真的了解 HDFS 的 SecondaryNameNode 是干什么的?

前言
HDFS SecondaryNameNode 是干什么的?
这是道经典的基础面试题,笔者问过面试者很多次(当然也被面试官问过很多次)。从印象看,大约有一半的被面试者无法正确作答,给出的答案甚至有“不就是 NameNode 的热备嘛 ”。本文来简单聊聊相关的知识,为节省篇幅,将 SecondaryNameNode 简称 SNN,NameNode 简称 NN。
NN 与 fsimage、edit log 文件
NN 负责管理 HDFS 中所有的元数据,包括但不限于文件/目录结构、文件权限、块 ID/大小/数量、副本策略等等。客户端执行读写操作前,先从 NN 获得元数据。当 NN 在运行时,元数据都是保存在内存中,以保证响应时间。
显然,元数据只保留在内存中是非常不可靠的,所以也需要持久化到磁盘。NN 内部有两类文件用于持久化元数据:
fsimage 文件,以 fsimage_为前缀,是序列化存储的元数据的整体快照;
edit log 文件,以 edits_为前缀,是顺序存储的元数据的增量修改(即客户端写入事务)日志。
这两类文件均存储在 ${dfs.namenode.name.dir}/current/ 路径下,查看其中的内容:
可见,fsimage 和 edit log 文件都会按照事务 ID 来分段。当前正在写入的 edit log 文件名会带有"inprogress"标识,而 seen_txid 文件保存的就是当前正在写入的 edit log 文件的起始事务 ID。
在任意时刻,最近的 fsimage 和 edit log 文件的内容加起来就是全量元数据。NN 在启动时,就会将最近的 fsimage 文件加载到内存,并重放它之后记录的 edit log 文件,恢复元数据的现场。
SNN 与 checkpoint 过程
为了避免 edit log 文件过大,以及缩短 NN 启动时恢复元数据的时间,我们需要定期地将 edit log 文件合并到 fsimage 文件,该合并过程叫做 checkpoint(这个词是真正被用烂了哈)。
由于 NN 的负担已经比较重,再让它来进行 I/O 密集型的文件合并操作就不太科学了,所以 Hadoop 引入了 SNN 负责这件事。也就是说,SNN 是辅助 NN 进行 checkpoint 操作的角色。
checkpoint 的触发由 hdfs-site.xml 中的两个参数来控制。
dfs.namenode.checkpoint.period:触发 checkpoint 的周期长度,默认为 1 小时。
dfs.namenode.checkpoint.txns:两次 checkpoint 之间最大允许进行的事务数(即 edit log 的增量条数),默认为 100 万。
只要满足上述两个参数的条件之一,就会触发 checkpoint 过程,叙述如下:
NN 生成新的 edits_inprogress 文件,后续的事务日志将写入该文件中,之前正在写的 edit log 文件即为待合并状态。
将待合并的 edit log 文件和 fsimage 文件一起复制到 SNN 本地。
SNN 像 NN 启动时一样,将 fsimage 文件加载到内存,并重放 edit log 文件进行合并。生成合并结果为 fsimage.chkpoint 文件。
SNN 将 fsimage.chkpoint 复制回 NN,并重命名为正式的 fsimage 文件名。
Hadoop 官方给出的图示如下。虽然文件名称不同,但思想是一样的。
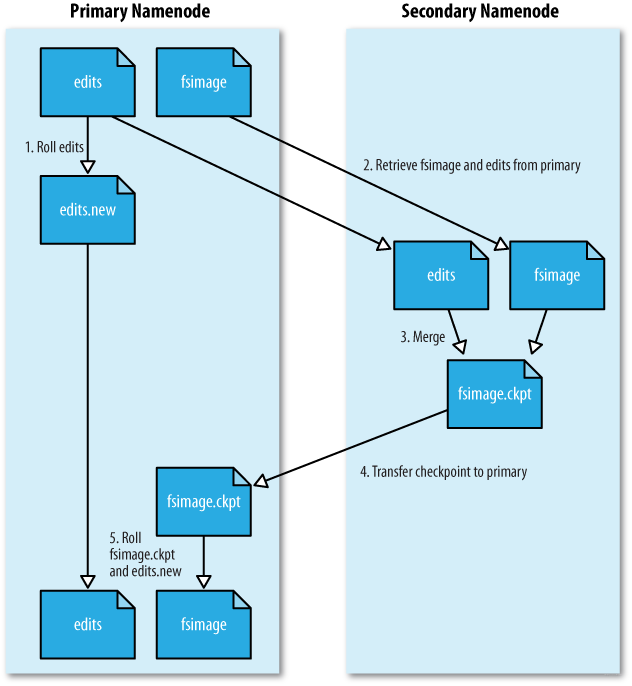
另外,为了避免 fsimage 文件占用太多磁盘空间,通过 dfs.namenode.num.checkpoints.retained 参数可以指定保留多少个 fsimage 文件,默认值为 2。
如果开启了 NN 高可用呢?
上面说的都是集群只有一个 NN 的情况。如果有两个 NN 并且开启了 HA 的话,SNN 就没用了——checkpoint 过程会直接交给 Standby NN 来负责。Active NN 会将 edit log 文件同时写到本地与共享存储(QJM 方案就是 JournalNode 集群)上去,Standby NN 从 JournalNode 集群拉取 edit log 文件进行合并,并保持 fsimage 文件与 Active NN 的同步。
NN 高可用的实现原理又是一个重要的话题,可以说很多,择日另外写文章讨论吧。

公众号:云祁QI 2020.06.23 加入
我是「云祁」,一枚热爱技术、会写诗的大数据开发猿,专注数据中台和 Hadoop / Spark / Flink 等大数据技术,欢迎一起交流学习。生命不是要超越别人,而是要超越自己!加油 (ง •_•)ง









评论