Flink 比 Spark 好在哪?
1 Flink 介绍
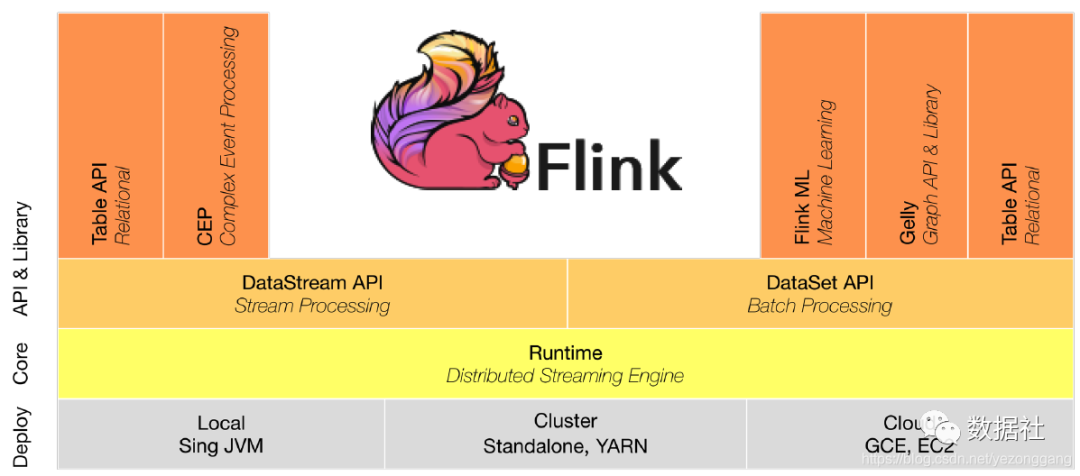
Flink 是一个面向分布式数据流处理和批量数据处理的开源计算平台。和 Spark 类似,两者都希望提供一个统一功能的计算平台给用户,都在尝试建立一个统一的平台以运行批量,流式,交互式,图处理,机器学习等应用。
1.1 部署模式
Flink 集群的部署,本身不依赖 Hadoop 集群,如果用到 HDFS 或是 HBase 中的存储数据,就需要选择对应的 Hadoop 版本。

Standalone
YARN
Mesos
Cloud
1.2 整合支持
Flink 支持消费 kafka 的数据;
支持 HBase,Cassandra, ElasticSearch
支持与 Alluxio 的整合
支持 RabbitMQ
1.3 API 支持
对 Streaming 数据类应用,提供 DataStream API
对批处理类应用,提供 DataSet API(支持 Java/Scala)
对流处理和批处理,都支持 Table API
支持双流 join
1.4 Libraries 支持
支持机器学习(FlinkML)
支持图分析(Gelly)
支持关系数据处理(Table)
支持复杂事件处理(CEP)
1.5 Flink on YARN
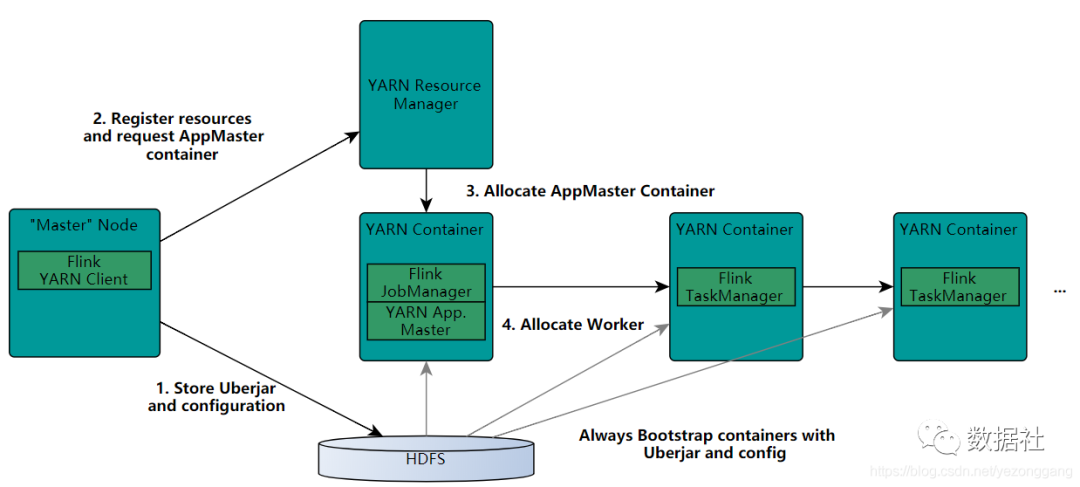
Flink 提供两种 Yarn 的部署方式 Yarn Setup:
Start a long-running Flink cluster on YARN
通过命令 yarn-session.sh 来实现,本质上是在 yarn 集群上启动一个 flink 集群。
由 yarn 预先给 flink 集群分配若干个 container 给 flink 使用,在 yarn 的界面上只能看到一个 Flink session with X TaskManagers 的任务。
只有一个 Flink 界面,可以从 Yarn 的 ApplicationMaster 链接进入。
使用 bin/flink run 命令发布任务时,本质上是使用 Flink 自带的调度,与普通的在 Flink 集群上发布任务并没有不同。不同的任务可能在一个 TaskManager 中,也即是在一个 JVM 进程中,无法实现资源隔离。
Run a Flink job on YARN
通过命令 bin/flink run -m yarn-cluster 实现,一次只发布一个任务,本质上给每个 flink 任务启动了一个集群。
yarn 不事先给 flink 分配 container,而是在任务发布时,启动 JobManager(对应 Yarn 的 AM)和 TaskManager,如果一个任务指定了 n 个 TaksManager(-yn n),则会启动 n+1 个 Container,其中一个是 JobManager。
发布 m 个应用,则有 m 个 Flink 界面,对比方式一,同样发布 m 个应用,会多出 m-1 个 JobManager 的。
发布任务时,实际上是使用了 Yarn 的调用。不同的任务不可能在一个 Container(JVM)中,也即是实现了资源隔离。
以第一种启动方式为例,其主要启动流程如下:
首先我们通过下面的命令行启动 flink on yarn 的集群
这里将产生总共五个进程:
1 个 FlinkYarnSessionCli ---> Yarn Client
1 个 YarnApplicationMasterRunner ---> AM + JobManager
3 个 YarnTaskManager --> TaskManager
即一个客户端+4 个 container,1 个 container 启动 AM,3 个 container 启动 TaskManager。
yarn-session.sh 支持的参数:

一个 Flink 环境在 YARN 上的启动流程:
FlinkYarnSessionCli 启动的过程中首先会检查 Yarn 上有没有足够的资源去启动所需要的 container,如果有,则上传一些 flink 的 jar 和配置文件到 HDFS,这里主要是启动 AM 进程和 TaskManager 进程的相关依赖 jar 包和配置文件。
接着 yarn client 会首先向 RM 申请一个 container 来启动 ApplicationMaster(YarnApplicationMasterRunner 进程),然后 RM 会通知其中一个 NM 启动这个 container,被分配到启动 AM 的 NM 会首先去 HDFS 上下载第一步上传的 jar 包和配置文件到本地,接着启动 AM;在这个过程中会启动 JobManager,因为 JobManager 和 AM 在同一进程里面,它会把 JobManager 的地址重新作为一个文件上传到 HDFS 上去,TaskManager 在启动的过程中也会去下载这个文件获取 JobManager 的地址,然后与其进行通信;AM 还负责 Flink 的 web 服务,Flink 里面用到的都是随机端口,这样就允许了用户能够启动多个 yarn session。
从这个启动过程中可以看出,在每次启动 Flink on YARN 之前,需要指定启动多少个 TaskManager,每个 taskManager 分配的资源是固定的,也就是说这个资源量从 taskManager 出生到死亡,资源情况一直是这么多,不管它所承载的作业需求资源情况,这样在作业需要更多资源的时候,没有更多的资源分配给对应的作业,相反,当一个作业仅需要很少的资源就能够运行的时候,仍然分配的是那些固定的资源,造成资源的浪费。
用户实现的 Flink 程序是由 Stream 和 Transformation 这两个基本构建块组成,其中 Stream 是一个中间结果数据,而 Transformation 是一个操作,它对一个或多个输入 Stream 进行计算处理,输出一个或多个结果 Stream。当一个 Flink 程序被执行的时候,它会被映射为 Streaming Dataflow。一个 Streaming Dataflow 是由一组 Stream 和 Transformation Operator 组成,它类似于一个 DAG 图,在启动的时候从一个或多个 Source Operator 开始,结束于一个或多个 Sink Operator。
下面是一个由 Flink 程序映射为 Streaming Dataflow 的示意图,如下所示:
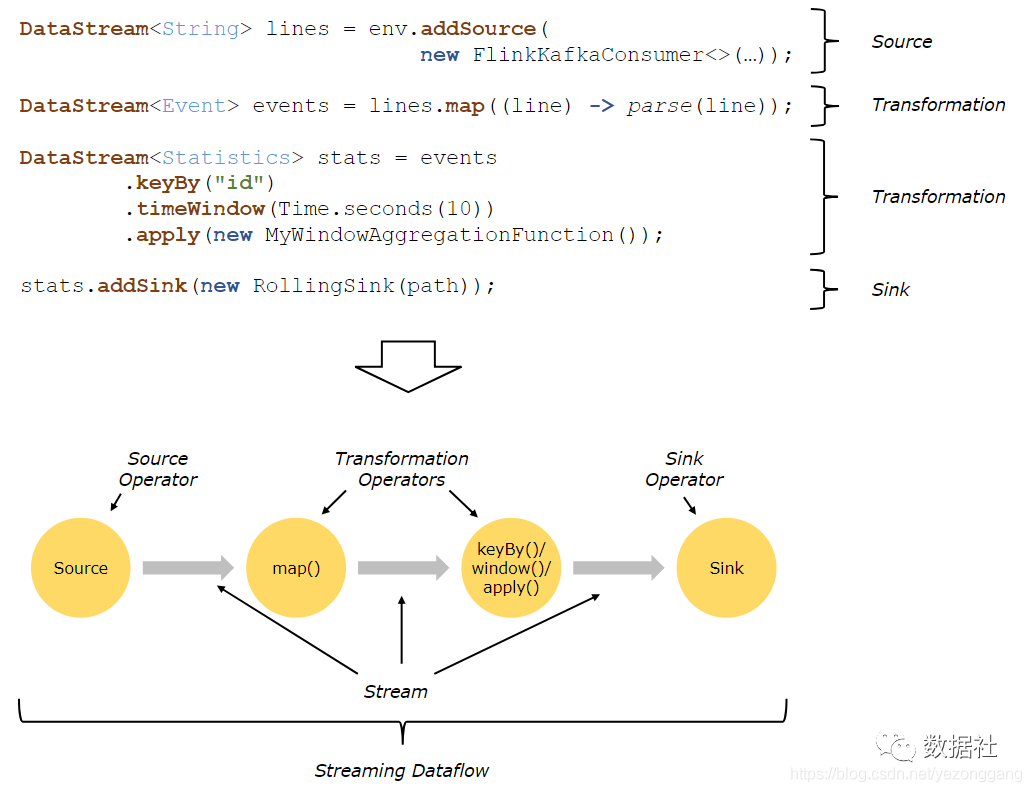
FlinkKafkaConsumer 是一个 Source Operator,map、keyBy、timeWindow、apply 是 Transformation Operator,RollingSink 是一个 Sink Operator。
1.6 CEP(Complex event processing)
Flink CEP 是一套极具通用性、易于使用的实时流式事件处理方案。作为 Flink 的原生组件,省去了第三方库与 Flink 配合使用时可能会导致的各种问题。但其功能现阶段看来还比较基础,不能表达复杂的业务场景,同时它不能够做到动态更新。
具体的业务逻辑
从例子代码中可以看到,patterns 需要用 java 代码写,需要编译,很冗长很麻烦,没法动态配置;需要可配置,或提供一种 DSL;再者,对于一个流同时只能设置一个 pattern,比如对于不同的用户实例想配置不同的 pattern,就没法支持;需要支持按 key 设置 pattern。
1.7 Flink 目前存在的一些问题
在实时计算中有这么一个普遍的逻辑:业务逻辑中以一个流式数据源与几个相关的配置表进行 join 操作,而配置表并不是一成不变的,会定期的进行数据更新,可以看成一个缓慢变化的流。这种 join 环境存在以下几个尚未解决的问题:
1.对元数据库的读压力;如果分析程序有 1000 并发,是否需要读 1000 次;
2.读维表数据不能拖慢主数据流的 throughput,每秒千万条数据量;
3.动态维表更新问题和一致性问题;元数据是不断变化的,如何把更新同步到各个并发上;
4.冷启动问题,如何保证主数据流流过的时候,维表数据已经 ready,否则会出现数据无法处理;
5.超大维表数据会导致流量抖动和频繁 gc,比如几十万条的实例数据,可能上百兆。
在 Flink 社区,对该问题也进行了关注
https://issues.apache.org/jira/browse/FLINK-6131
https://issues.apache.org/jira/browse/FLINK-2320
https://issues.apache.org/jira/browse/FLINK-3514
当然在生产环境上也有相应的解决方案:
使用 redis 来做 cache,只用一个 job,负责从元数据库同步数据到 redis,这样就解决 1,3
然后所有的并发都从 redis 直接查询需要的元数据,这样就解决 4;对于 2,在并发上做 local cache,只有第一次需要真正查询 redis,后续定期异步更新就好,不会影响到主数据流;对于 5,因为现在不需要一下全量的读取维表数据到内存,用到的时候才去读,分摊了负载,也可以得到缓解。
这个方案也有一定的弊端,增加了架构的外部依赖,要额外保障外部 redis 和同步 job 的稳定性。
2 Flink vs Spark
2.1 框架
Spark 把 streaming 看成是更快的批处理,而 Flink 把批处理看成 streaming 的 special case。这里面的思路决定了各自的方向,其中两者的差异点有如下这些:
实时 vs 近实时的角度:Flink 提供了基于每个事件的流式处理机制,所以可以被认为是一个真正的流式计;而 Spark,不是基于事件的粒度,而是用小批量来模拟流式,也就是多个事件的集合。所以 Spark 被认为是近实时的处理系统。
Spark streaming 是更快的批处理,而 Flink Batch 是有限数据的流式计算。
2.1.1 流式计算和批处理 API
Spark 对于流式计算和批处理,都是基于 RDD 的抽象。这样很方便将两种计算方式合并表示。而 Flink 将流式计算和批处理分别抽象出来 DataStream 和 DataSet 两种 API,这一点上 Flink 相对于 spark 来说是一个糟糕的设计。
2.2 社区活跃度对比
Spark 2.3 继续向更快、更易用、更智能的目标迈进,引入了低延迟的持续处理能力和流到流的连接,让 Structured Streaming 达到了一个里程碑式的高度。
3 提交一个 Flink 作业
启动 flink 服务
./bin/yarn-session.sh -n 4 -jm 2048 -tm 2048

在 yarn 监控界面上可以看到该作业的执行状态
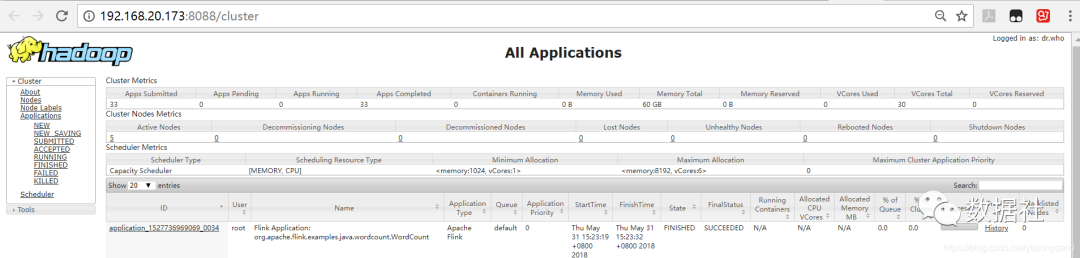
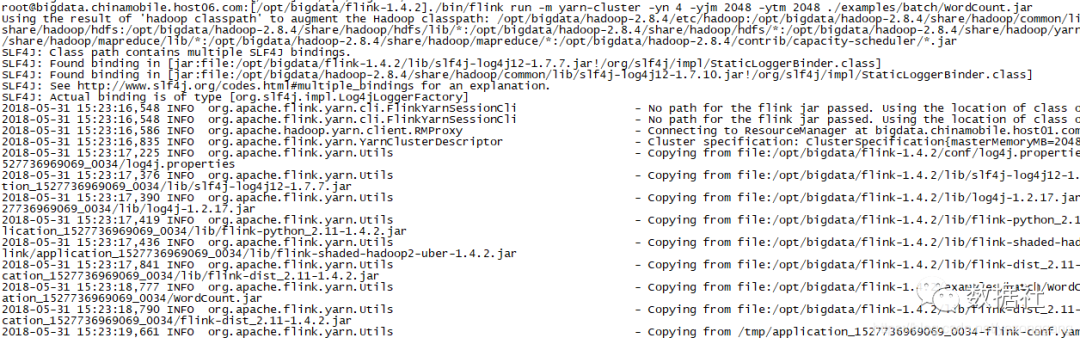
并验证 Wordcount 例子
在 client 端可以看到 log:
版权声明: 本文为 InfoQ 作者【数据社】的原创文章。
原文链接:【http://xie.infoq.cn/article/2ac1ced38ca77f52d40a68fb2】。文章转载请联系作者。

微信公众号:数据社 2018.04.26 加入
专注大数据架构,数据仓库,MPP数据库分享,微信公众号数据社









评论