Web 渗透测试:信息收集篇


[toc]
在之前的一系列文章中,我们主要讲了内网渗透的一些知识,而在现实中,要进行内网渗透,一个很重要的前提便是:你得能进入内网啊!所以,从这篇文章开始,我们将开启 Web 渗透的学习(内网渗透系列还会继续长期更新哦)。
渗透测试,是渗透测试工程师完全模拟黑客可能使用的攻击技术和漏洞发现技术,对目标网络、主机、应用的安全作深入的探测,帮助企业挖掘出正常业务流程中的安全缺陷和漏洞,助力企业先于黑客发现安全风险,防患于未然。
Web 应用的渗透测试流程主要分为 3 个阶段,分别是:信息收集→漏洞发现→漏洞利用。本文我们将对信息收集这一环节做一个基本的讲解。
信息收集介绍
进行 web 渗透测试之前,最重要的一步那就是就是信息收集了,俗话说“渗透的本质也就是信息收集”,信息收集的深度,直接关系到渗透测试的成败。打好信息收集这一基础可以让测试者选择合适和准确的渗透测试攻击方式,缩短渗透测试的时间。一般来说收集的信息越多越好,通常包括以下几个部分:
域名信息收集
子域名信息收集
站点信息收集
敏感信息收集
服务器信息收集
端口信息收集
真实 IP 地址识别
社会工程学
下面我们对这几种信息收集分别做相应的讲解。
域名信息收集
域名(英语:Domain Name),又称网域,是由一串用点分隔的名字组成的 Internet 上某一台计算机或计算机组的名称,用于在数据传输时对计算机的定位标识(有时也指地理位置)。由于 IP 地址具有不方便记忆并且不能显示地址组织的名称和性质等缺点,人们设计出了域名,并通过网域名称系统来将域名和 IP 地址相互映射,使人更方便地访问互联网,而不用去记住能够被机器直接读取的 IP 地址数串。
顶级域名/一级域名:
顶级域(或顶级域名,也称为一级域名),是互联网 DNS 等级之中的最高级的域,它保存于 DNS 根域的名字空间中。顶级域名是域名的最后一个部分,即是域名最后一点之后的字母,例如在http://www.example.com这个域名中,**顶级域是****.com**。
二级域名:
除了顶级域名,还有二级域名,就是最靠近顶级域名左侧的字段。例如在http://www.example.com这个域名中,example就是二级域名。
子域名:
子域名(或子域;英语:Subdomain)是在域名系统等级中,属于更高一层域的域。比如,mail.example.com 和 calendar.example.com 是 example.com 的两个子域,而 example.com 则是顶级域.com 的子域。凡顶级域名前加前缀的都是该顶级域名的子域名,而子域名根据技术的多少分为二级子域名,三级子域名以及多级子域名。
一般来说,在做渗透测试之前,渗透测试人员能够了解到的信息有限,一般也就只知道一个域名,这就需要渗透测试人员首先要针对一个仅有的域名进行信息搜集,获取域名的注册信息,包括该域名的 DNS 服务器信息、子域信息和注册人的联系信息等信息。可以用以下几种方法来收集域名信息。
Whois 查询
whois 是用来查询域名的 IP 以及所有者等信息的传输协议。简单说,whois 就是一个用来查询域名是否已经被注册,以及注册域名的详细信息的数据库(如域名所有人、域名注册商),不同域名后缀的 Whois 信息需要到不同的 Whois 数据库查询。通过 whois 来实现对域名信息的查询,可以得到注册人的姓名和邮箱信息通常对测试个人站点非常有用,因为我们可以通过搜索引擎和社交网络挖掘出域名所有人的很多信息。
(1)在线查询
如今网上出现了一些网页接口简化的线上查询工具,可以一次向不同的数据库查询。网页接口的查询工具仍然依赖 whois 协议向服务器发送查询请求,命令列接口的工具仍然被系统管理员广泛使用。whois 通常使用 TCP 协议 43 端口。每个域名/IP 的 whois 信息由对应的管理机构保存。
常见的网站包括:
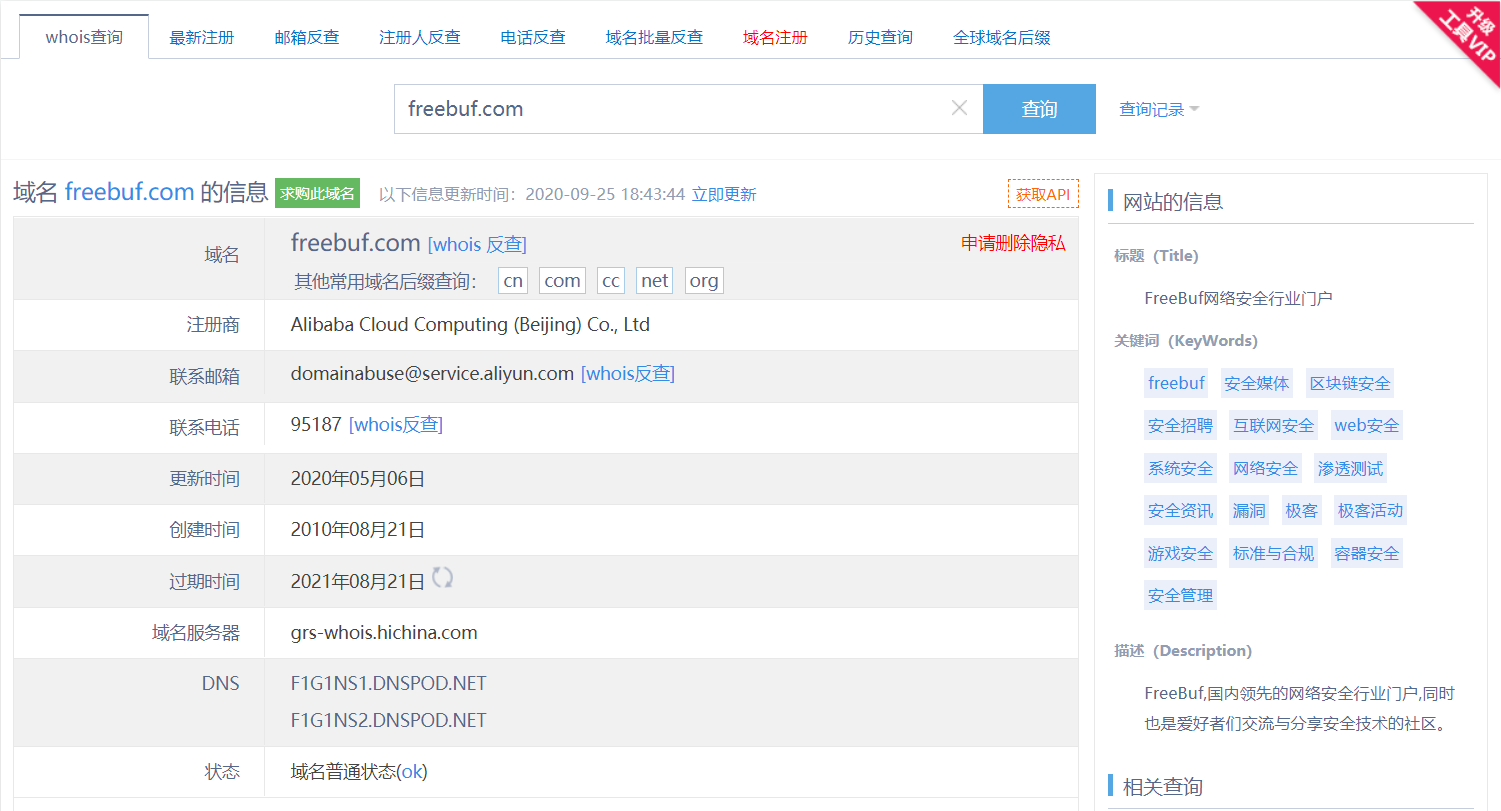
Whois 站长之家查询:http://whois.chinaz.com/
阿里云中国万网查询:https://whois.aliyun.com/
Whois Lookup 查找目标网站所有者的信息:http://whois.domaintools.com/
Netcraft Site Report 显示目标网站上使用的技术:http://toolbar.netcraft.com/site_report?url=
Robtex DNS 查询显示关于目标网站的全面的 DNS 信息:https://www.robtex.com/
全球 Whois 查询:https://www.whois365.com/cn/
站长工具爱站查询:https://whois.aizhan.com/
示例:下面是使用站长之家 Whois 查询 freebuf 域名的相关信息:
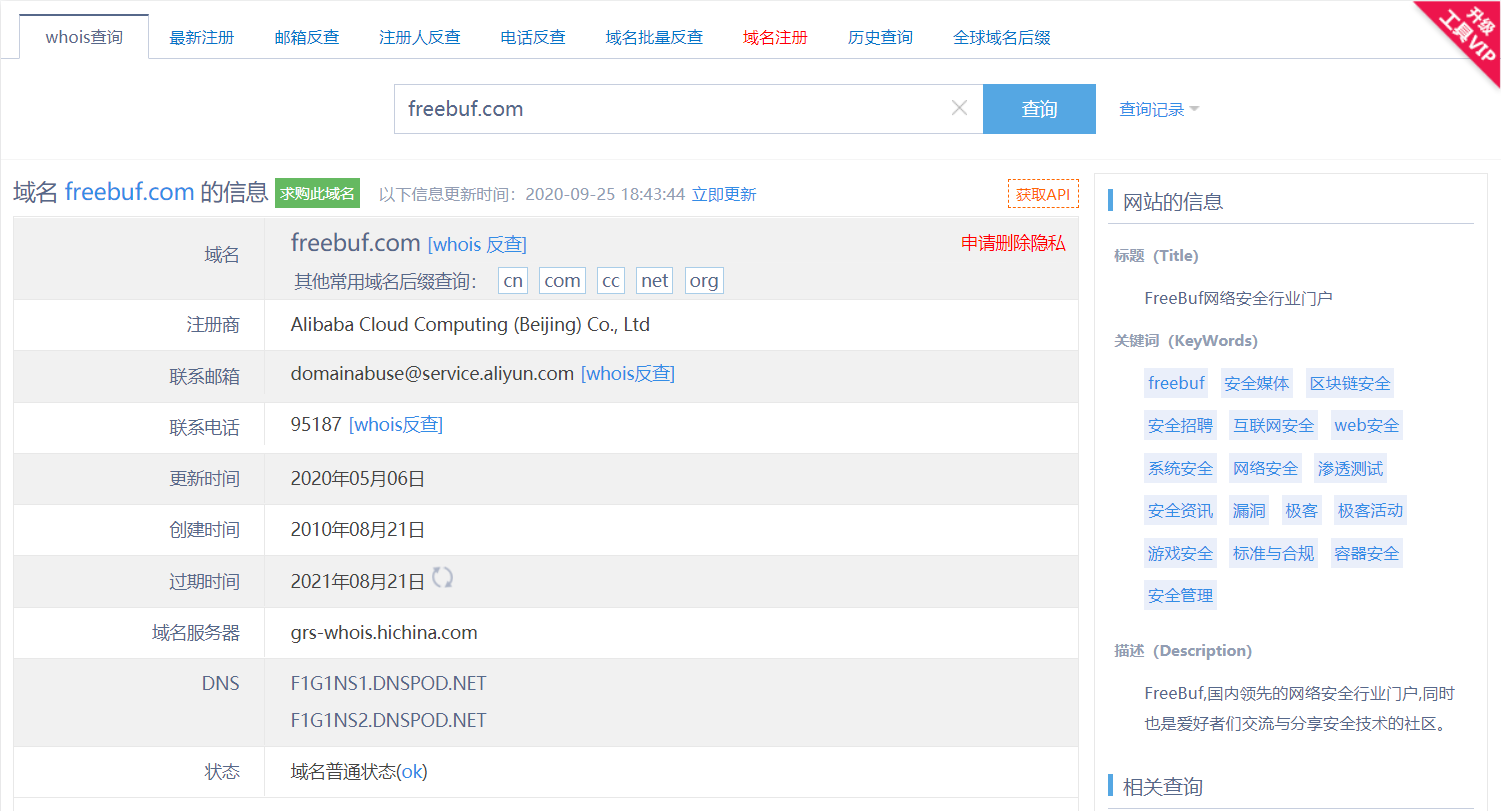
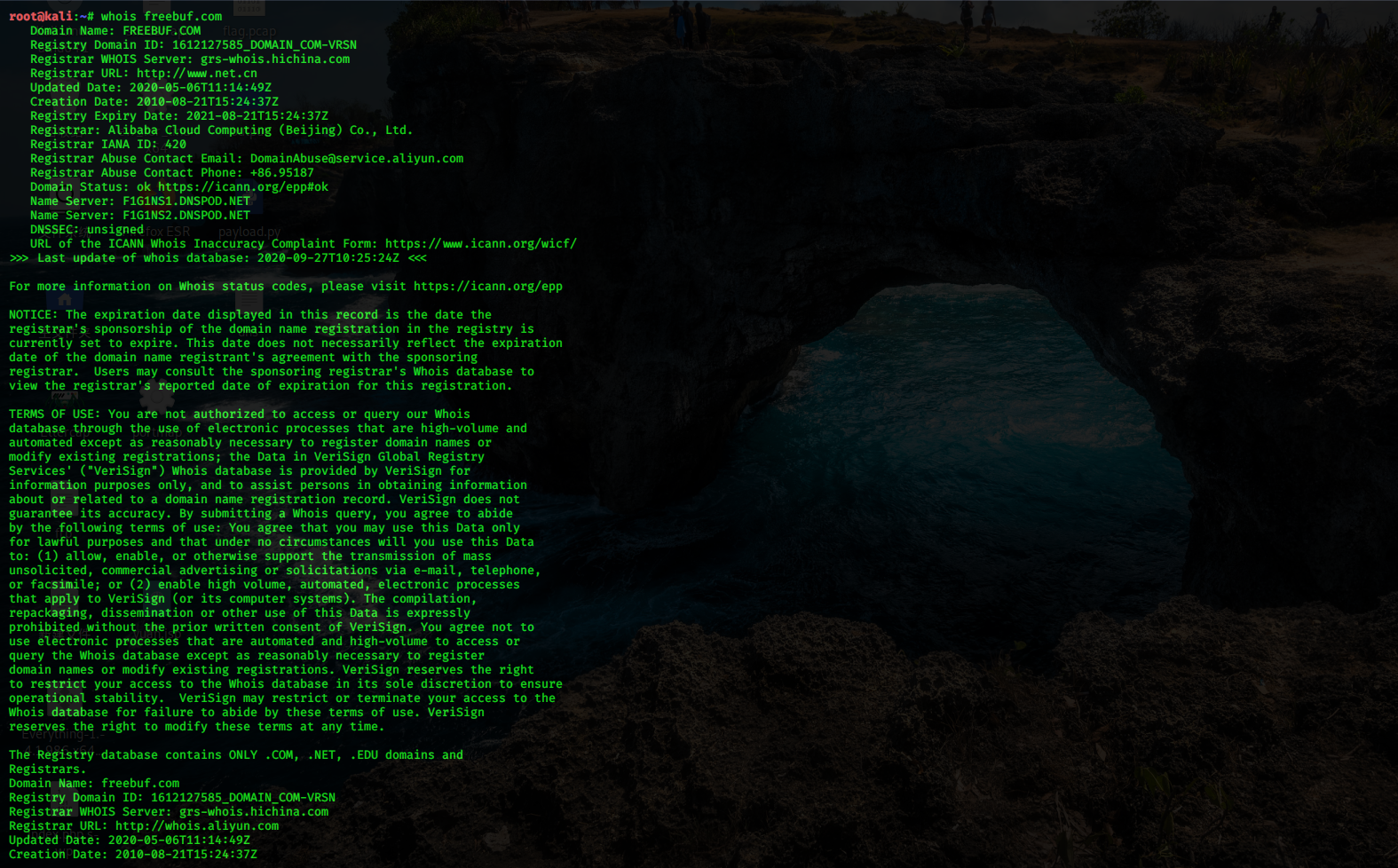
(2)使用 kali 中的 whois 工具查询
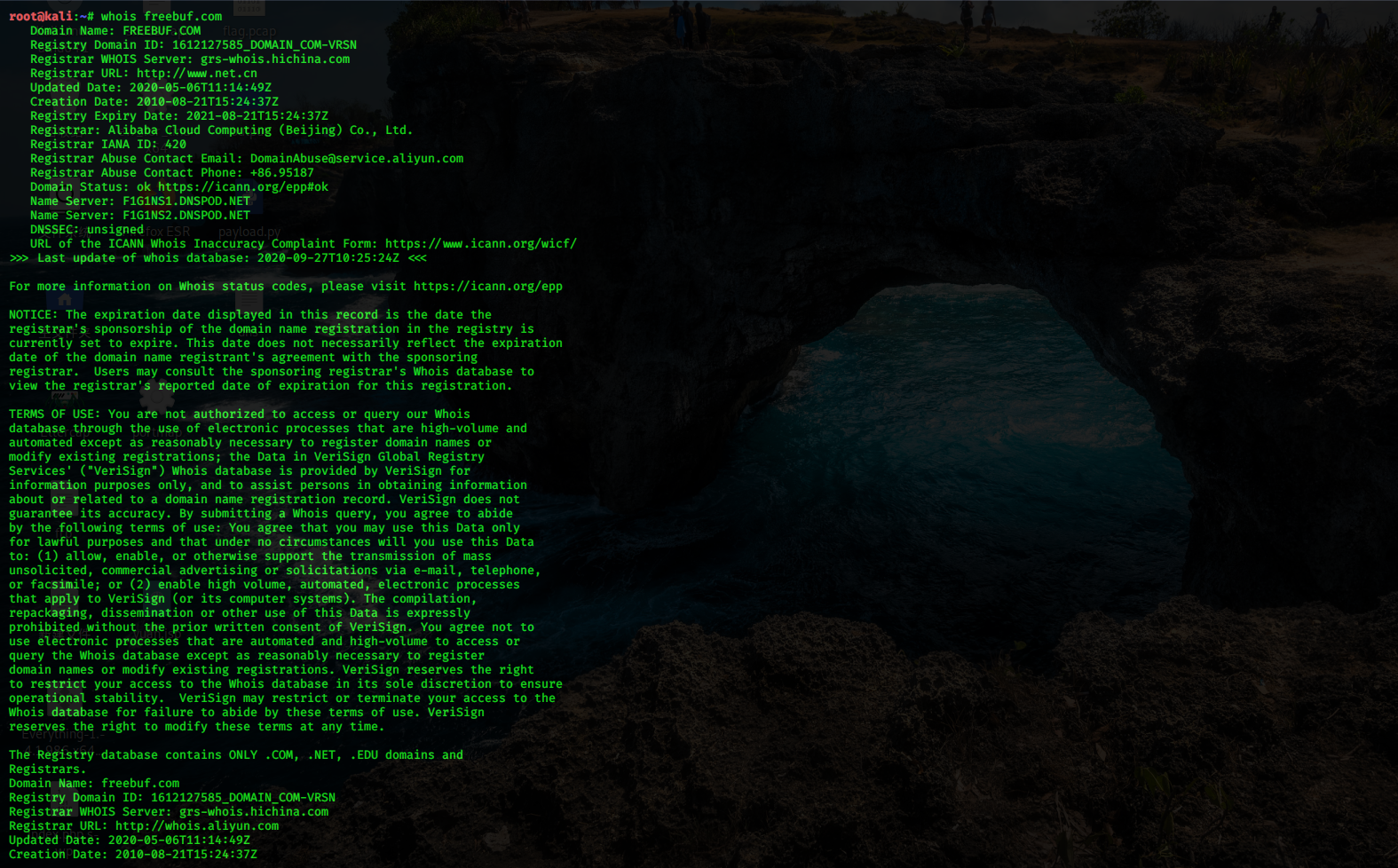
在 Kali Linux 下自带的 Whois 查询工具,通过命令 Whois 查询域名信息,只需输入要查询的域名即可,如下图所示。
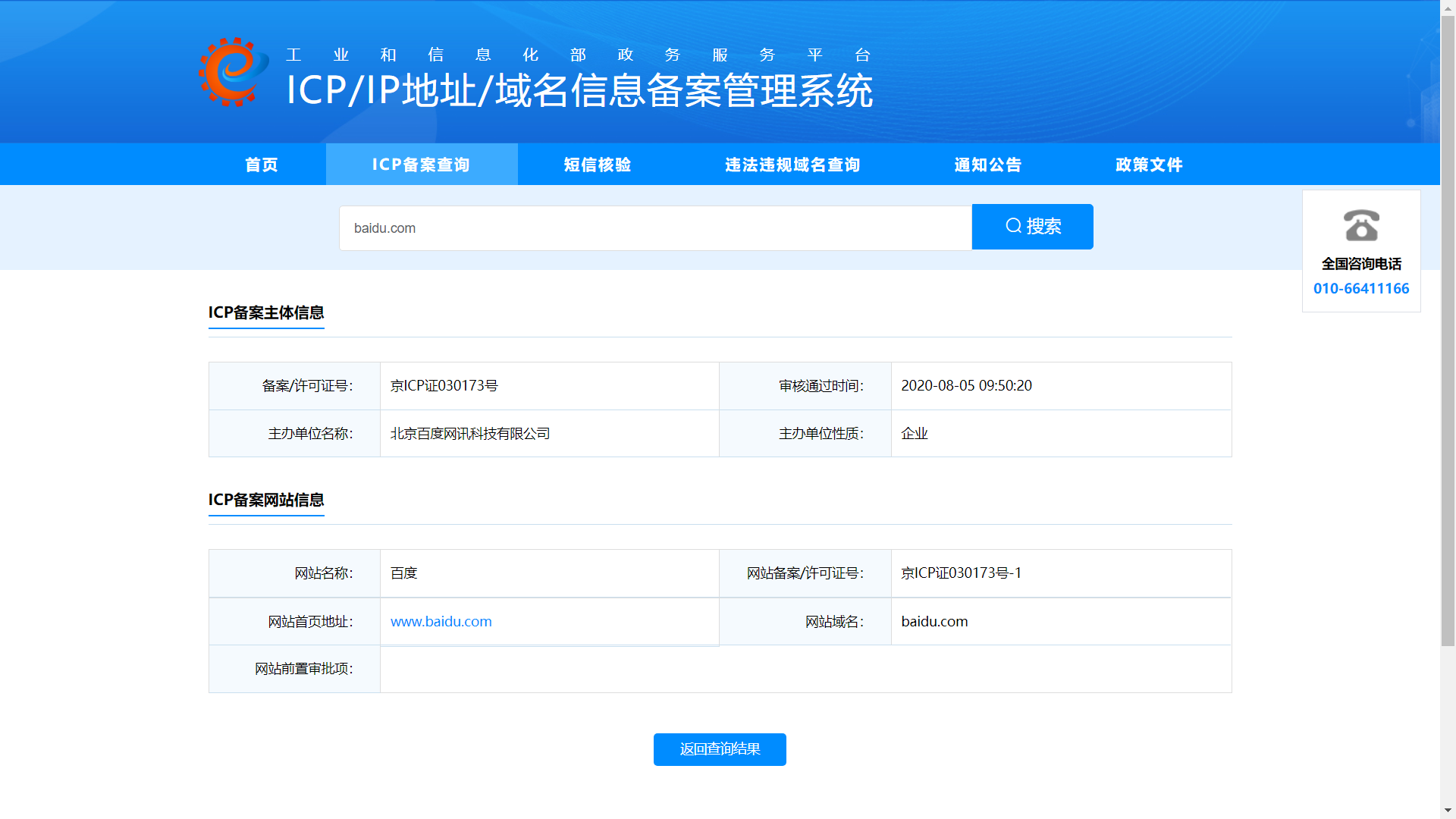
备案信息查询
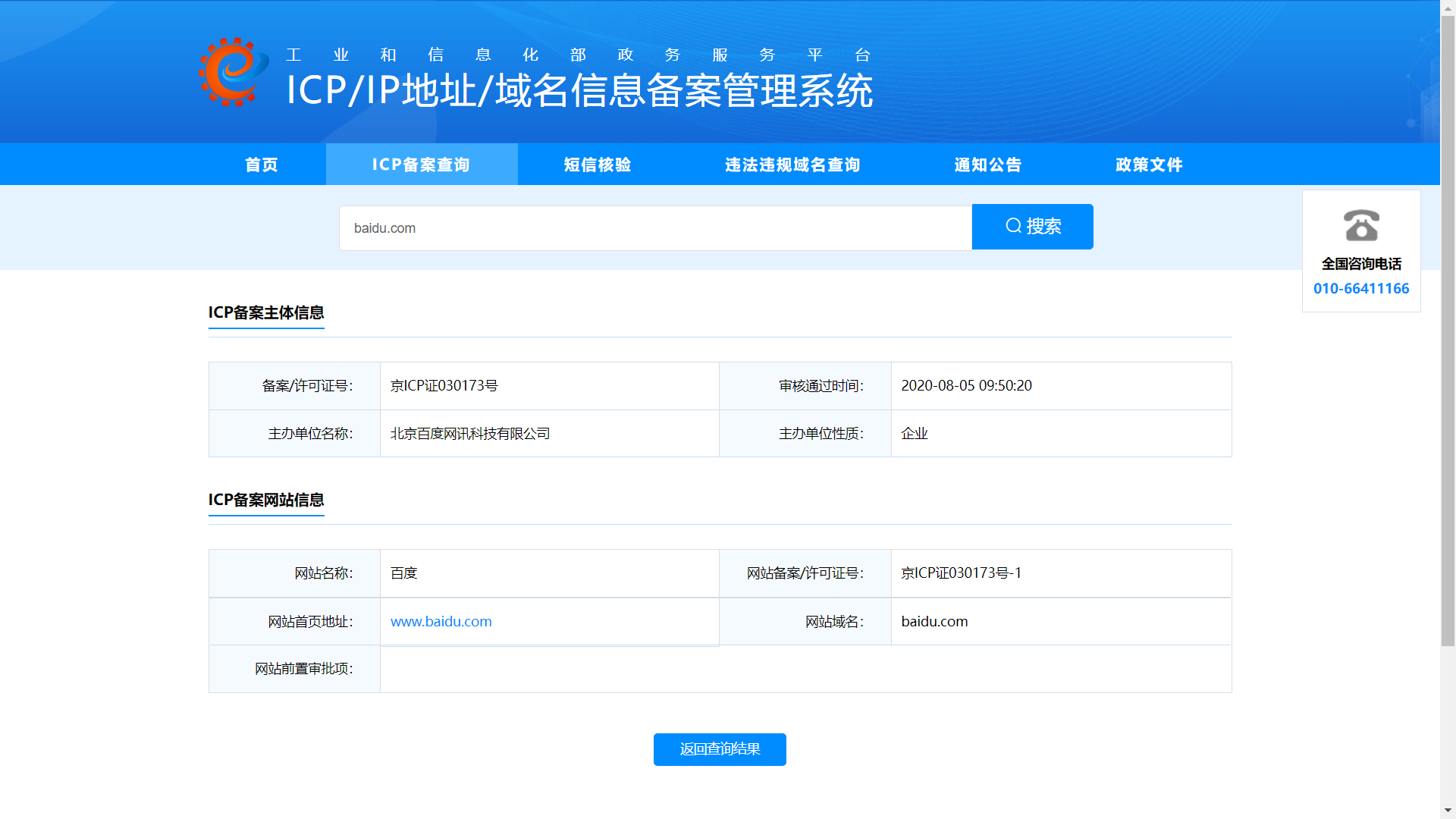
网站备案信息是根据国家法律法规规定,由网站所有者向国家有关部门申请的备案,是国家信息产业部对网站的一种管理途径,是为了防止在网上从事非法网站经营活动,当然主要是针对国内网站。
在备案查询中我们主要关注的是:单位信息例如名称、备案编号、网站负责人、法人、电子邮箱、联系电话等。
常用的备案信息查询网站有以下几个:
ICP/IP 地址/域名信息备案管理系统:http://beian.miit.gov.cn/publish/query/indexFirst.action
ICP 备案查询网:http://www.beianbeian.com/
企业资产查询
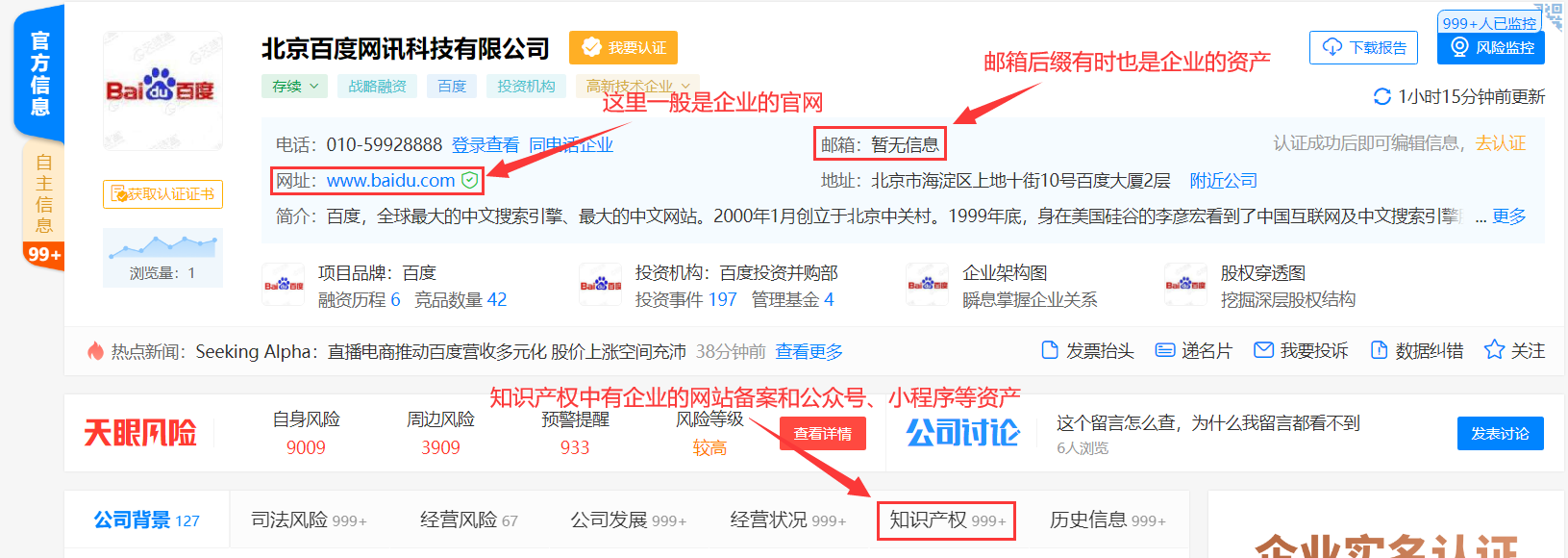
天眼查、企查查等查企业的软件也是非常重要的信息收集途径,每次攻防演练的目标名单中总有各种公司,有国企也有私企,其中的小型民营企业相比其他的政府、大型互联网企业、金融、电力等目标要好打得多,因此它们总是首要目标,而天眼查、企查查等作为查企业最牛逼的网站,其重要性也就不言而喻了。
下面以天眼查为例介绍:
天眼查中共有 3 个地方可能出现目标的资产:
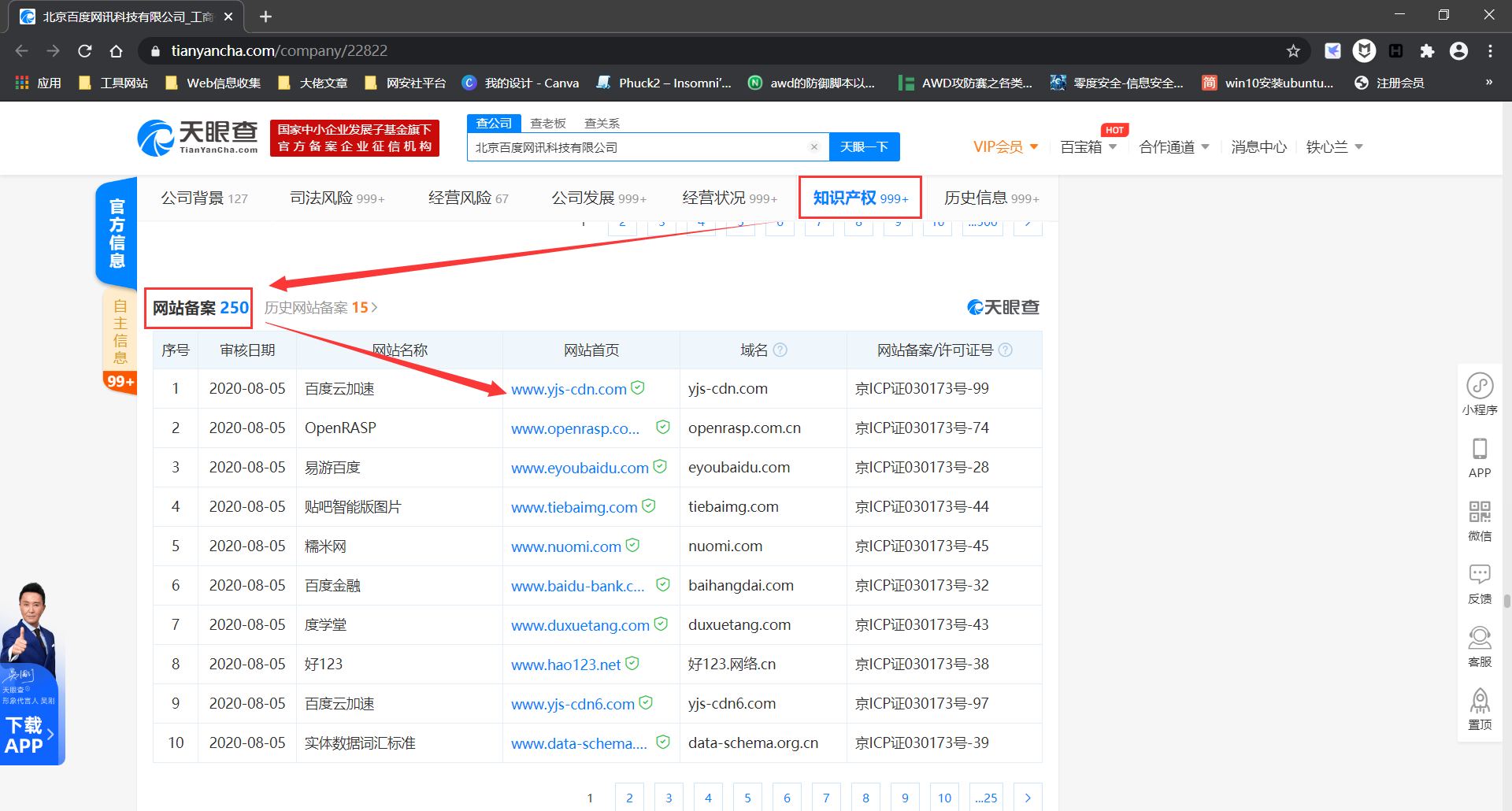
子域名信息收集
子域名(或子域;英语:Subdomain)是在域名系统等级中,属于更高一层域的域。比如,mail.example.com 和 calendar.example.com 是 example.com 的两个子域,而 example.com 则是顶级域.com 的子域。凡顶级域名前加前缀的都是该顶级域名的子域名,而子域名根据技术的多少分为二级子域名,三级子域名以及多级子域名。
为什么要收集子域名
子域名枚举可以在测试范围内发现更多的域或子域,这将增大漏洞发现的几率。
有些隐藏的、被忽略的子域上运行的应用程序可能帮助我们发现重大漏洞。
在同一个组织的不同域或应用程序中往往存在相同的漏洞
假设我们的目标网络规模比较大,直接从主域入手显然是很不理智的,因为对于这种规模的目标,一般其主域都是重点防护区域,所以不如先进入目标的某个子域,然后再想办法迂回接近真正的目标,这无疑是个比较好的选择。
收集子域名的方法有以下几种:
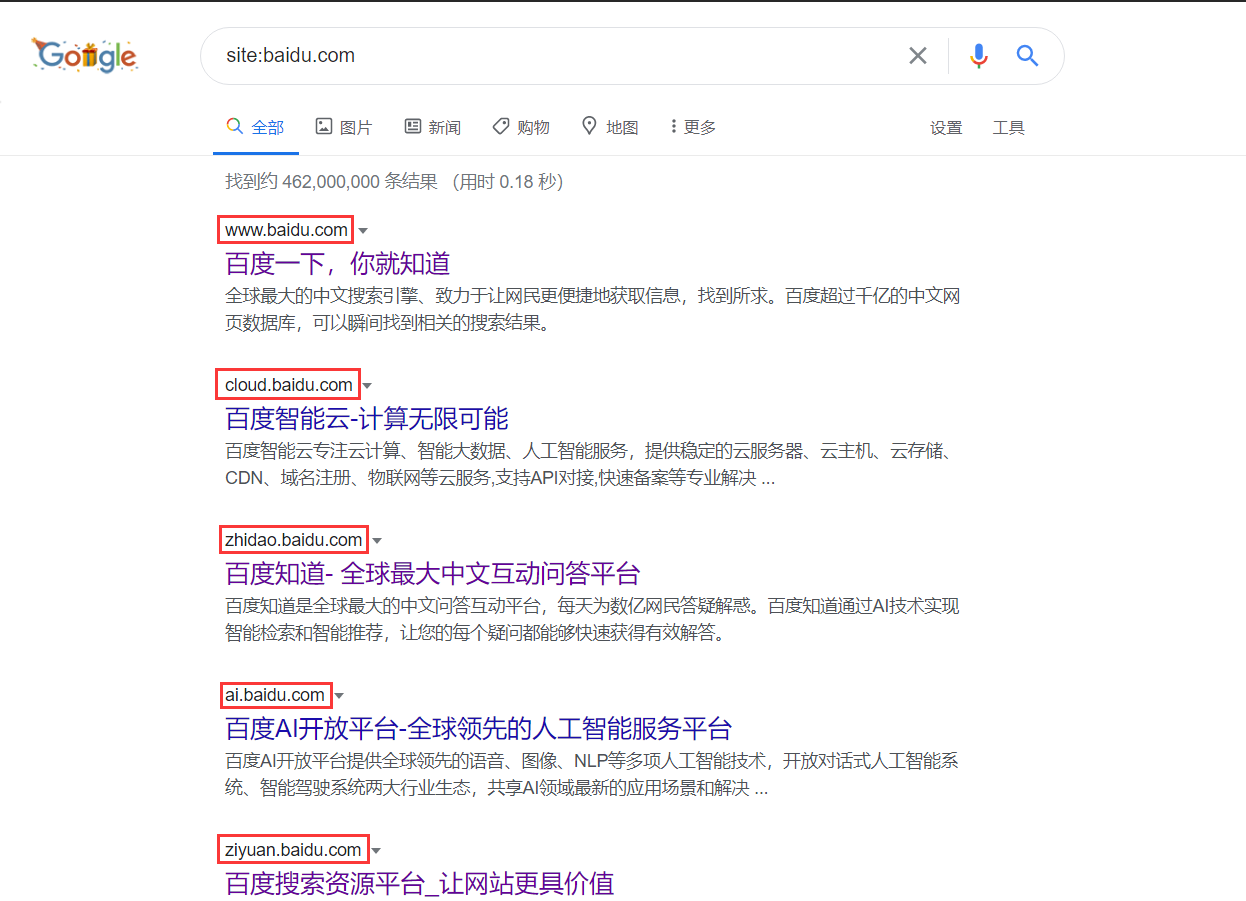
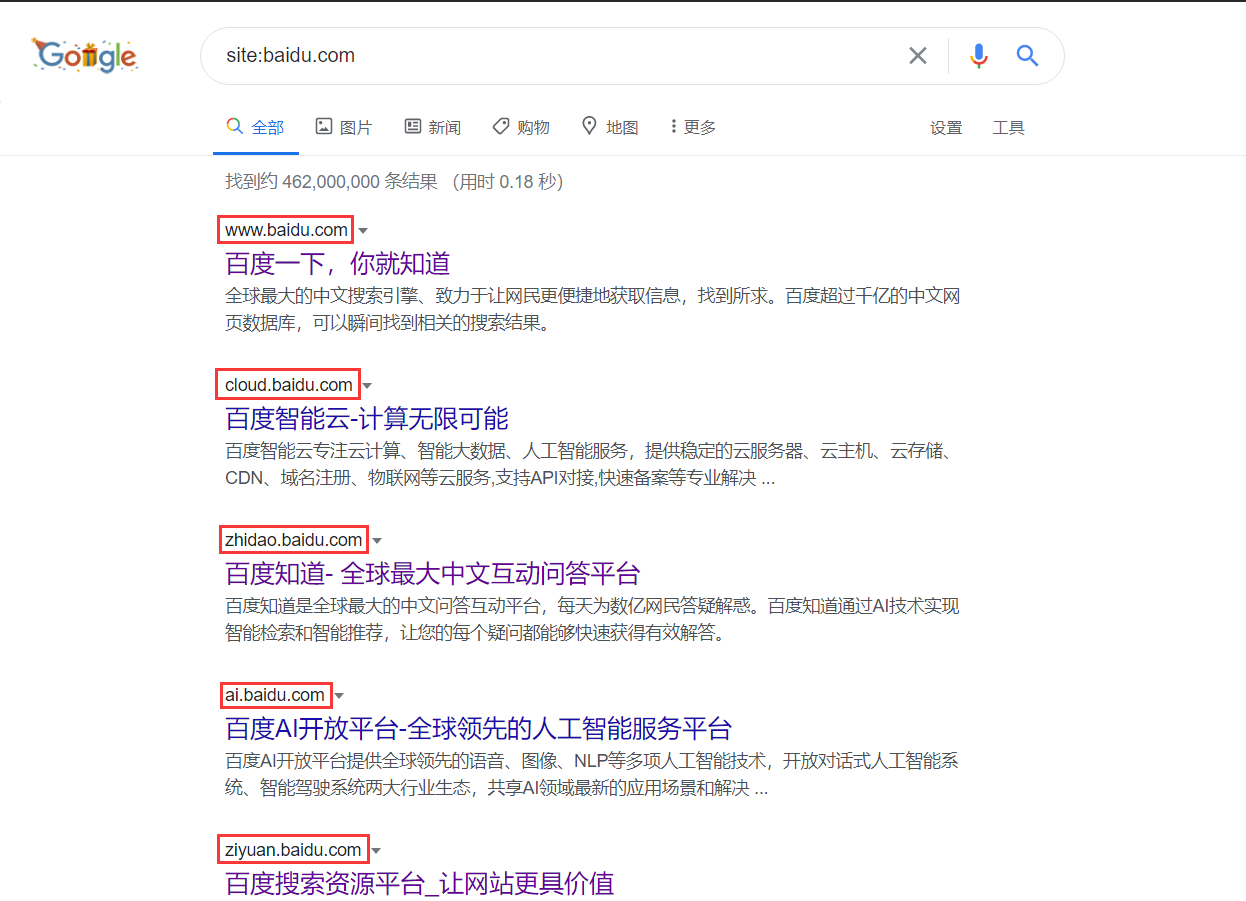
利用搜索引擎查询
我们可以利用 Google 语法搜索子域名,我们以百度的域名为例,使用“site:baidu.com”语法,如下图所示。
利用在线工具查询
网上有很多子域名的查询站点,可通过它们检索某个给定域名的子域名。如:
DNSdumpster:https://dnsdumpster.com/
whois 反查:http://whois.chinaz.com/
virustotal:www.virustotal.com
IP 反查绑定域名:http://dns.aizhan.com/
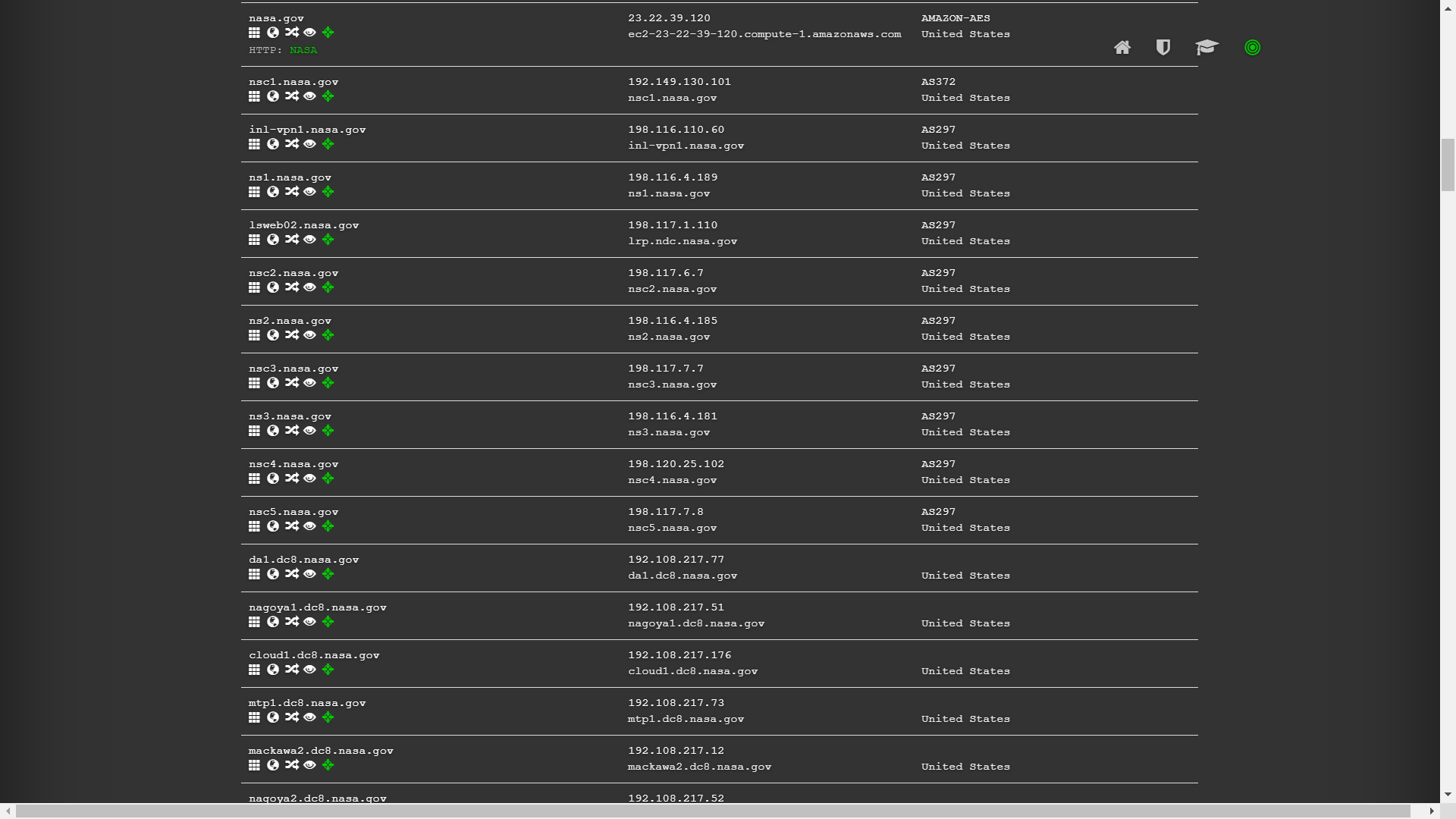
我们用 DNSdumpster 查询 nasa 的子域名:
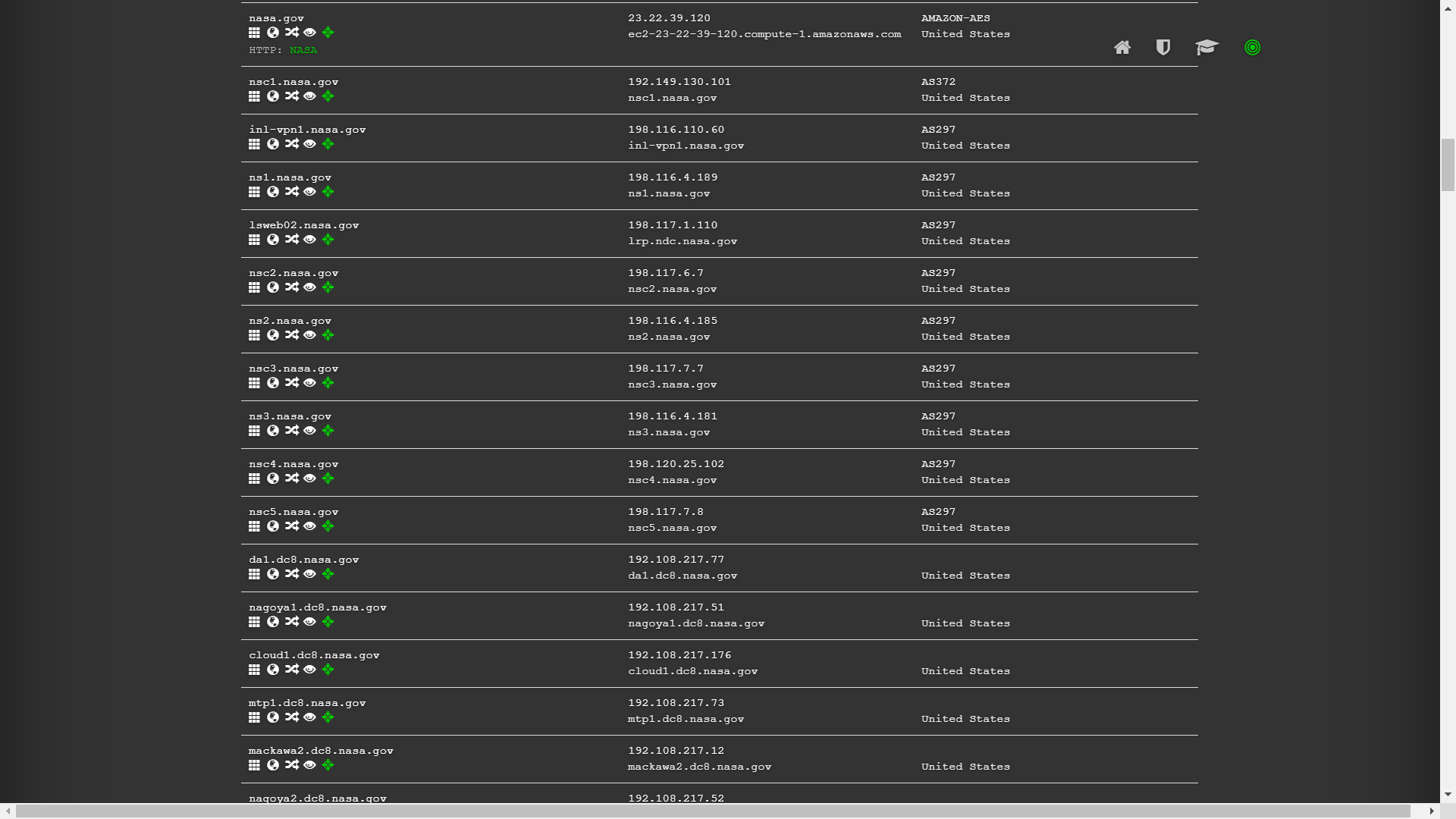
通过证书透明度公开日志枚举子域名
证书透明度是证书授权机构的一个项目,证书授权机构会将每个 SSL/TLS 证书发布到公共日志中。一个 SSL/TLS 证书通常包含域名、子域名和邮件地址,这些也经常成为攻击者非常希望获得的有用信息。
查找某个域名所属证书的最简单的方法就是使用搜索引擎来搜索一些公开的 CT 日志,例如以下网站:
crt.sh:https://crt.sh
censys:https://censys.io
利用工具枚举子域名
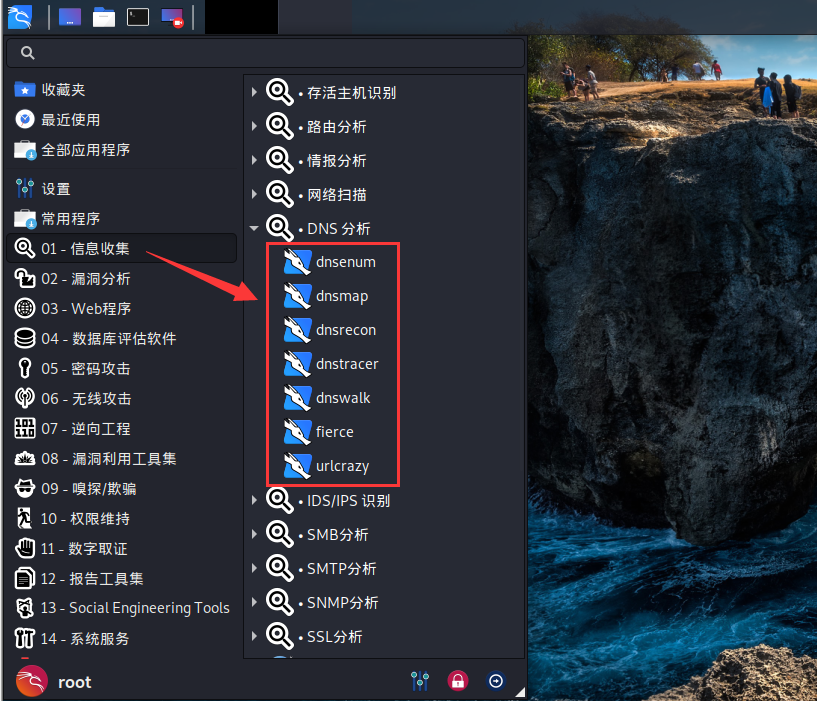
kali 上的工具
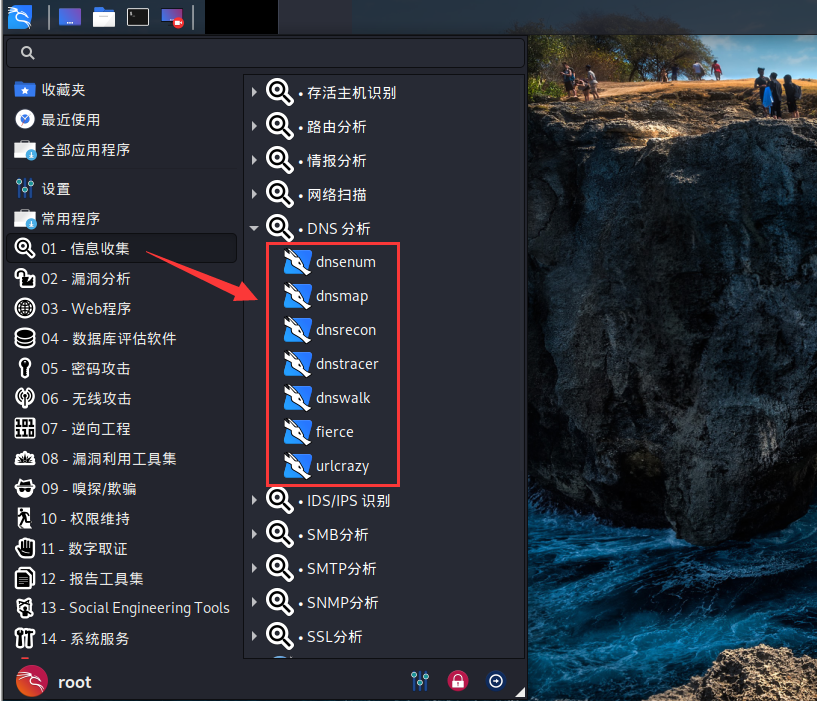
在 kali 中的信息收集模块的 DNS 分析中,有很多工具可以进行域名信息收集,如上图。
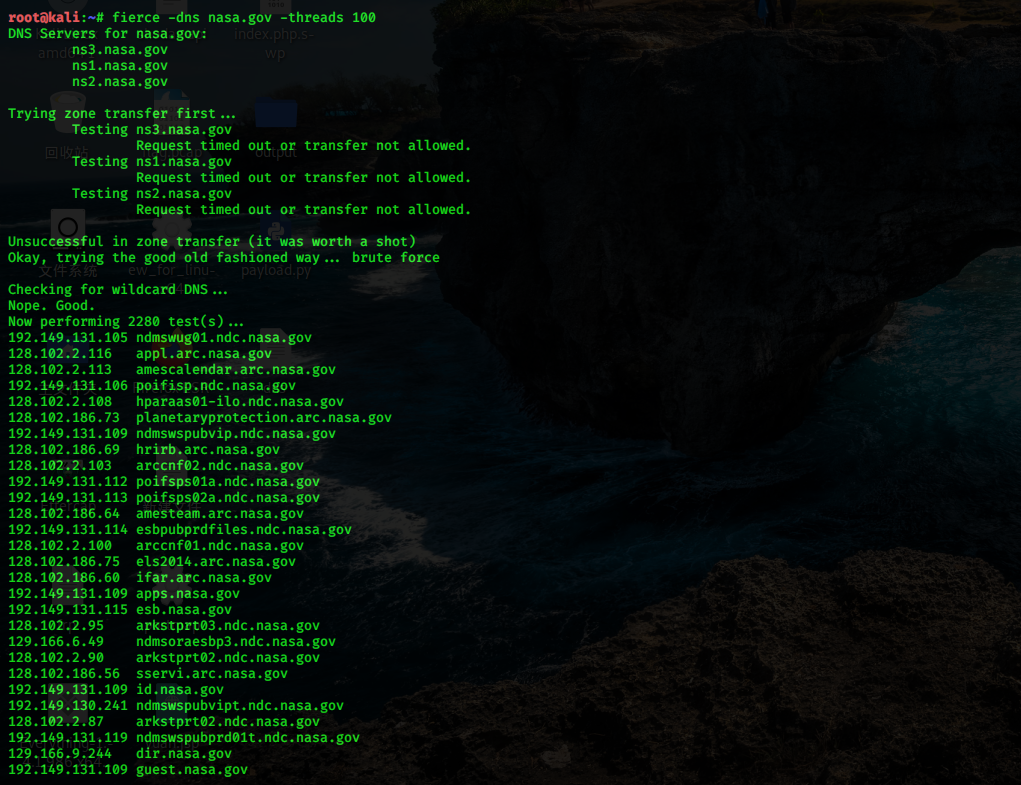
我们可以利用 Fierce 工具,进行子域名枚举。该工具首先测试是否有域传送漏洞,若存在则应该直接通过域传送搜集子域信息,没有域传送漏洞则采用爆破的方式。
使用方法:
CODE
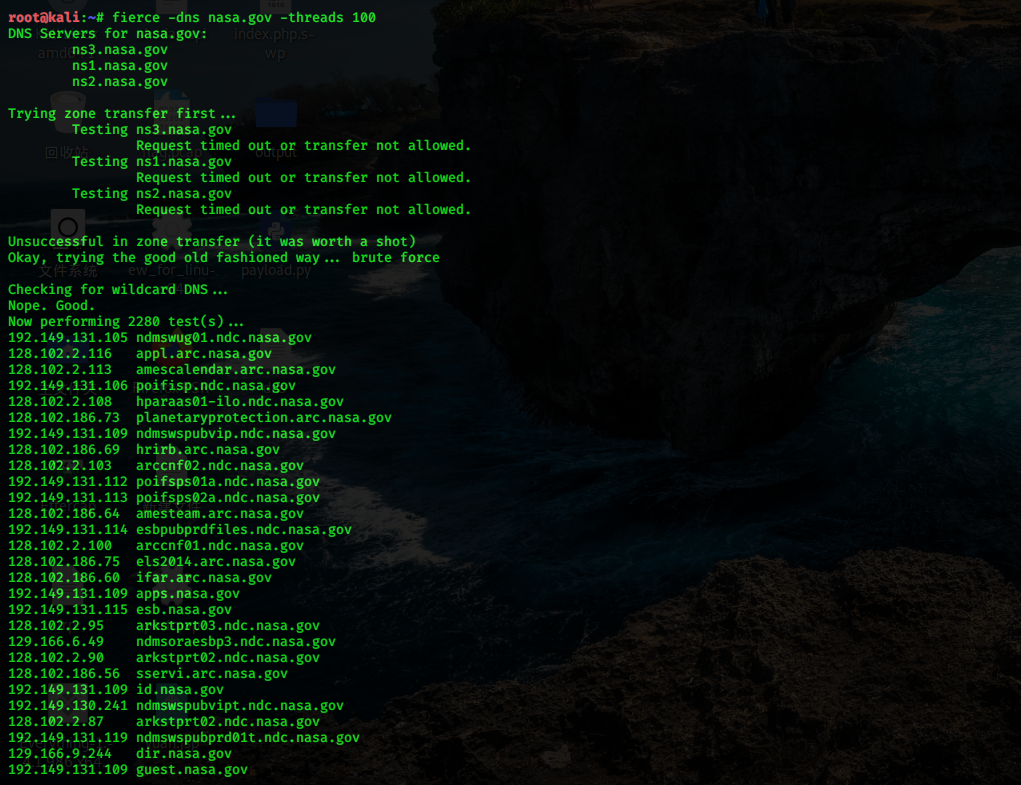
Windows 上的工具
Windows 上的子域名查询工具主要由:
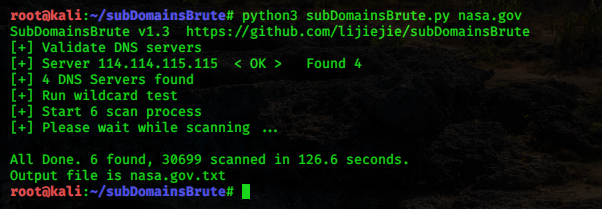
subDomainsbrute 工具可以用于二级域名收集,下载地址:https://github.com/lijiejie/subDomainsBrute
Python3 环境下运行需要安装 aiodns 库。使用该工具的命令执行如下:
CODE
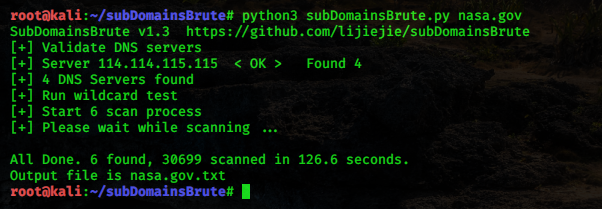
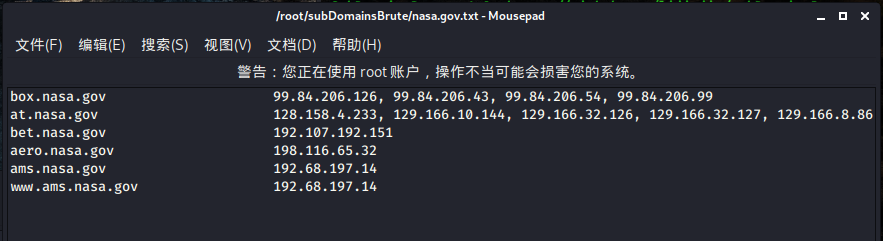
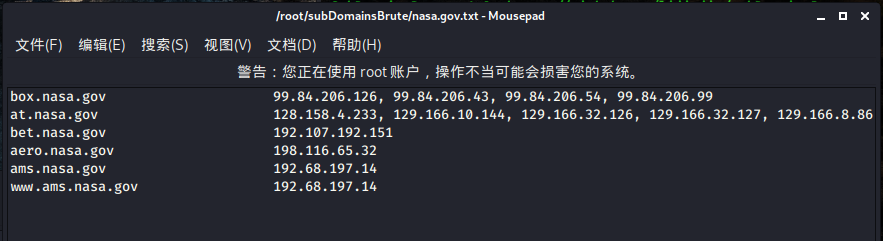
收集完后,会将收集结果写入一个域名对应的文件中:
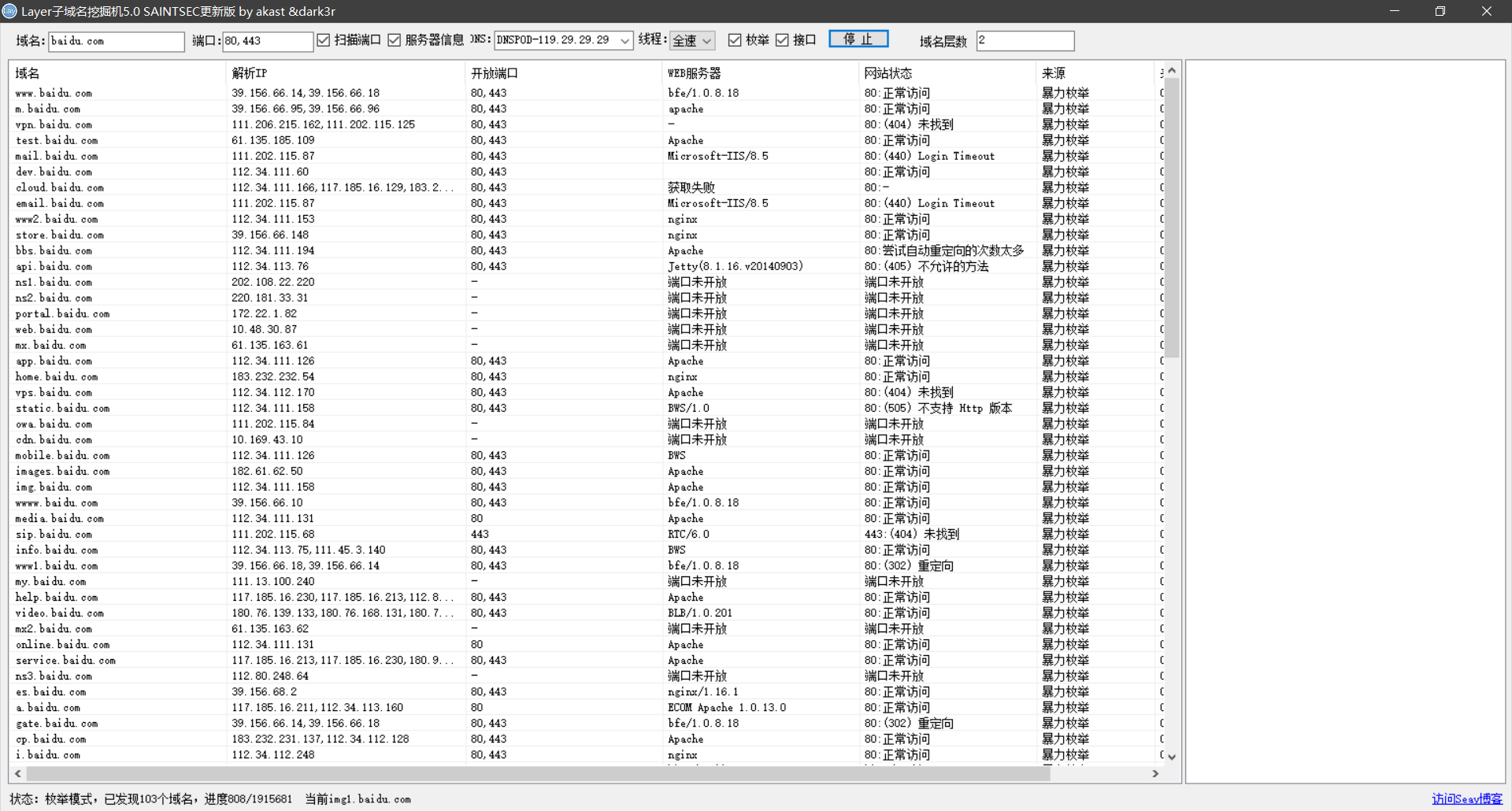
除了 subDomainsbrute 工具,Layer 子域名挖掘机也是十分强大的,用它收集子域名将详细的显示域名、解析 IP、CDN 列表、Web 服务器和网站状态等信息:
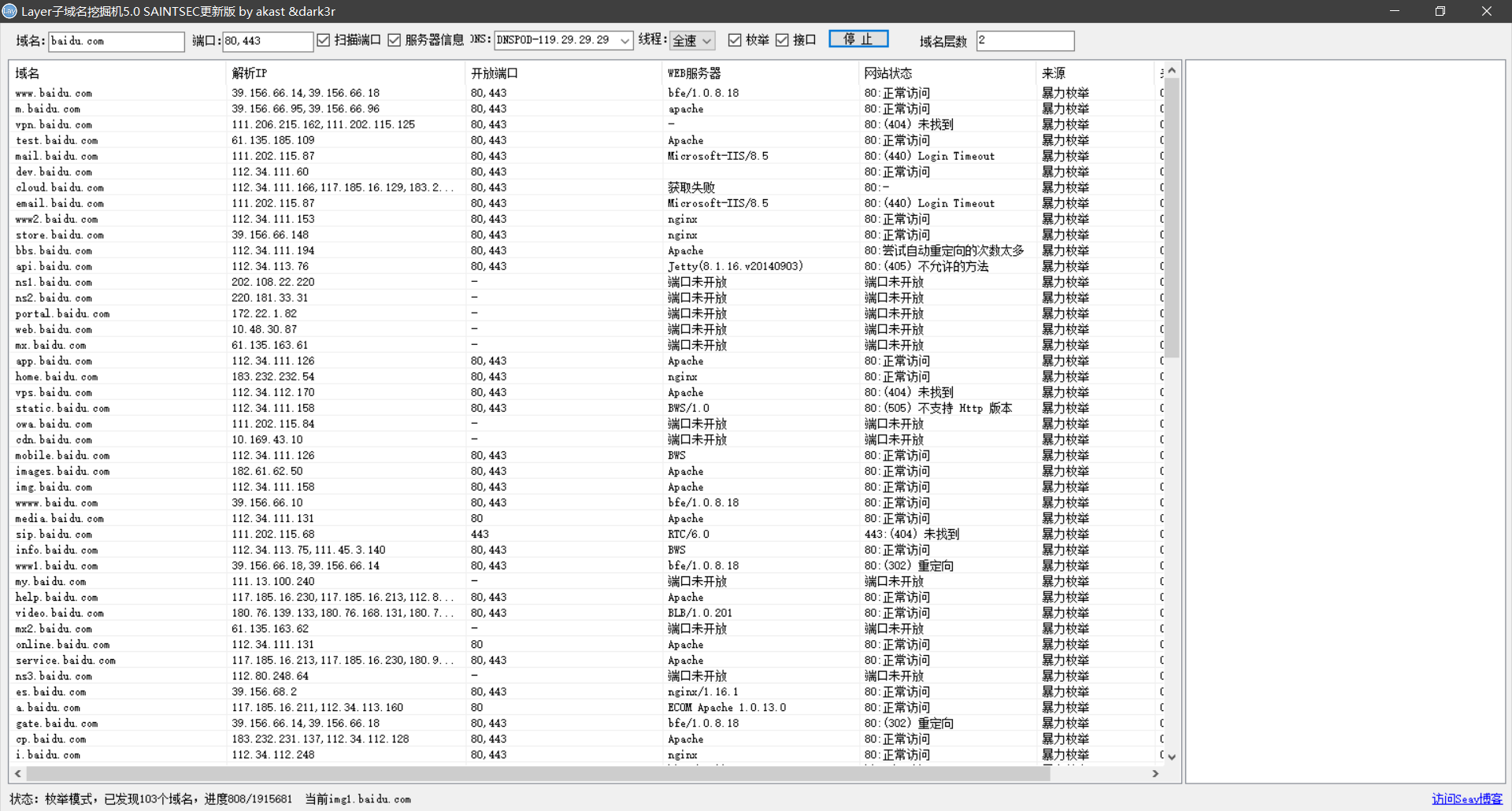
该工具请自行上网搜索下载。
站点信息收集
接下来我们进行 web 网站站点信息收集,主要收集如下信息:
CMS 指纹识别
历史漏洞
脚本语言
敏感目录/文件
Waf 识别
……
CMS 指纹识别
CMS(内容管理系统)又称为整站系统或文章系统,用于网站内容管理。用户只需要下载对应的 CMS 软件包,就能部署搭建,并直接利用 CMS。但是各种 CMS 都具有其独特的结构命名规则和特定的文件内容,因此可以利用这些内容来获取 CMS 站点的具体软件 CMS 与版本。
在渗透测试中,对进行指纹识别是相当有必要的,识别出相应的 CMS,才能查找与其相关的漏洞,然后才能进行相应的渗透操作。
常见的 CMS 有 Dedecms(织梦)、Discuz、PHPWEB、PHPWind、PHPCMS、ECShop、Dvbbs、SiteWeaver、ASPCMS、帝国、Z-Blog、WordPress 等。
(1)在线识别
如今,网上一些在线的网站查询 CMS 指纹识别,如下所示:
BugScaner: http://whatweb.bugscaner.com/look/
WhatWeb: https://whatweb.net/
如下,我们用 WhatWeb: https://whatweb.net/在线识别一下我的博客:
(2)利用工具
常见的 CMS 指纹识别工具有 WhatWeb、WebRobo、椰树、御剑 Web 指纹识别。大禹 CMS 识别程序等,可以快速识别一些主流 CMS。
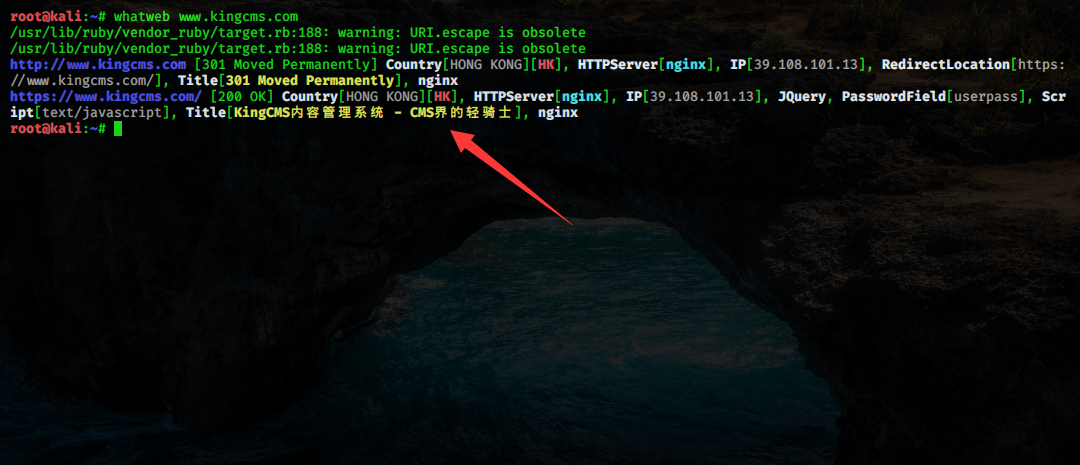
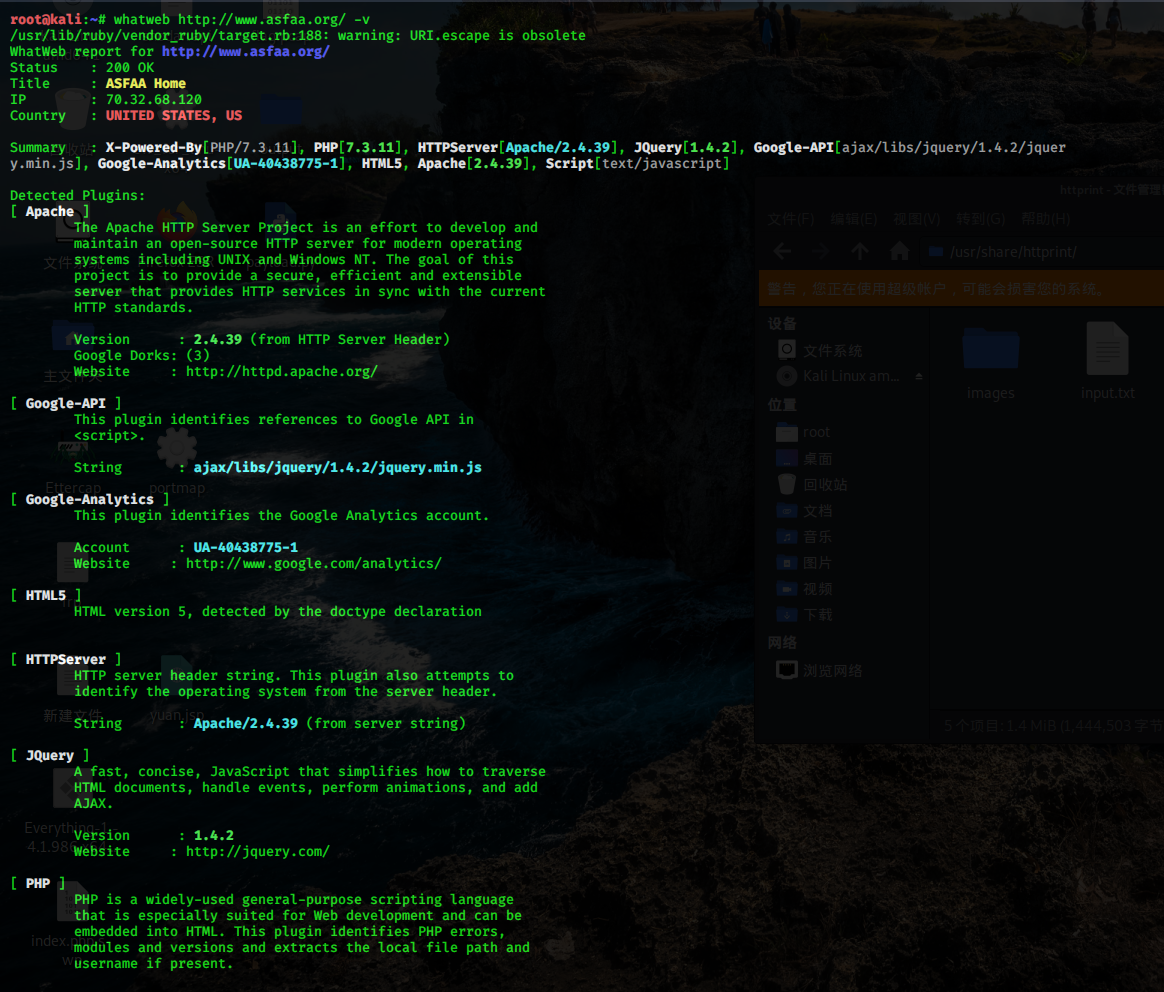
如下,我们利用 kali 上的 WhatWeb 工具识别目标站点的 cms:
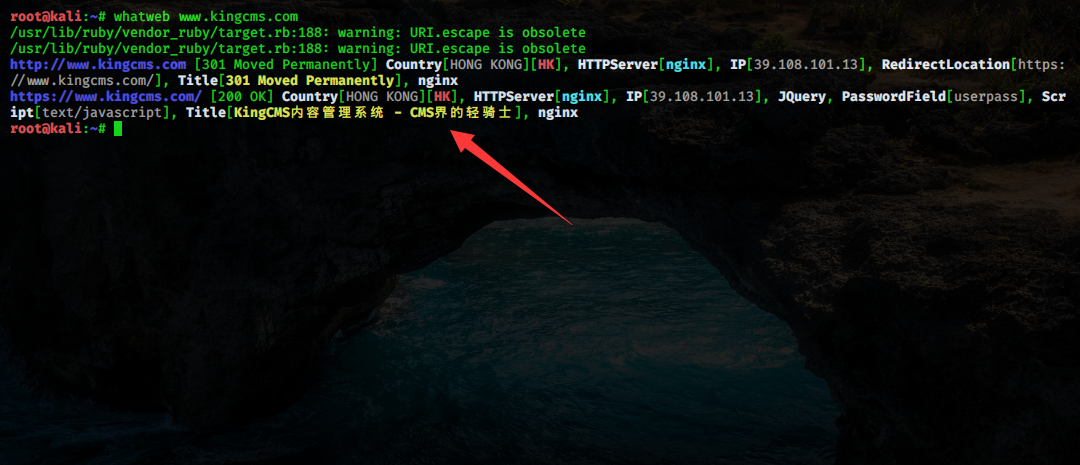
如上图,WhatWeb 将目标站点的服务器、中间节、cms 等都识别了出来。
当我们得知了一个站点的 cms 类型后,我们可以在网上查找与其相关的漏洞并进行相应的测试。
(3)手工识别
\1. 根据 HTTP 响应头判断,重点关注 X-Powered-By、cookie 等字段
\2. 根据 HTML 特征,重点关注 body、title、meta 等标签的内容和属性。
\3. 根据特殊的 class 判断。HTML 中存在特定 class 属性的某些 div 标签,如
……
敏感目录/文件收集
也就是对目标网站做个目录扫描。在 web 渗透中,探测 Web 目录结构和隐藏的敏感文件是一个十分重要的环节,从中可以获取网站的后台管理页面、文件上传界面、robots.txt,甚至可能扫描出备份文件从而得到网站的源代码。
常见的网站目录的扫描工具主要有:
御剑后台扫描工具
dirbuster 扫描工具
dirsearch 扫描工具
dirb
wwwscan
Spinder.py
Sensitivefilescan
Weakfilescan
……
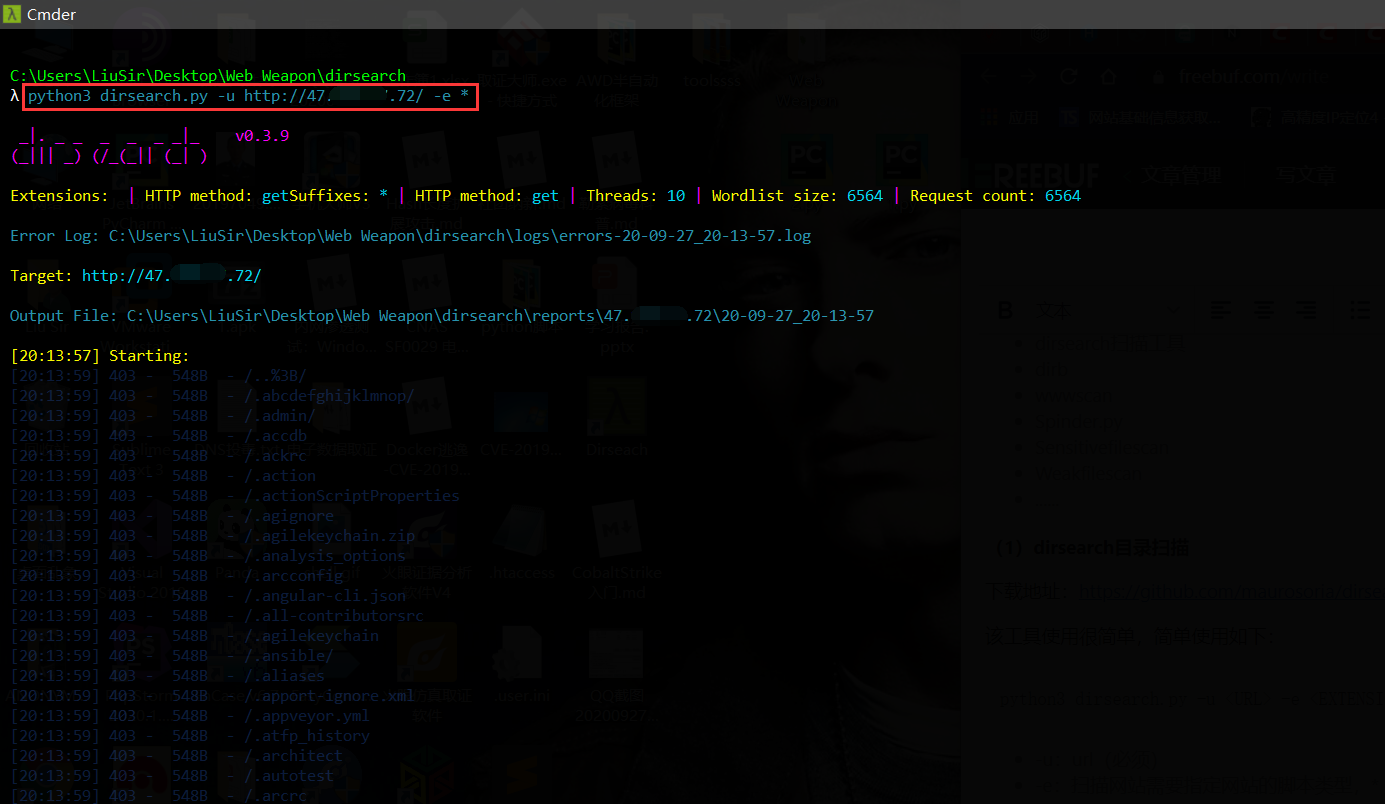
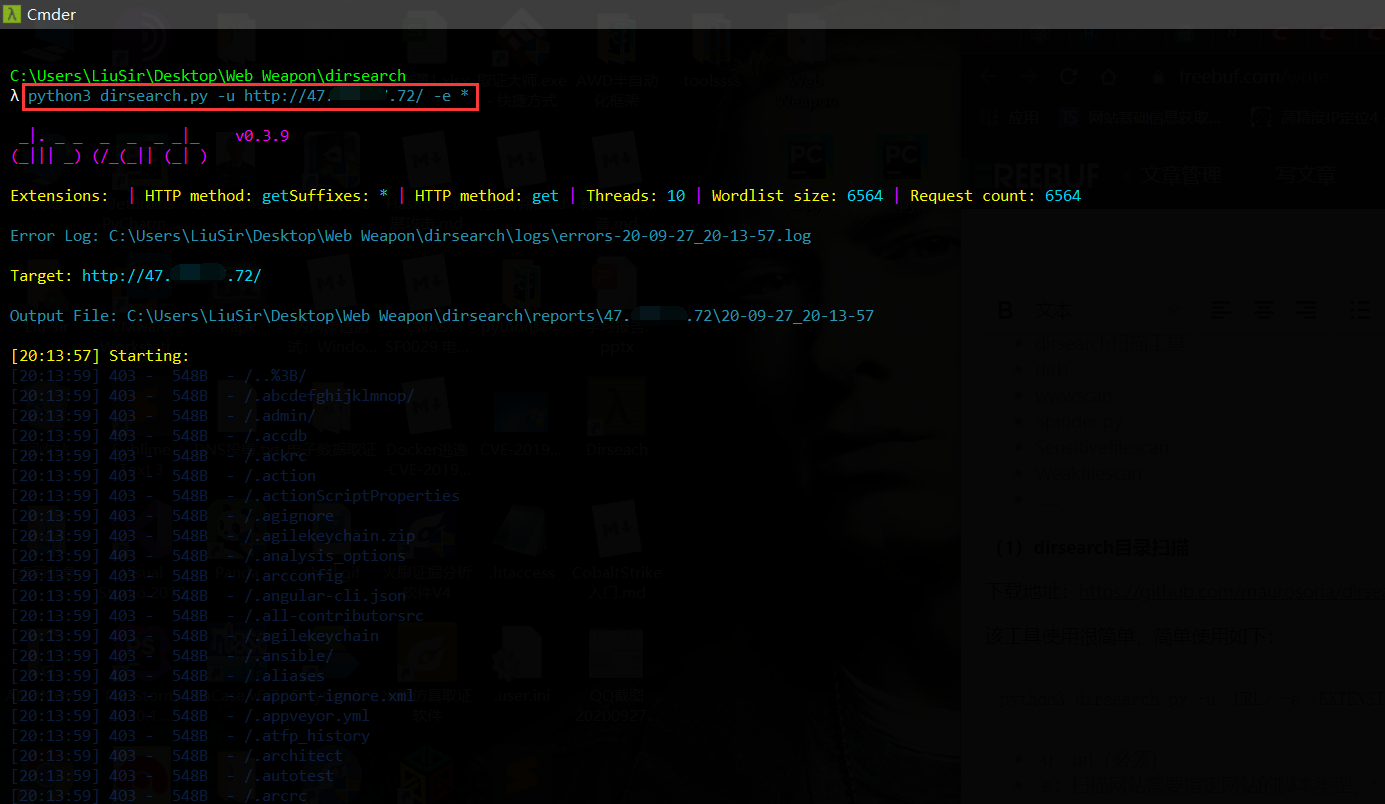
(1)dirsearch 目录扫描
下载地址:https://github.com/maurosoria/dirsearch
该工具使用很简单,简单使用如下:
CODE
-u:url(必须)
-e:扫描网站需要指定网站的脚本类型,* 为全部类型的脚本(必须)
-w:字典(可选)
-t:线程(可选)
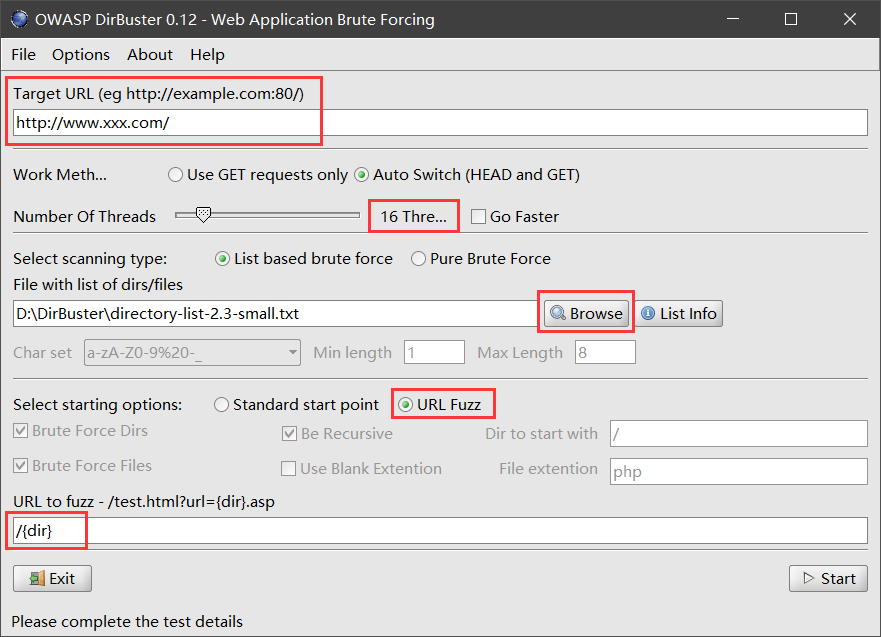
(2)DirBuster 目录扫描
DirBuster 是 Owasp(开放 Web 软体安全项目- Open Web Application Security Project )开发的一款专门用于探测 Web 服务器的目录和隐藏文件。(需要 java 环境)
使用如下:
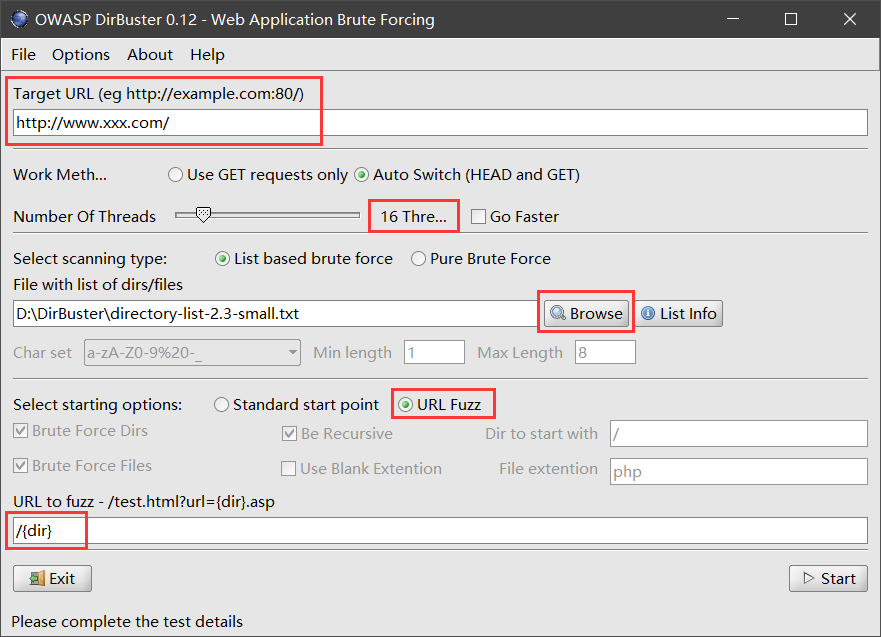
首先在 Target URL 输入框中输入要扫描的网址并将扫描过程中的请求方法设置为“Auto Switch(HEAD and GET)”。
自行设置线程(太大了容易造成系统死机哦)
选择扫描类型,如果使用个人字典扫描,则选择“List based bruteforce”选项。
单击“Browse”加载字典。
单机“URL Fuzz”,选择 URL 模糊测试(不选择该选项则使用标准模式)
在 URL to fuzz 里输入“/{dir}”。这里的{dir}是一个变量,用来代表字典中的每一行,运行时{dir}会被字典中的目录替换掉。
点击“start”开始扫描
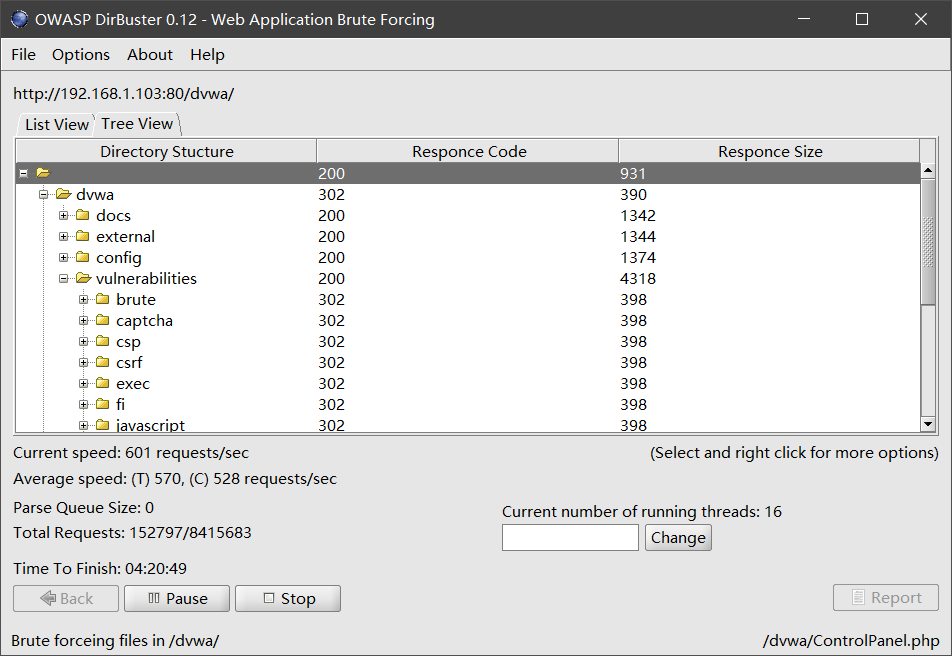
使用 DirBuster 扫描完成之后,查看扫描结果,这里的显示方式可以选择树状显示,也可以直接列出所有存在的页面:
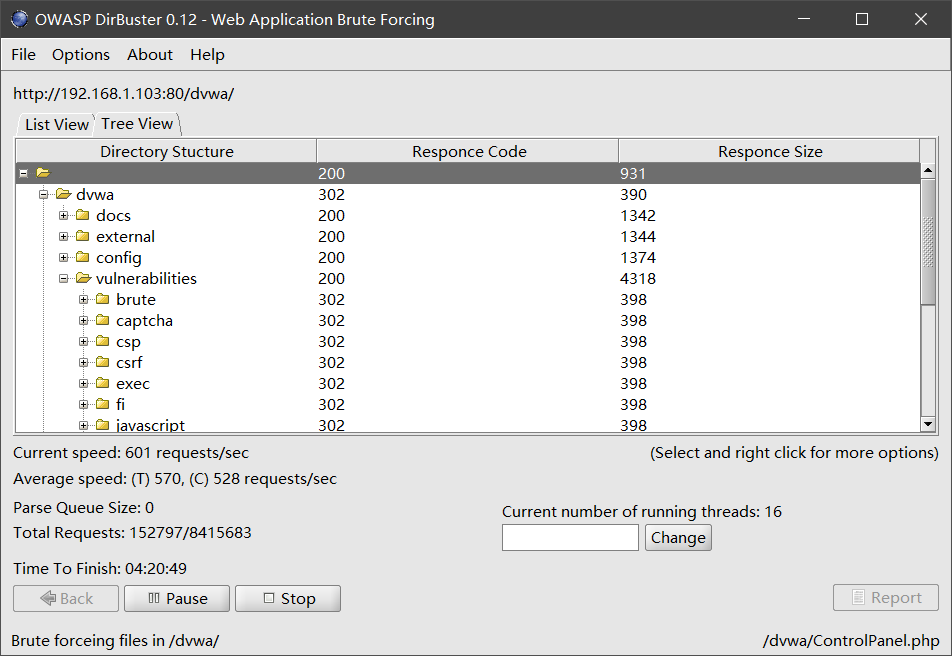
Waf 识别
Web 应用防护系统(也称为:网站应用级入侵防御系统。英文:Web Application Firewall,简称: WAF)。利用国际上公认的一种说法:Web 应用防火墙是通过执行一系列针对 HTTP/HTTPS 的安全策略来专门为 Web 应用提供保护的一款产品。
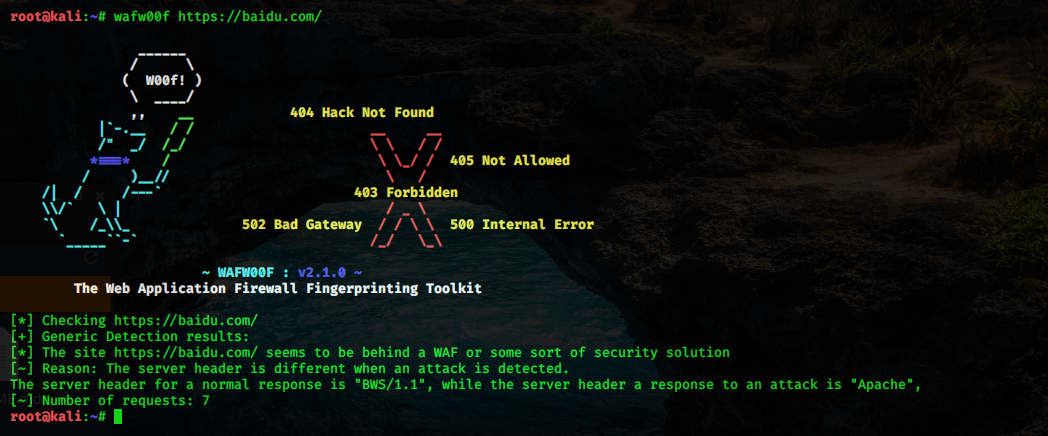
wafw00f 是一个 Web 应用防火墙(WAF)指纹识别的工具。
下载地址:https://github.com/EnableSecurity/wafw00f
wafw00f 的工作原理:
\1. 发送正常的 HTTP 请求,然后分析响应,这可以识别出很多 WAF。
\2. 如果不成功,它会发送一些(可能是恶意的)HTTP 请求,使用简单的逻辑推断是哪一个 WAF。
\3. 如果这也不成功,它会分析之前返回的响应,使用其它简单的算法猜测是否有某个 WAF 或者安全解决方案响应了我们的攻击。
kali 上内置了该工具:
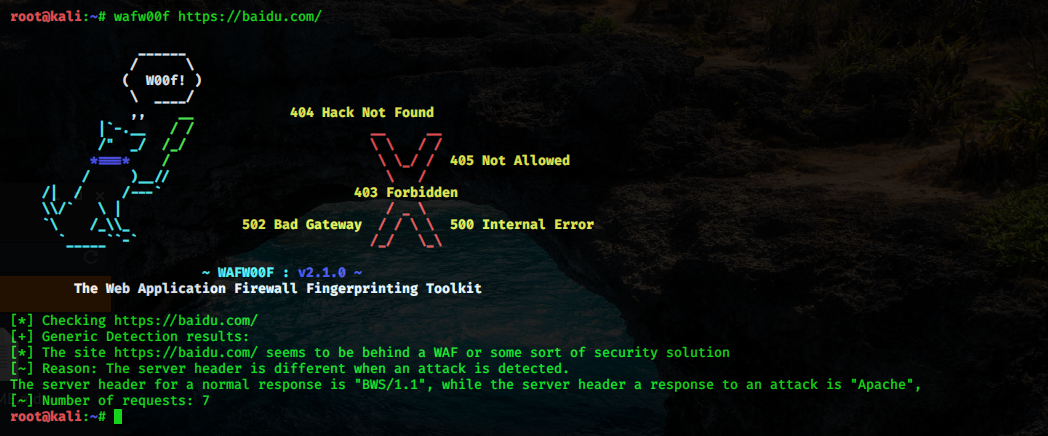
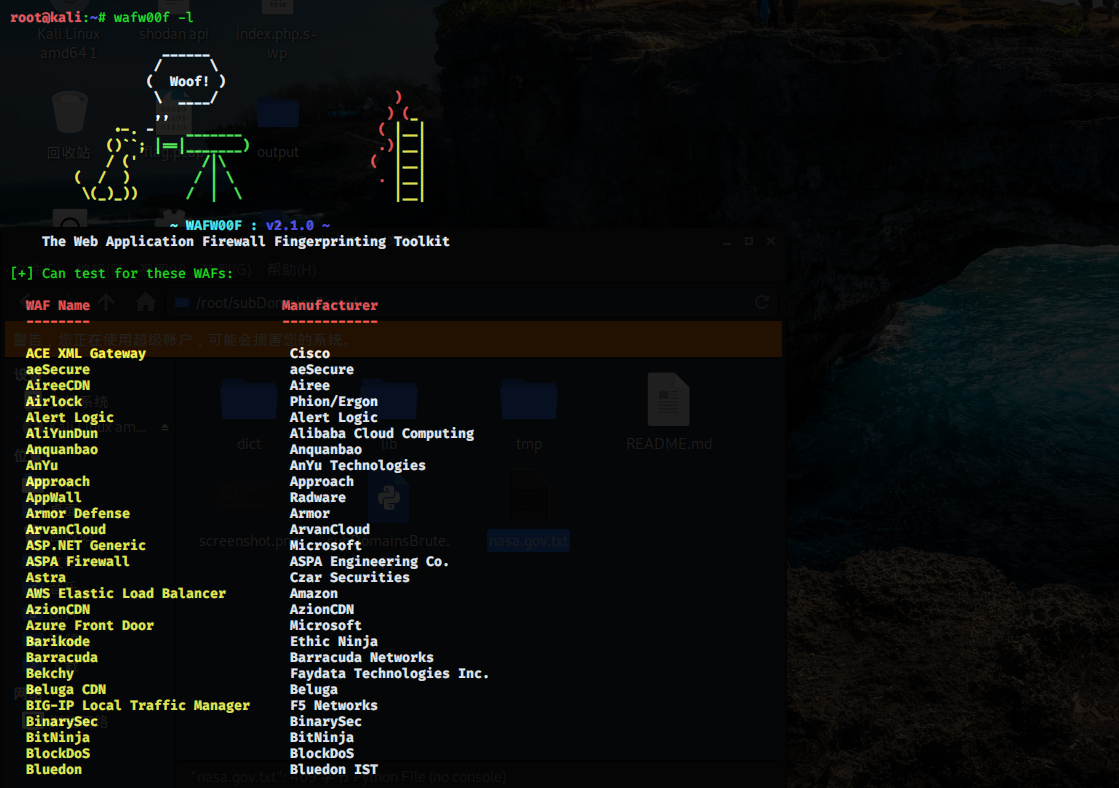
wafw00f 支持非常多的 WAF 识别。要查看它能够检测到哪些 WAF,请使用-l 选项:

……
简单使用如下:
CODE
敏感信息收集
有时候,针对某些安全做得很好的目标,直接通过技术层面是无法完成渗透测试的。此时,便可以利用搜索引擎搜索目标暴露在互联网上的关联信息。例如:数据库文件、SQL 注入、服务配置信息,甚至是通过 Git 找到站点泄露源代码,以及 Redis 等未授权访问、Robots.txt 等敏感信息,从而达到渗透目的。
Google hacking

Google 搜索引擎从 1998 年开始沿用至今,我们所有的问题,在 Google 上面几乎都能找到答案。Google 可以用来发现远远超过我们甚至应该能找到的信息,Google 可以找到敏感文件,网络漏洞,它允许操作系统和识别,甚至可以被用来找到密码,数据库乃至整个邮箱内容……
Google Hacking 正是是利用谷歌搜索的强大,来在浩瀚的互联网中搜索到超乎我们想象我的信息。轻量级的搜索可以搜索出一些遗留后门,不想被发现的后台入口、sql 注入等网络漏洞,中量级的搜索出一些用户信息泄露,源代码泄露,未授权访问等等,重量级的则可能是 mdb 文件下载,CMS 未被锁定 install 页面,网站配置密码,php 远程文件包含漏洞等重要信息。
利用 Google Hacking 我们能够收集很多对我们有用的情报,毫无疑问 Google 是一个伟大的信息收集工具。
要利用 Google 搜索我们想要的信息,需要配合谷歌搜索引擎的一些语法:
CODE
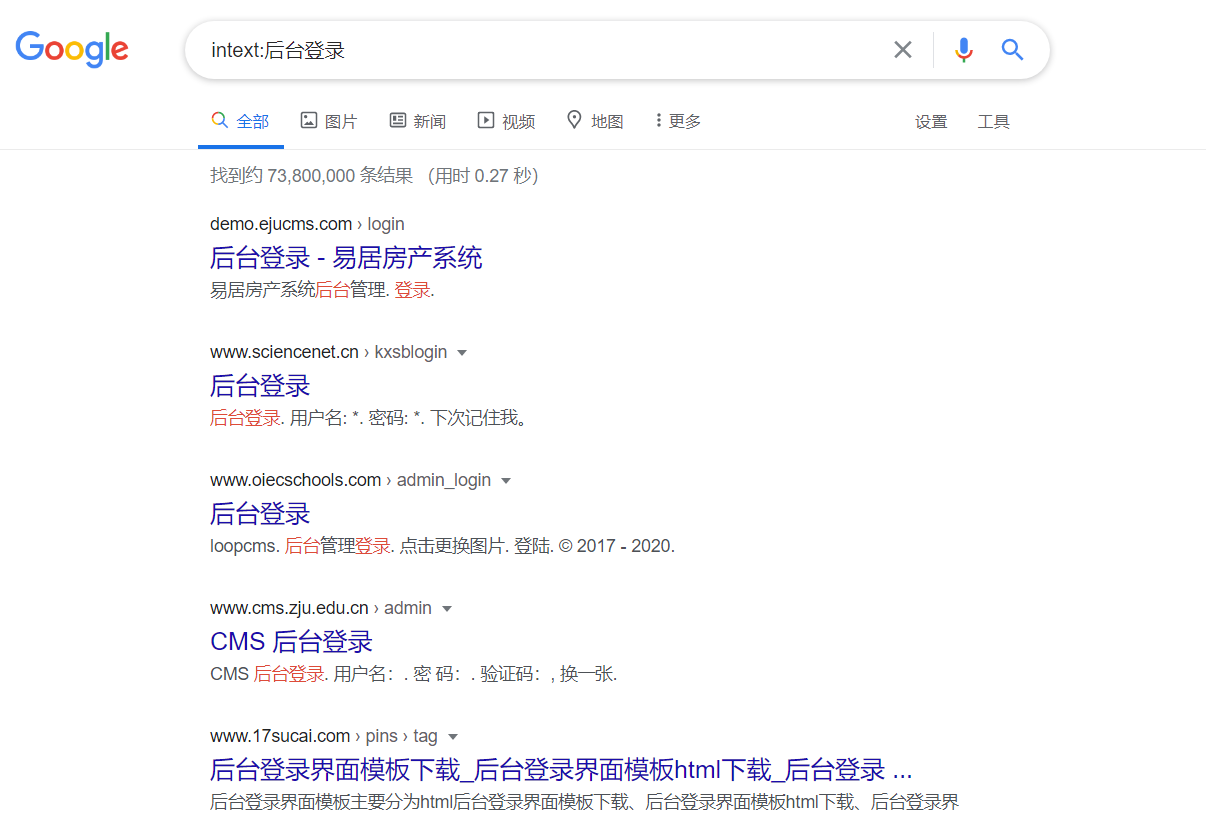
查找网站后台
intext:后台登录:将只返回正文中包含“后台登录”的网页
intitle:后台登录:将只返回标题中包含“后台登录”的网页
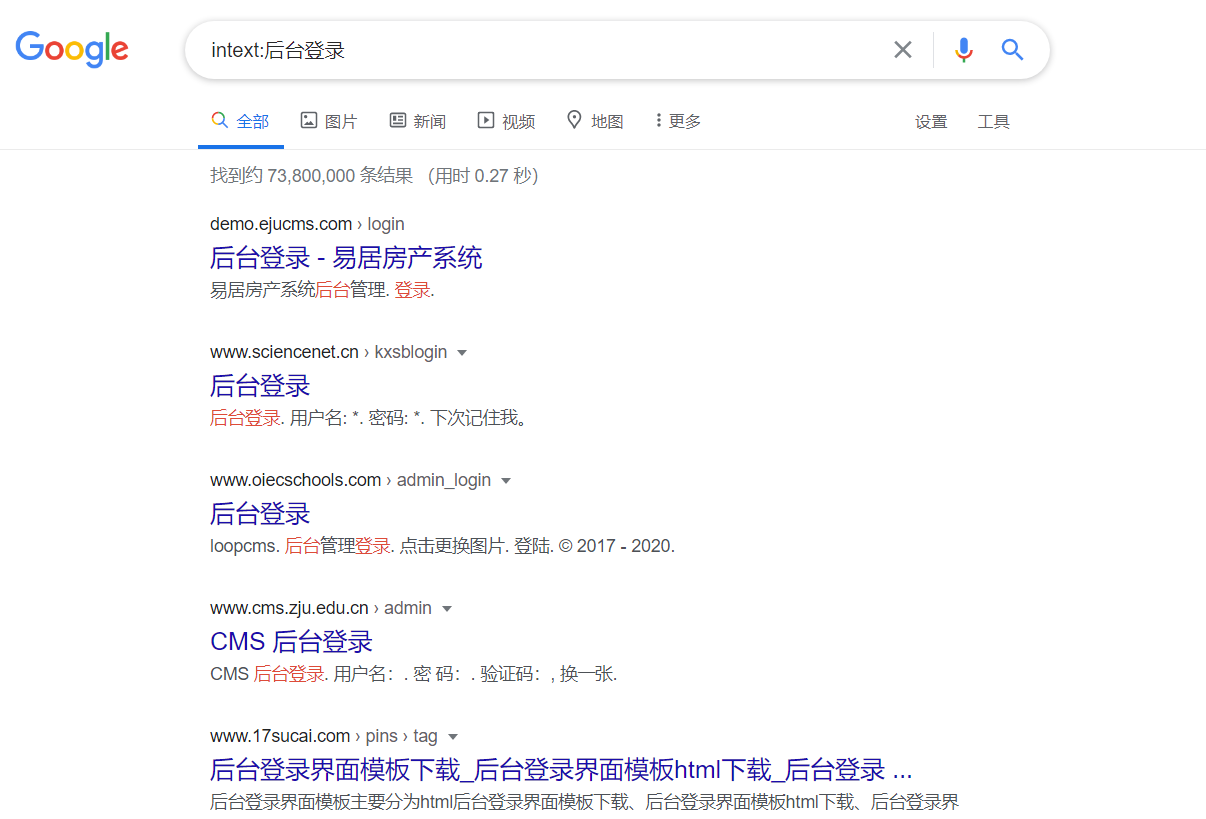
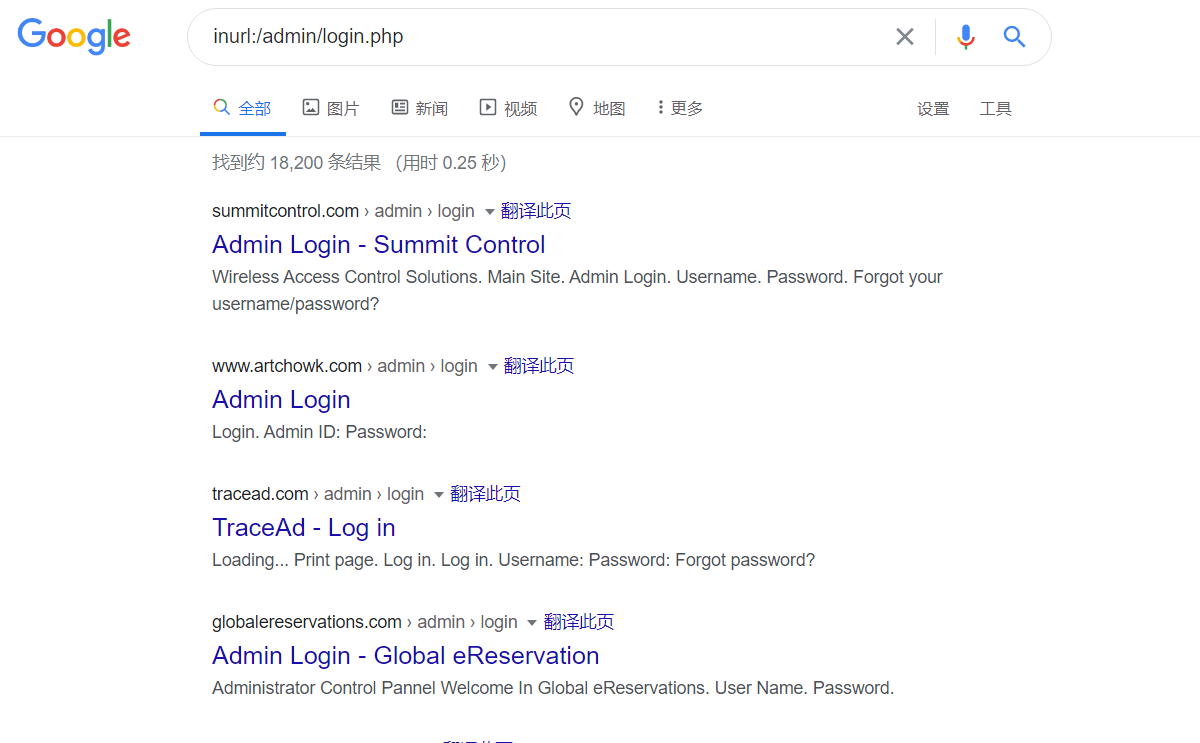
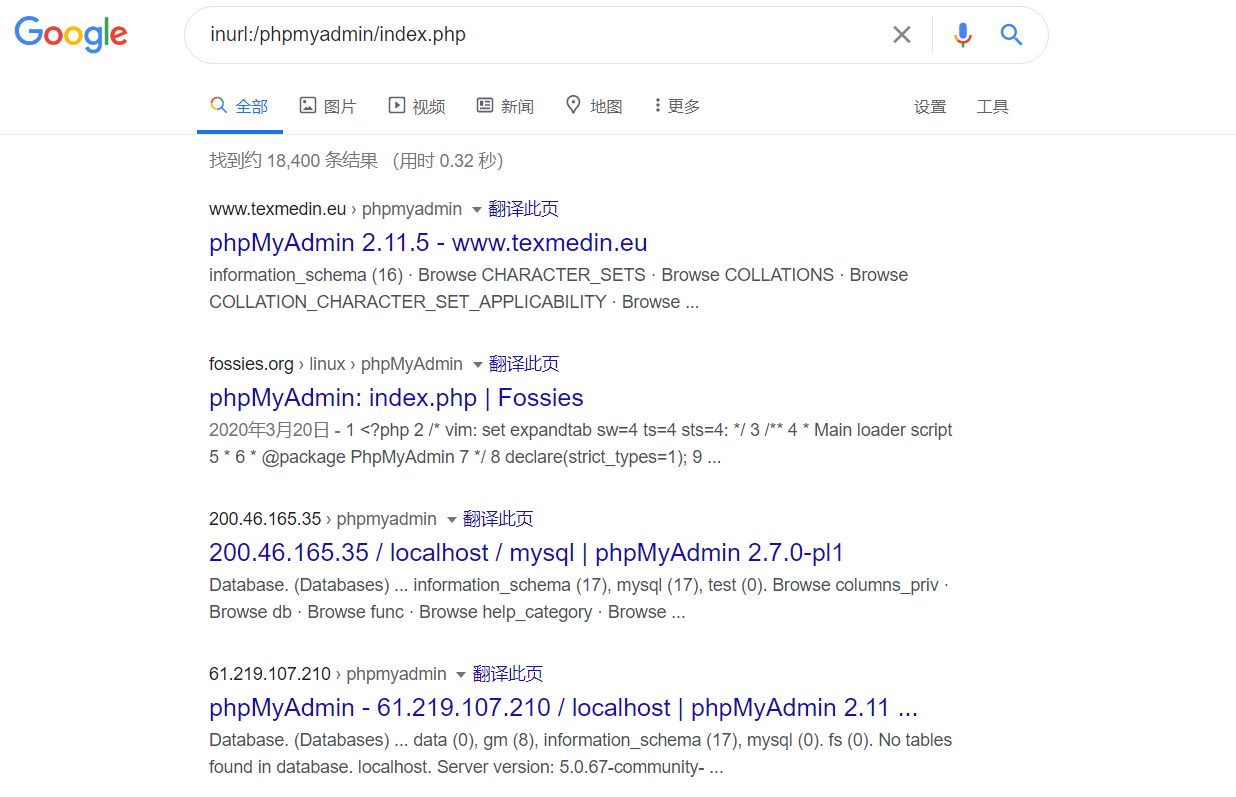
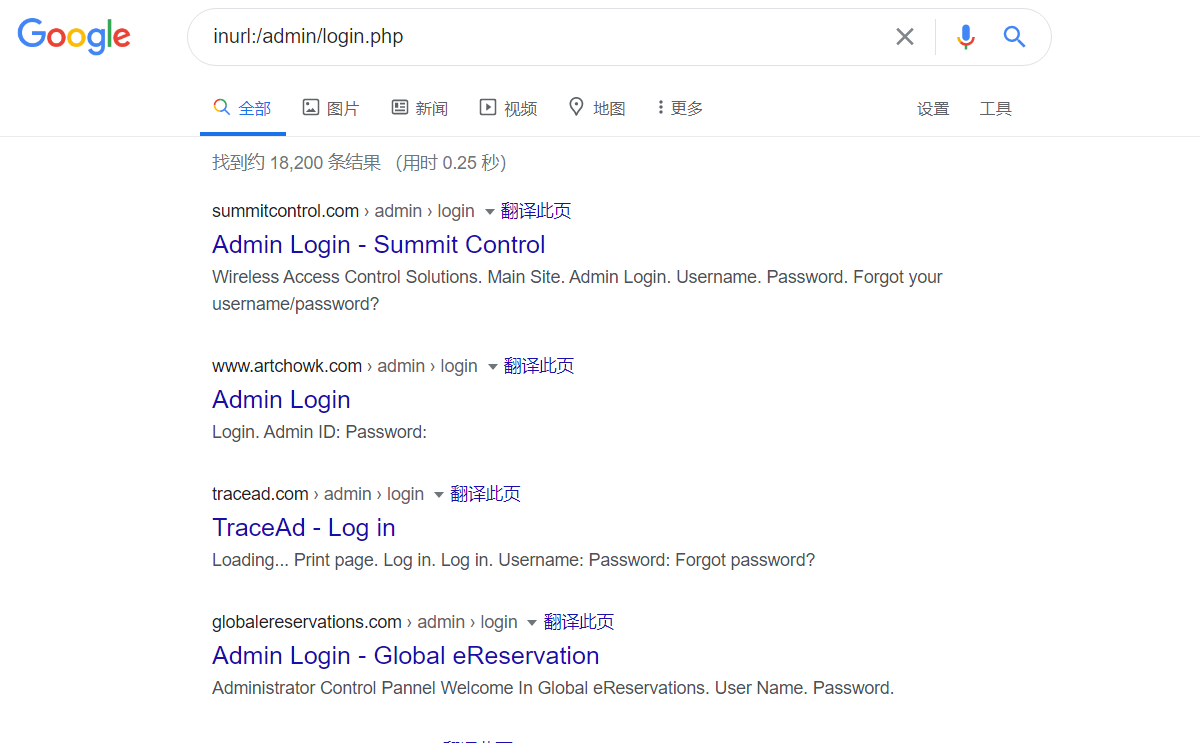
查找指定网站后台
site:xx.com intext:管理
site:xx.com inurl:login
site:xx.com intitle:后台
查看指定网站的文件上传漏洞
site:xx.com inurl:file
site:xx.com inurl:load
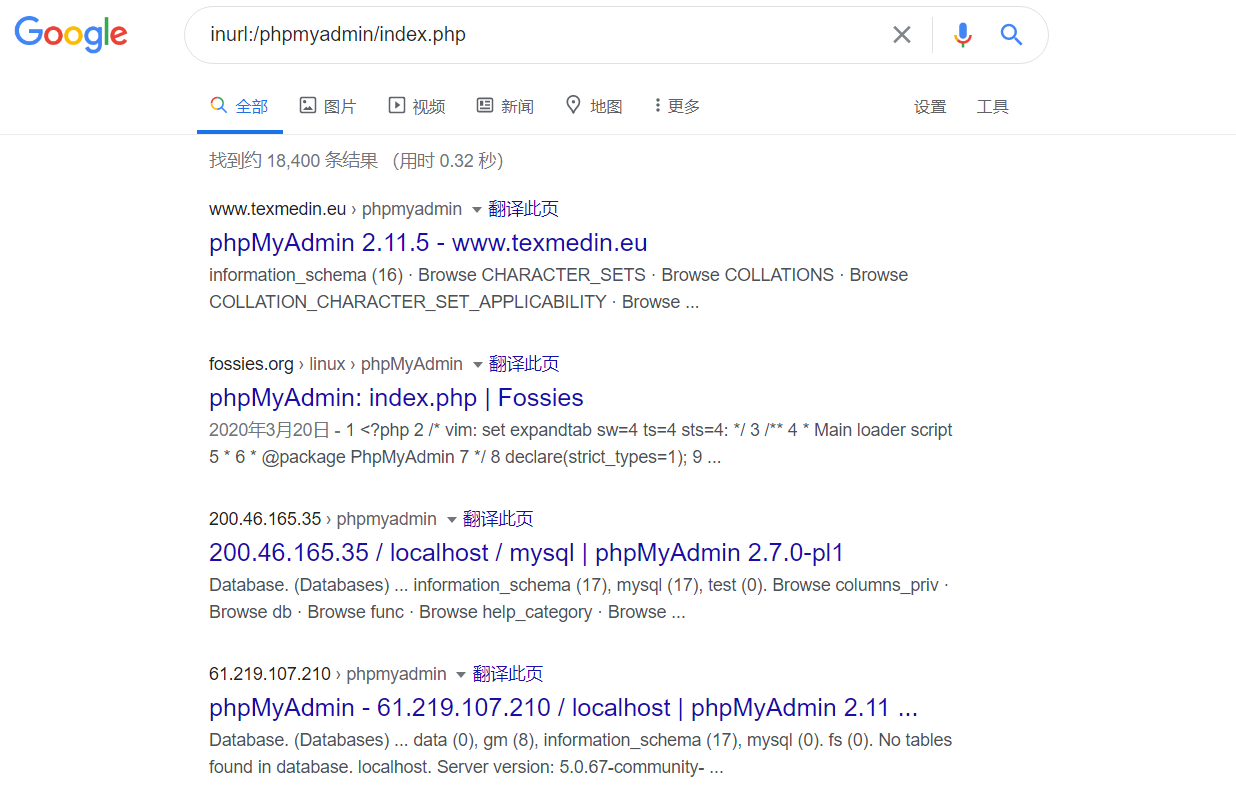
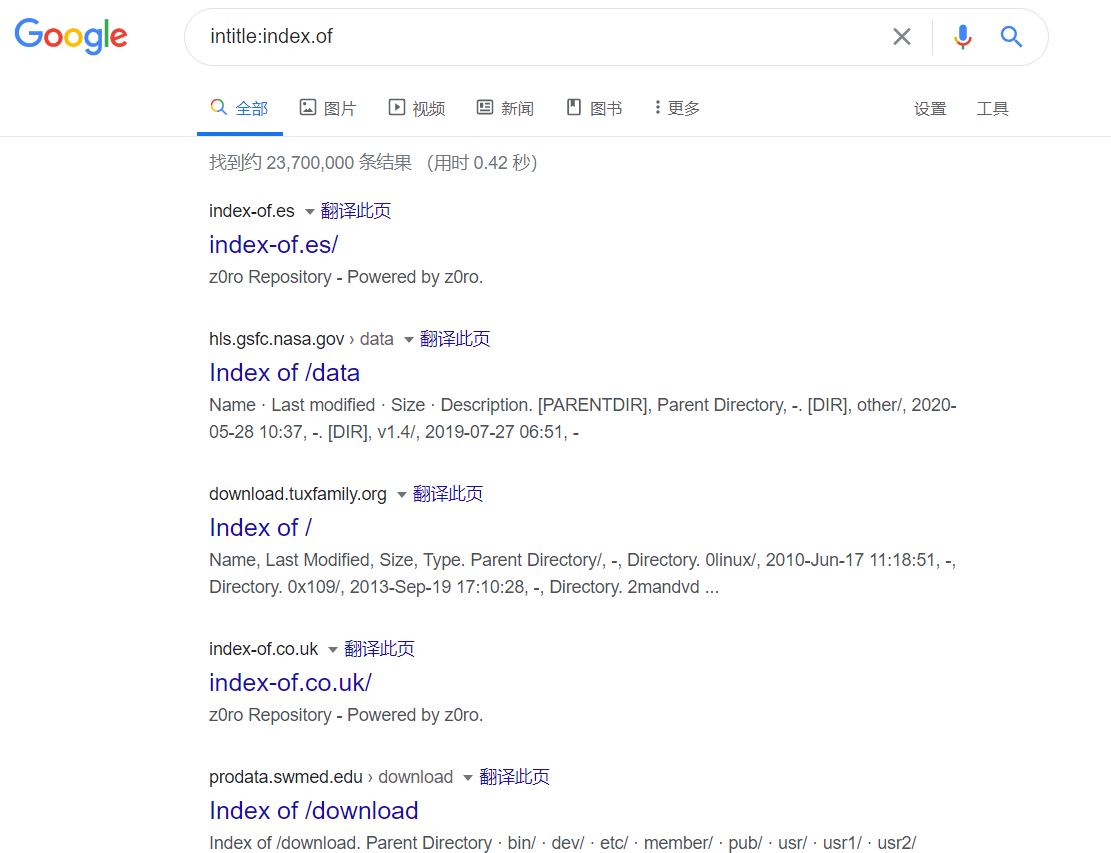
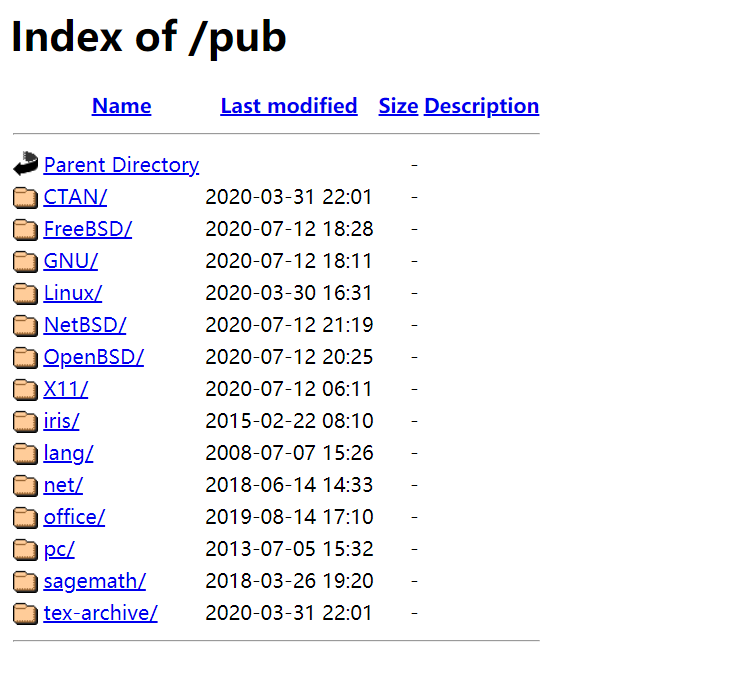
利用 Index of 可以发现允许目录浏览的 web 网站,就像在本地的普通目录一样
CODE
用 index of 目录列表列出存在于一个 web 服务器上的文件和目录。
intitle:index.of 这里的休止符代表的是单个字母的通配符
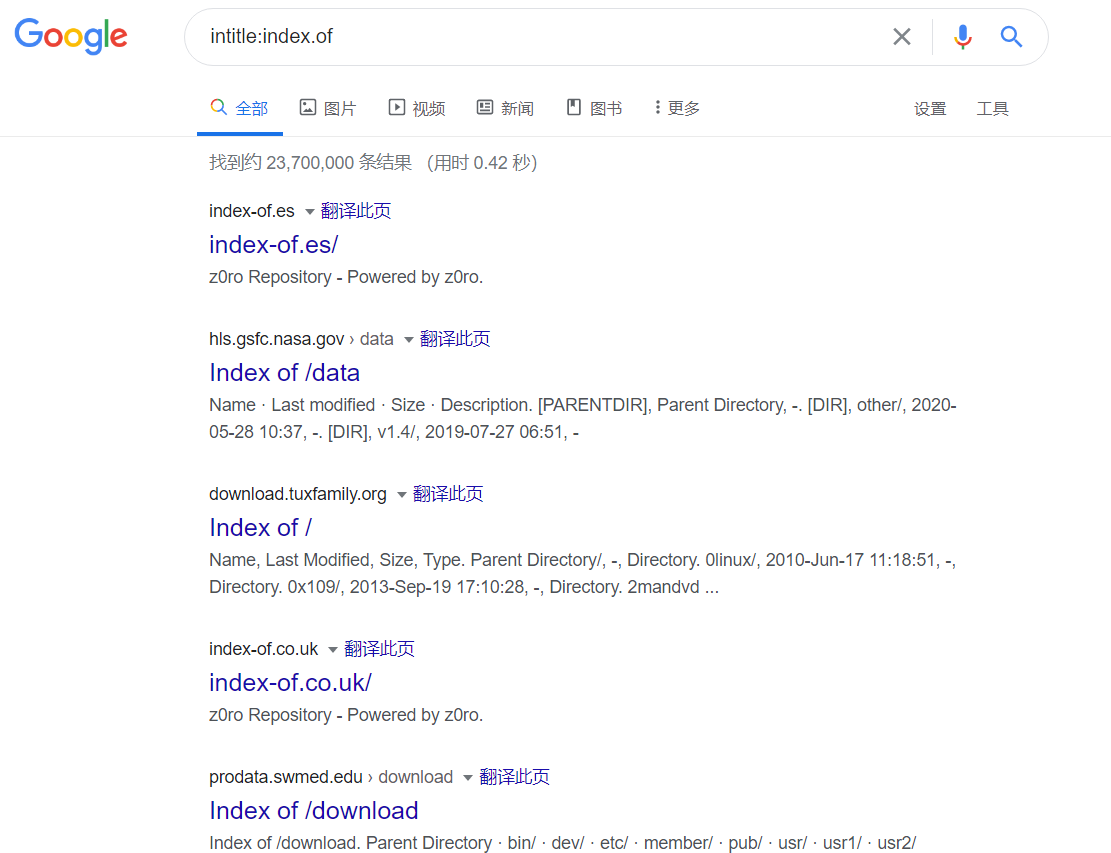
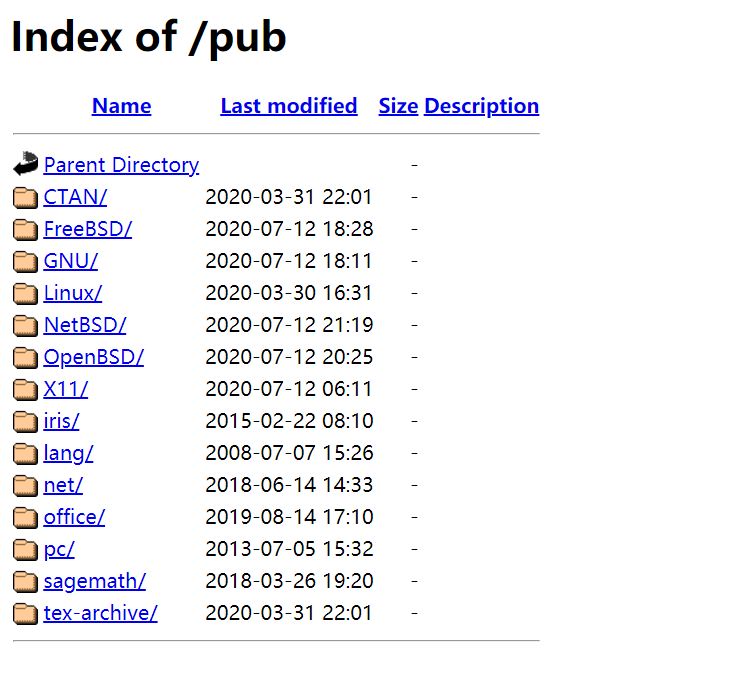
intitle:index.of index.php.bak
inurl:index.php.bak
intitle:index.of www.zip
查找 sql 注入
inurl:?id=1
inurl: php?id=
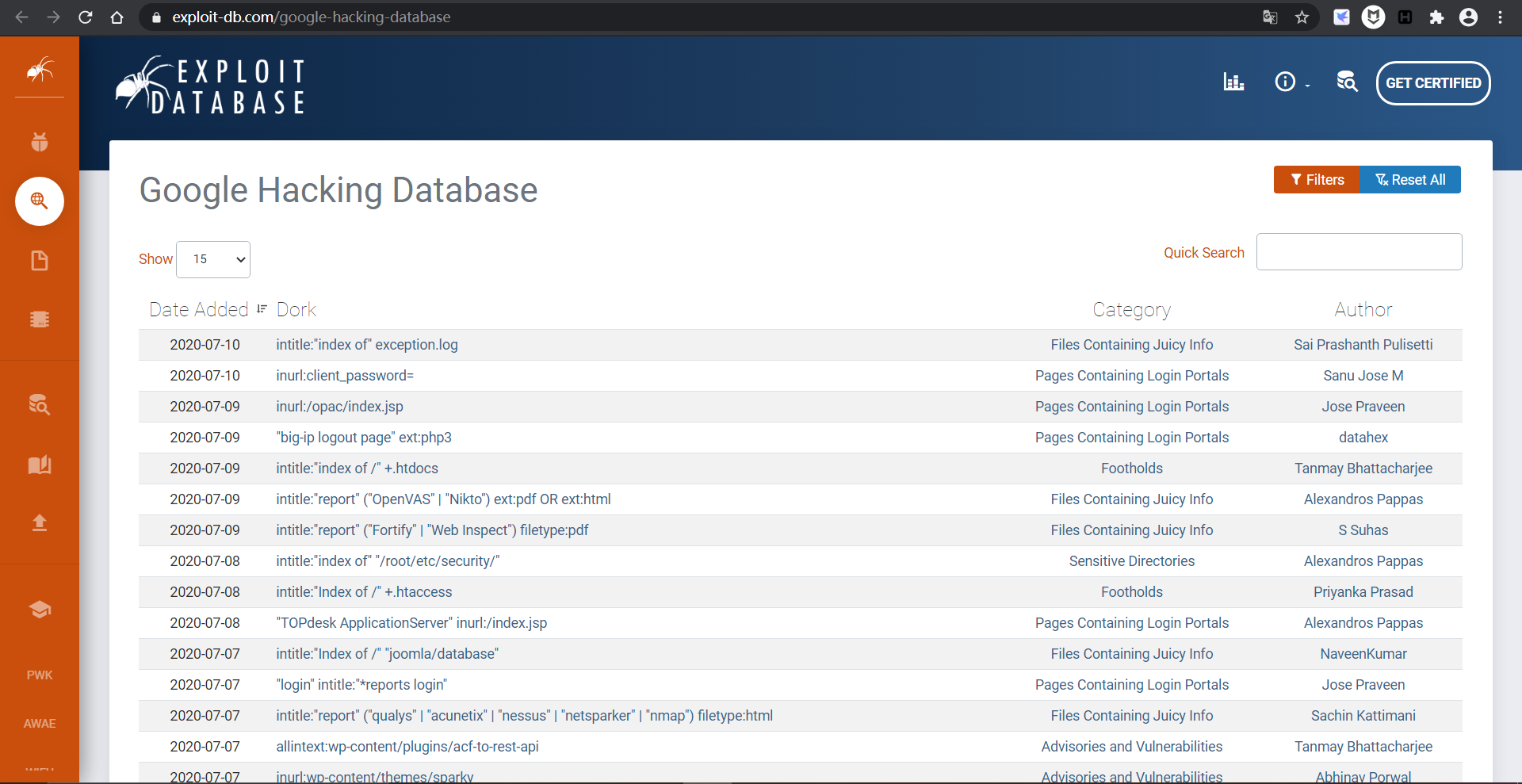
GHDB 谷歌黑客数据库
链接:https://www.exploit-db.com/google-hacking-database/
黑客们能通过简单的搜索框在网络中出入于无形,在这背后还有一个强大的后盾,那就是 Google Hacking Database(GHDB)
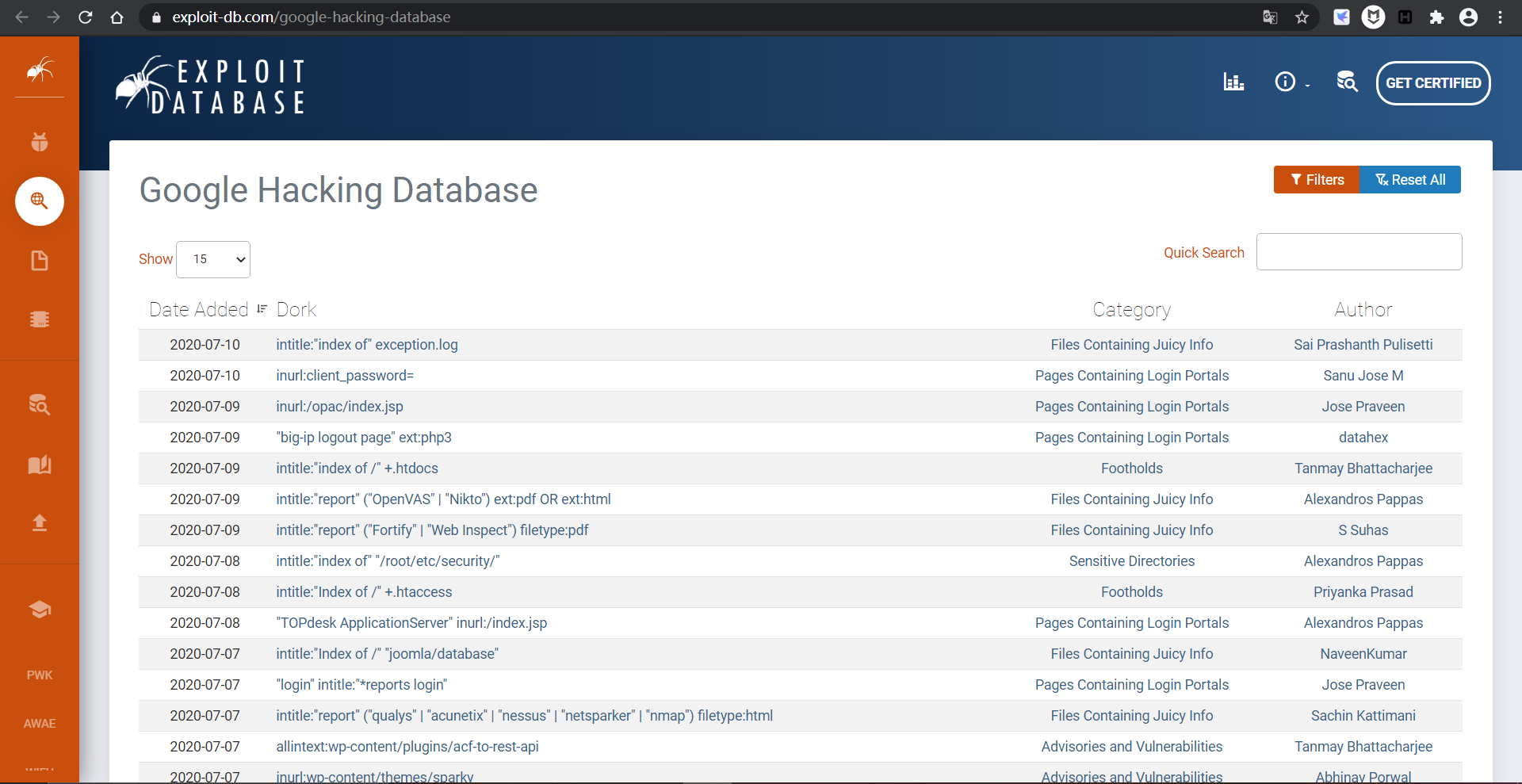
这是全世界的黑客朋友们自发维护的一个汇集着各种已经被优化的查询语句的数据库,每天都在不断地更新各种好用有效的 Google 查询语句。
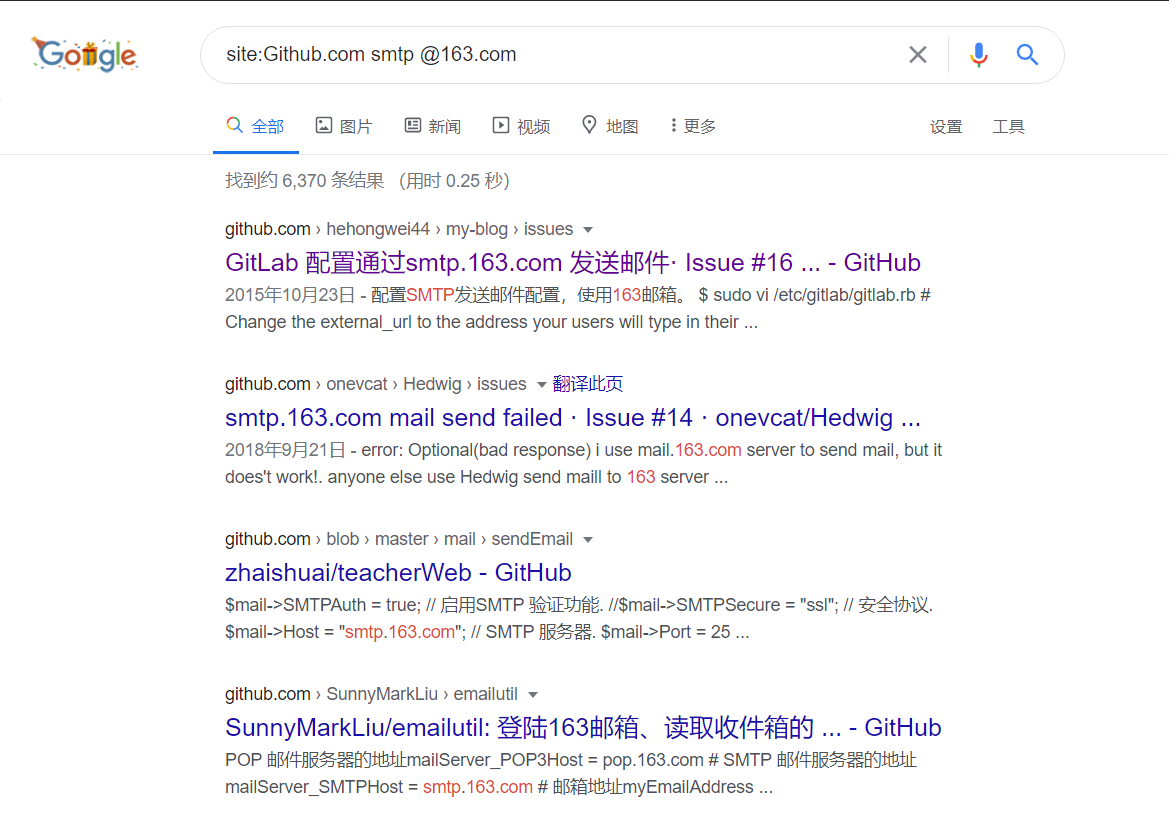
Github 信息泄露

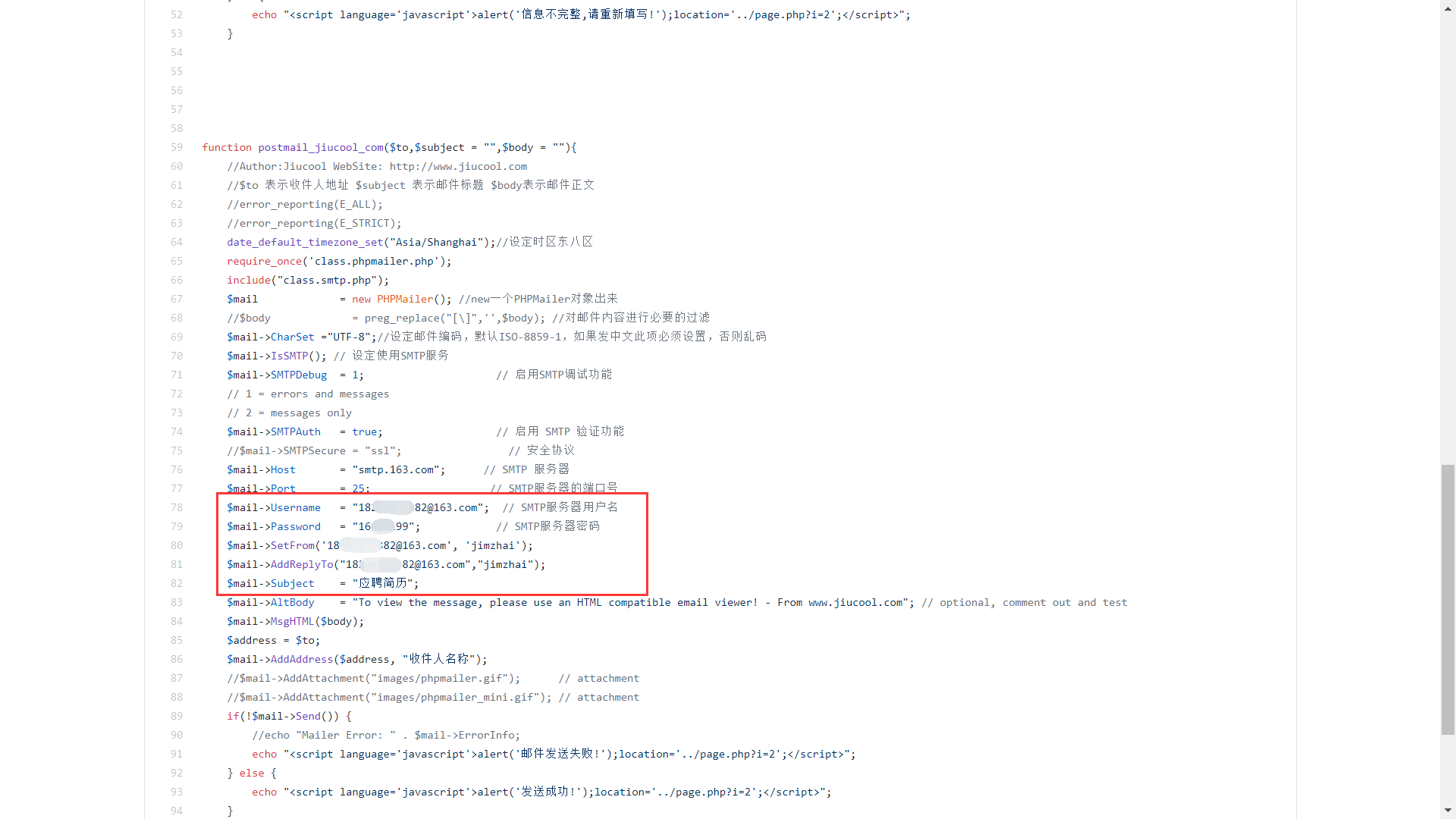
GitHub 作为开源代码平台,给程序员提供了很多便利,但如果使用不当,比如将包含了账号密码、密钥等配置文件的代码上传了,导致攻击者能发现并进一步利用这些泄露的信息,就是一个典型的 GitHub 敏感信息泄露漏洞,再如开发人员在开发时,常常会先把源码提交到 github,最后再从远程托管网站把源码 pull 到服务器的 web 目录下,如果忘记把.git 文件删除,就造成此漏洞。利用.git 文件恢复网站的源码,而源码里可能会有数据库的信息,详情参见:https://blog.csdn.net/qq_45521281/article/details/105767428
很多网站及系统都会使用 pop3 和 smtp 发送来邮件,不少开发者由于安全意识不足会把相关的配置文件信息也放到 Github 上,所以如果这时候我们动用一下 Google 搜索语法,就能把这些敏感信息给找出来了。
CODE
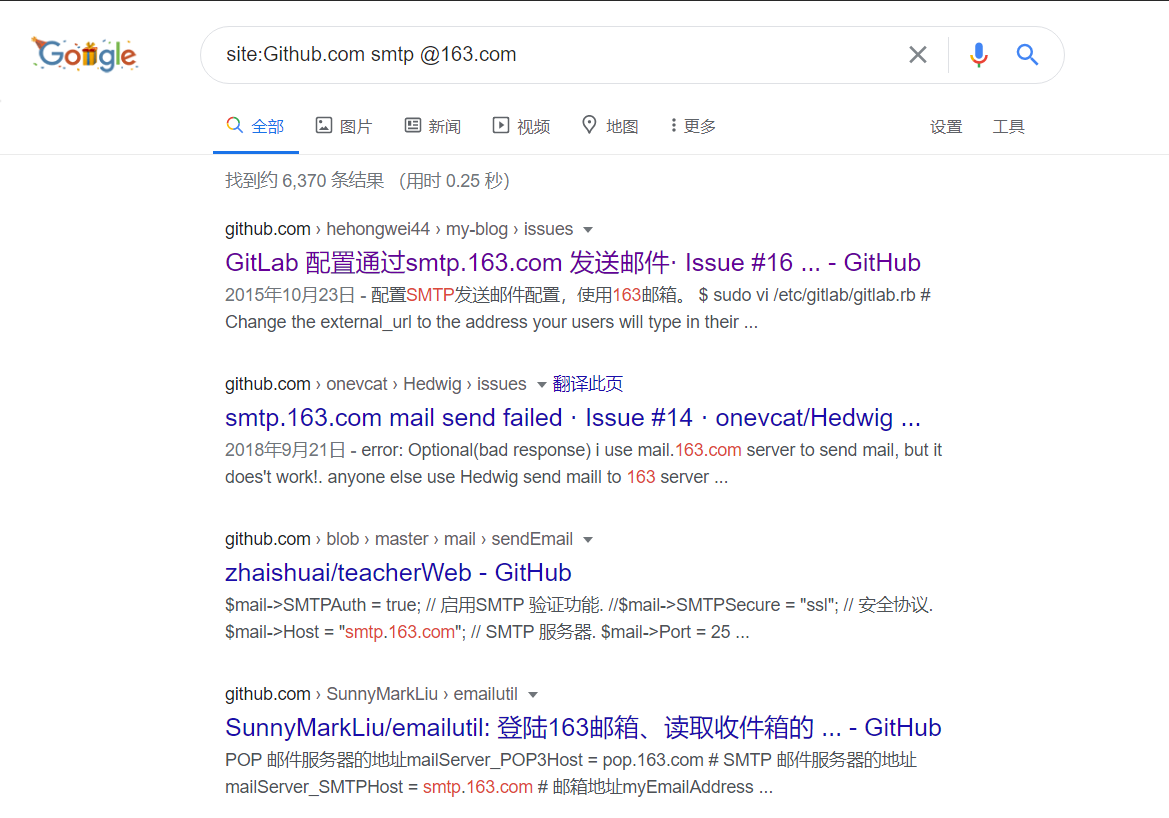
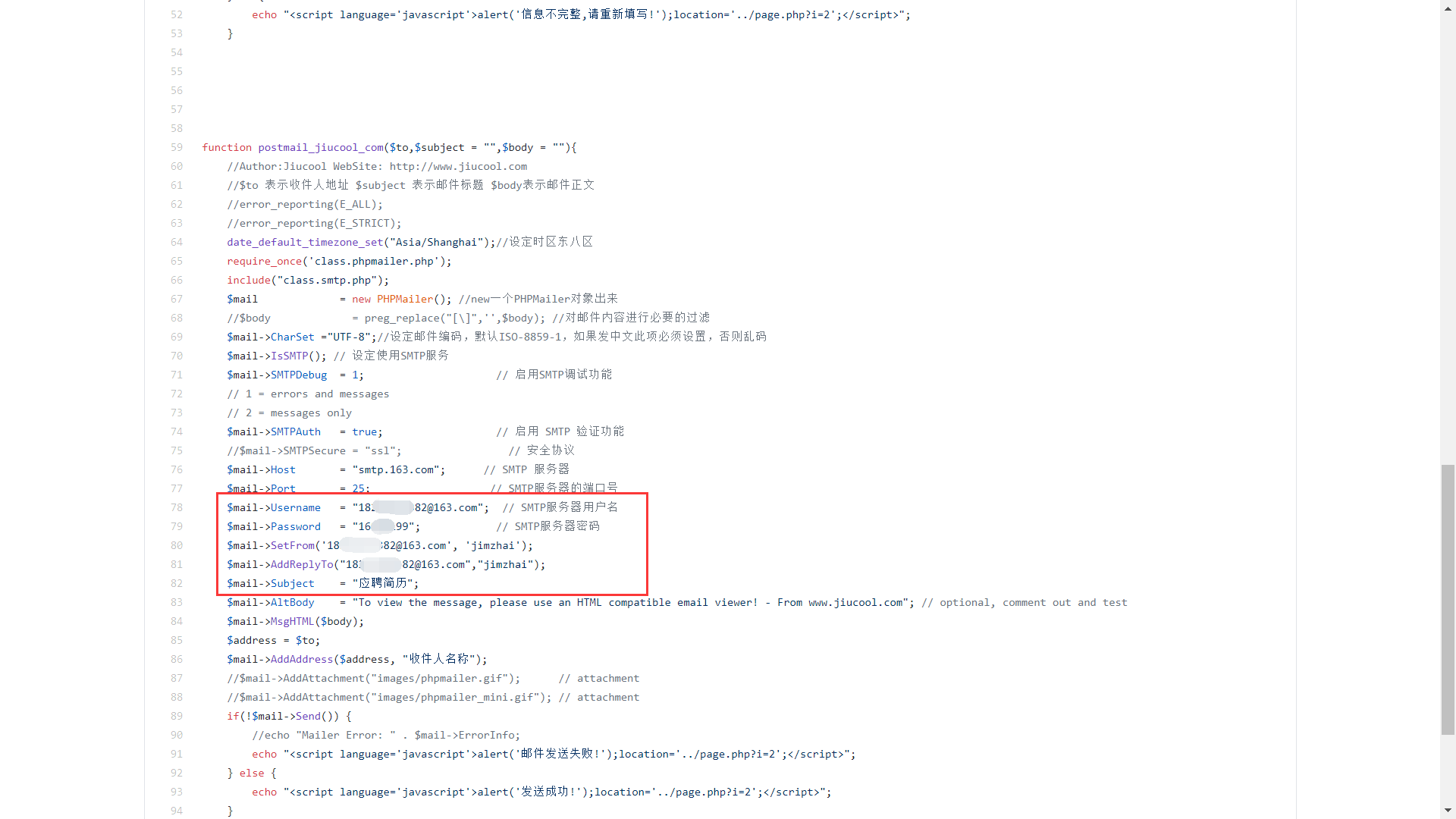
数据库信息泄露:
CODE
服务器信息收集
我们还需要对目标服务器的信息进行收集,主要包括一下部分:
Web 服务器指纹识别
真实 IP 地址识别
编程语言
Web 中间件
端口信息收集
后端存储技术识别
……
Web 服务器指纹识别
Web 服务器指纹识别是了解正在运行的 web 服务器类型和版本,目前市场上存在几种不同的 web 服务器提供商和软件版本,了解被测试的 web 服务器的类型,能让测试者更好去测试已知漏洞和大概的利用方法,将会在渗透测试过程中有很大的帮助,甚至会改变测试的路线。
Web 服务器指纹识别主要识别一下信息:
1、Web 服务器名称,版本
2、Web 服务器后端是否有应用服务器
3、数据库(DBMS)是否部署在同一主机(host),数据库类型
4、Web 应用使用的编程语言
5、Web 应用框架
……
(1)手工检测
1. HTTP 头分析
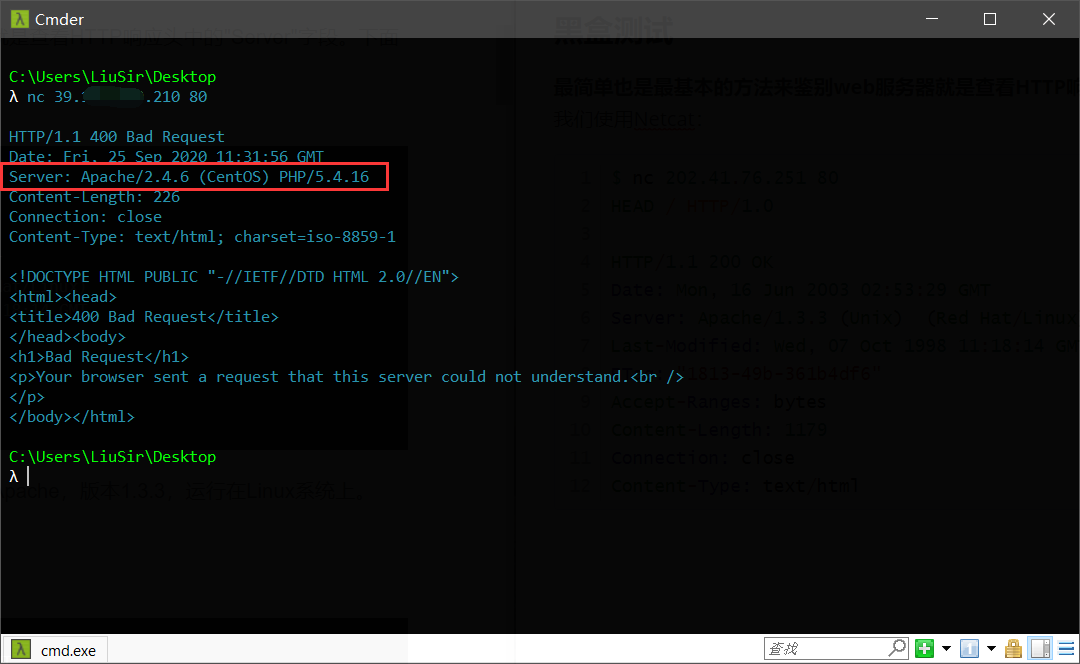
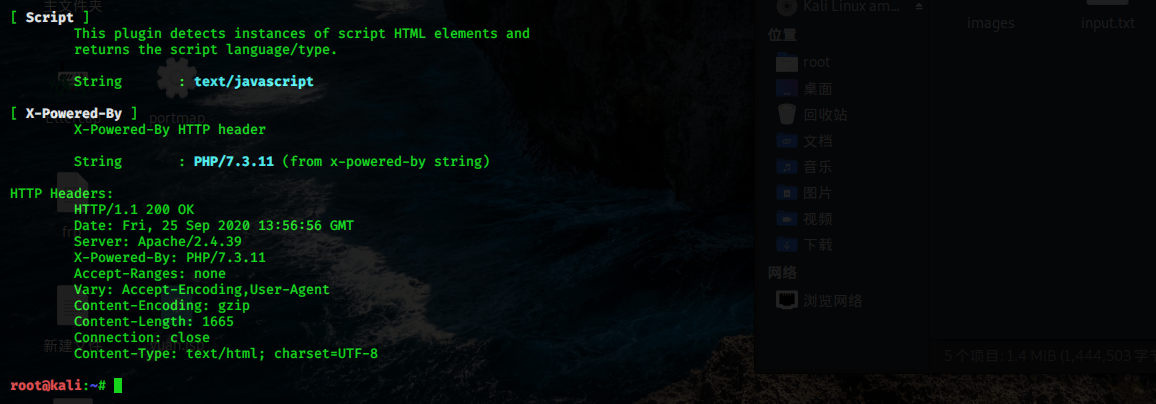
即查看 HTTP 响应头中的 Server、X-Powered-By、Cookie 等字段,这也是最基本的方法。
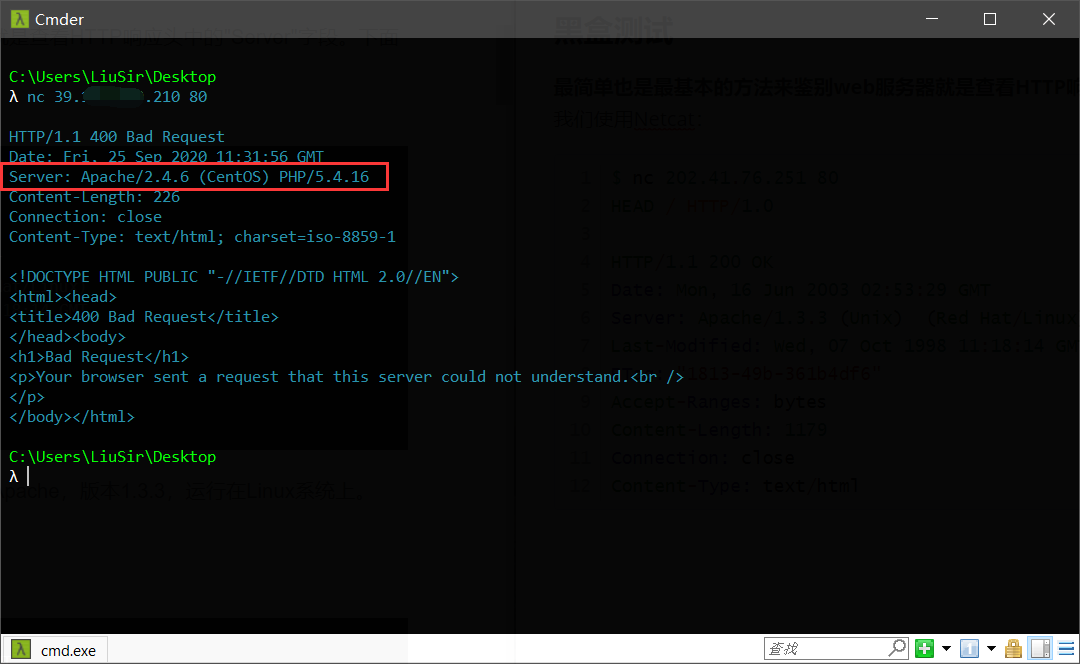
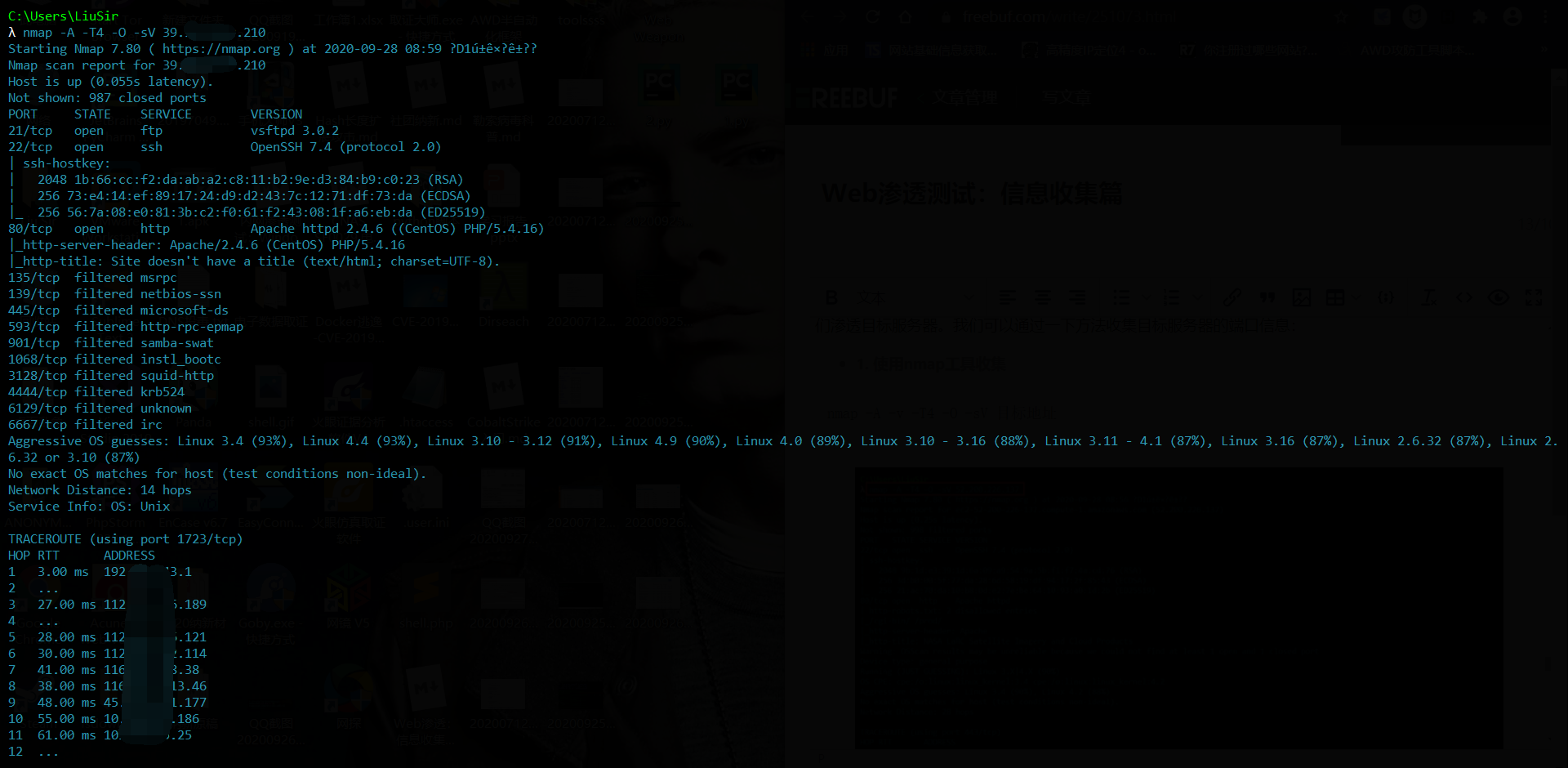
如上图,从 Server 字段,我们可以发现服务器可能是 Apache,版本 2.4.6,运行在 CentOS Linux 系统上。
根据 X-Powered-By 字段我们可以判断识别出 web 框架,并且不同的 web 框架有其特有的 cookie,根据这个我们也能判断识别出 web 应用框架。
2. 协议行为
即从 HTTP 头字段顺序分析,观察 HTTP 响应头的组织顺序,因为每个服务器都有一个内部的 HTTP 头排序方法。
3. 浏览并观察网站
我们可以观察网站某些位置的 HTML 源码(特殊的 class 名称)及其注释(comment)部分,可能暴露有价值信息。观察网站页面后缀可以判断 Web 应用使用的编程语言和框架。
4. 刻意构造错误
错误页面可以给你提供关于服务器的大量信息。可以通过构造含有随机字符串的 URL,并访问它来尝试得到 404 页面。
(2)利用工具识别
whatweb 是一款用于辅助的自动化 Web 应用指纹分析工具
CODE

指定要扫描的文件
CODE
详细回显扫描:
CODE
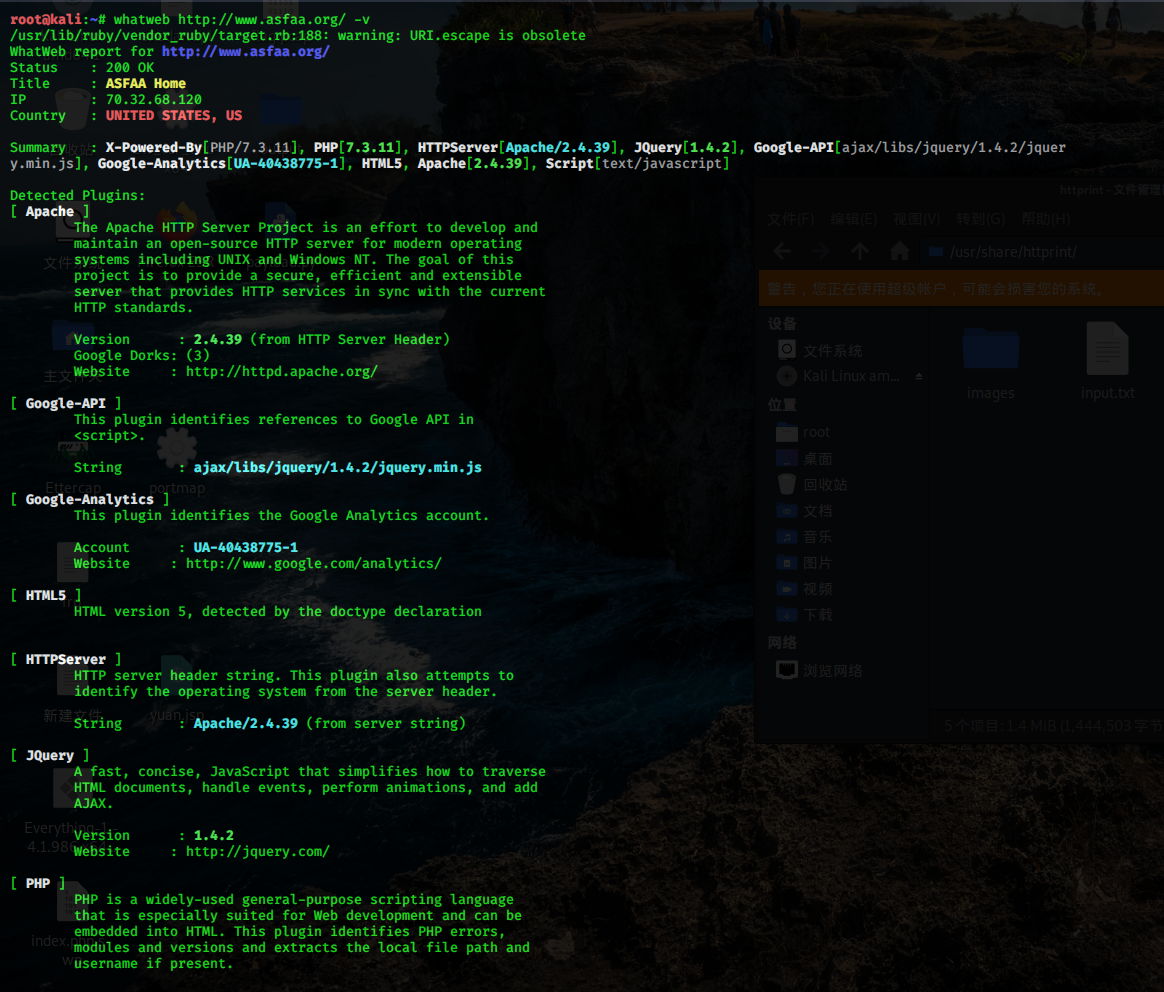
Whatweb 是一个基于 Ruby 语言的开源网站指纹识别软件,如上图,正如它的名字一样,whatweb 能够识别各种关于网站的详细信息包括:CMS 类型、博客平台、中间件、web 框架模块、网站服务器、脚本类型、JavaScript 库、IP、cookie 等等。
另外,我们可以使用 Nmap OS 指纹初步判断操作系统。对于后端 DBMS 的识别,如果主机对外开放 DBMS 的话,可以通过端口特征判断,尤其是在开放默认端口比如 3306、1443、27017 等。
真实 IP 地址识别
在渗透测试中,一般只会给你一个域名,那么我们就要根据这个域名来确定目标服务器的真实 IP,我们可以通过像www.ip138.com这样的 IP 查询网直接获取目标的一些 IP 及域名信息,但这里的前提是目标服务器没有使用 CDN。
什么是 CDN?
CDN 的全称是 Content Delivery Network,即内容分发网络。CDN 是构建在现有网络基础之上的智能虚拟网络,依靠部署在各地的边缘服务器,通过中心平台的负载均衡、内容分发、调度等功能模块,使用户就近获取所需内容,降低网络拥塞,提高用户访问响应速度和命中率。CDN 的关键技术主要有内容存储和分发技术。
CDN 将用户经常访问的静态数据资源直接缓存到节点服务器上,当用户再次请求时,会直接分发到在离用户近的节点服务器上响应给用户,当用户有实际数据交互时才会从远程 Web 服务器上响应,这样可以大大提高网站的响应速度及用户体验。CDN 网络的诞生大大地改善了互联网的服务质量,因此传统的大型网络运营商纷纷开始建设自己的 CDN 网络。
因此,如果目标服务器使用了 CDN 服务,那么我们直接查询到的 IP 并不是真正的目标服务器的 IP,而是一台离你最近的目标节点的 CDN 服务器,这就导致了我们没法直接得到目标服务器的真实 IP。
如何判断目标服务器使用了 CDN?
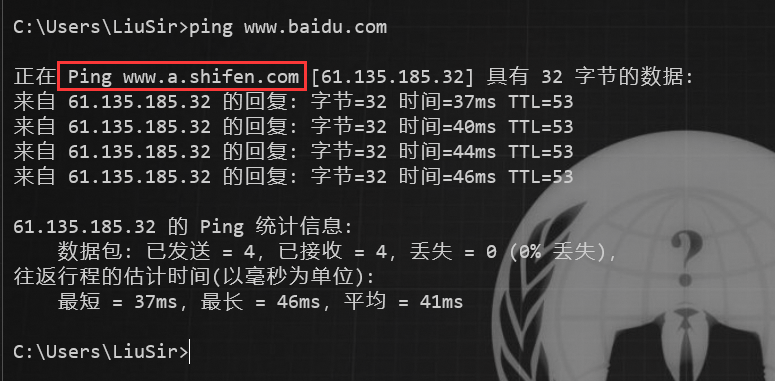
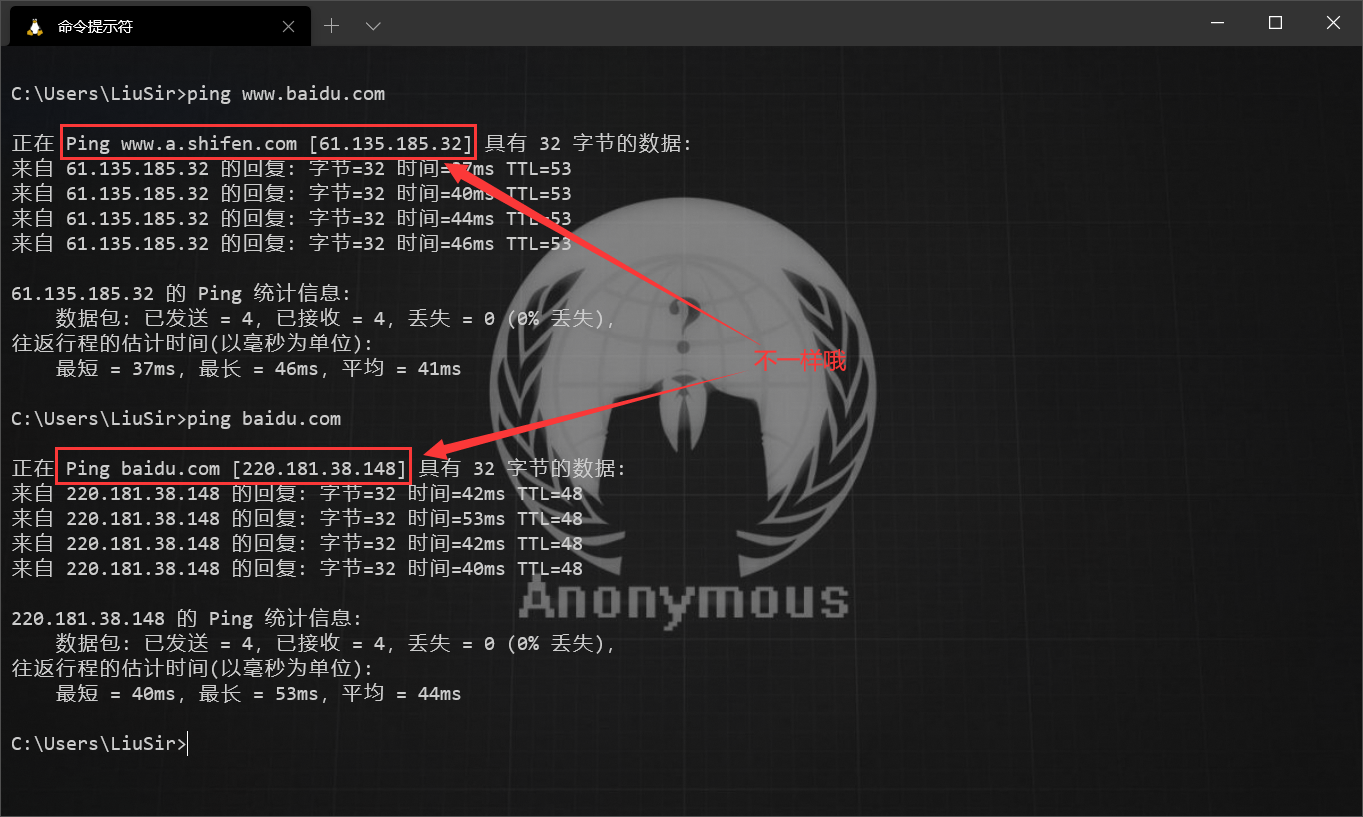
我们可以 ping 这个网站域名,比如我们 ping 百度:
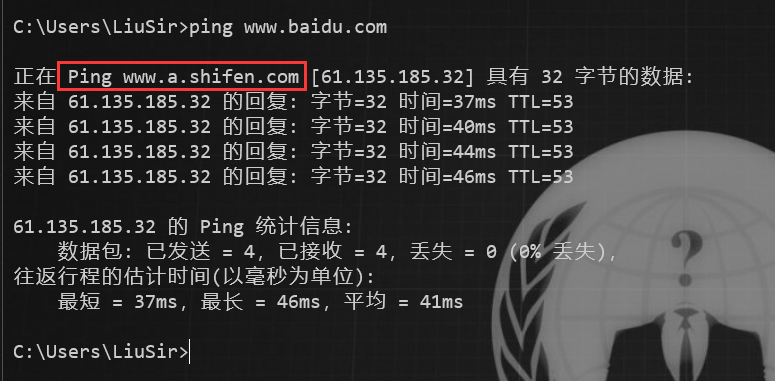
如上图,我们可以看到百度使用了 CDN。
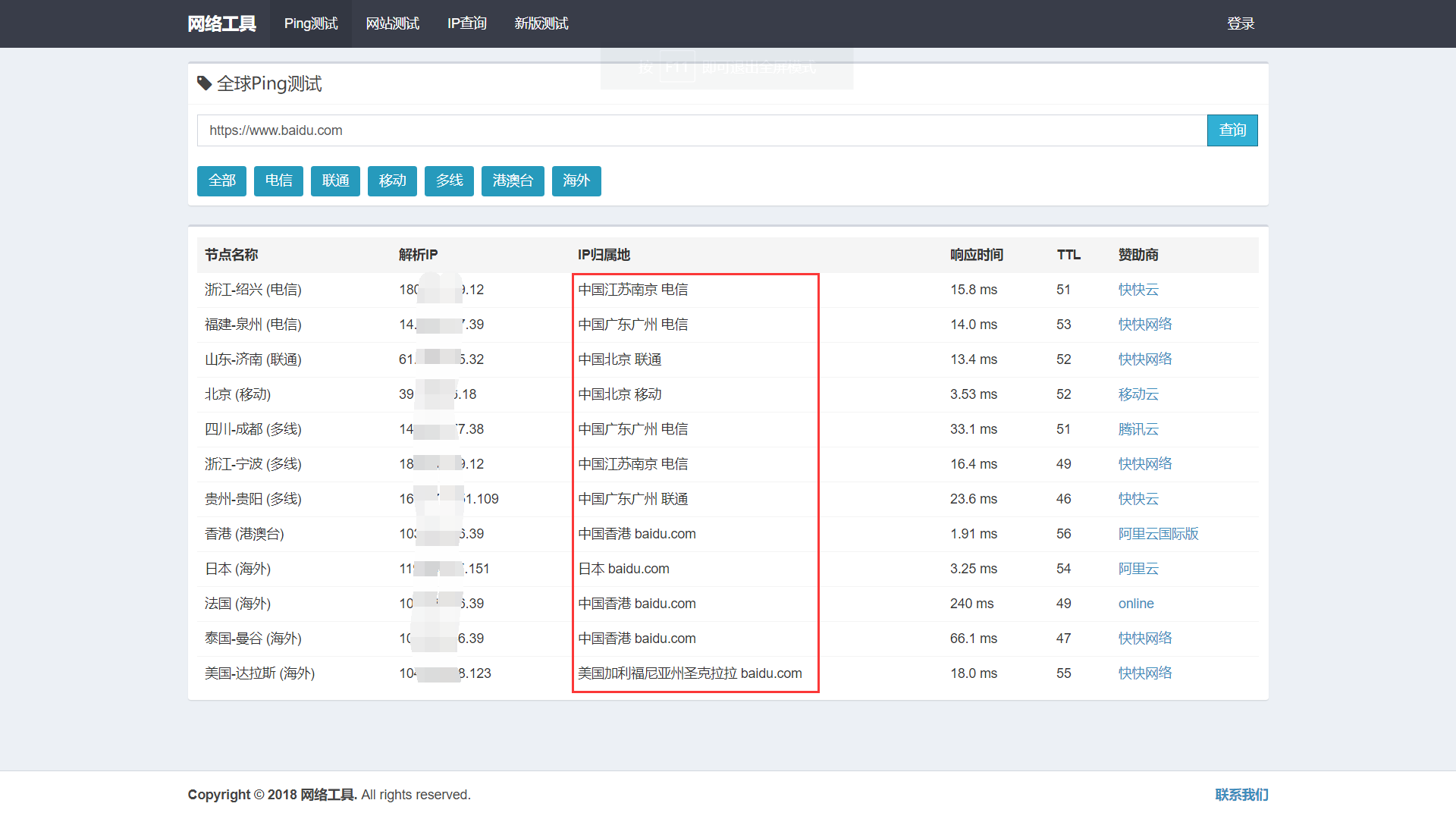
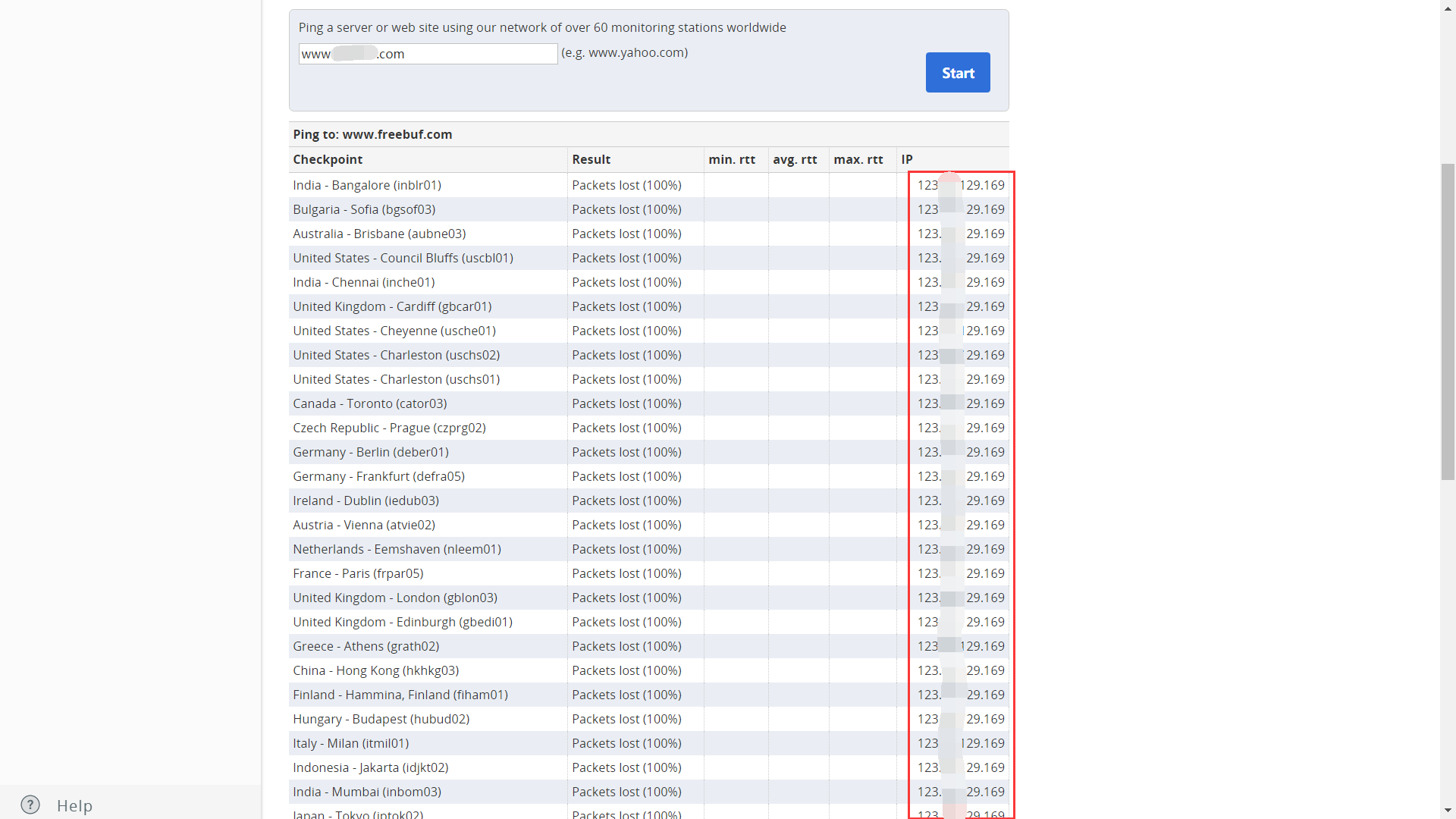
我们也可以设置代理或者通过在线 ping 网站来在不同地区进行 ping 测试,然后对比每个地区 ping 出的 IP 结果,查看这些 IP 是否一致,一致,则极有可能不存在 CDN。根据 CDN 的工作原理,如果网站使用了 CDN,那么从全国各地访问网站的 IP 地址是各个 CDN 节点的 IP 地址,那么如果 ping 出来的 IP 大多不太一样或者规律性很强,可以尝试查询这些 IP 的归属地,判断是否存在 CDN。有以下网站可以进行 ping 测试:
以 https://www.wepcc.com/ 为例,如图所示,对 https://www.baidu.com 进行 ping 命令测试,根据 IP 地址和归属地不同,可以判断 https://www.baidu.com 使用了 CDN。
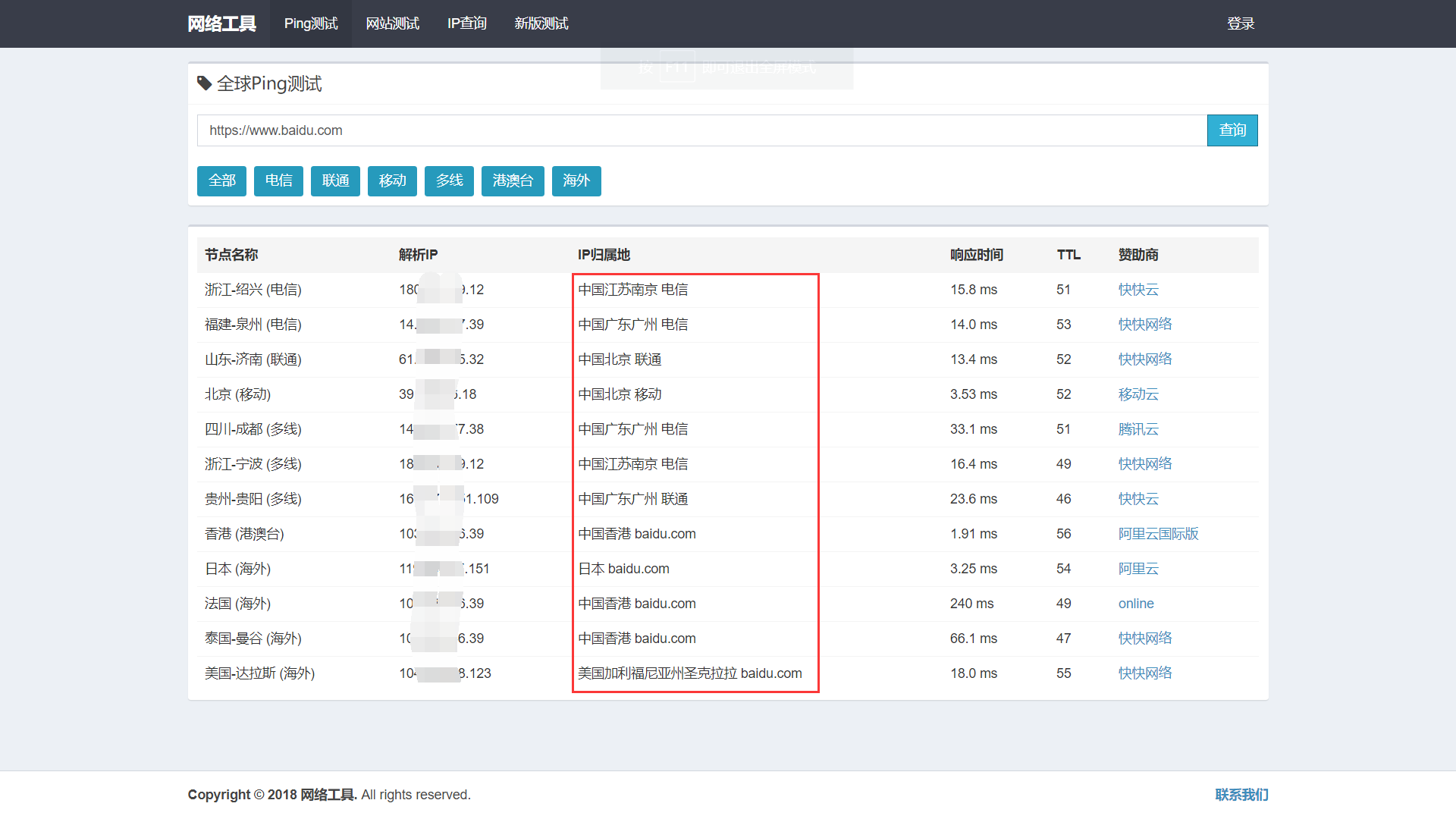
如何绕过 CDN 找到目标真实 IP?
1. 利用子域名。一般来说很多站长可能只会对主站或者流量较大的分站使用 CDN,但是一些流量比较小的分站可能没有挂 CDN,这些分站和主站虽然不是同一个 IP 但是都在同一个 C 段下面的情况,所以我们可以通过 ping 二级域名获取分站 lP,从而能判断出目标的真实 IP 段。
2. 查询主域。以前用 CDN 的时候有个习惯,只让 WWW 域名使用 cdn,秃域名不使用,为的是在维护网站时更方便,不用等 cdn 缓存。所以试着把目标网站的 www 去掉,ping 一下看 ip 和 正在 Ping 的域名 是不是变了,如下图,这个方法还是挺有效的:
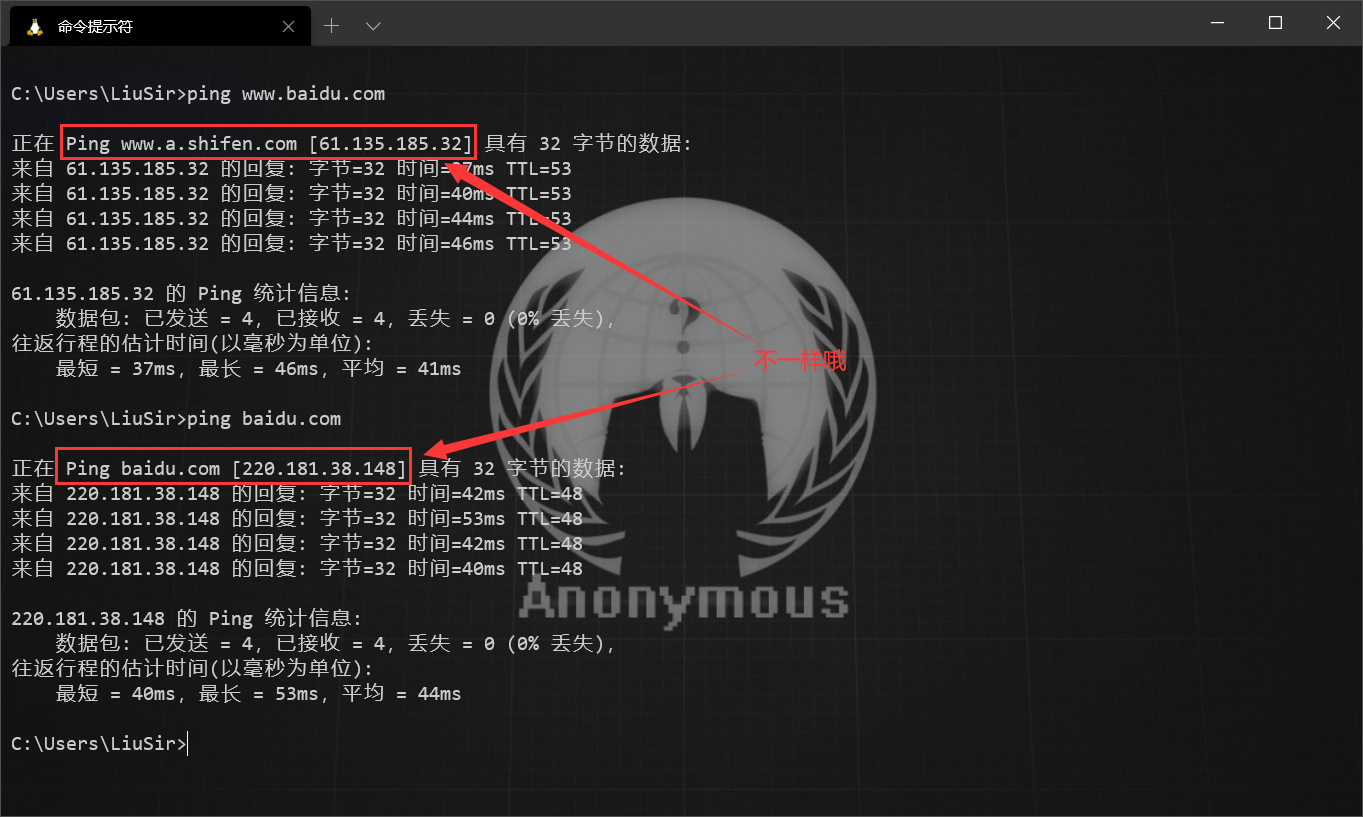
3. 扫描网站敏感文件,如 phpinfo.php 等,从而找到目标的真实 IP。
4. 从国外访问。国内很多 CDN 厂商因为各种原因只做了国内的线路,而针对国外的线路可能几乎没有,此时我们使用国外的主机直接访问可能就能获取到真实 P。我们可以通过国外在线代理网站访问,可能会得到真实的 IP 地址,外国在线代理网站:
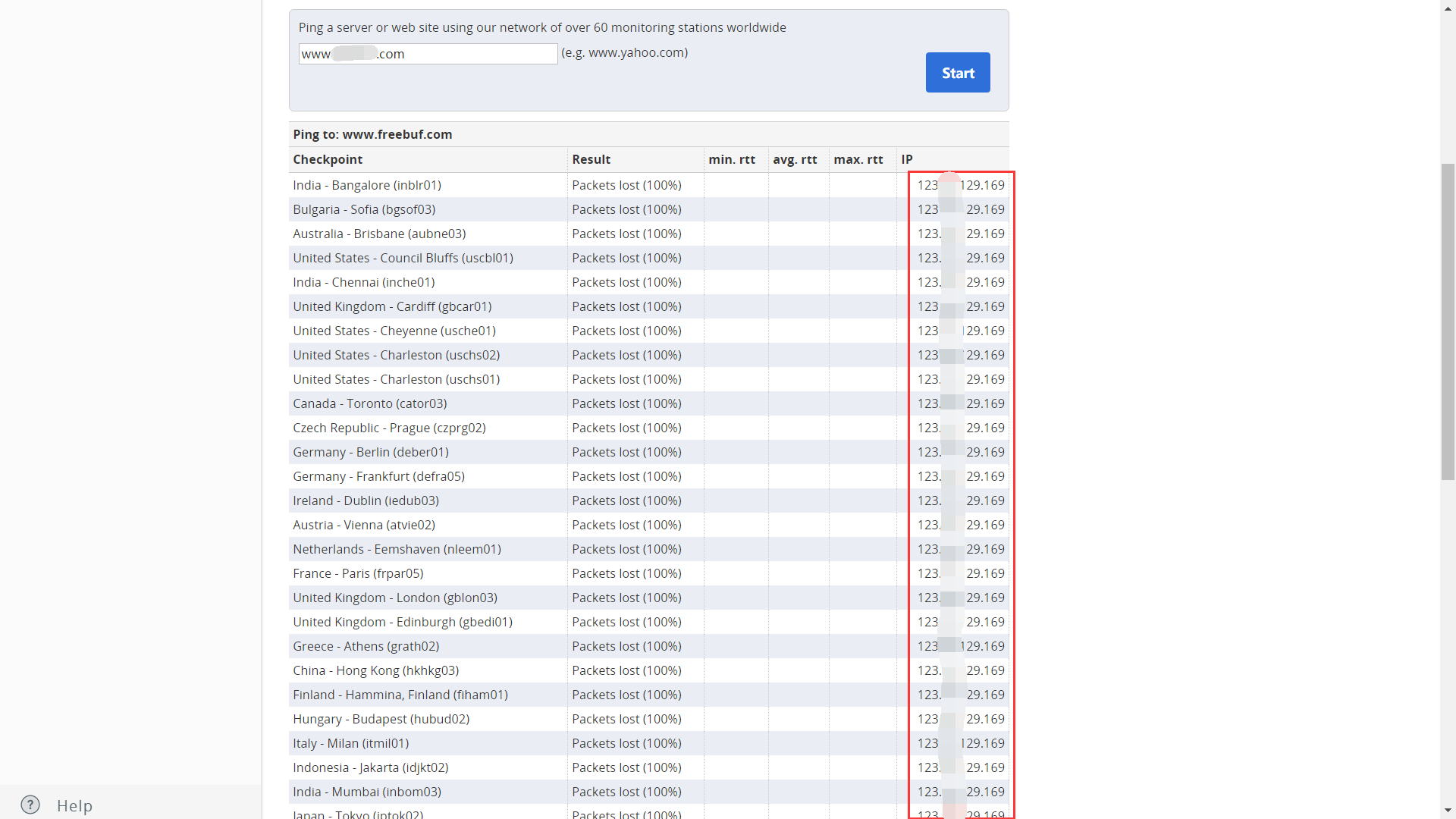
如上图,从国外代理访问目标网站的 IP 都是一样的。
5. 通过邮件服务器。一般的邮件系统都在内部,没有经过 CDN 的解析,通过目标网站用户注册或者 RSS 订阅功能,查看邮件,寻找邮件头中的邮件服务器域名 IP,ping 这个邮件服务器的域名,由于这个邮件服务器的有可能跟目标 Web 在一个段上,我们直接一个一个扫,看返回的 HTML 源代码是否跟 web 的对的上,就可以获得目标的真实 IP(必须是目标自己内部的邮件服务器,第三方或者公共邮件服务器是没有用的)。
6. 查看域名历史解析记录。也许目标很久之前没有使用 CDN,所以可能会存在使用 CDN 前的记录。所以可以通过https://www.netcraft.com、https://viewdns.info/ 等网站来观察域名的 IP 历史记录。
**7. **通过网站 SSL 证书寻找真实 IP。原理请参考:https://www.cnblogs.com/qiudabai/p/9763739.html#方法4 ,但是此方法适用于 https 的站点。
首先获得网站证书序列号(不要挂代理)
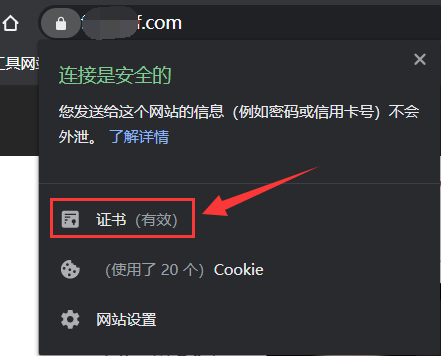
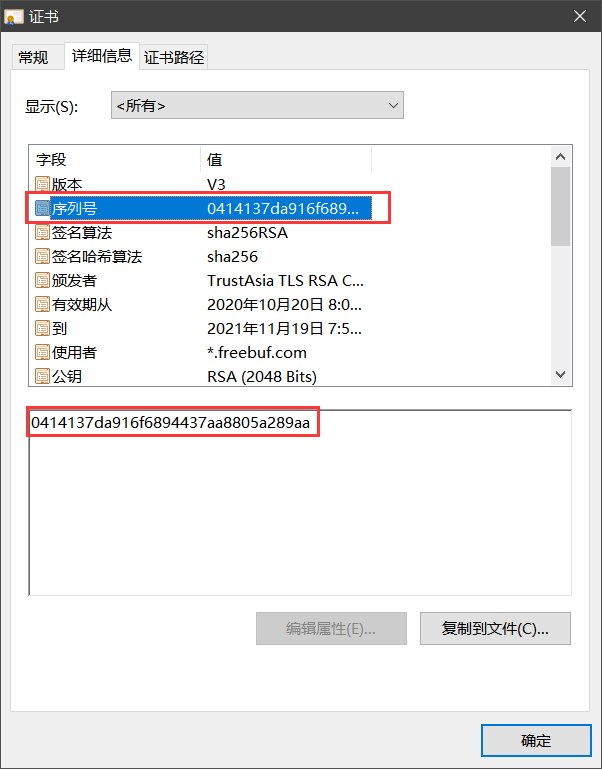
然后将该证书序列号转换成十进制 https://tool.lu/hexconvert/ :
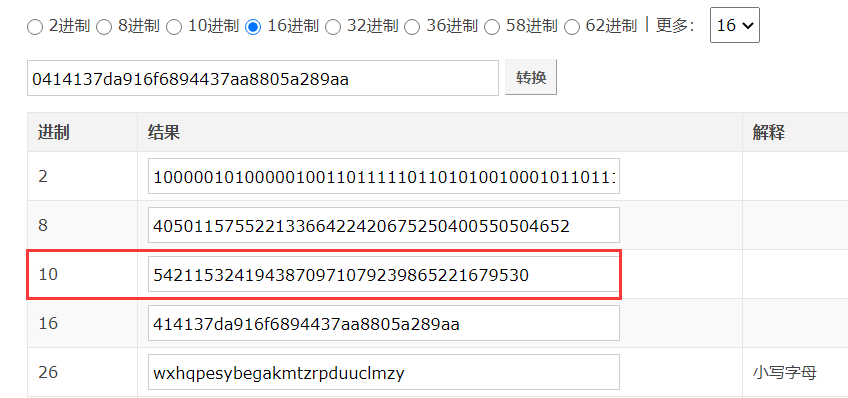
最后利用如下 fofa 语法进行 cert 搜索:
PYTHON
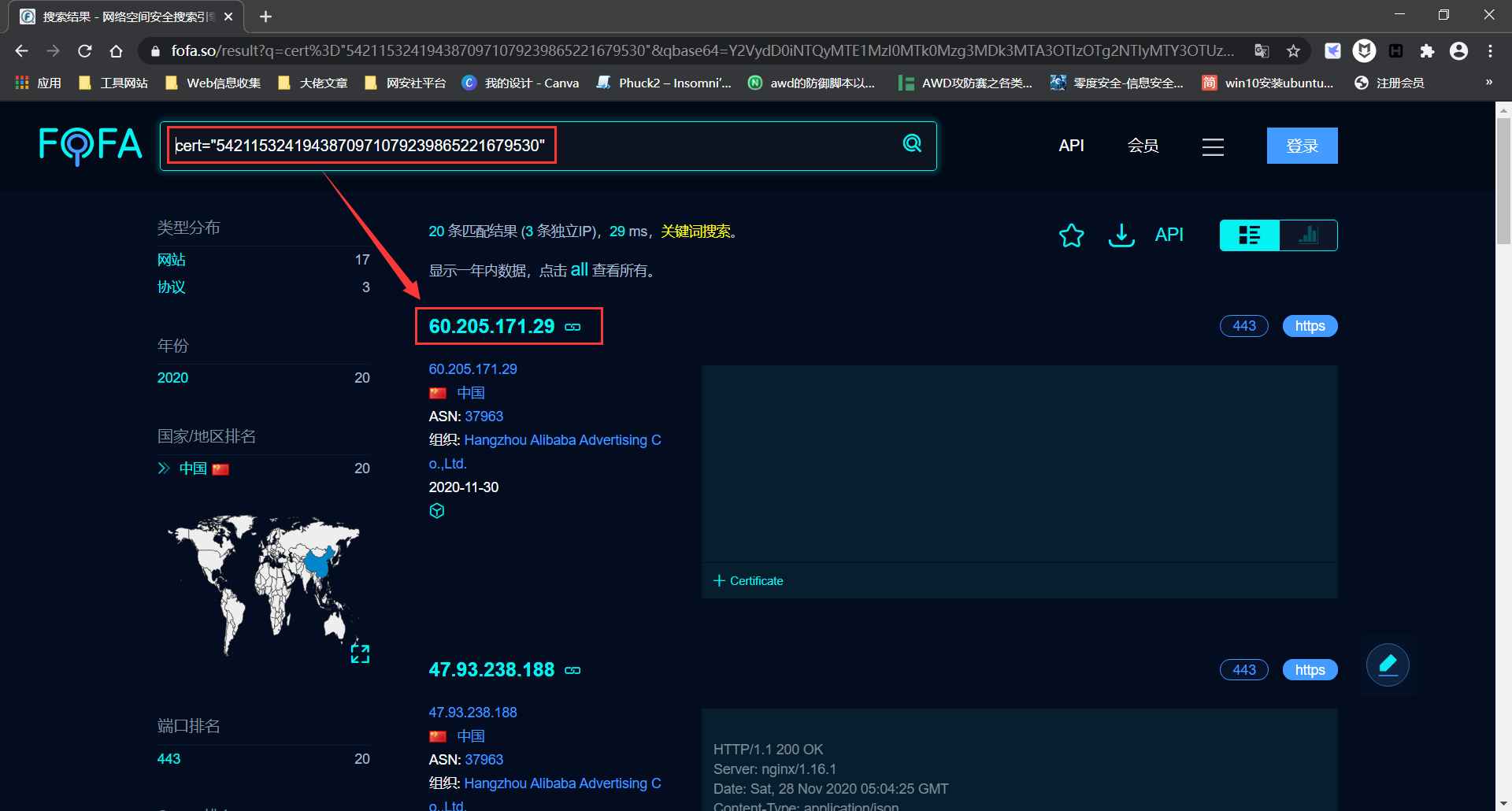
如上图,第一个就是真实的 IP。
8. Nslookup 查询。查询域名的 NS 记录、MX 记录、TXT 记录等很有可能指向的是真实 ip 或同 C 段服务器。
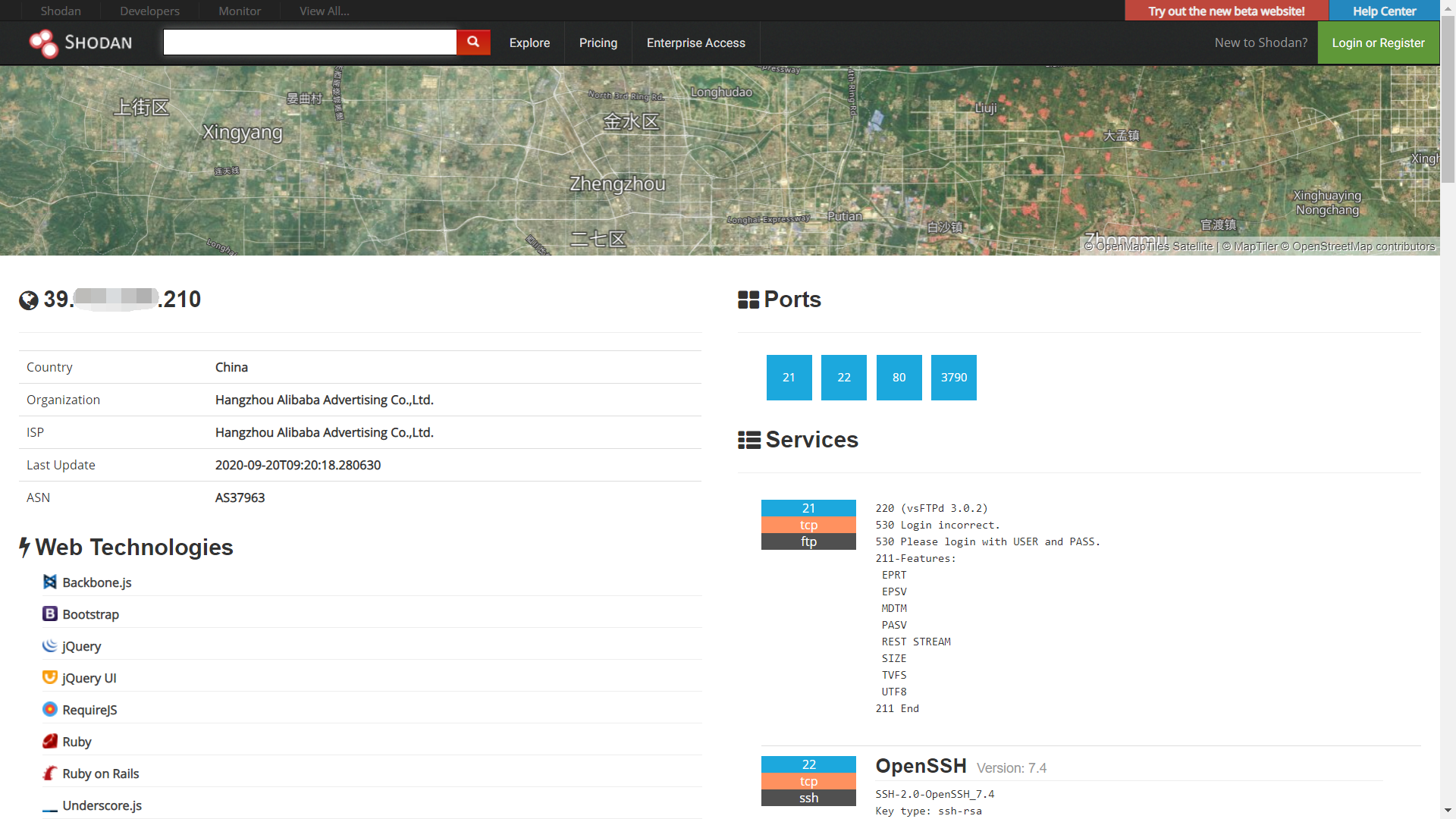
**9. **利用网络空间搜索引擎。这里主要是利用网站返回的内容寻找真实原始 IP,如果原始服务器 IP 也返回了网站的内容,那么可以在网上搜索大量的相关数据。最常见的网络空间搜索引擎有如下:
Shodan:https://www.shodan.io/
FOFA:https://fofa.so/
10. 让目标主动连接我们。
1、发邮件给我们。比如订阅、注册的时候会有注册连接发送到我们的邮件,然后查看邮件全文源代码或邮件标头,寻找邮件头中的邮件服务器域名 IP 就可以了。
2、利用网站漏洞。比如有代码执行漏洞、SSRF、存储型的 XSS 都可以让服务器主动访问我们预设的 web 服务器,那么就能在日志里面看见目标网站服务器的真实 IP。
**11. **利用 App。如果目标网站有自己的 App,可以尝试利用 Fiddler 或 Burp Suite 抓取 App 的请求,从里面找到目标的真实 IP。
**12. **绕过 CloudFlare CDN 查找真实 IP。现在很多网站都使用 CloudFlare 提供的 CDN 服务,在确定了目标网站使用 CDN 后,可以先尝试通过在线网站 CloudFlareWatch( http://www.crimeflare.us/cfs.html#box )对 CloudFlare 客户网站进行真实 IP 查询。
……
验证获得的真实 IP 地址
通过上面的方法获取了很多的 IP 地址(上面的方法 4),此时我们需要确定哪一个才是真正的 IP 地址,如果是 Web,最简单的验证方法是直接尝试用 IP 访问,看看响应的页面是不是和访问域名返回的一样即可。
C 段
获得目标真实 IP 后,我们可以百度该 IP 看是不是云上资产,
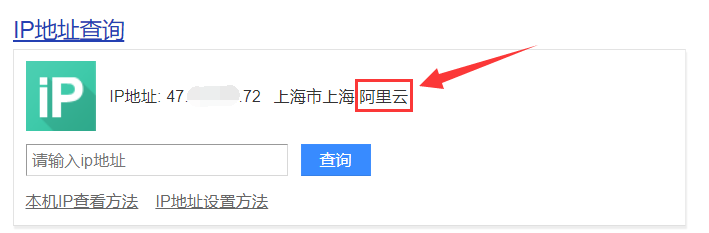
如果是阿里云或者腾讯云等云上资产的话,扫 C 段容易出现扫出一大片东西,但是没有一个是目标资产的情况。不是云上资产的话就正常扫 C 段就可以。
端口信息收集
在渗透测试的过程中,收集端口信息是一个十分重要的过程,通过扫描目标服务器开放的端口可以从该端口判断服务器上运行的服务。因为针对不同的端口具有不同的攻击方法,收集端口信息可以对症下药,便于我们渗透目标服务器。我们可以通过一下方法收集目标服务器的端口信息:
1. 使用 nmap 工具收集
CODE
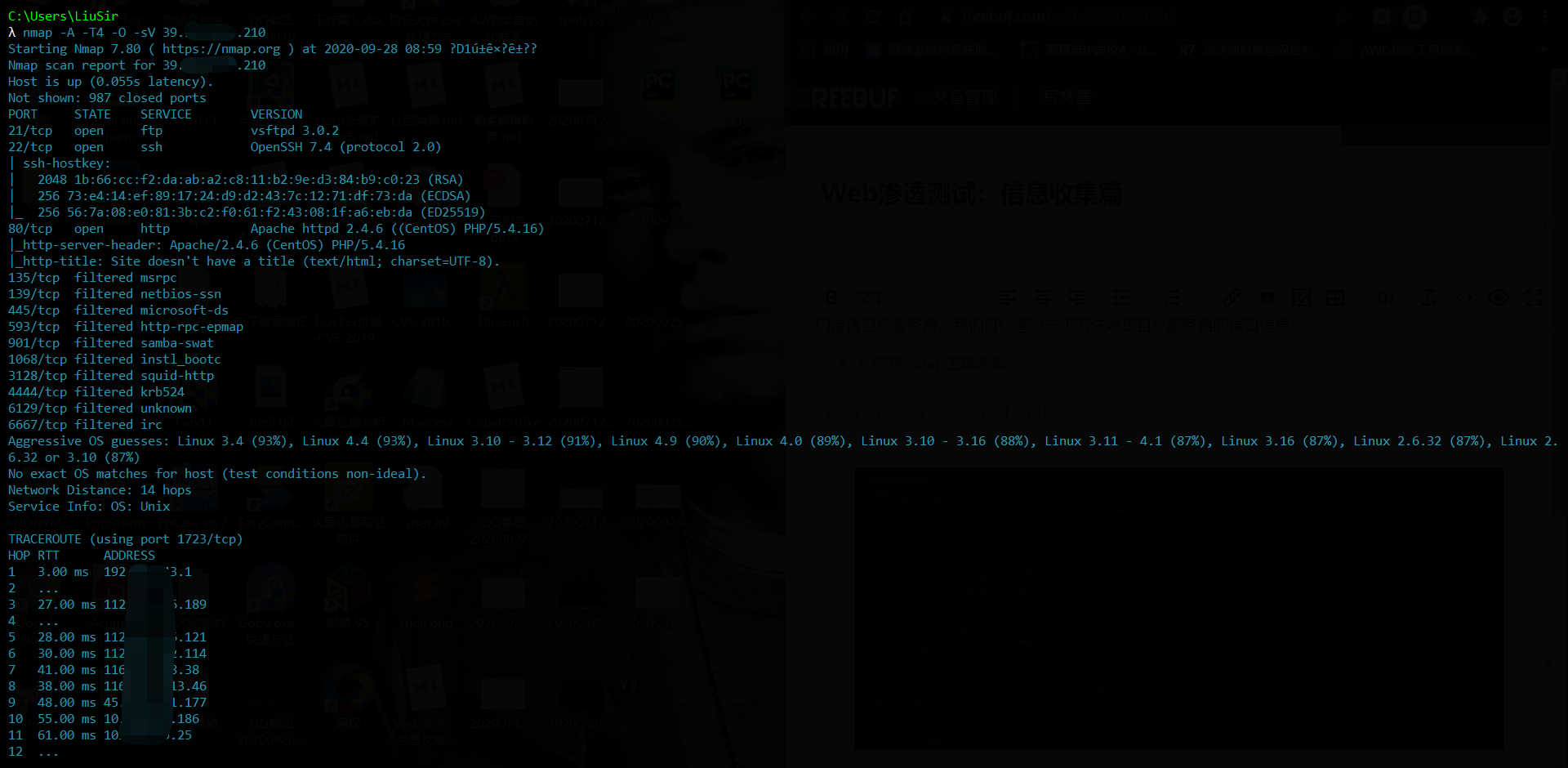
Nmap 扫得比较慢但较为准确,这里给出 2 条比较好的命令:
PHP
可以在阿里云的 vps 上装 nmap,用它来扫端口,一般 1 个 IP 全端口 3-5 分钟扫完。
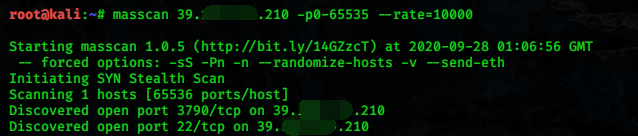
2. 使用 masscan 探测端口开放信息
Masscan 号称是最快的互联网端口扫描器,最快可以在六分钟内扫遍互联网。masscan 的扫描结果类似于 nmap(一个很著名的端口扫描器),在内部,它更像 scanrand, unicornscan, and ZMap,采用了异步传输的方式。它和这些扫描器最主要的区别是,它比这些扫描器更快。而且,masscan 更加灵活,它允许自定义任意的地址范和端口范围。
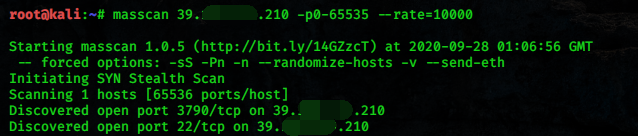
由于使用工具通常会在目标网站留下痕迹,接下来提供一种在线网站探测方法。
ThreatScan 在线网站(网站基础信息收集):https://scan.top15.cn/
Shodan:https://www.shodan.io/
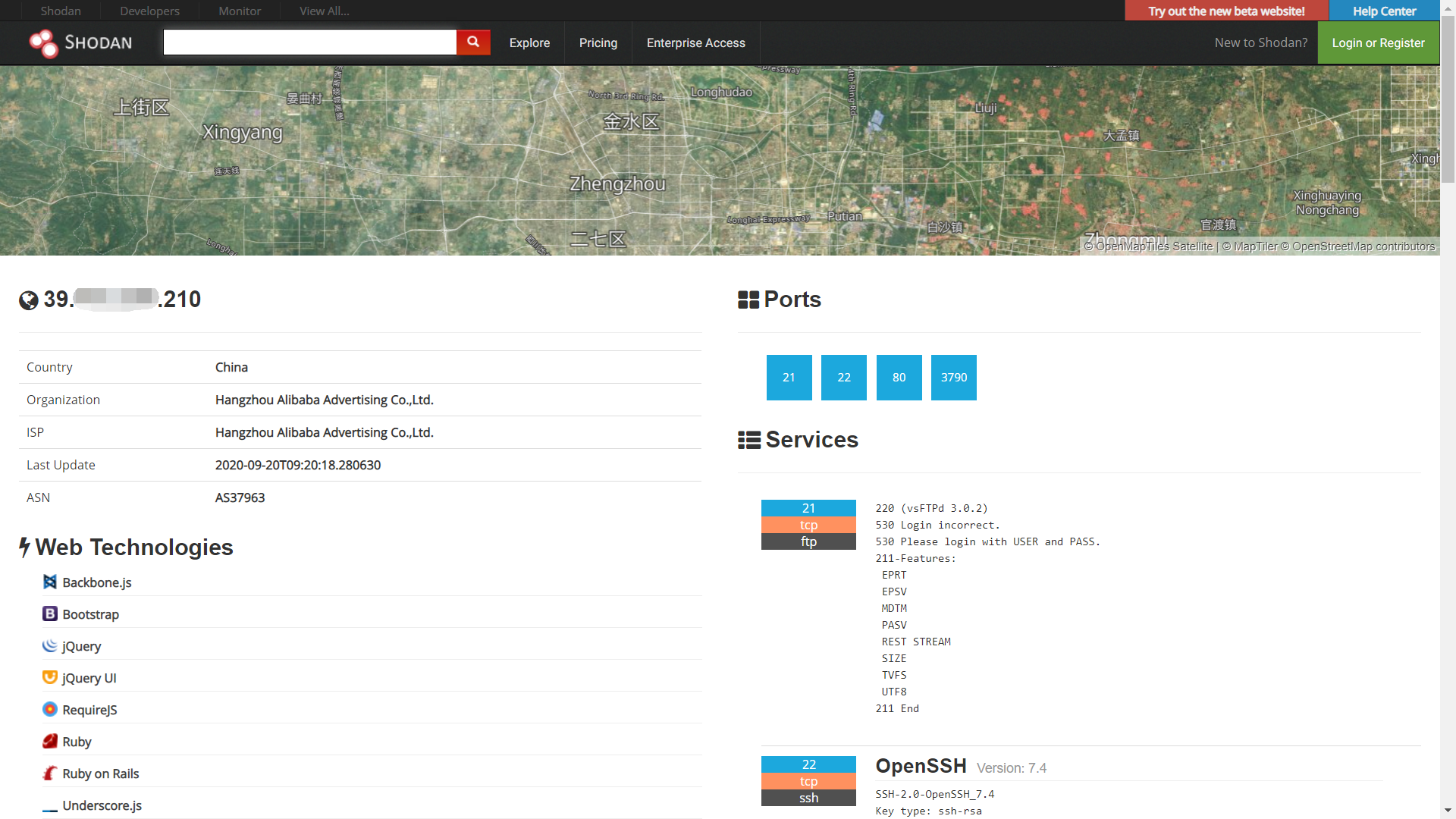
常见的端口及其攻击方向可以参考:https://blog.csdn.net/weixin_42320142/article/details/102679143
社会工程学
相信看过《我是谁:没有绝对的安全系统》的朋友对社会工程学可能有深刻的印象了。全片的过程中,一直在处处渗透着社会工程学的原理,利用人们的胆小怕事,来获取自己利益。而后来,男主将社会工程学运用到了极致,成功为自己赢得了一个新的身份。

社会工程学(Social Engineering)是一种通过人际交流的方式获得信息的非技术渗透手段。其实,现在的黑客攻击也不止是仅仅通过网络来进行远程的渗透与入侵,还会通过社会工程学在线下场景中来针对人性弱点进行相应的攻击。而且不幸的是,这种手段对于黑客来说非常有效,成功率也非常之高。事实上,社会工程学已是企业安全最大的威胁之一。狭义与广义社会工程学最明显的区别就是是否会与受害者产生交互行为。广义是有针对性的去对某一单一或多一目标进行攻击的行为。社会工程学在渗透测试中起着不小的作用,利用社会工程学,攻击者可以从一名员工的口中挖掘出本应该是秘密的信息。
凯文·米特尼克在《反欺骗的艺术》中曾提到,人为因素才是安全的软肋。很多企业、公司在信息安全上投入大量的资金,最终导致数据泄露的原因,往往却是发生在人本身。你们可能永远都想象不到,对于黑客们来说,通过一个用户名、一串数字、一串英文代码,社会工程师就可以通过这么几条的线索,通过社工攻击手段,加以筛选、整理,就能把你的所有个人情况信息、家庭状况、兴趣爱好、婚姻状况、你在网上留下的一切痕迹等个人信息全部掌握得一清二楚。虽然这个可能是最不起眼,而且还是最麻烦的方法。一种无需依托任何黑客软件,更注重研究人性弱点的黑客手法正在兴起,这就是社会工程学黑客技术。
社会工程学攻击包括四个阶段:
研究:信息收集(WEB、媒体、垃圾桶、物理),确定并研究目标
钩子:与目标建立第一次交谈(HOOK、下套)
下手:与目标建立信任并获取信息
退场:不引起目标怀疑的离开攻击现场
社会工程学收集的常见信息包括:姓名、性别、出生日期、身份 zheng 号、身份 zheng 家庭住址、身份 zheng 所在公安局、快递收货地址、大致活动范围、qq、手机号、邮箱、银行 card 号(银行开户行)、支付宝、贴吧、百度、微博、猎聘、58、同城、网盘、微信、常用 ID、学历(小/初/高/大学/履历)、目标性格详细分析、常用密码、照片 EXIF 信息。
常见可获取信息系统包括:中航信系统、春秋航空系统、12306 系统、三大运营商网站、全国人口基本信息资源库、全国机动车/驾驶人信息资源库、各大快递系统(越权)、全国出入境人员资源库、全国在逃人员信息资源库、企业相关系统、全国安全重点单位信息资源库等。
举个例子:
假设我们要对一家公司进行渗透测试,正在收集目标的真实 IP 阶段,此时就可以利用收集到的这家公司的某位销售人员的电子邮箱。首先,给这位销售人员发送邮件,假装对某个产品很感兴趣,显然销售人员会回复邮件。这样攻击者就可以通过分析邮件头来收集这家公司的真实 IP 地址及内部电子邮件服务器的相关信息。通过进一步地应用社会工程学,假设现在已经收集了目标人物的邮箱、QQ、电话号码、姓名,以及域名服务商,也通过爆破或者撞库的方法获取邮箱的密码,这时就可以冒充目标人物要求客服人员协助重置域管理密码,甚至技术人员会帮着重置密码,从而使攻击者拿下域管理控制台,然后做域劫持。
详情请参考:
https://www.zhihu.com/question/26113526
https://blog.csdn.net/Eastmount/article/details/100585715
推荐书籍:
《黑客心理学》、《欺骗的艺术》
Ending……

“知己知彼,百战不殆”,进行 web 渗透测试之前,最重要的一步那就是就是信息收集了,俗话说“渗透的本质也就是信息收集”,信息收集的深度,直接关系到渗透测试的成败。打好信息收集这一基础可以让测试者选择合适和准确的渗透测试攻击方式,缩短渗透测试的时间。
参考
https://blog.csdn.net/qq_41880069/article/details/83037081
https://blog.csdn.net/qq_32434307/article/details/107353811
https://blog.csdn.net/Eastmount/article/details/102816621
https://www.freebuf.com/sectool/104256.html
https://blog.csdn.net/weixin_41970600/article/details/104766547
https://blog.csdn.net/qq_36119192/article/details/84029809
https://www.freebuf.com/news/137497.html
https://www.fujieace.com/penetration-test/cdn-find-ip.html
https://blog.csdn.net/qq_36119192/article/details/89151336
https://blog.csdn.net/zyhj2010/article/details/45064903
https://blog.csdn.net/Eastmount/article/details/100585715

还未添加个人签名 2021.04.06 加入
还未添加个人简介









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
评论