分布式缓存
1、缓存是什么?
缓存:存储在计算机上的一个【原始数据】的【复制集(数据的拷贝)】,以便于访问;
缓存是介于数据访问者和数据源之间的一种【高速存储】,当数据需要【多次读取】的时候,用于加快读取速度;
2、为什么需要缓存?
数据写入缓存的为了【多次读取】,提升经常访问数据的读取速度,如 缓存;
如果不是【多次读取】,使用缓存的意义不大;
3、缓存的分类
3-1、通读缓存(read-through)
客户端访问【通读缓存】,如果通读缓存中没有数据,则【通读缓存】直接去查询数据,而不需要再通过客户端访问;
通读缓存给客户端返回缓存资源,并在请求未命中缓存时获取实际数据;
客户端连接的是【通读缓存】而不是生产响应的原始服务器;
客户端看不到数据源,缓存代理数据源;
通读缓存有:
代理与反向代理缓存;
CDN 缓存;
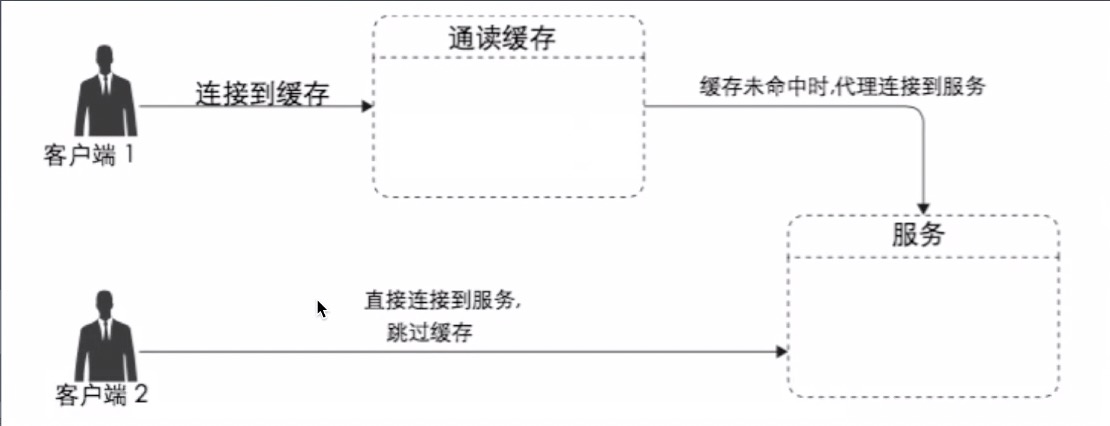
3-2、旁路缓存(cache-aside)
客户端同事连接缓存和服务;
对象缓存是一种旁路缓存,旁路缓存通常是一个独立的键值对(key-value)存储;
应用代码通常会询问对象缓存需要的对象是否存在,如果存在,它会获取并使用缓存对象,如果不存在或已过期,应用会连接主数据源来组装数据,并将其保存回对象缓存中以便将来使用;

常见的旁路缓存:
数据库缓存:哈希索引;
前端缓存;
应用程序缓存;
分布式对象缓存;
4、缓存数据存储
4-1、缓存的数据结构
4-1-1、缓存的存储
缓存一般使用【内存】作为实现【高速读取】的物理存储;
4-1-2、哈希表
1、背景
在百万、千万或者亿级的数据,如何【快速查找】想要访问的数据?
2、这里建议使用【哈希表】的数据结构
时间复杂度为 O(1);
哈希表的本质是一个数组,只要给定数组的下标,就可以对数据进行随机访问;
数组的下标存放数据的地址;
哈希表的数组大小可以无限大,只要内存足够大?
哈希表的结构如下:
3、哈希表的访问过程
(1) 计算 Key 值的 HashCode,在 Java 中,Integer 和 String 类型都重写了 hashCode() 方法,在 HashMap 等结构中,判断一个 key 是否存在,或者 get 某个 key 的值,都依赖 key 的 hashCode() 方法,因此一般都建议使用【包装类型】或者字符串 String 作为 Map 的 key;
(2) 根据 HashCode 值,用哈希表的数组长度作为除数,即 HashCode mod 数组长度 取模,取模后的结果就是 Key 在哈希表中的地址;
(3) 哈希表中存放的值不是对象的 Value,而是对象存放的地址指针,根据地址指针获取实际的对象;
(4) 不同的 Key 取模后的地址可能出现一样,这个现象称之为【冲突(collision)】,Java 中 HashMap 和 ConcurrentHashMap 使用 链表或红黑树 来解决 Hash 冲突的问题;
4-2、缓存的关键指标
4-2-1、缓存命中率
缓存是否有效依赖于能多少次重用同一个缓存响应业务请求,整个度量指标被称作缓存命中率;
如果查询一个缓存,10 次查询 9 次能够得到正确结果,那么它的命中率是 90%;
缓存一次写入,多次读取,提升缓存的效果;
影响缓存命中率的主要指标:
缓存健集合大小;缓存中每个对象使用【键值】进行识别,定位一个对象的【唯一方式】就是对缓存键执行精确匹配;例如:电商为每个商品缓存信息,需要使用商品 ID 作为缓存键;一定要想办法减少缓存键的数量;缓存键越少,缓存的效率越高;这里是指键的范围;
缓存可使用内存空间;缓存可使用内存空间直接决定缓存对象的平均大小和缓存对象数量;因为缓存通常存储在内存中,缓存对象可用空间【受到严格限制且相对昂贵】;物理上缓存的对象越多,【缓存命中率就越高】;这里指装载的数据量;
缓存对象生存时间;缓存对象生存时间为 TTL(Time To Live);缓存的时间越长,缓存对象被重用的可能性就越高;例如 图片文件;
总结:
提升缓存的命中率,首先缓存的 key 尽量少,存储的数据尽量多,缓存的时间较长;
4-3、缓存类型
4-3-1、代理缓存
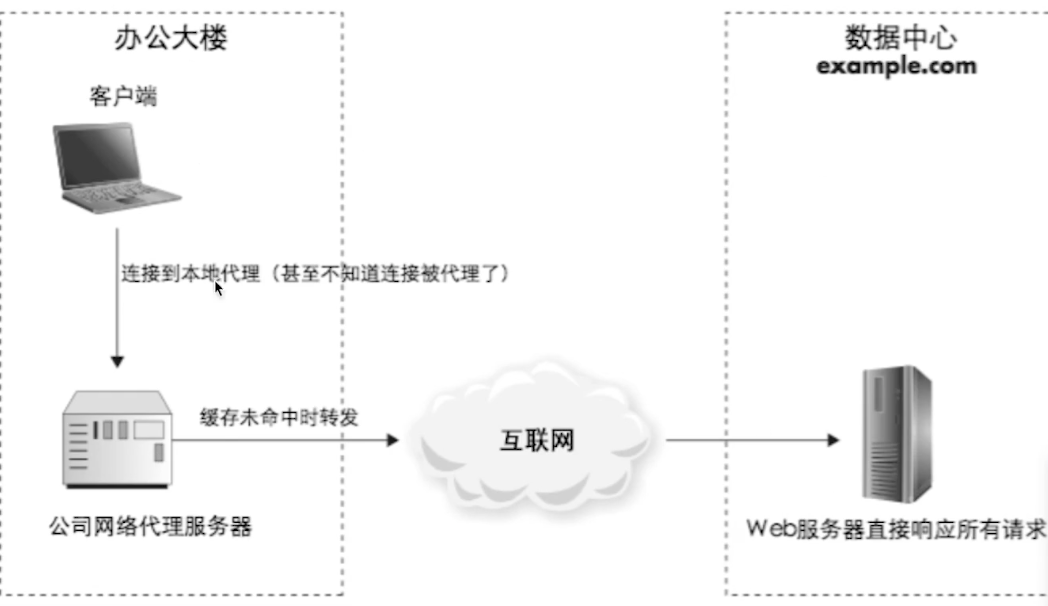
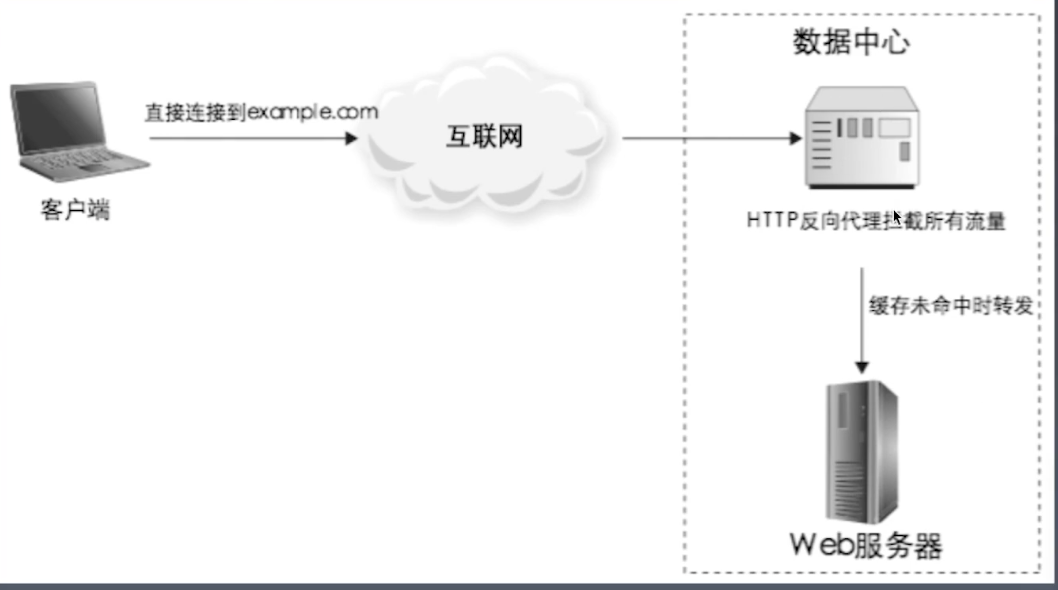
4-3-2、反向代理缓存
代理数据中心对外输出;
一般 URL 是 key,URL 对应的资源是 value;
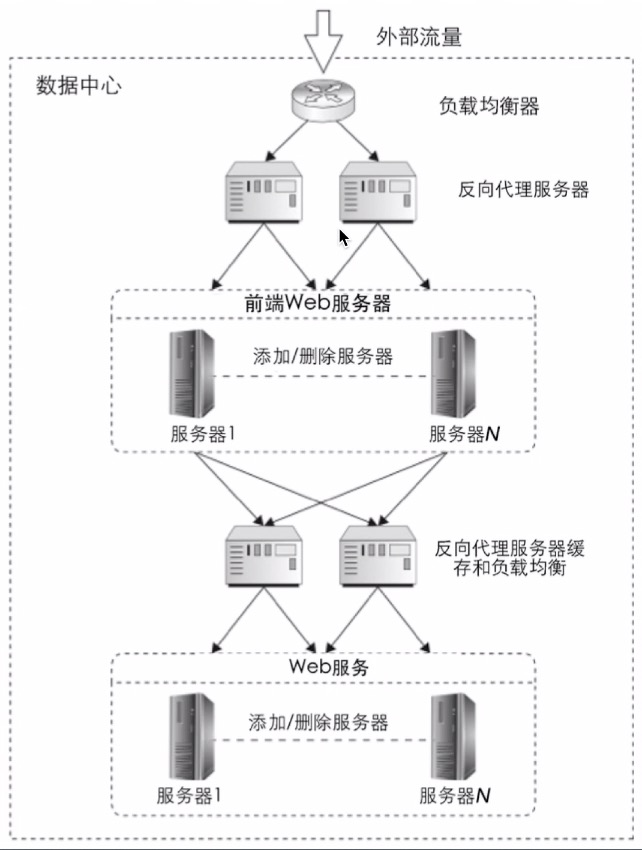
4-3-3、多层反向代理缓存
例如根据用户 ID,缓存用户信息,不需要查询数据;
对于 Restful 风格的接口很友好,在请求 URL 中可以提取缓存的 key,从而对 key 进行缓存直接获取 Value;
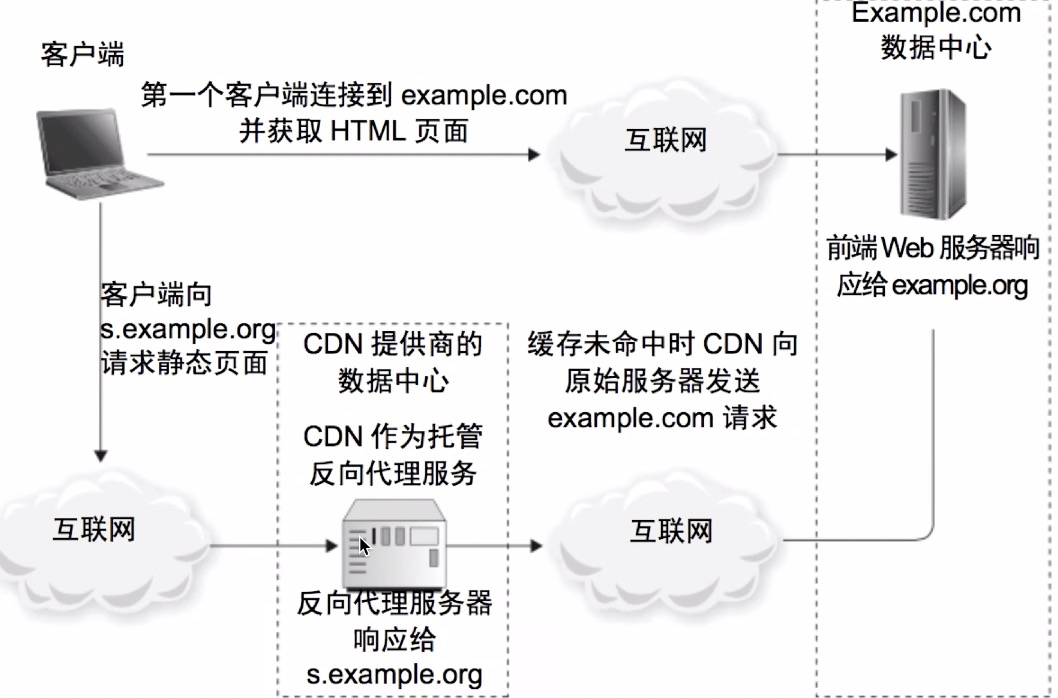
4-3-4、内容分发网络(CDN)
用户请求 URL,如果是动态域名,DNS 直接访问数据中心;如果是静态域名,则先请求【CDN 服务器】,如果 CND 服务器中有对应数据,则直接返回,如果【CDN 服务器】没有命中缓存,再请求数据中心;
优点:
速度快;
减少数据中心的请求压力;
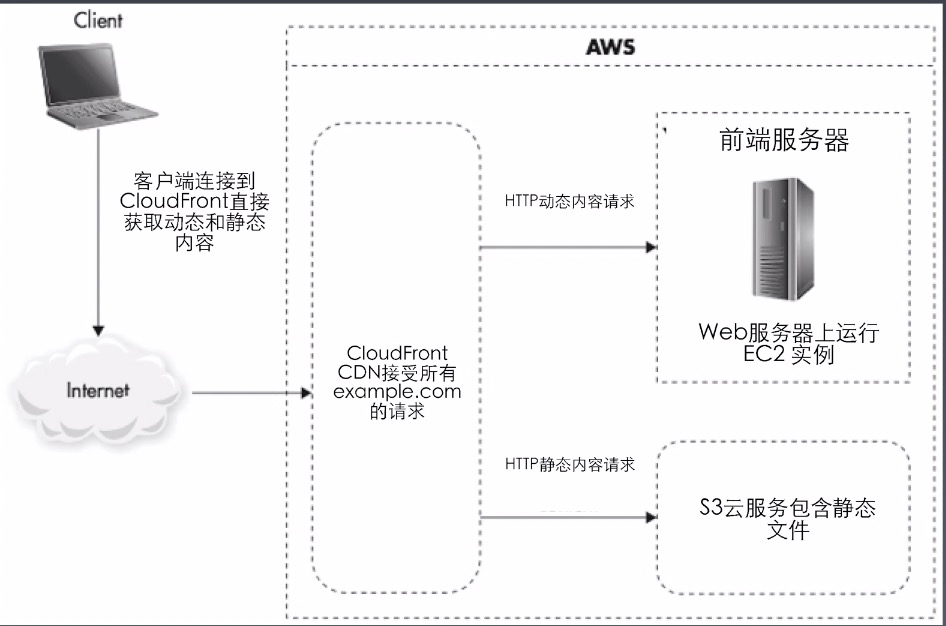
CDN 同时配置静态文件和动态文件
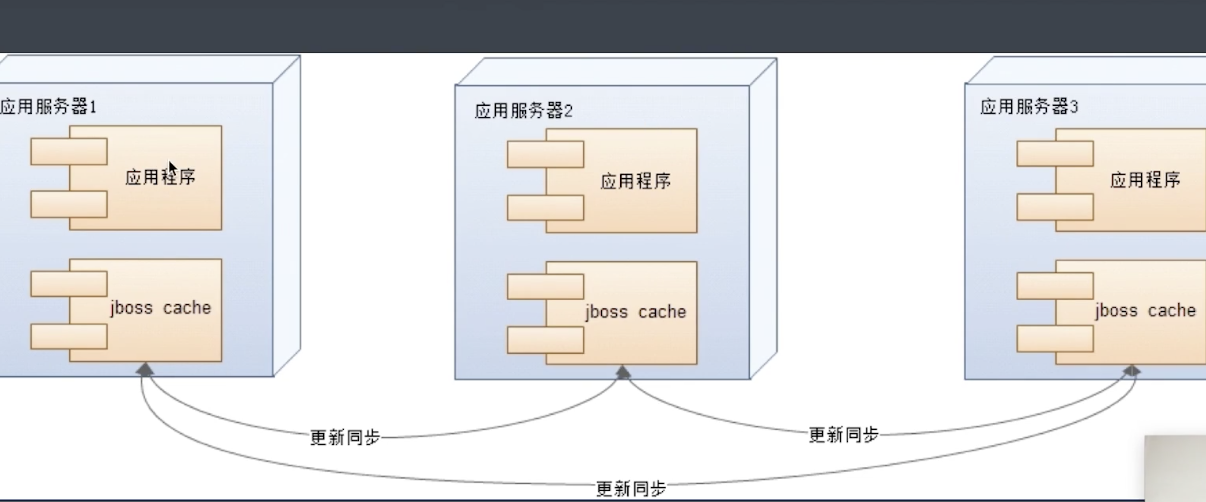
本地对象缓存
对象直接缓存在应用程序内存中;
对象存储在共享内存,同一台机器的多个进程可以访问它们;
缓存服务器作为独立应用和应用程序部署在同一个服务器上;
本地对象缓存构建分布式集群
缺点:
服务器规模较大时,不能满足需求,数据同步更新消耗内存资源,大量的网络同步占用带宽,消耗 CPU;
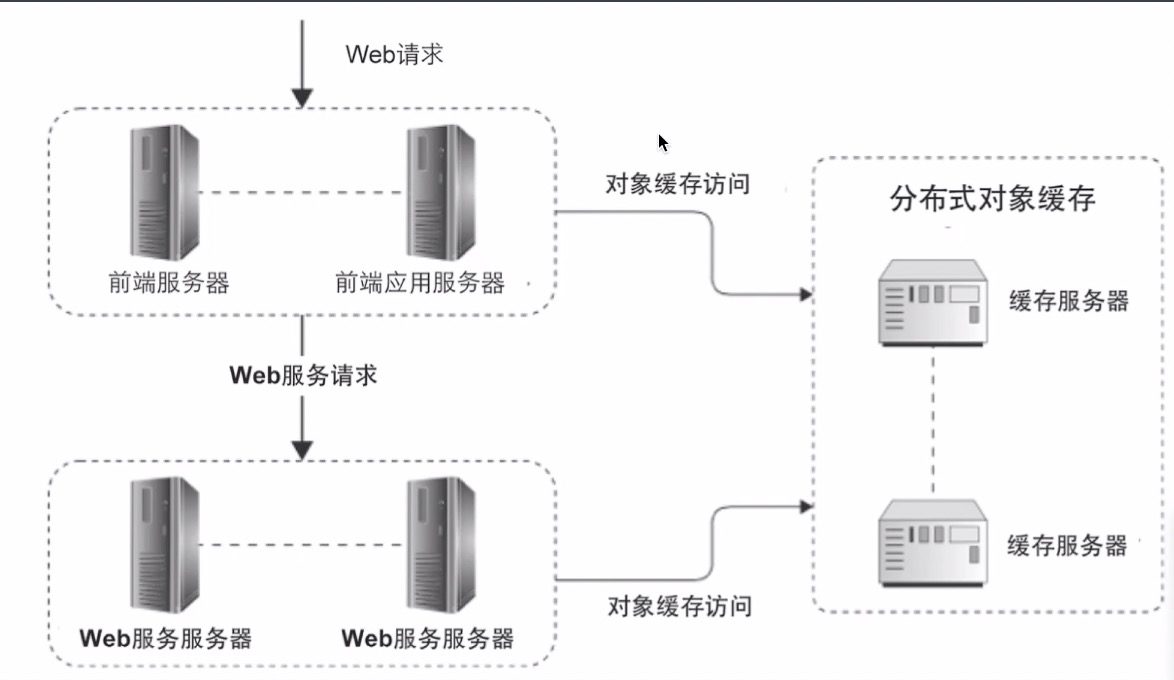
远程分布式对象缓存
缓存的读写由缓存服务器提供服务,应用服务器通过远程访问从分布式缓存中获取值;
集群的概念:由相同功能或者相同角色的一组服务器构成的集合,共同对外提供服务;
分布式集群遇到的问题:
1、Key 值如何定位到指定服务器?取模;
2、当服务器进行扩容或缩容时,需要对数据重新取模,假如数据取模后无法在缓存服务器获取,只能去数据库读取,大量的请求将到达数据库,有可能导致服务奔溃;
5、分布式一致性哈希算法
5-1、余数哈希
对服务器的个数取模;得到的余数就是服务器的编号;
5-2、一致性哈希算法
问题背景:
服务器扩容或者缩容时,需要对 Key 重新 hash,有可能导致 Key 的分布不均匀;
一致性哈希环
1、构造一个环形结构;
2、哈希环上的值范围是 0 - 2^32-1;
3、服务器节点取 hash 值放到环上;
4、当要查找某个 key 在哪台服务器上,先对 Key 取 Hash 值,值落在环上,如果这个值恰好等于某个服务器的 hash 值,就直接访问这台服务器;如果 Key 的 Hash 值与任意一台服务器的 Hash 值都不相等,沿着哈希环【顺时针】查找,最近的一个服务器节点就是这个 Key 值要访问的节点;
在环上顺时针查找离 key 最近的 Node
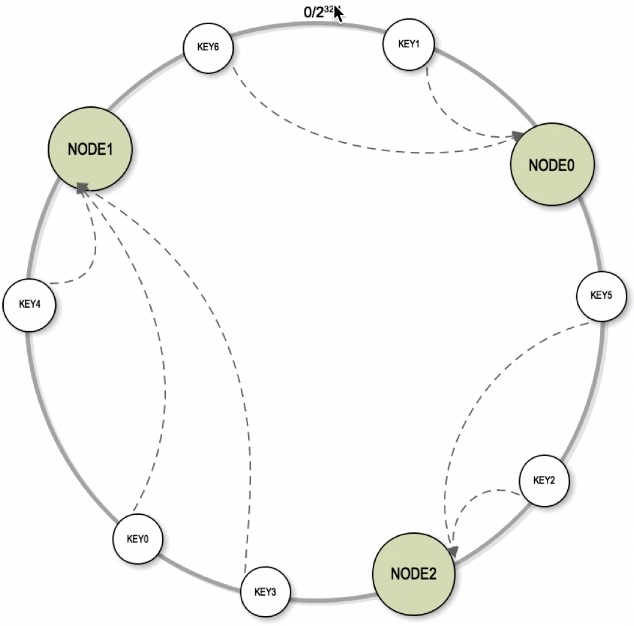
一致性 Hash 节点扩容
当扩容一台机器后,影响的数据范围只是在 新增机器 和 前一台机器 之间的值;
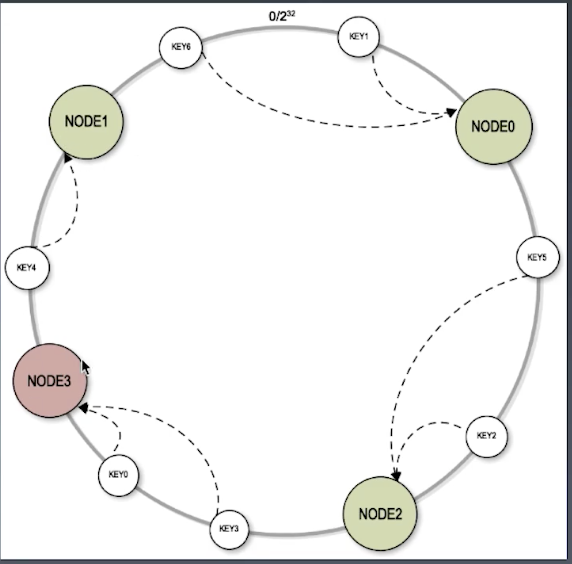
问题:
缓存的负载不均衡;
加机器不能满足 数据平均,达到平衡数据,减少访问数量;
哈希值是一个随机数据,如果 两个节点 较近,访问 Node0 的数据较多;
加机器也不能平衡每个节点的访问数量;
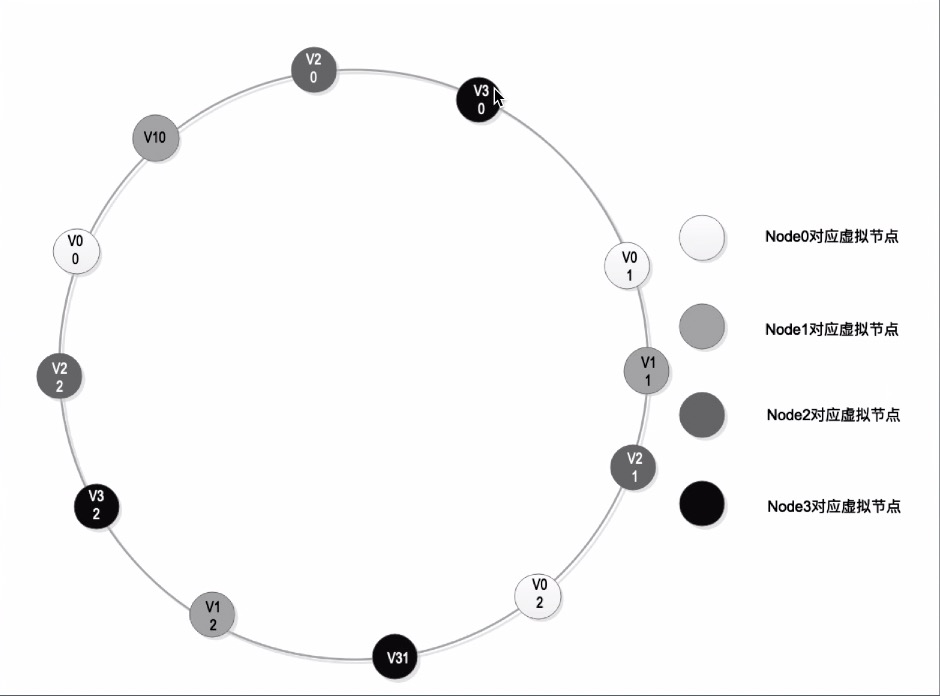
5-3、基于虚拟节点的一致性 Hash 算法
使用多个【虚拟节点】,将值【均匀】的分布在环上;
当加一个新的节点,新的虚拟节点也是均匀的;
影响的数据量比较少;
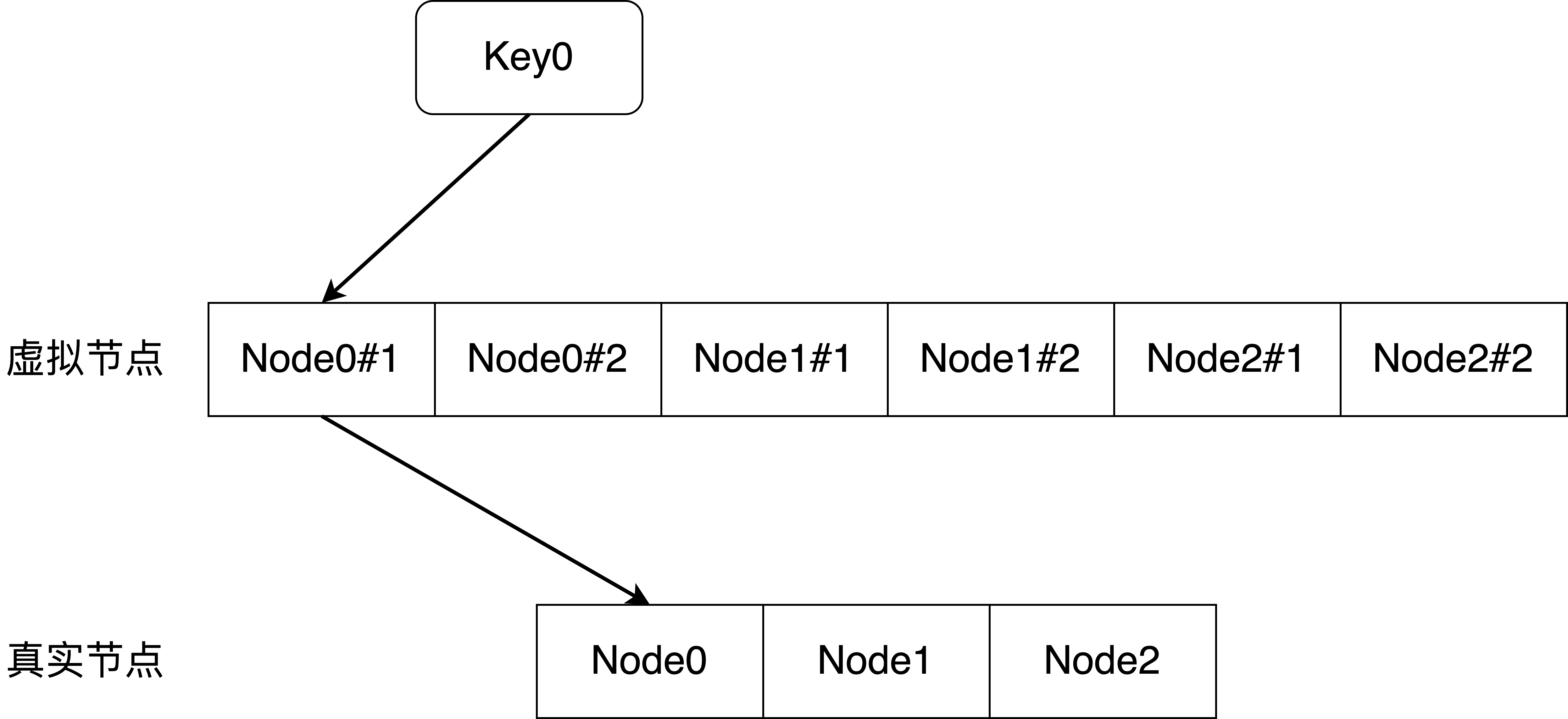
访问过程:
1、计算 Key 的 Hash 值;
2、根据 Hash 值找到对应的虚拟节点;
3、根据虚拟节点获得真实节点;
6、技术栈各个层次的缓存
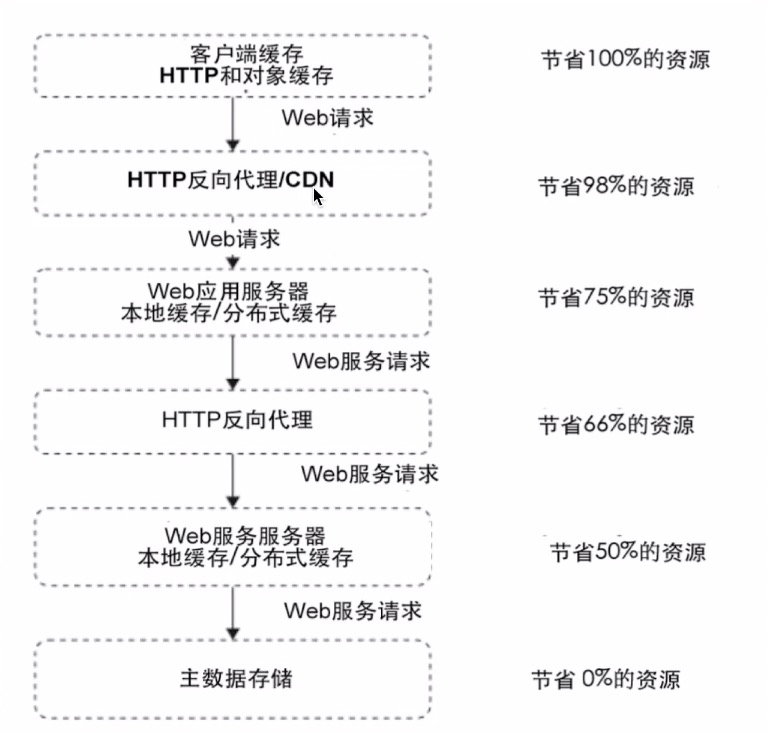
7、缓存为什么能显著提升性能
缓存数据通常来自内存,比磁盘上的数据有更快的访问速度;
缓存存储数据的最终结果形态,不需要中间计算,减少 CPU 资源的消耗;
缓存降低数据库、磁盘、网络的负载压力,使这些 I/O 设备获得更好的响应特性;
缓存就是一个数据存储服务,不要太复杂,包括数据更新,因为会造成数据不一致;
8、缓存是系统性能优化的大杀器
技术简单;
性能提升显著;
应用场景多;
合理使用缓存
使用缓存对提高系统性能有很多好处,但是不合理的使用缓存可能非但不能提高系统性能,还会成为系统的累赘,甚至风险;
实践中,缓存滥用的情景屡见不鲜 -- 过分依赖缓存、不合适的数据访问特性等;
频繁修改的数据:这种数据如果缓存起来,由于频繁修改,应用还来不及读取就已失效或更新,徒增系统负担。一般说来,数据的读写比在 2:1 以上,缓存才有意义;
【多次读取】的高速存储;
没有热点的访问:
缓存使用内存作为存储,内存资源宝贵而有限,不能将所有数据都缓存起来,如果应用系统访问数据没有热点,不遵循【二八定律】,即大部分数据访问不是集中在小部分数据上,那么缓存就没有意义,因为大部分数据还没有被再次访问就已经被挤出缓存;
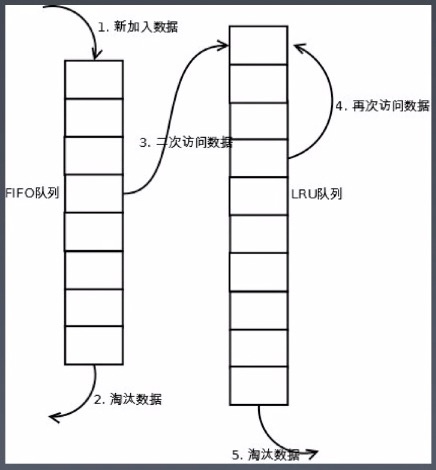
控制缓存失效的数据结构 LRU 算法
频繁访问的热点数据,数据多次访问,将数据放入链表前,而访问较少的数据放入链表后;
数据不一致与脏读
一般会对缓存的数据设置失效时间,一旦超过失效时间,就要从数据库中重新加载;
因此应用要容忍一定时间的数据不一致,如卖家已经编辑商品属性,但是需要通过一段时间才能被买家看到;在互联网应用中,这种延迟通常是可以接受的,但是具体应用仍需慎重对待;
还有一种策略是数据更新时立即更新缓存,不过也会带来更多系统开销和事物一致性问题;
因此数据更新时通知缓存失效,删除该缓存数据,时一种更加稳妥的做法;
缓存雪崩
缓存是为了提高数据读取性能,缓存数据丢失或者缓存不可用不会影响到应用程序处理,因为可以从数据库直接获取数据;
但是随着业务发展,缓存会承担大部分的数据访问压力,当缓存服务崩溃时,数据库会因为完全不能承受大压力而宕机,进而导致服务不可用;这种情况被称作缓存雪崩,发生这种故障,甚至不能简单的重启缓存服务器和数据库服务器来恢复;
解决方法:
缓存数据的过期时间设置随机,防止同一时间大量数据过期现象发生;
如果缓存数据库是分布式部署,将热点数据均匀分布在不同缓存数据库中;
设置热点数据永远不过期;
缓存预热
缓存中存放的是热点数据,热点数据是缓存系统里有 LRU 算法对不断访问的数据筛选淘汰出来,这个过程需要花费较长的时间,在这段时间,系统的性能和数据库复杂较差,因此最好在缓存系统启动时就把热点数据加载好,这个缓存预加载手段较缓存预热(warm up)。
对于一些元数据如 城市地名列表,类目信息,可以启动时加载数据库中全部数据到缓存进行预热;
缓存穿透
如果不恰当的业务、或者恶意攻击持续高并发的【请求某个不存在的数据】,因为缓存没有保存该数据,所有的请求都会落在数据库上,会对数据库造成很大压力,甚至奔溃;
解决方法:
一个简单的对策就是讲【不存在的数据也缓存起来(其 value 值为 null)】,并设定一个较短的失效时间;
9、Redis 集群
Redis 集群预先分好 16384 个桶,当需要在 Redis 集群中放置一个 key-value 时,根据 CRC16(key) mod 16384 的值,决定将一个 Key 放到哪个桶中;
Redis-Cluster 把所有的物理节点映射到【0-16383】slot 上(不一定是平均分配),cluster 负责维护 slot 与服务器的映射关系;
客户端与 Redis 节点直连,客户端不需要连接集群所有节点,连接集群中任何一个可用节点即可;
所有的 Redis 节点彼此互联;
版权声明: 本文为 InfoQ 作者【Arthur】的原创文章。
原文链接:【http://xie.infoq.cn/article/22c1da5c16e2649d20a0361a9】。未经作者许可,禁止转载。

还未添加个人签名 2018.08.31 加入
还未添加个人简介









评论