HBase 分布式部署
发布于: 2021 年 03 月 07 日

1、版本对应(官网地址)
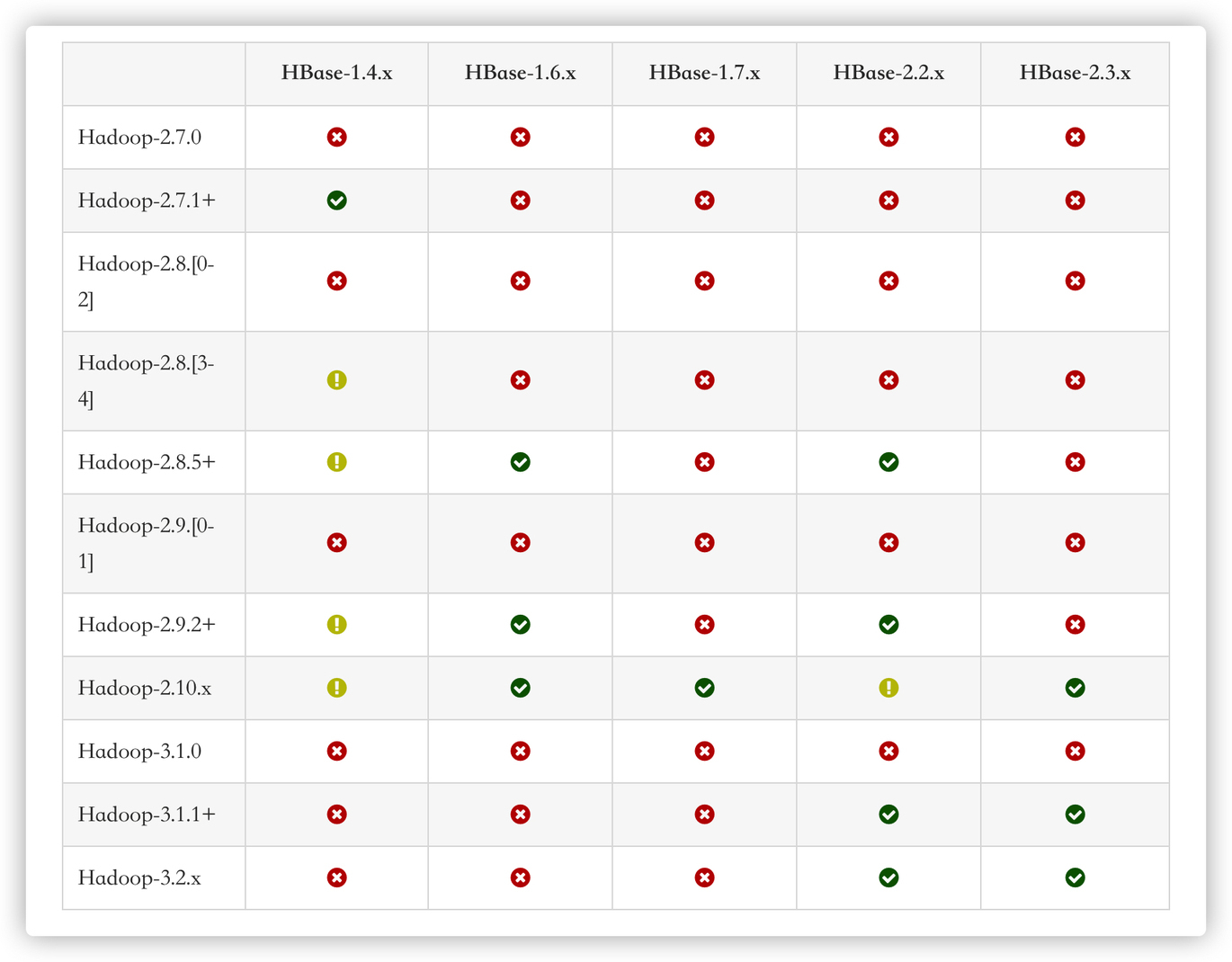
选用版本:hadoop-3.1.4 + hbase-2.3.4 + apache-zookeeper-3.5.9 + java version "1.8.0_181"
2、Hadoop 分布式部署
2.1 部署计划
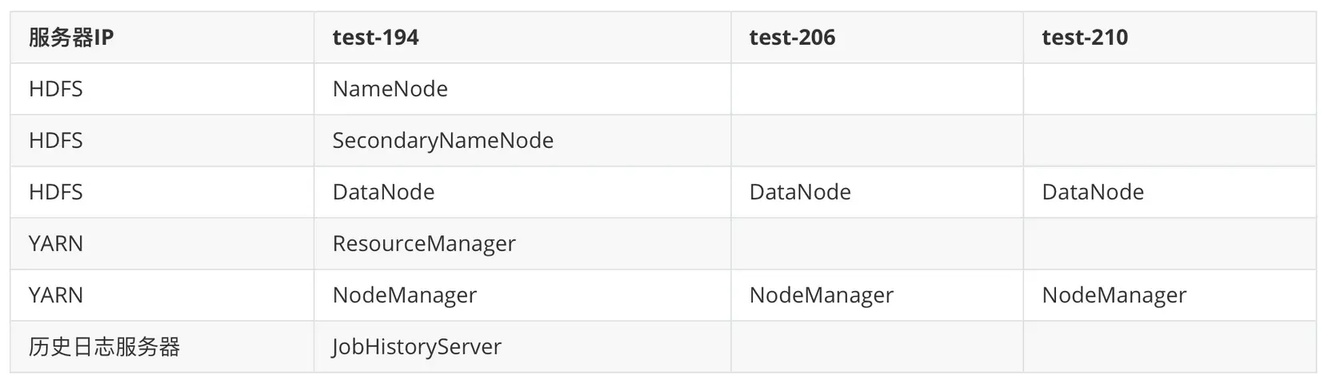
2.2 配置文件
core-site.xml 是全局配置,hdfs-site.xml 和 mapred-site.xml 分别是 hdfs 和 mapred 的局部配置。
core-default.html
<configuration> <!-- 文件系统类型://主机名或ip:端口号 --> <property> <name>fs.defaultFS</name> <value>hdfs://test-194:8020</value> </property>
<!-- 文件存储临时目录(需要创建)--> <property> <name>hadoop.tmp.dir</name> <value>/home/hadoop/data/tmp/</value> </property>
<!-- 缓冲区大小 --> <property> <name>io.file.buffer.size</name> <value>4096</value> </property>
<!-- 开启hdfs垃圾桶机制,删除文件后放到垃圾桶中,10080分钟后清理垃圾桶 --> <property> <name>fs.trash.interval</name> <value>10080</value> </property></configuration>复制代码
hdfs-site.xml
<configuration> <!-- 访问secondary node的地址,主机名:端口 --> <property> <name>dfs.namenode.secondary.http-address</name> <value>test-194:9868</value> </property> <!-- namenode访问地址和端口 --> <property> <name>dfs.namenode.http-address</name> <value>test-194:9870</value> </property> <!-- namenode元数据存放位置(需要自己创建) --> <property> <name>dfs.namenode.name.dir</name> <value>file:///home/hadoop/data/namenodedatas</value> </property> <!-- 定义dataNode数据存储的节点位置,实际工作中,一般先确定磁盘的挂载目录,然后多个目录用,进行分割 --> <property> <name>dfs.datanode.data.dir</name> <value>file:///home/hadoop/data/datanodedatas</value> </property> <!-- namenode日志文件存放目录(editslog) --> <property> <name>dfs.namenode.edits.dir</name> <value>file:///home/hadoop/data/dfs/name-edits</value> </property> <!-- secondarynamenode保存待合并的fsimage --> <property> <name>dfs.namenode.checkpoint.dir</name> <value>file:///home/hadoop/data/dfs/name</value> </property> <!-- secondarynamenode保存待合并的editslog --> <property> <name>dfs.namenode.checkpoint.edits.dir</name> <value>file:///home/hadoop/data/dfs/secondry-edits</value> </property> <!-- 每个文件切片的备份个数(默认为三个) --> <property> <name>dfs.replication</name> <value>3</value> </property> <!-- hdfs的文件权限 --> <property> <name>dfs.permissions.enabled</name> <value>false</value> </property> <!-- 设置一个文件切片的大小:128M --> <property> <name>dfs.blocksize</name> <value>134217728</value> </property></configuration>复制代码
hadoop-env.sh
export JAVA_HOME=/usr/local/jdk
export HADOOP_SSH_OPTS="-p 56789"复制代码
mapred-env.sh
export JAVA_HOME=/usr/local/jdk复制代码
mapred-site.xml
<configuration> <!-- --> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <!-- 开启mapreduce的小任务模式 --> <property> <name>mapreduce.job.ubertask.enable</name> <value>true</value> </property> <!-- 设置历史任务的主机和端口 --> <property> <name>mapreduce.jobhistory.address</name> <value>test-194:10020</value> </property> <!-- 通过网页访问历史任务的主机和端口 --> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>test-194:19888</value> </property> <property> <name>yarn.app.mapreduce.am.env</name> <value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value> </property> <property> <name>mapreduce.map.env</name> <value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value> </property> <property> <name>mapreduce.reduce.env</name> <value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value> </property></configuration>复制代码
yarn-site.xml
<configuration> <!-- 配置yarn.resourcemanager的主机名 --> <property> <name>yarn.resourcemanager.hostname</name> <value>test-194</value> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <!-- 如果vmem、pmem资源不够,会报错,此处将资源监察置为false --> <property> <name>yarn.nodemanager.vmem-check-enabled</name> <value>false</value> </property> <property> <name>yarn.nodemanager.pmem-check-enabled</name> <value>false</value> </property></configuration>复制代码
workers
test-194test-206test-210复制代码
创建对应目录
mkdir -p /home/hadoop/data/tmp/mkdir -p /home/hadoop/data/namenodedatasmkdir -p /home/hadoop/data/datanodedatasmkdir -p /home/hadoop/data/dfs/name-editsmkdir -p /home/hadoop/data/dfs/namemkdir -p /home/hadoop/data/dfs/secondry-edits复制代码
环境变量
export HADOOP_HOME=/home/hadoopexport PATH=:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH复制代码
2.3 启动集群
(主节点上执行以下命令)
start-dfs.shstart-yarn.sh# 已过时mr-jobhistory-daemon.sh start historyservermapred --daemon start historyserver复制代码
停止集群
stop-dfs.shstop-yarn.sh # 已过时 mr-jobhistory-daemon.sh stop historyservermapred --daemon stop historyserver复制代码
逐个启动
# 在主节点上使用以下命令启动 HDFS NameNode: # 已过时 hadoop-daemon.sh start namenode hdfs --daemon start namenode
# 在主节点上使用以下命令启动 HDFS SecondaryNamenode: # 已过时 hadoop-daemon.sh start secondarynamenode hdfs --daemon start secondarynamenode
# 在每个从节点上使用以下命令启动 HDFS DataNode: # 已过时 hadoop-daemon.sh start datanodehdfs --daemon start datanode
# 在主节点上使用以下命令启动 YARN ResourceManager: # 已过时 yarn-daemon.sh start resourcemanager yarn --daemon start resourcemanager
# 在每个从节点上使用以下命令启动 YARN nodemanager: # 已过时 yarn-daemon.sh start nodemanager yarn --daemon start nodemanager
#以上脚本位于$HADOOP_HOME/sbin/目录下。如果想要停止某个节点上某个角色,只需要把命令中的start 改为stop 即可。复制代码
检验节点
[root@test-194 ~]# jps14627 SecondaryNameNode14915 ResourceManager15636 Jps14405 DataNode15447 JobHistoryServer15033 NodeManager14283 NameNode
[root@test-206 ~]# jps5832 Jps5611 NodeManager5455 DataNode
[root@test-210 ~]# jps21073 Jps13201 DataNode13663 NodeManager复制代码
3、Zookeeper 部署
zookeeper:开源分布式协调服务框架,主要解决分布式系统中的一致性和数据管理问题。
本质上是分布式文件系统,适合存放小的文件(最好不超过 1M),也可以理解为数据库(存放配置文件)。
端口号:详情
3888:选举 Leader。
2888:集群内的机器通讯使用。(Leader 使用此端口)
2181:对 Client 端提供服务的端口。
1、解压文件
[root@test-194 file]# tar -zxvf apache-zookeeper-3.5.9-bin.tar.gz -C /home/复制代码
2、同步时钟
[root@test-194 ~]# ntpdate time1.aliyun.com[root@test-206 ~]# ntpdate time1.aliyun.com[root@test-210 ~]# ntpdate time1.aliyun.com复制代码
3、zoo.cfg 配置文件
tickTime=2000initLimit=10syncLimit=5dataDir=/home/zookeeper/zkdatasclientPort=2181
#保留多少个快照(默认3)autopurge.snapRetainCount=3
#日志多久清理一次(默认1h)autopurge.purgeInterval=1
#服务器集群地址mid.1=node01:端口1:端口2server.1=test-194:2888:3888server.2=test-206:2888:3888server.3=test-210:2888:3888复制代码
4、添加 mid
#创建zkdatas目录mkdir -p /home/zookeeper/zkdatasecho 1 > /home/zookeeper/zkdatas/myid复制代码
5、启动 zookeeper
#启动zookeeper./bin/zkServer.sh start
#查看zookeeper状态[root@test-194 zookeeper]# ./bin/zkServer.sh status/usr/local/jdk/bin/javaZooKeeper JMX enabled by defaultUsing config: /home/zookeeper/bin/../conf/zoo.cfgClient port found: 2181. Client address: localhost. Client SSL: false.#从Mode: follower#主Mode: leader复制代码
4、HBase 部署
1、解压安装包
[root@test-194 file]# tar -zxvf hbase-2.3.4-bin.tar.gz -C /home/复制代码
2、配置文件
regionservers
test-194test-206test-210复制代码
hbase-env.sh
#jdk环境变量export JAVA_HOME=/usr/local/jdk/#不使用内置zookeeperexport HBASE_MANAGES_ZK=false#ssh端口export HBASE_SSH_OPTS="-p 56789"复制代码
hbase-site.xml
<configuration>
<!-- 本地文件系统 的临时文件夹(重新启动计算机将清空 /tmp目录) --> <property> <name>hbase.tmp.dir</name> <value>./tmp</value> </property> <!-- hbase根目录 --> <property> <name>hbase.rootdir</name> <value>hdfs://test-194:8020/hbase</value> </property> <!-- 分布式(false表示单机模式) --> <property> <name>hbase.cluster.distributed</name> <value>true</value> </property> <!-- zookeeper集群 --> <property> <name>hbase.zookeeper.quorum</name> <value>test-194,test-206,test-210</value> </property> <!-- zookeeper工作目录 --> <property> <name>hbase.zookeeper.property.dataDir</name> <value>/home/zookeeper/zkDatas</value> </property> </configuration>
<!-- 默认端口(0.98以前是60000,可以不配置) --> <property> <name>hbase.master.port</name> <value>16000</value> </property>
<!-- hbase master的web UI页面端口(默认16010,可以不配置) --> <property> <name>hbase.master.info.port</name> <value>16010</value> <description>the port for the hbase master web UI set to -1 if you do not wan a UI instance run </description> </property>复制代码
制作 Hadoop 配置文件的软连接
ln -s /home/hadoop/etc/hadoop/core-site.xml /home/hbase/conf/core-site.xmlln -s /home/hadoop/etc/hadoop/hdfs-site.xml /home/hbase/conf/hdfs-site.xml复制代码
3、启动 HBase
/home/hbase/bin/start-hbase.sh复制代码
5、最终检验
[root@test-194 ~]# jps12096 QuorumPeerMain17314 Jps16706 HMaster14627 SecondaryNameNode14915 ResourceManager14405 DataNode15447 JobHistoryServer15033 NodeManager16202 HRegionServer14283 NameNode
[root@test-206 ~]# jps4932 QuorumPeerMain5911 HRegionServer5611 NodeManager6175 Jps5455 DataNode
[root@test-210 ~]# jps13201 DataNode1188 Jps3976 QuorumPeerMain25914 HRegionServer13663 NodeManager复制代码
划线
评论
复制
发布于: 2021 年 03 月 07 日阅读数: 18
版权声明: 本文为 InfoQ 作者【Fong】的原创文章。
原文链接:【http://xie.infoq.cn/article/23f2f1194455fde7569941459】。文章转载请联系作者。

Fong
关注
还未添加个人签名 2019.10.16 加入
还未添加个人简介









评论