Storm。
搜索引擎主要聚合海量数据、进行标签化管理、并提供搜索服务给业务调用。常见的搜索引擎如elasticsearch、solr等。
推荐引擎是主动发现用户当前或潜在需求的定律,并主动推送信息给用户的信息网络,其可应用于搜索结果的智能匹配,新闻推荐等场景。
数据仓库是一个面向主题的、集成的、随时间变化的、但信息本身相对稳定的数据集合,用于对管理决策过程的支持。主要作用如下:
1.数据分析、数据挖掘、人工智能、机器学习、风险控制、无人驾驶。
2.数据化运营、精准运营。
3.广告精准、智能投放。
6. 数据中心机房架构
数据中心机房架构主要是针对IAAS层的抽象,设计的技术栈有docker、主机虚拟化、k8s和对应的硬件架构,这里不再进行详述。
7. 运维与安全架构
运维安全架构包括数据采集与展示、数据监控与告警、攻击与防护、数据加密及解密等技术栈。常用解决方案如下:
ELK: elastic stack开源的ELK组件,主要包括elasticsearch(简称es),logstash,kibana三个核心组件。可进行日志的采集分析与处理。
APM:进行docker容器、主机端到端的数据监控与告警。
攻击与防护:WAF。

还未添加个人签名 2019.01.06 加入
还未添加个人简介









评论