关于作者
前滴滴出行技术专家,现任OPPO文档数据库mongodb负责人,负责oppo千万级峰值TPS/十万亿级数据量文档数据库mongodb内核研发及运维工作,一直专注于分布式缓存、高性能服务端、数据库、中间件等相关研发。后续持续分享《MongoDB内核源码设计、性能优化、最佳运维实践》,Github账号地址:https://github.com/y123456yz
背景
mongodb内核代码中提供有完善的gotool工具,这些开源工具作用主要有:数据导出及恢复(mongodump、mongorestore、mongoexport、mongoimport)工具、客户端shell链接工具(mongo)、IO测试工具(mongoperf)、流量qps/时延等监控统计工具(mongostat、mongotop)。
mongodb默认只提供mongostat和mongotop工具来完成流量和时延统计,这两个工具的主要功能如下:
mongostat:监控整个集群的qps统计信息
mongotop:监控表级的读写时延统计信息。
问题:
显然,mongostat和mongotop满足不了我们怼上面的两个问题的需求。实际上,mongodb内部实现上提供有对应的表级别qps和表级别时延统计接口,拿到这些接口统计后,我们就可以快速获取对应的数据结果,本文讲分析表级统计的实现原理及核心代码实现。
1. mongostat、mongotop监控统计信息
mongodb官方对外开源的qps及时延监控主要有mongostat和mongotop,本章节分析这两个工具的用法及监控项。
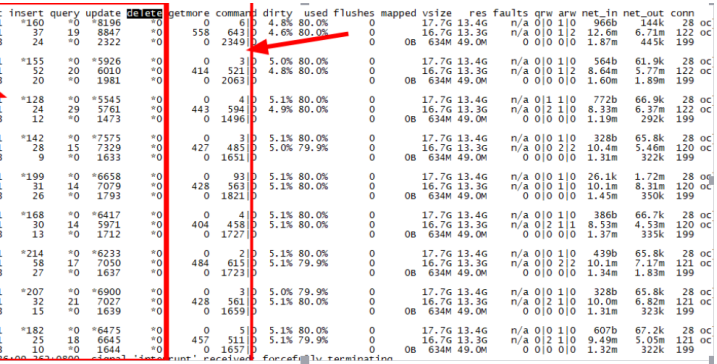
1.1 mongostat监控统计
mongodb提供了mongostat工具来监控当前集群的各种操作统计。Mongostat监控统计如下图所示:
其中,insert、delete、update、query这四项统计比较好理解,分别对应增、删、改、查,getMore记录批量拉数据时候的游标操作统计,command统计在mongos和mongod中有不同的涵义,具体参考:mongodb内核源码实现、性能调优、最佳运维实践系列-command命令处理模块源码实现三
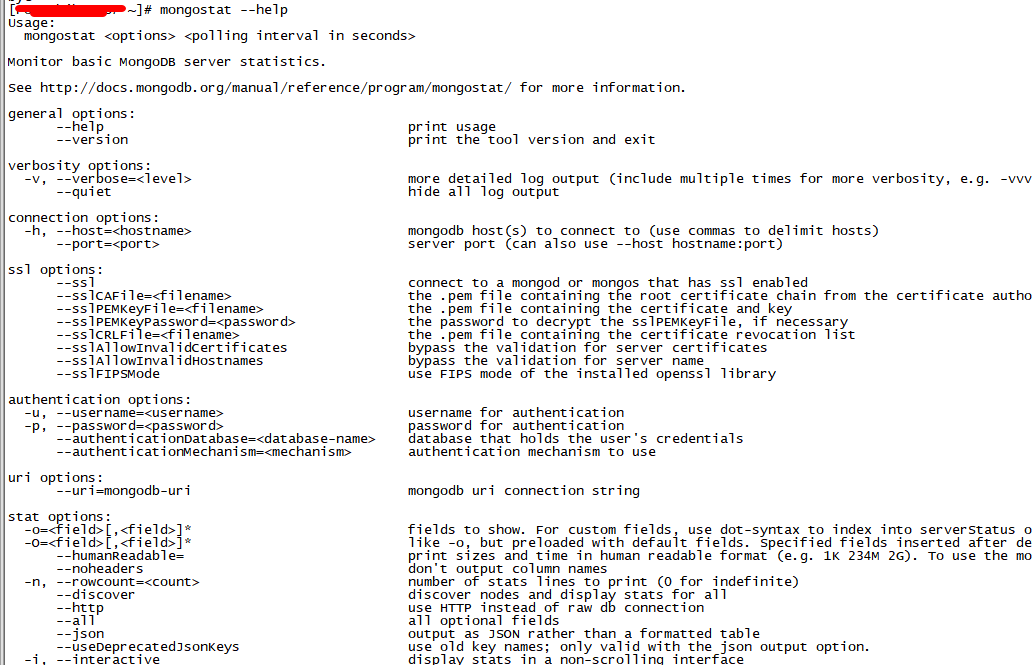
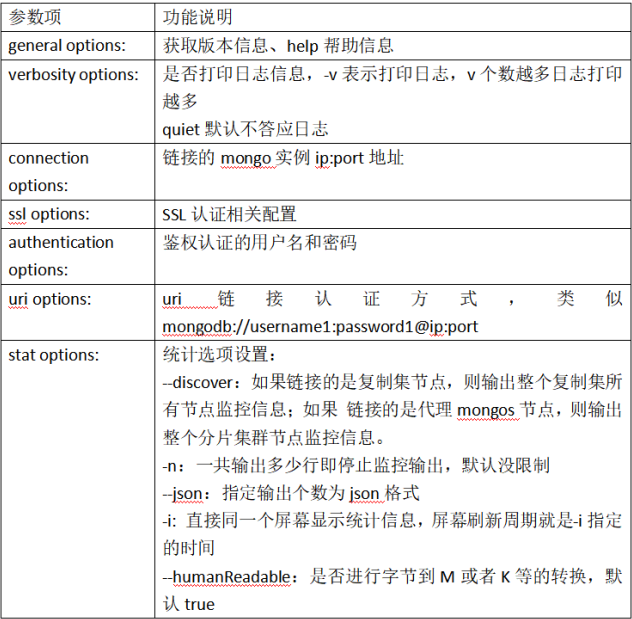
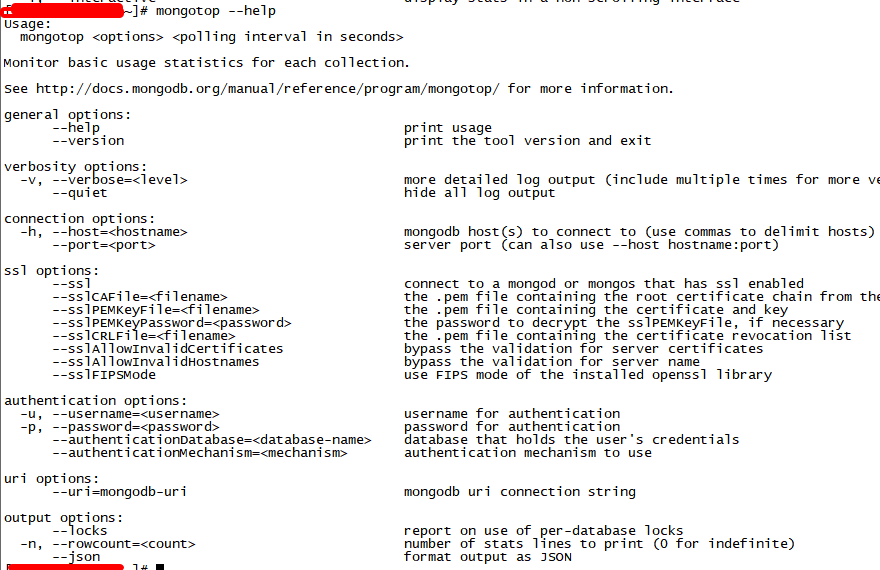
mongostat help参数功能详细说明如下:
1.2 mongotop监控统计
mongotop实现对所有表的读写时延消耗统计,并按照总耗时排序直观输出,对应统计打印信息如下图所示:
mongotop监控输出项各字段说明如下:
mongotop工具help参数信息说明如下表所示:
2. 表级详细操作统计及其时延监控统计
mongod实例会对表级别的增、删、改、查、getMore、command进行详细的操作统计,并对每种操作的时延进行统计。每个表都拥有一个CollectionData结构,该结构中存储所有操作统计和时延统计;同一个操作的qps统计和时延统计通过UsageData结构实现,包含count和time两个成员。
2.1表级统计实现原理
详细的表级统计通过以下几个类结构分层实现:
UsageMap是一个StringMap表结构,该map表中的成员类型为CollectionData,一个CollectionData对应一个表名及其该表的各自详细qps和时延统计信息,核心代码定义如下:
typedef StringMap<CollectionData> UsageMap;
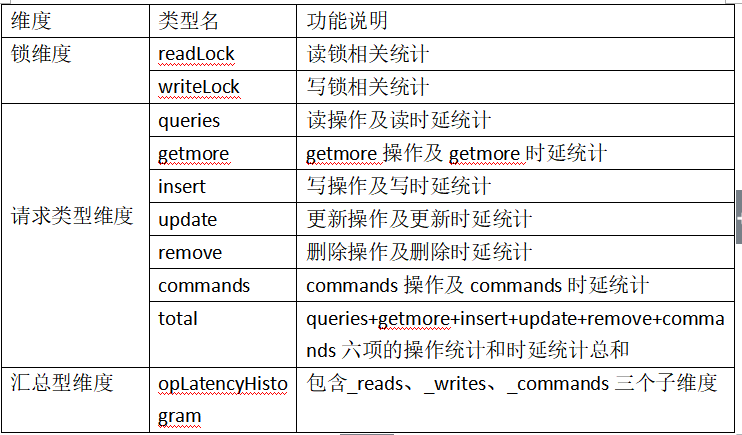
CollectionData结构中包含多个成员,包含了三个维度的统计,每个维度中的成员对应一个操作统计项,统计维度及其操作类型如下表:
UsageData完成上面的锁维度和请求类型维度的操作计数和时延计数,UsageData包含count和time两个成员,分别用于操作计数和时延计数。
OperationLatencyHistogram实现表级别的操作汇总计数和汇总型时延统计,在该汇总型统计中把请求类型维度中的六项操作(queries、getmore、insert、update、remove、commands)合并汇总为三项统计:_reads、_writes、_commands。
2.2核心代码实现
mongodb表级详细统计实现主要由src/mongo/db/stats/目录中的top.cpp、top.h、operation_latency_histogram.cpp、operation_latency_histogram.h四个文件完成。
2.2.1核心数据结构实现
核心数据结构代码实现如下:
1.class Top {
2. ......
3. //map表中每个表占用一个
4. struct CollectionData {
5. ......
6. //锁维度
7. UsageData readLock;
8. UsageData writeLock;
9.
10. //表级别不同操作的时延统计,粒度相比OperationLatencyHistogram更小
11. //请求类型维度,包含增、删、改、查、getMore、command六类
12. UsageData queries;
13. UsageData getmore;
14. UsageData insert;
15. UsageData update;
16. UsageData remove;
17. UsageData commands;
18. //总的,上面的[queries,commands]
19. UsageData total;
20.
21. //汇总型维度,包含读、写、command三个维度
22. OperationLatencyHistogram opLatencyHistogram;
23. };
24. //锁类型,读锁还是写锁
25. enum class LockType {
26. ReadLocked,
27. WriteLocked,
28. NotLocked,
29. };
30. //Top._usage 各种命令的详细统计记录在该map表中
31. //map表中每个表占用一个,参考Top::record
32. typedef StringMap<CollectionData> UsageMap;
33.
34.public:
35. //全局UsageMap表,表中每个成员对应一个collection表
36. UsageMap _usage;
37. ......
38.}
从上面的核心算法可以看出,UsageMap 为map表结构,包含有所有表名及其对应的表级请求统计和时延统计,每个表的所有统计记录到structCollectionData {} 结构中。
CollectionData 结构中的成员可以分为三类:锁统计、详细请求统计、汇总型统计,其中汇总型统计由class OperationLatencyHistogram {}类实现,核心成员如下:
1.class OperationLatencyHistogram {
2. ......
3.private:
4. //可以用于记录历史统计,通过buckets来区分,最大可以记录kMaxBuckets个历史统计信息
5. struct HistogramData {
6. std::array<uint64_t, kMaxBuckets> buckets{};
7. uint64_t entryCount = 0;
8. uint64_t sum = 0;
9. };
10. ......
11. HistogramData _reads, _writes, _commands;
}
2.2.2核心算法实现
按照不同的维度,表级详细统计核心算法实现可以包含:锁及请求类型详细统计算法实现、汇总型表级详细统计算法实现。
mongodb按照不同统计维度,同一个请求可以归纳到不同锁类型,同时也可以归纳到不同请求类型。例如,db.test.find({xxx})这个查询,在对test表详细统计的时候,该查询会同时对该表的读锁readLock统计及queries统计进行计数,也就是会同时记录该操作锁操作计数和查询操作计数。
锁类型统计及请求类型表级统计核心算法实现如下:
1. 找出对应表统计存储结构CollectionData
1.void Top::record(...) {
2. ......
3.
4. //根据表名从Map表种找到该表在表中对应hash位置
5. auto hashedNs = UsageMap::HashedKey(ns);
6. stdx::lock_guard<SimpleMutex> lk(_lock);
7.
8. //如果ns是已经删除的表,直接返回
9. if ((command || logicalOp == LogicalOp::opQuery) && ns == _lastDropped) {
10. _lastDropped = "";
11. return;
12. }
13. //找到改表对应的CollectionData
14. CollectionData& coll = _usage[hashedNs];
15. //开始表级计数统计
16. _record(opCtx, coll, logicalOp, lockType, micros, readWriteType);
17.}
2. 对该表进行真正的计数统计操作
1.//Top::record调用 各个命令的op及时延统计
2.void Top::_record(...) {
3. //汇总型详细表级统计
4. _incrementHistogram(opCtx, micros, &c.opLatencyHistogram, readWriteType);
5. //该表总时延计数,包括增删改查getMore command六项 及其他所有的统计
6. c.total.inc(micros);
7. //写锁计数
8. if (lockType == LockType::WriteLocked)
9. c.writeLock.inc(micros);
10. //读锁计数
11. else if (lockType == LockType::ReadLocked)
12. c.readLock.inc(micros);
13.
14. //详细增 删 改 查 getMore command统计及时延
15. switch (logicalOp) {
16. //无效类型
17. case LogicalOp::opInvalid:
18. // use 0 for unknown, non-specific
19. break;
20. case LogicalOp::opUpdate: //增
21. c.update.inc(micros);
22. break;
23. case LogicalOp::opInsert: //插入
24. c.insert.inc(micros);
25. break;
26. case LogicalOp::opQuery: //查询
27. c.queries.inc(micros);
28. break;
29. case LogicalOp::opGetMore: //getMore游标
30. c.getmore.inc(micros);
31. break;
32. case LogicalOp::opDelete: //删除
33. c.remove.inc(micros);
34. break;
35. case LogicalOp::opKillCursors: //
36. break;
37. case LogicalOp::opCommand:
38. c.commands.inc(micros);
39. break;
40. default:
41. MONGO_UNREACHABLE;
42. }
43.}
汇总型操作详细统计主要实现读、写、command操作统计及对应时延统计,这类操作核心代码实现如下:
按照不同操作分类
1.//不同请求归类参考getReadWriteType
2.//Top::_incrementHistogram 操作和时延计数操作
3.void OperationLatencyHistogram::increment(uint64_t latency, Command::ReadWriteType type) {
4. //确定latency时延对应在[0-2]、(2-4]、(4-8]、(8-16]、(16-32]、(32-64]、(64-128]...中的那个区间
5. int bucket = _getBucket(latency);
6. switch (type) {
7. //读时延累加,操作计数自增
8. case Command::ReadWriteType::kRead:
9. _incrementData(latency, bucket, &_reads);
10. break;
11. //写时延累加,操作计数自增
12. case Command::ReadWriteType::kWrite:
13. _incrementData(latency, bucket, &_writes);
14. break;
15. //command时延累加,操作计数自增
16. case Command::ReadWriteType::kCommand:
17. _incrementData(latency, bucket, &_commands);
18. break;
19. default:
20. MONGO_UNREACHABLE;
21. }
22.}
2. 对应分类操作计数、时延计数
1.//OperationLatencyHistogram::increment中调用
2.//读 写 command总操作自增,时延对应增加latency
3.void OperationLatencyHistogram::_incrementData(uint64_t latency, int bucket, HistogramData* data) {
4. //落在bucket桶指定时延范围的对应操作数自增
5. data->buckets[bucket]++;
6. //该操作总计数
7. data->entryCount++;
8. //该操作总时延计数
9. data->sum += latency;
}
3. 时延范围分区桶统计
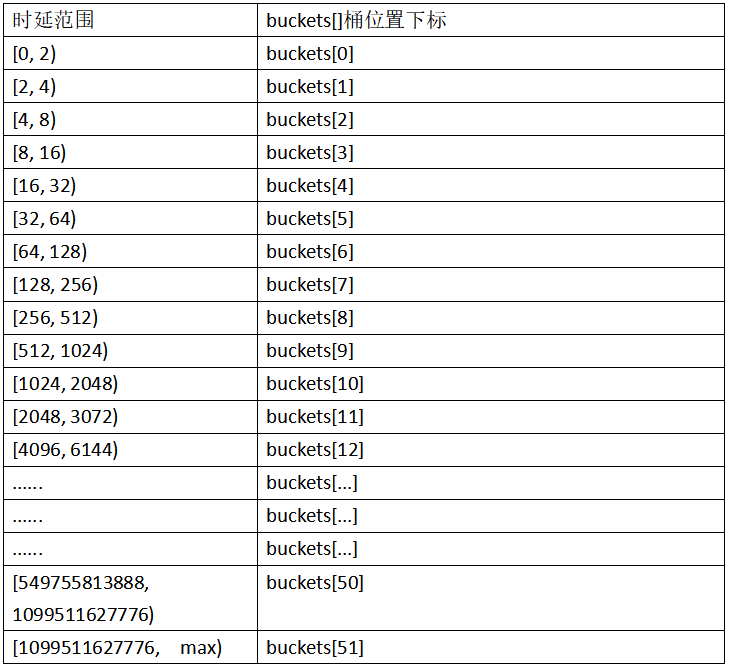
mongodb进行汇总型操作及时延统计后,可以获取总体的读、写、command平均时延,但是无法获取例如最大时延、95%分位时延、99分位时延等。mongodb为了满足这些需求,同时降低代码实现难度,通过分区时延统计来满足业务的这些需求。
时延范围分区桶实现原理:根据时延值,按照如下时延范围和分区桶得对应关系来完成统计操作,时延和桶的对应关系如下图所示:
时延范围分区桶核心算法实现核心代码实现如下:
1.//桶计数
2.void OperationLatencyHistogram::_incrementData(uint64_t latency, int bucket, HistogramData* data) {
3. //落在bucket桶指定时延范围的对应操作数自增
4. data->buckets[bucket]++;
5. ......
6.}
7.
8.//不同请求归类参考getReadWriteType
9.//Top::_incrementHistogram 操作和时延计数操作
10.void OperationLatencyHistogram::increment(uint64_t latency, Command::ReadWriteType type) {
11. //确定latency时延对应在[0-2]、(2-4]、(4-8]、(8-16]、(16-32]、(32-64]、(64-128]...中的那个区间
12. int bucket = _getBucket(latency);
13. switch (type) {
14. //读时延累加,操作计数自增
15. case Command::ReadWriteType::kRead:
16. _incrementData(latency, bucket, &_reads);
17. break;
18. //写时延累加,操作计数自增
19. case Command::ReadWriteType::kWrite:
20. _incrementData(latency, bucket, &_writes);
21. break;
22. //command时延累加,操作计数自增
23. case Command::ReadWriteType::kCommand:
24. _incrementData(latency, bucket, &_commands);
25. break;
26. default:
27. MONGO_UNREACHABLE;
28. }
}
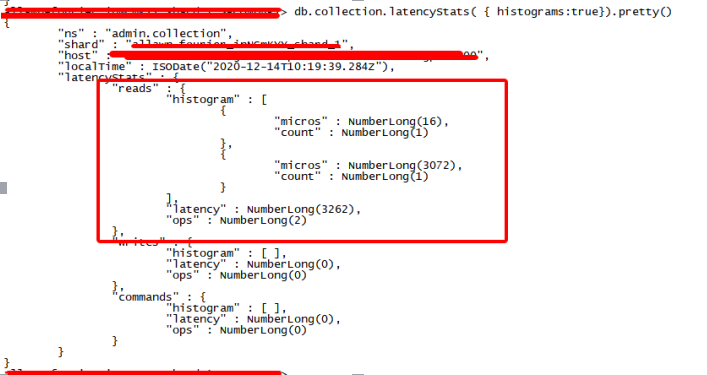
从上面的代码可以看出,汇总型统计中的读、写、command操作统计及时延统计包含该请求类型中的所有时延范围分区桶统计,已下图中的collection表read统计为例:
1. reads.ops=reads.histogram[]数组count之和
2. histogram.micros代表时延范围分区桶的时延边界值,例如2、4、8、16,以此类推。
3. 表级详细统计对外接口
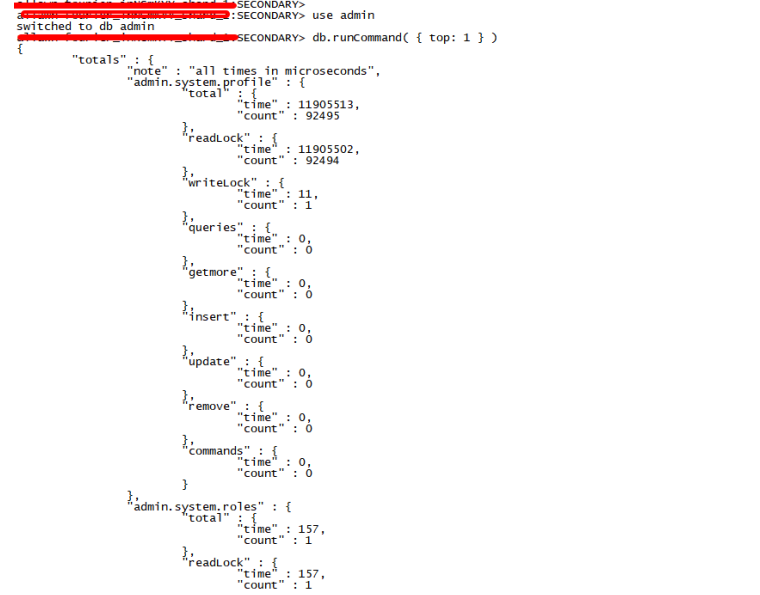
3.1表级别锁维度及请求类型维度相关统计接口
表级别锁维度及请求类型维度相关统计对外接口可以通过下面的命令获取得到(注:只能在mongod实例执行):
use admin
db.runCommand( { top: 1 } )
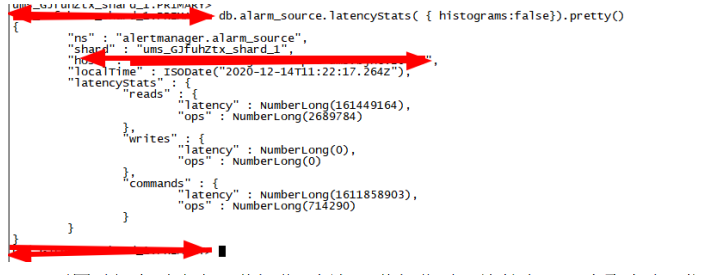
3.2汇总型表级别统计
表级别汇总型读、写、command相关操作及时延统计可以通过如下命令获取:
不同时间段对应有那些操作,例如那些操作时延比较高,可以通过时延范围分区桶统计接口获取:













评论