Spark 学习笔记一之为什么 Spark 这么牛逼

先来看一组信息:
2014 年的 Sort Benchmark 测试中,Spark 在使用十分之一计算资源的情况下,相同数据排序,Spark 比 MapReduce 快 3 倍!
2015 年 6 月,Spark 最大的集群来自腾讯——8000 个结点,单个 Job 最大来自阿里巴巴和 Databricks——1PB
Use of MapReduce engine for Big Data projects wille decline,replaced by Apache Spark. ——Hadoop 之父 Doug Cutting
Hadoop 商业发行版本的市场领导者 Cloudera、Horton works、MapR纷纷转投Spark,并把 Spark 作为大数据解决方案的首选和核心计算引擎。
可以看出来,这么多大牛和大厂为Spark 背书,Spark 绝对很牛逼!
这一篇文章主要结合 Spark 的发展历程来讲讲 Spark 为什么这么牛逼。
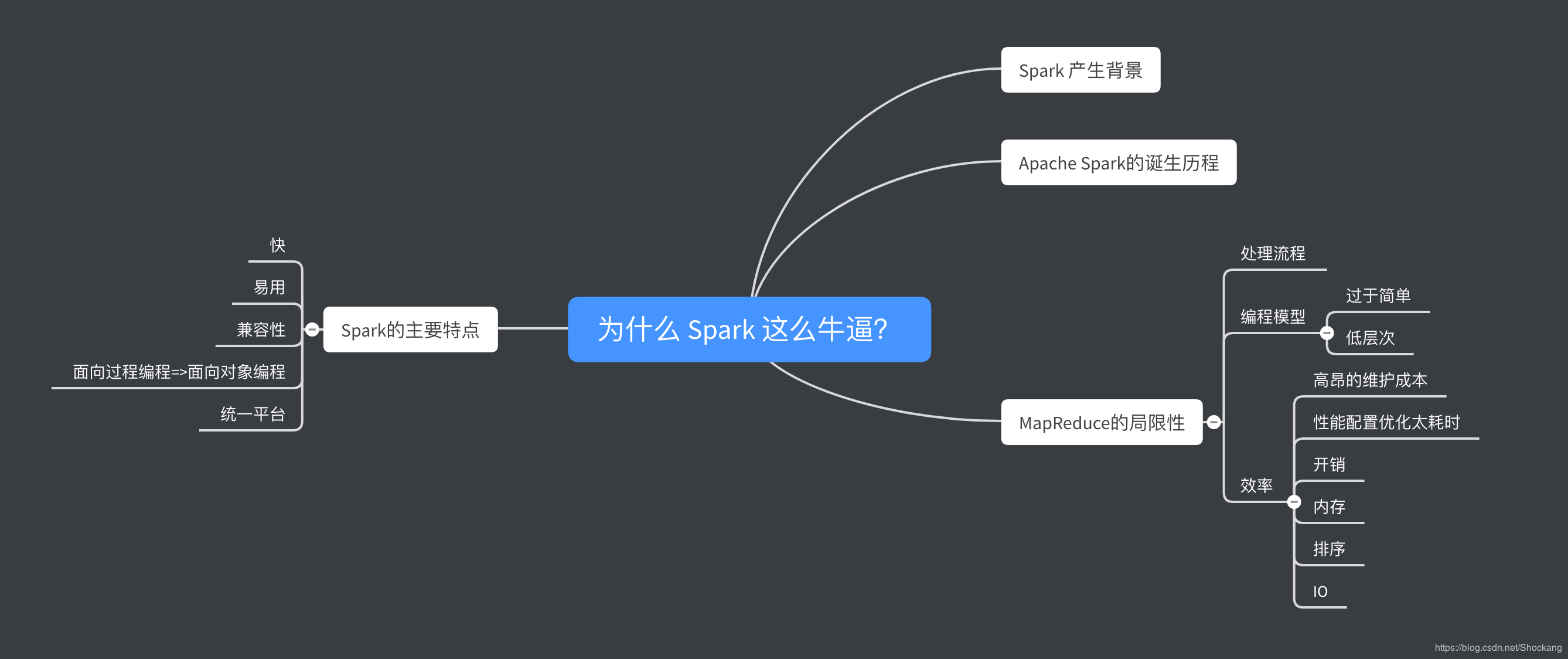
思维导图
照例,先呈上来本文的思维导图,辅助理解。
Spark 产生背景
为什么我们迫切需要用于数据分析的新计算引擎和编程模型?——这是由于计算机应用和硬件技术背后的商业形势变化所导致的。
在计算机发展的很长一段时间内,计算机的性能每年都会因处理器速度的提高而变得更快更好,这段时间,单个处理器已经可以满足我们大数据的需求了。
然而,由于硬盘散热等因素的限制,硬件开发人员放弃了制造更快单个处理器的思路,转而增加更多的相同计算能力的并行 CPU 计算核心。这种变化意味着需要修改应用程序以支持并行计算,以便更快运行,这就促使了 Apache Spark 等新编程模型的出现。
最重要的是,虽然单个处理器性能的增速减缓了,但是数据存储和数据采集技术的发展没有减缓。许多数据采集技术(传感器、摄像头、公共数据集)不断发展,成本在不断下降。这就导致了我们的世界发展成了一个采集数据非常便宜的世界,但是处理它需要大规模的并行计算。但是,过去开发的软件无法自动扩展为并行程序,数据处理领域的传统编程模型也无法自动并行化,因此我们需要一种新的编程模型。
Apache Spark的诞生历程
Apache Spark 来源于加州大学伯克利分校 2009 年的 Spark 研究项目,诞生于 AMPLab 实验室。
当时,Hadoop MapReduce 是运行在计算机集群上的主要并行计算引擎,这是第一个在数千个节点集群上面进行并行数据处理的开源系统。AMPLab 曾与多位早期的 MapReduce 的用户合作,以了解 MapReduce 编程模型的优缺点,针对现实中遇到的各种问题,开始设计更通用更好用的计算平台。
在与 MapReduce 用户的交流中,有两件事得到了确认。
1. 集群计算具有巨大的潜力
2. MapReduce 引擎构建大型应用程序既具有挑战性又显得很低效。
- 比如一个典型的机器学习算法问题,可能需要对数据进行 十几二十次迭代,MR 中,每次迭代都得通过一个 MapReduce 作业来完成,必须在分布式集群上重新读取全部数据并单独启动一次作业。
- 为了解决迭代计算的问题,Spark 团队首先设计了一个基于函数式编程的 API,可以简洁的表达多计算步骤的应用程序,然后,该团队通过一个新的引擎来实现这个 API,这个引擎可以跨多个计算步骤执行高效的内存数据共享。
Spark 最初版本支持批处理应用程序,但是很快发现了另一类重要的应用:交互式数据处理和即席查询(ad-hoc)查询。
即席查询,就是指用户根据自己的需求(这个需求可能是临时产生的),灵活的选择查询条件,系统能够根据用户的选择生成返回响应的结果,例如返回用户自定义的统计报表。
>
即席查询类似于 SQL 查询,只不过 SQL 查询你可以通过索引分区来优化它,即席查询你没办法预先来优化,只能实时的自动来优化。
>
即席查询是评估数据仓库的一个重要指标。
通过简单的将 Scala 解释器插入 Spark,该项目提供了一个高可用的交互式系统。
为了支持即席查询,AMPLab 很快开发了 Shark 系统,这是一个类似于 Hive SQL的系统,只不过将 Hive SQL底层的计算引擎 MR 替换成了 Spark。
(后来出于不再依赖 Hive 的考虑,同时也为了实现一个统一的平台,Spark 将 Shark 交给了 Hive 团队,在 Shark 的基础上研发出了 Spark SQL。)
再然后,AMPLab 认识到,Spark 最强大的功能来自于新的软件库,于是开始遵循当今的”标准库“方法。特别是,AMPLab 中不同的研究组开始开发 MLLib,Spark Streaming和 GraphX。
AMPLab 团队确保这些软件库都具有高度的互操作性,使得人们第一次可以在同一个引擎中编写多种端到端的大数据应用程序。
到 2013 年,这个项目已经得到了广发的应用。AMPLab 作为该项目一个长期的、非商业机构为 Apache 软件基金会贡献了 Spark。Spark 在 Apache 软件基金会只短短孵化了几个月就迅速成为 Apache 软件基金会的顶级项目。
Spark 至此开始展现它独特的气质,光芒万丈!
Spark 是在 MapReduce 的基础上产生的,借鉴了 大量 MapReduce 实践经验,并引入了多种新型设计思想和优化策略。
我们先来总结一下Hadoop MapReduce 计算框架存在的局限性。
MapReduce的局限性
我们主要从 3 个角度来看 MapReduce 的局限性。
处理流程
MR 的处理流程大致上如下图所示
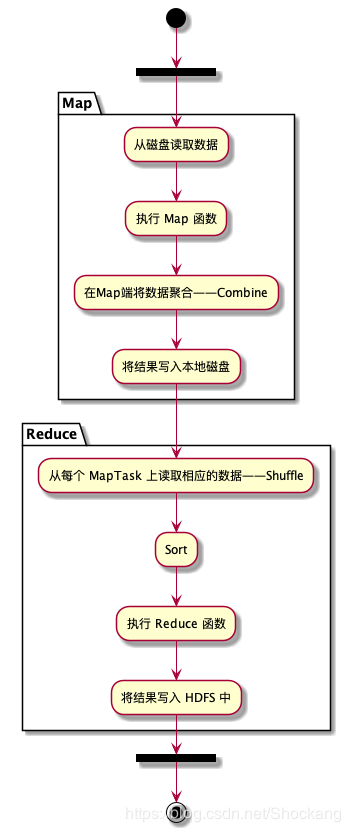
上面的处理流程中有两个子阶段严重降低了性能
- Map阶段产生的中间结果写到了磁盘上,降低了系统性能;
- Shuffle 阶段采用 HTTP 协议从每个 MapTask 上远程复制结果,这种设计思路同样降低了系统性能。
编程模型
简单
- 只提供 Map 和 Reduce 两个操作。实现一个简单的 join,都需要先 Map 再 Reduce 才能处理,这面对错综复杂的大数据场景是远远不够的。
- 着重有四类场景 MapReduce 编程模型显得非常乏力。
- 实时流数据处理。
- 交互式数据处理。
- 即席查询。
- 迭代计算比较多的数据挖掘和机器学习运算。
低层次
- MapReduce 模型的抽象层次低,大量的底层逻辑都需要开发者手工完成。
- 就跟写代码一样,你用 Java,Python 等高级编程语言能搞定的活,非要用汇编语言来写,即使完成一个小功能,都得写上大量代码。
效率
高昂的维护成本
- 每一个 MapReduce 任务都有可能出错,都需要重试和异常处理的机制。
- 协调这些子 MapReduce 的任务往往需要和业务逻辑紧密耦合的状态机。
- 这样过于复杂的维护让系统开发者苦不堪言。
性能配置优化太耗时
- 在 MapReduce 的性能配置优化上需要花费太多时间。
- 包括了缓冲大小 (buffer size),分片多少(number of shards),预抓取策略(prefetch),缓存大小(cache size)等等。
开销
- 任务调度和启动开销大,每个任务运行时都需要启动一个单独的 JVM,用完直接释放了,资源得不到复用。
内存!内存!内存!
- Google MapReduce 发表在 2004 年,当时硬盘便宜内存死贵死贵的,因此,基于磁盘的 MapReduce 能够得到大众的认可,但是十年后就不一样了,内存价格降下来了,基于磁盘的 MapReduce的明显不能满足我们的要求了。
排序
- Map 和 Reduce 端都得排序,对于大量不需要排序的应用来说,无疑增加了额外开销。
IO
- 复杂的 SQL 需要转换成多个 MapReduce 作业计算完成,这些作业之间通过 HDFS 完成数据交换,读写 HDFS 需要消耗大量的磁盘和 网络 IO
Spark的主要特点
快
运行工作负载的速度提高了100倍。下图为Hadoop和Spark中的逻辑回归速度对比,图片来自 Spark 官网。
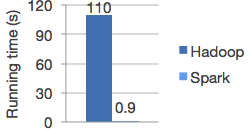
Apache Spark使用最新的DAG调度程序,查询优化器和物理执行引擎,可实现批处理和流数据的高性能。
易用
丰富的 API
- 不像 MapReduce 那样仅仅局限于 Mapper、Partitioner、Reducer 等低级 API,Spark既提供了丰富的 API
- 低层次 API——RDD、累加器、广播变量
- 高层次的结构化 API——DataFrame、DataSet
- 这些 API 都支持函数式编程,能够更好的适应复杂多变的大数据场景。
- 同时高层次 API 由于都带有 Schema,故所有操作都可以享受 Spark SQL Catalyst optimizer 带来的性能提升,如 Code Generation、Tungsten 等。
Spark 支持四种语言的编程 API——Scala/Java/Python/R
代码量更少——实现相同功能模块,Spark 比 MapReduce 少 2~5 倍。
兼容性
Spark可在Hadoop,Apache Mesos,Kubernetes,独立或云中运行。它可以访问各种数据源。

面向过程编程=>面向对象编程
Spark具有面向开发者更友好的编程模型——RDD。
我们知道,大数据计算就是在大规模的数据集上进行一系列的数据计算处理。
MapReduce 针对输入数据,将计算过程分为两个阶段,一个 Map 阶段,一个 Reduce 阶段,可以理解成是面向过程的大数据计算。我们在用 MapReduce 编程的时候,思考的是,如何将计算逻辑用 Map 和 Reduce 两个阶段实现,map 和 reduce 函数的输入和输出是什么,这也是我们在学习 MapReduce 编程的时候一再强调的。
而 Spark 则直接针对数据进行编程,将大规模数据集合抽象成一个 RDD 对象,然后在这个 RDD 上进行各种计算处理,得到一个新的 RDD,继续计算处理,直到得到最后的结果数据。所以 Spark 可以理解成是面向对象的大数据计算。我们在进行 Spark 编程的时候,思考的是一个 RDD 对象需要经过什么样的操作,转换成另一个 RDD 对象,思考的重心和落脚点都在 RDD 上。
统一平台
Spark 的设计理念,即构建一个统一的计算引擎,提供一套统一的 API,支持广泛的数据分析任务,从简单的数据加载,到 SQL查询,再到机器学习和流式计算等。
Spark 不仅支持引擎附带的标准库,同时也支持由开源社区以第三方包形式发布的大量外部库。
今天,Spark 的标准库实际上已经成为了一系列开源项目的集成。
Spark 核心引擎本身变化不大,但是配套的软件库已经越来越强大。
Spark 包括:
Spark SQL(处理结构化数据)
MLLib(机器学习库)
Spark Streaming(流处理库)
Structured Streaming(结构化流处理)
GraphX(图分析)
除了这些库之外,还有数百种开源外部库,包括各种存储系统的连接器和机器学习算法等。
总结
每一项流行性新技术的诞生不仅意味着一个亟待解决的技术难题,同时也是对前人技术的不断总结与创新。
本文先介绍了 Spark 的产生背景,说明了大数据信息时代的背景下急需一个能够实现自动并行处理的编程模型,接着描述了一下Apache Spark 的诞生历程,更方便大家了解 Spark的一些主要功能背后的起源是什么。其次,由于Spark 是在 MapReduce 的基础上发展起来的,我再结合 MapReduce 的局限性来引出 Spark 的主要特点,两相对比,相信能直观的展现 Spark 的各种牛逼之处。
这篇文章是我阅读了诸多书籍、博客专栏后结合个人的心得体会进行的统一汇总梳理。
具体参考的有:
《Spark:权威指南》——Bill Chambers / Matei Zaharia著
《Spark 大数据商业实战三部曲:内核解密|商业案例|性能调优》 -王家林/段智华/夏阳 著
《大数据架构详解-从数据获取到深度学习》-朱洁/罗华霖著
《大数据技术体系详解-原理、架构与实践》-董西成著
《从 0 开始学大数据》-李智慧
《大规模数据处理实战》 -蔡元楠
版权声明: 本文为 InfoQ 作者【Shockang】的原创文章。
原文链接:【http://xie.infoq.cn/article/2856c9014286c172bf1ee3886】。
本文遵守【CC BY-NC】协议,转载请保留原文出处及本版权声明。

大数据开发工程师 2018.10.10 加入
分享大数据开发学习中的心得体会









评论