Apache Doris 在 WeLab 实时大数据平台的应用实践

1、概述
WeLab 是业内领先的金融科技公司。我们以定制化服务的方式为合作伙伴提供金融智能解决方案,帮助合作伙伴实现金融科技创新。WeLab 拥有独创的风险管理技术,可以高效地整合和分析移动端大数据,并对用户的风险进行定级,高效地输出决策。为了实现秒级决策,我们对数据处理的实时性,准确性和安全性都有很高的要求。Apache Doris 数据库就是在这样的背景下被引入到我们大数据平台中来的,并最终成为了我们大数据平台的重要基石之一。
WeLab 的实时大数据平台是一套包含了数据实时采集、存储、集成、挖掘、分析和可视化的综合性大数据平台。它具有管理自动化、流程化、规范化、智能化等特点,并能够支撑更轻量、灵活、低门槛并快速迭代的大数据应
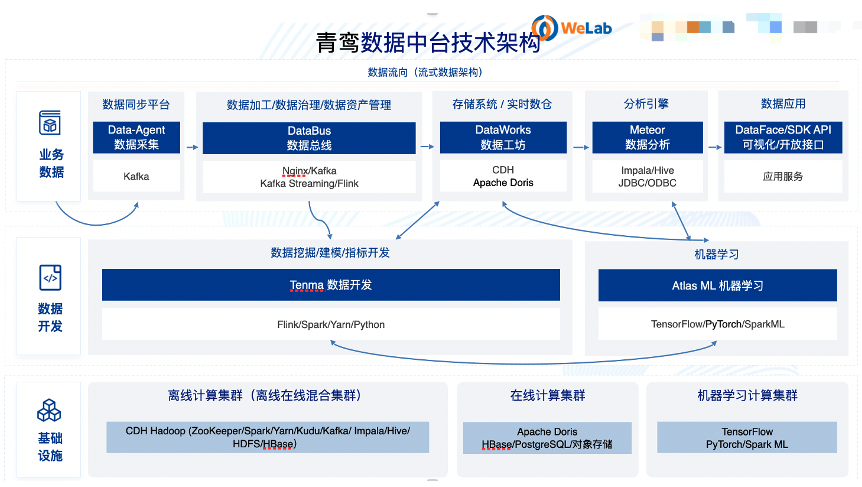
在这个大数据平台体系中,Apache Doris 主要支撑了两个重要的场景:实时自助 BI 报表和用户运营分析。
2、实时自助 BI 报表
在大数据平台建设初期,我们完全依赖 Hadoop 技术生态,利用离线计算提供分析服务。但是 Hadoop 技术栈对实时性支持得不够好,而且基于 Hadoop 技术栈开发报表成本比较高,不够灵活。
另一方面,在这个时期,报表的输出都是以传统 BI 的模式提供的,但是传统 BI 部署开发周期较长,需进行整体的架构设计,各个模块均需要进行技术开发。在这种模式下,新需求的开发也非常耗时,IT 部门负担较重。从这种大数据分析输出的效果来看,运营人员无法实时地通过数据来分析用户的行为路径,也就无法迅速地在产品,业务上做出相应的对策。
为了解决上述两个问题,我们一方面希望引入能够进行实时数据分析的技术方案,另一方面希望能用自助 BI 来替代传统 BI。自助 BI 比传统 BI 更加的灵活且易于使用,非 IT 背景的业务分析人员也可以方便使用,可以更好地满足用户的数据分析需求。
我们的升级工作从调研市面上的各种 MPP 执行引擎开始。我们一共调研了 Kudu+Impala,Greenplum 和 Apache Doris 三种 MPP 执行引擎,具体结果如下。
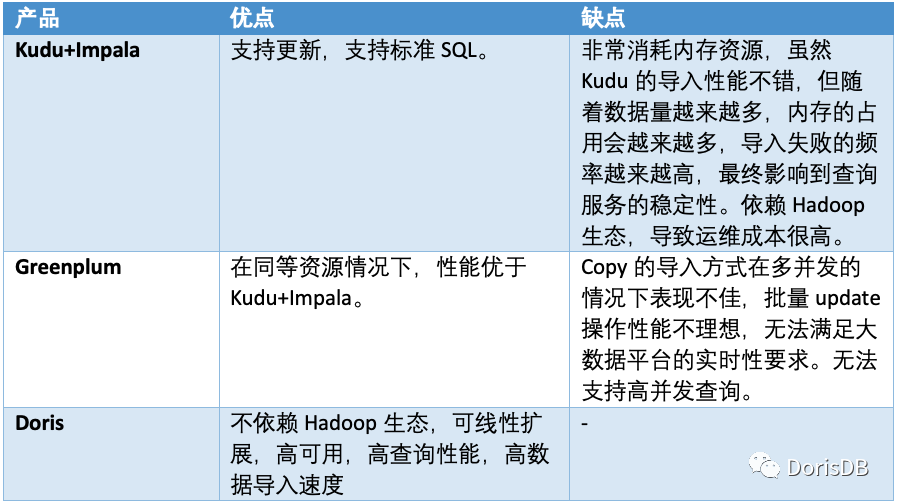
经过全面的对比分析,我们最终放弃了 Kudu+Impala 和 Greenplum,决定使用 Doris 来作为实时大数据平台的底层存储。
2.1 数据表设计
利用 Doris 的多种数据模型,我们的事件表和维度表设计方案如下。
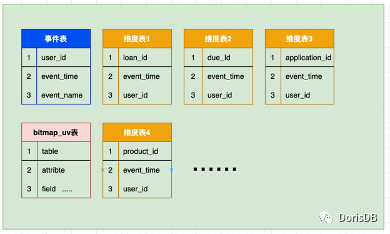
事件表: Duplicate 模型。Duplicate 模型没有主键,可根据指定字段,数据可重复。
Bitmap_uv 表:Aggregate 模型。聚合模型需指定聚合字段。
维度表: Uniq 模型。设定 key,具有唯一性。可进行覆盖数据操作。
以上这个设计是非常简单的,有别于传统数仓中多层级表的设计理念。通过这样的轻便设计,一旦业务方有分析需求,只需在数据总线的界面操作配置好,把业务方的表数据同步到 doris 中。然后通过自助分析就可以轻松得到报表的相关结果。
2.2 建表和查询
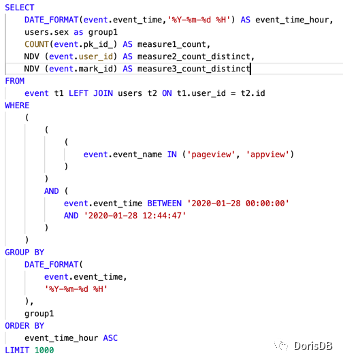
以下是一个事件表的建表例子。

通过自助 BI 界面,只需要进行拖拉拽,就能转化成底层 SQL。以下是一个通过自助 BI 生成的底层 SQL 例子。
2.3 实践经验
在基于 Doris 构建上述实时报表的过程中,我们总结了一些 Doris 的使用经验。
1. 分区与分桶。Doris 中,通过关键字 Partitiion 进行分区,通过关键字 Distributed 进行分桶。分区分桶的关键字都必须先定义在建表模型的 key 里面。分区分桶很好地优化了大表查询性能。不过选择什么字段作为分区分桶字段是需要考虑的。假如在一个 sql 中,条件里如果没有命中分区字段,分桶字段,那么查询性可能会大打折扣的。再提一点的是,Doris 很好地支持了动态分区功能,这对于开发人员来说是非常友好的。而 Kudu 的分区只能手动的。
2. 前缀索引。上文的建表脚本最前面的字段是 event_name,event_time,user_id。那是因为这几个字段都是经常作为查询的条件字段,这样的建表方式有利于前缀索引发挥作用。在 Aggregate、Uniq 和 Duplicate 三种数据模型中。底层的数据存储,是按照各自建表语句中,AGGREGATE KEY、UNIQ KEY 和 DUPLICATE KEY 中指定的列进行排序存储的。
3. 并发数。如果在实践中发现 SQL 查询性能不佳,并且观察到机器的 cpu 利用率不高,可以尝试调节分桶数,并发数。并发数 = (分桶数 * 分区数) / 机器数,相应地设置“parallel_fragment_exec_instance_num”这个参数。
4. Colocate Join。Doris 支持多种分布式 Join 的方式,不仅支持 Broadcast Join、Shuffle Join,还支持 Colocate Join。相比 Shuffle Join 和 Broadcast Join,Colocate Join 在查询时没有数据的网络传输,性能会更高。在 Doris 的具体实现中,Colocate Join 相比 Shuffle Join 可以拥有更高的并发粒度,也可以显著提升 Join 的性能。详情可参考(https://blog.bcmeng.com/post/doris-colocate-join.html#why-colocate-join)。
2.4 性能测试
以下是我们结合自身的场景对 Doris 进行性能测试的结果。
1. 创建事件表 5000W,用户表 4000W 进行关联查询
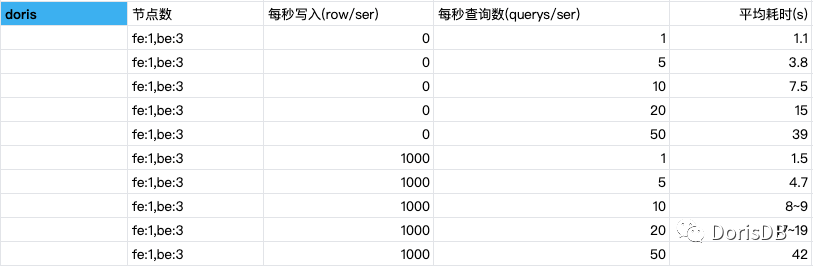
2. 调整参数,tc_use_memory_min=21474836480,chunk_reserved_bytes_limit=21474836480,移除 sql 的 order by

3. Collocate Join

4. 提升机器配置,8C->16C
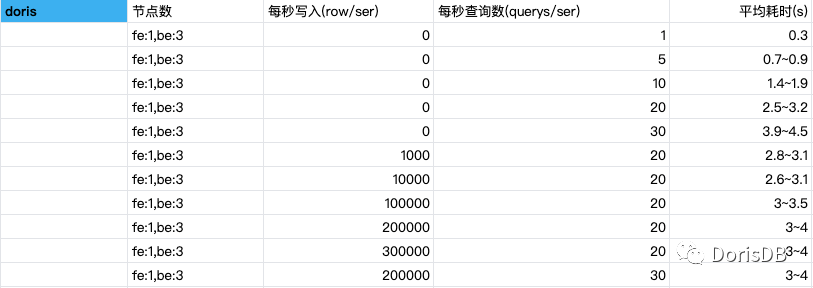
以上的验证,分别通过改变 sql 语法,调整相关参数,使用 Collocate Join,匹配前缀索引,甚至提升机器配置的方式提升了 sql 查询的性能。后面的测试都是在并发导入的同时对查询进行压测。从测试结果看,Doris 引擎的查询能力是非常优秀的。
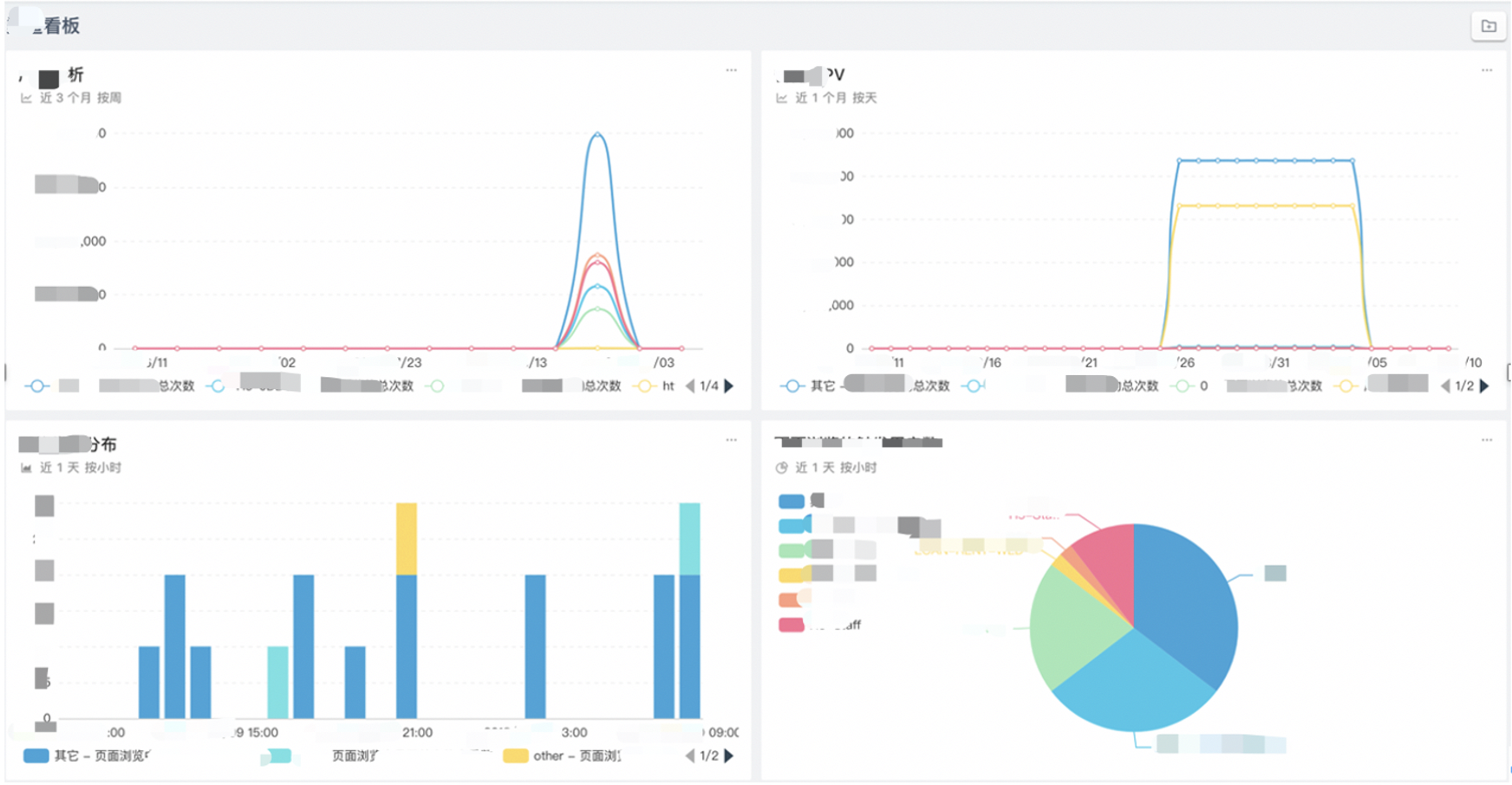
2.5 报表展示
基于 Doris 优秀的查询能力,我们自助 BI 系统建设变得非常容易。下图是 WeLab 最终实现的自助 BI 分析系统的截图。通过这个分析系统,业务人员只需要几分钟,就可以看到出他们想要的数据分析结果。不论是从开发成本,维护成本,还是快速分析带来的业务收益来看,实时自助 BI 报表对业务的价值都是十分显著的。
3 在线用户运营
众所周知,获客成本高是当今困扰各类互联网金融 APP 的一个重大问题。目前应对该问题的最好方法是对用户行为进行有效的分析,探索不同用户的关键行为,洞察指标背后的增长点。并通过事件、留存、漏斗、用户画像等相关模型追踪用户行为,用数据指引产品改进方向,并快速验证。

在用户行为分析中,以用户行为转化模型(如:漏斗,留存率等)的建立和计算最为关键,也最为复杂。WeLab 实时大数据平台在计算用户行为转化模型上,经历过几个阶段:离线计算阶段、Hbase 阶段和目前的 Doris 阶段。
3.1 离线计算阶段
上文已经提到,在大数据平台建设初期,我们是完全通过 Hadoop 大数据技术的生态来进行用户行为模型的计算的。当时我们把数据存放在 HDFS 上,然后通过 MR 来计算用户行为的转化结果,以此实现漏斗,留存等转化模型。
这种方式的最大问题是时效性很差,一般都是“T+1”的交付方式,对于运营人员来说,他们无法快速观察用户使用产品的情况,也就降低了对产品优化的效率。
3.2 Hbase 阶段
为了增加用户行为转化的时效性,我们参考了大量的资料,其中包括美团分享的《每天数百亿用户行为数据,美团点评怎么实现秒级转化分析?》(https://tech.meituan.com/2018/03/20/user-funnel-analysis-design-build.html)。通过对各种案例的调研,我们发现使用 bitmap 计算用户转化相关的分析模型是比较好的方案。但当时我们没有调研到有支持 bitmap 结构的大数据存储,所以我们基于 hbase,通过它独有的结构,构造出一个伪 bitmap 的数据结构。
这种方式需要对 Hbase 的 Rowkey 进行特殊处理,需要用表名、字段、值、时间 4 个要素组合形成 Rowkey,再通过序列变为字节存放。这样便可以对任意维度定义为标签,把用户 ID 作为 column 来存放。界面可以实现随意选择字段,值作为条件过滤用户。但 hbase 本身不支持 bitmap 的交集运算,所以必须把数据先加载到 java 内存,转换为 RoaringLongBitmap 模型,最后才可以进行各种用户转换的计算。
但这种方式在后期遇到了很大的性能问题。随着 Scan Rowkey 量的变大,value 创建的 column 也会变得越来越多,最后必须通过优化 column 数目来优化性能。每次查询时,都需要把大量数据先加载到内存后进行 bit 运算,非常消耗内存资源。
3.3 Doris 阶段
为了解决 Hbse 方案的性能问题,我们继续调研支持 Bitmap 数据结构的开源大数据存储系统。非常巧的是,在我们寻找新的 MPP 执行引擎的同时,发现了 Apache Doris 是支持 bitmap 结构的。通过调研,并参考了美团工程师分享文章《Apache Doris 基于 Bitmap 的精确去重和用户行为分析》(https://blog.bcmeng.com/post/doris-bitmap.html#a-store-about-bitmap-count-distinct)中的设计思路,我们对平台的用户转化分析功能进行了重构。
具体来说,我们的工作分为:建表,数据导入、数据格式转换、SQL 查询几个步骤。
3.3.1 建表
我们的表结构参考了 Hbase Rowkey 的设计,保留了表、字段、值、时间等主要要素。建表脚本如下:

3.3.2 数据导入
Doris 支持多种数据导入方式(具体可以参考 Doris 的官方文档),在我们的场景中,我们采用的是 Stream Load 的方式。因为我们数据仓库的设计是先由上游各个业务层的数据存储,包括关系型数据库、日志、MQ 等多种数据来源,统一订阅到数据总线,经过加工、清洗,再由数据工坊写入到指定的大数据存储。Stream Load 的原理是通过 http 的方式导入数据,这样可以很好地适配到数据工坊统一写入存储的接口。
Stream Load 的性能是非常卓越的,符合我们大数据平台所需要的实时性要求。以下是我们对 Doris 做的应用层导入性能测试结果。
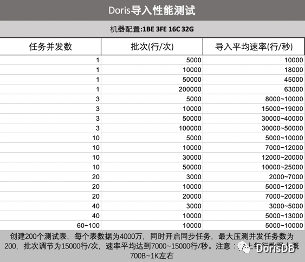
从测试的结果可以看出,Stream Load 的导入性能受到几方面因素的影响,包括每次导入的数据量、导入任务的并发数、机器配置等。为了把导入性能发挥到极致,必须要结合实际情况对这几方面因素进行必要的调整。
不过,对于我们平台而言,把数据缓存到内存,再调用 Stream Load 的方式会有一些缺点。例如,数据会先积攒在 java 内存,再写入到 Doris。那么当任务数越来越多,批次越来越大,整体消耗的内存会越来越大,可能会导致 OOM。所以建议在线上使用之前,先模拟一个生产环境的数据体量,进行性能测试,得出性能指标作为参考。
3.3.3 数据转换
导入的数据是按行存储的,例如,事件表的一行数据里,包含了用户的名称、国家、年龄、性别等字段,这些字段对应值都可以成为一个标签。在数据转换时需要将每行数据中的不同列,转换成对应 bitmap 结构中的信息,然后再导入对应的 Doris 表中。
3.3.4 SQL 查询
最后,通过 sql 查询就可以实现在数据存储底层完成 bitmap 的交集运算。以下是我们进行交集运算的一个例子。

Doris 引擎的 bitmap 查询性能优越,基本都是秒级出结果。在功能方面,bitmap 还有可以加强的地方。例如,在 bitmap 的查询 API 中没有可以按列表形式返回 bitmap 中用户 ID 的方法。只有一个“BITMAP_FROM_STRING”方法,可以把 bitmap 转换为字符串形式。但字符串是不能直接通过 sql 查询返回的,因为有可能 bitmap 的用户数量非常的庞大,可能有上千万甚至上亿的数量级。如果以列表的形式,则可以通过分页截取用户 ID 列表大小,然后反查用户明细到前端展示,有利于运营追踪用户详情。
4 总结
本文讲述了 WeLab 实时大数据平台是如何整合 Apache Doris 引擎,以及我们是如何思考和处理在平台搭建中遇到的一些问题的。
在平台的不断演进中,我们意识到,Hadoop 生态固然是大数据技术的基石。但随着技术的发展,hadoop 生态的开发成本,运维成本,很难满足现今互联网日新月异的业务快速迭代需求。其实并不是所有公司都适合 hadoop 这种庞大的大数据生态。
MPP 引擎代表了大数据未来发展的一种趋势。其中 Apache Doris 是 MPP 引擎的优秀代表。MPP 架构的最原始想法是消除共享资源,每个执行器有单独的 CPU,内存和硬盘资源。一个执行器无法直接访问另一个执行器上的资源,除非通过网络上的受控的数据交换。这种架构较完美地解决了可扩展性的问题。
但无论是哪种技术都不是完美的,任何技术必须不断进步,不断发展,才能更好地满足用户的需求,才能真正体现技术的价值。希望各位技术人一起努力,继续推进伟大的技术发展。
作者:黄文威,WeLab 架构工程师

最好的国产MPP分析型数据库 2020.08.08 加入
还未添加个人简介









评论