【架构师训练营第 1 期 13 周】 学习总结
【架构师训练营第 1 期 13 周】 学习总结
这周老师介绍了大数据批计算 Spark 的计算逻辑,通过 RDD 对数据进行分块处理。而现在很多 app 都在使用的流计算,主要工具有 Flink、Storm、Spark Streaming,这些工具基本都是继承自批计算的技术,主要是把包分的更小来进行计算。然后老师还介绍了大数据基准测试工具 HiBench,可以通过它给大数据系统做计算测试,测量计算能力。讲解完工具之后,后面一节讲解了大数据分析与可视化,企业的各项数据指标分析,和展现图表模式。之后的几节都是讲解计算的各种算法,比如 PageRank 网页排名,分类并进行标签的一系列分类聚类算法:KNN 分类算法,提取文本特征值 TF-IDF 算法,贝叶斯分类算法,K-means。现在各大 APP 常用的推荐引擎算法,以及正在飞速发展的机器学习和神经网络算法。
通过这两周从大数据工具,到大数据算法的了解。随着信息越来越多地被收集到互联网上,系统对人的分析画像会更加准确,持续优化各类算法,处理的数据量级会持续增加。未来还有很大的发展空间,不能单纯满足于使用工具,做工具人,还需要了解业务才能针对性地使用算法进行分析。各类算法了解的门槛也很高,需要持续学习。
附上这周记录的简单笔记:
============================分割线=====================================
13.1 大数据计算引擎 Spark(上)
Spark 特点:
DAG 切分的多阶段计算过程更快速
使用内存存储中间计算结果更加高效
RDD 的编程模型更简单
分片 rdd->shuffle->key 聚合
优化了编程过程,本质没有变化。
RDD 弹性分布式数据集(Resilient Distributed Datasets),既是 Spark 面向开发者的编程模型,又是 Spark 自身架构的核心元素。
MapReduce 面向过程,主要看输入输出。
Spark 直接针对数据进行编程,将大规模数据集合抽象成一个 RDD 对象,然后再 RDD 上处理,得到新的 RDD,继续处理知道最后结果。思考的重心和落脚点都在 RDD 上。
各种转换函数实现 RDD 转换
RDD 转换两种:
1.转换操作产生的 RDD 不会出现新的分片,惰性计算。窄依赖(无 shuffle 依赖)
2.会产生新的分片,不同的数据重新聚合在一起,数据重组。宽依赖(shuffle 依赖)
============================分割线=====================================
13.2 大数据计算引擎 Spark(下)
多个计算阶段(stage),这些计算阶段组成一个有向无环图 DAG,Spark 任务调度器可以根据 DAG 的依赖关系执行计算阶段。
每个阶段要处理的数据量生成相应的任务集合(TaskSet),每个任务都分配一个任务进程去处理,Spark 就实现了大数据的分布式计算。
DAGScheduler 是 DAG 生成和管理组件,根据代码生成 DAG,然后将程序分发到分布式计算集群,按计算阶段的先后关系进行调度执行。
RDD 之间转换连接线呈现多对多交叉连接时,就会产生洗呢阶段。
RDD 函数有两种:
1.转换函数,调用后还是得到 RDD;
2.action 函数,调用后不返回 RDD
Spark 代码可以转换成 DAG 有向无环图,运行后得到作业任务的执行时间图。
SparkContext 通过 RDD 编程得到 DAG,Cluster Manager 进行管理计算资源,通过 worker node 有空闲资源就进行计算。
Spark 生态可以进行各种大数据计算。
============================分割线=====================================
13.3 流处理计算:Flink、Storm、Spark Streaming
Storm:实时的 Hadoop,低延迟、高性能、分布式、可伸缩、高可用。和 Hadoop 的角色一一对应。
Spark Streaming 和 Flink :批处理和流处理都是类似的, 就是分片大小问题。
============================分割线=====================================
13.4 大数据基准测试工具 HiBench
构建测试数据
算法验证
验证集群处理能力
============================分割线=====================================
13.5 大数据分析与可视化
互联网运营常用数据指标:
新增用户数:日/周/年
用户留存率
用户留存率=留存用户数/当期新增用户数, 大约 40%是不错的数据
用户流失率=1-用户留存率
活跃用户数
PV(Page View):用户点击次数
GMV(成交总金额 Gross Merchandise Volume)
转换率=有购买行为的用户数/总访问用户数
数据可视化图表和数据监控
折线图
散点图
热力图
漏斗图
通过数据分析进行监控运营状态
============================分割线=====================================
13.6 网页排名算法 PageRank
Google 左侧排名或佩奇排名。由创办人拉里.佩奇来命名。
让连接来“投票”,看各个页面之间引用次数。
矩阵向量,稀疏矩阵

============================分割线=====================================
13.7 分类和聚类算法
KNN 分类算法(K 近邻, K Nearest Neighbour 算法):和已经标注好的样本进行对比计算距离,得到最靠近的。
通过欧氏距离计算公式看数据的准确性
余弦相似度计算公式计算倾向性
提取文本特征值 TF-IDF 算法
TF(词频 Term Frequency)=某个词在文档中出现的次数/文档总词数
IDF(逆文档频率 Inverse Document Frequency,表示该词文档稀缺程度)=log(所有的文档总数/出现该词的文档数)
TF-IDF=TF*IDF
贝叶斯分类算法
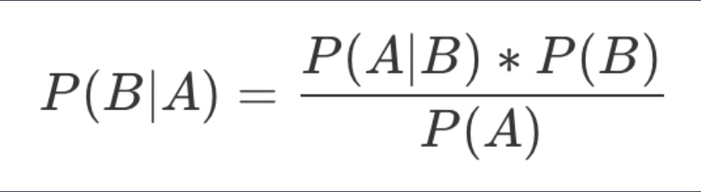
K-means 聚类算法:
随机种子点;
求出随机种子距离;
对比中心点
循环前两步直到不再变动中心点;
============================分割线=====================================
13.8 推荐引擎算法
推荐引擎提高用户留存率
推荐算法:
基于人口统计的推荐
基于商品属性的推荐
基于用户的协同过滤推荐
基于商品的协同过滤推荐
============================分割线=====================================
13.9 机器学习和神经网络算法
样本:训练数据,包括输入和结果两个部分
模型:映射样本输入与样本结果的函数
算法:从模型的假设空间中寻找一个最优的函数
机器学习的数学原理:从假设空间寻找最优函数,而最优函数就是使样本数据的函数值和真实值距离最小的函数。
感知机算法:比较简单的二分类模型,将输入特征分类为+1、-1 两类,通过求和得到损失值。
神经网络:多个感知机连接在一起,调参党
============================分割线=====================================
版权声明: 本文为 InfoQ 作者【Bear】的原创文章。
原文链接:【http://xie.infoq.cn/article/2e60e13c1465184956123bc1e】。文章转载请联系作者。

还未添加个人签名 2019.02.16 加入
还未添加个人简介









评论