SecureBoost 算法
本文转自“雨夜随笔”公众号,欢迎关注。
之所以要开始写《数据价值》这一系列文章,是最近学习和工作中逐渐感觉目前随着数据的爆发,如何去挖掘数据的价值正成为目前的主流话题,所以希望不断记录相关的信息和和知识,来探寻如何去挖掘数据价值和目前的一些尝试。
背景
在《数据价值-联邦学习篇》:初识 这篇文章中我们简单讲解了联邦学习的由来,概念和现状。那么在2016年Google发表的联邦学习论文,针对的场景是横向联邦学习,也就是样本特征重叠部分较多,但是用户重叠部分较少的情景。这个场景适合于同一规范下的模型聚合,像Android上的模型训练,样本除了用户不同,基本情况都是一样的。但是随着行业间的融合,更多的场景变成了用户重叠部分很多,但是特征重叠部分较多的情况。
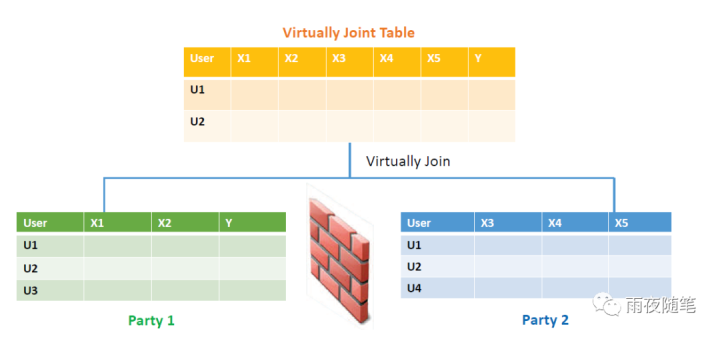
比如我是一家银行,我这边目前有一个识别用户能否定时还钱的模型,但是因为我这边只有用户账户的一些信息,这些维度对于决定用户能否定时还钱来说显得还是太少了,这样造成模型的准确率达不到理想的效果,于是我想用户的其他信息,比如和电信或者移动合作,把他们的标签也应用起来,应该可以提高模型的准确率,而这就是纵向联邦学习的由来,而将纵向联邦学习推向可行高度的就是《SecureBoost: A Lossless Federated Learning Framework》这篇论文,那么就让我们开始今天的旅程。
同态加密
SecureBoost 论文的提出背景是现在行业对数据的的隐私要求越来越高,所以 SecureBoost 论述的第一个就是在隐私性上的保证,这里面包括通过分析去除不必要的信息,只传输必要的信息。然后是使用同态加密处理必要的隐私信息,同态加密是一种新型的加密方式,与其他加密方式不同的在于关注数据的处理安全,可以保证其他用户可以在无法破解数据的情况下处理数据。就像下图:
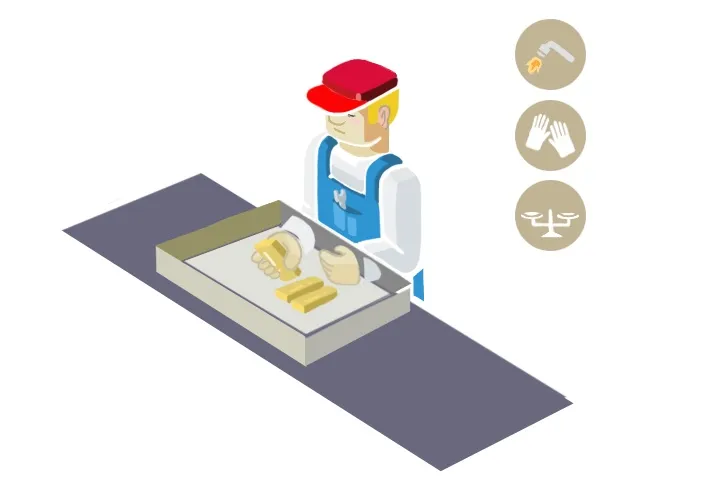
我们把黄金锁在盒子里面,这个相当于加密,然后给其他用户。其他用户无法接触到盒子里面的黄金,也不知道盒子里面是什么。而我们告诉用户如何去操作里面的东西,并提供了手套来处理黄金,那么在用户处理完黄金后,我们就可以拿到处理后的黄金。而 SecureBoost 就是就是采用这一点保证隐私信息的安全。
训练
在SecureBoost 设定的场景中包含两种角色,一种是拥有标签和数据的Active Party,另外一种是只拥有数据的Passive Party。一个SecureBoost 场景下,应当有1个Active Party, n个Passive Party.如下图:
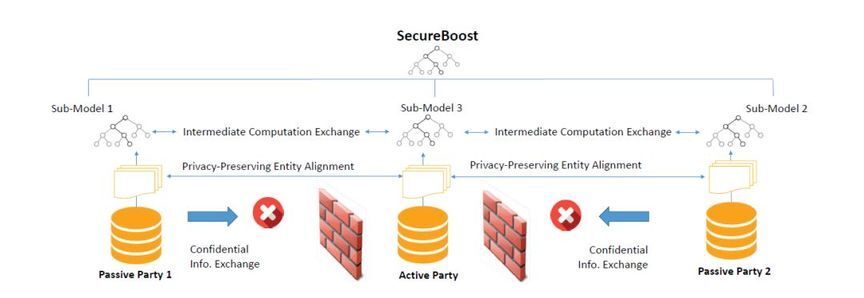
SecureBoost 训练总共分为两部分,第一是数据对齐,第二部分是构造Boost树。由于这两部分并不是SecureBoost的重点,这里只做简单介绍。
数据对齐
数据对齐的难点在于如何让隐私信息不被暴露的情况下对齐数据,也就是说比如A有{u1,u2,u3,u4}四个数据,B有{u1,u2,u3,u5}四个数据,如果让A,B在不知道对方的数据前提下,找到{u1,u2,u3}这个并集。这里SecureBoost没有自己造轮子,而是使用了Gang Liang and Sudarshan S. Chawathe的《Privacy-Preserving Inter-Database Operations》论文中的方法。具体的我们来看FATE的实现:

总体上的思路就是:
B先通过RSA生成n(公有密钥)、e(加密算法)、d(解密算法),然后把公钥(n,e)传给A。

A拿到公钥后,先将自己的数据通过哈希函数进行加密,然后通过增加噪声r,然后通过加密算法(e)加密然后回传给B。
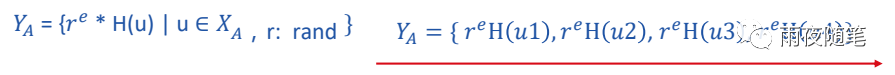
B拿到加密后的Y(A)后,使用解密算法(d)解密,这时获得含有噪声的哈希值Z(A),然后B同时将自己的数据进行哈希然后在进行解密,再进行二次哈希,传给A。
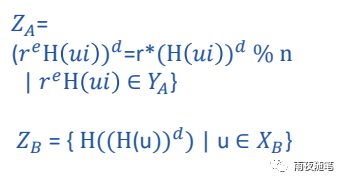
A拿到后,先消除Z(A)的噪声,然后再进行哈希,得到D(A),这样D(A)和Z(B)都是两方数据进行二次哈希和解密后的值,也就是处于同一纬度。这时候就可以求两者的并集。然后回传给B.
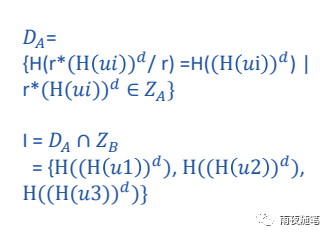
B拿到后通过比对自己数据和并集后的数据,得到实际的并集{u1,u2,u3}.然后回传给A.

通过上面的操作,A,B在不知道对方的差分数据下得到了并集,也就是对齐了数据样本。
构造Boost树
然后就是构造Boost树,这个其实就是将XGBoost通过联邦学习的方式进行构建Boost树。,SecureBoost 关注的在于如果在保护隐私的情况下构造出全局的Boost树,我们关注上面构造的过程,在数据对齐后,每一方会交换训练的中间值,也就是权重。这里值得注意的是,为了保证数据安全,这里也使用了同态加密。并且为了保证能够使用同态加密,这里对数据进行了处理,以除去无法进行同态加密的运算。
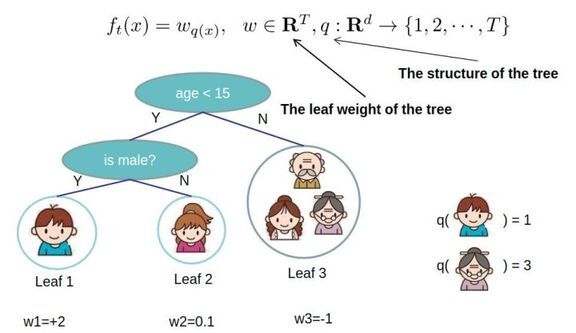
总的来说,SecureBoost 在处理这两部分时,重点使用了同态加密来保证数据的安全,同时为了符合同态加密的条件,调节了整个构造过程。
推理
那么通过上面的方式,我们构造了下面的树:
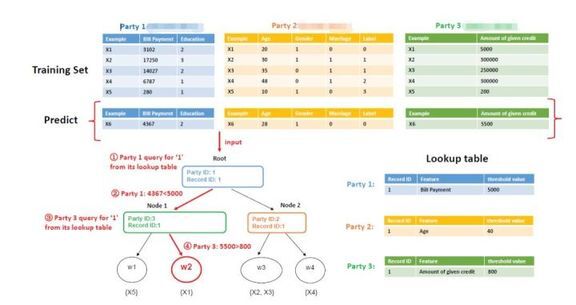
这里首先要说明的是,这张图是SecureBoost 论文中的图,而实际描述中中Party1应该是Active Party,所以标签应该是Party 1的。那么我们接下来就容易理解了,构造的Boost数,左边的叶子节点永远小于右边。而每一个非叶子节点都是一个查询条件。那么现在我们把需要推理的条件输入进来,进入到根节点,我们查询当期记录是Party 1的,而对应的值是Bill Payment 5000,而当前的值4367比5000小,所以我们进入左子树,然后查询到时Party 3的,对应的值是Amount of given credit 800,比输入的5500小,所以我们进入到右子树。这时发现已经是是叶子节点了,那么我们直接找到这个值的标签,也就是x1的标签0,和我们的输入一致,我们认为这个预测是成功的。
更严格的SecureBoost
由于SecureBoost 构造Boost树第一个子树是由Active Party和Passive Party共同参与的,所以导致主动方的标签信息可能发生泄漏。所以SecureBoost在论文中提出了更为严格的Completely SecureBoost,也就是第一个子树完全有Active Party构造,Passive Party完全不参与。这样的话Passive Party只能拿到第一个子树的结果,这样就可以保证标签信息不被泄漏。
总结
SecureBoost 是为了实现纵向联邦学习的为了提出了一种构建算法,目的是为了在保护数据隐私的前提下进行多方联合学习。SecureBoost 在应用到纵向联邦学习时,主要包括两点,一是数据对齐,提出了一种在不泄露数据标识的情况下寻找数据交集的方法。二是训练构造Boost树,同样出发点是保护数据的安全。同时为了进一步减少数据的泄露风险,提出了更为严格的Completely SecureBoost。隐私和安全是把双刃剑,在保护隐私和安全的情况下,联邦学习的训练效率不可避免的收到了影响。这也是目前联邦学习不断探索的方向。

版权声明: 本文为 InfoQ 作者【soolaugust】的原创文章。
原文链接:【http://xie.infoq.cn/article/2e3da0e1cb8ef16cb6197b733】。未经作者许可,禁止转载。

公众号:雨夜随笔 2018.09.21 加入
公众号:雨夜随笔









评论