【架构师训练营】week 5 homework

前言
哈希寻址
假设有一个由A、B、C三个节点组成的KV服务,每个节点存放不同的KV数据。
使用哈希寻址。通过哈希算法,每个key可以寻址到对应的服务器。如:查询key是key-01,计算公式为 hash(key-01) % 3 = 1,经过计算寻址到了编号为1的服务器节点A。
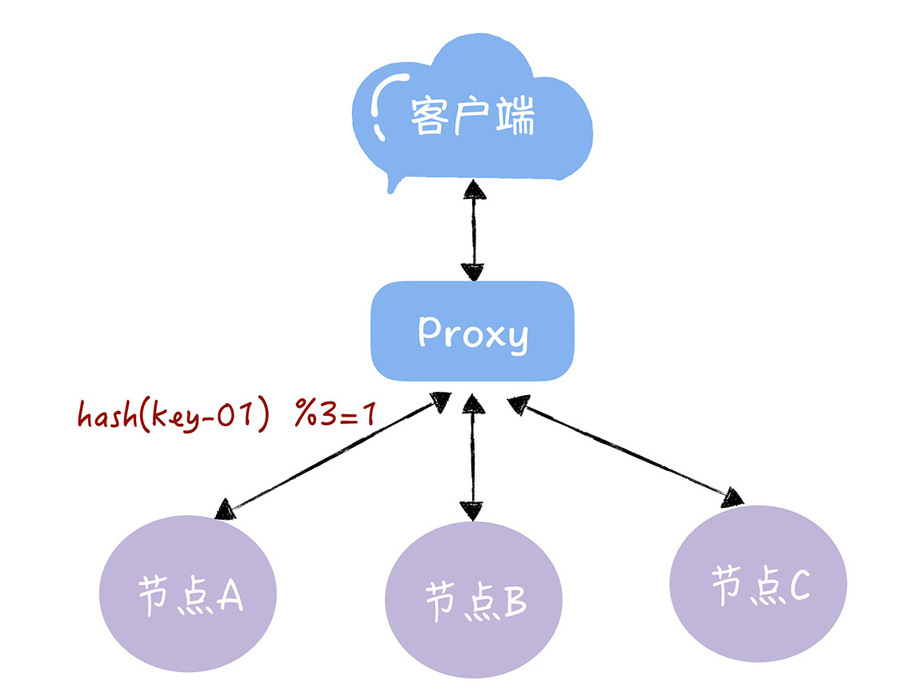
存在问题:如果服务器数量发生变化,基于新的服务器数量来执行哈希算法的时候,就会出现路由寻址失败的情况,Proxy 无法找到之前寻址到的那个服务器节点。
如:当3个节点不能满足业务需求,此时增加一个节点,那么之前的 hash(key-01) % 3 = 1就变成了hash(key-01) % 4 = x,取模运算发生了变化,此时 x 可能为 2,对应的寻址到的是节点 B 。原来 key-01 对应的数据,存储在节点 A 而不是 B。
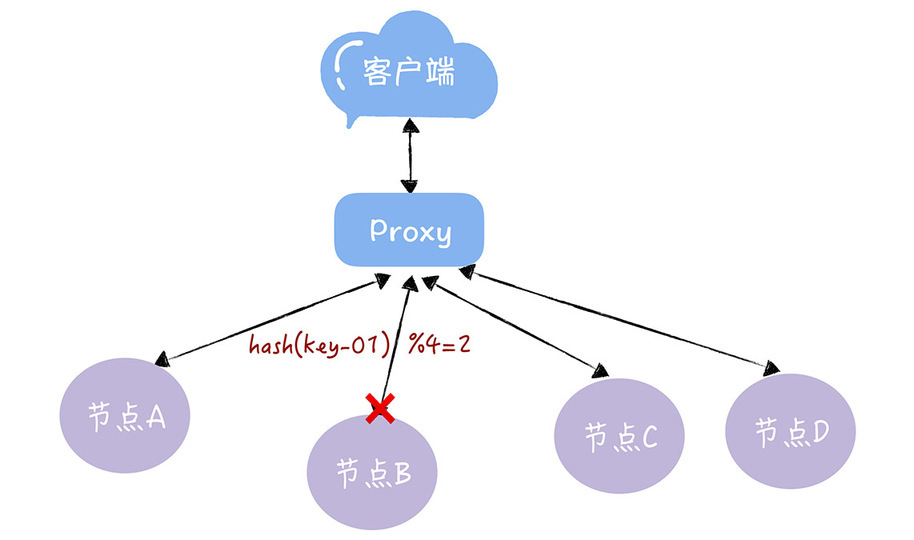
实现
对于 1000 万 key 的 3 节点 KV 存储,若增加一个节点,即 4 节点,需要迁移多少数据?
由代码输出可以看出,从3节点改到4节点需要迁移 74.999985% 的数据。可见迁移的成本很高昂。
引入
一致哈希算法也用了取模运算,但与哈希算法不同的是,哈希算法是对节点的数量进行取模运算,而一致哈希算法是对 2^32 进行取模运算。一致哈希算法,将整个哈希值空间组织成一个虚拟的圆环,也就是哈希环。
在一致性哈希中,可以通过哈希算法(假设为 c-hash()),将节点映射到哈希环上。
寻址方式:
首先,将 key 作为参数执行 c-hash() 计算哈希值,并确定此 key 在环上的位置;
然后,从这个位置沿着哈希环顺时针“行走”,遇到的第一节点就是 key 对应的节点。
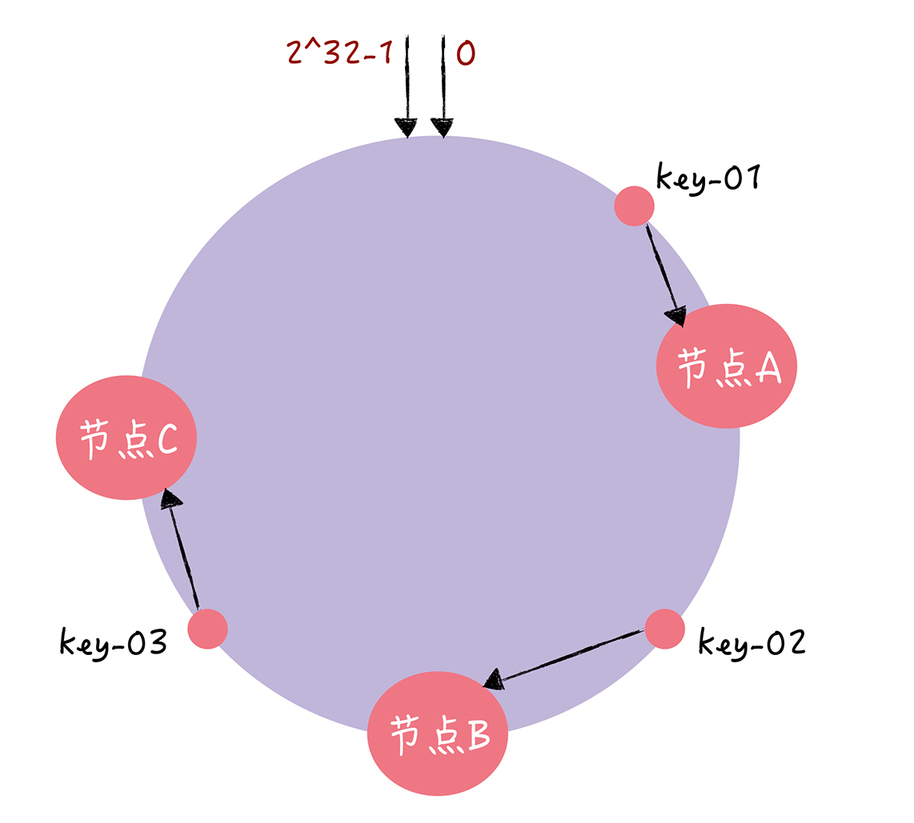
一致性哈希如何避免哈希算法的数据迁移成本高的问题?
以增加和移除节点为例。
在一致哈希算法中,如果某个节点宕机不可用了,那么受影响的数据仅仅是,会寻址到此节点和前一节点之间的数据。
在一致哈希算法中,如果增加一个节点,受影响的数据仅仅是,会寻址到新节点和前一节点之间的数据,其它数据也不会受到影响。
优化
客户端访问请求集中在少数的节点上,出现了有些机器高负载,有些机器低负载的情况,那么在一致哈希中,有什么办法能让数据访问分布的比较均匀呢?
答案是虚拟节点。对每一个服务器节点计算多个哈希值,在每个计算结果位置上,都放置一个虚拟节点,并将虚拟节点映射到实际节点。
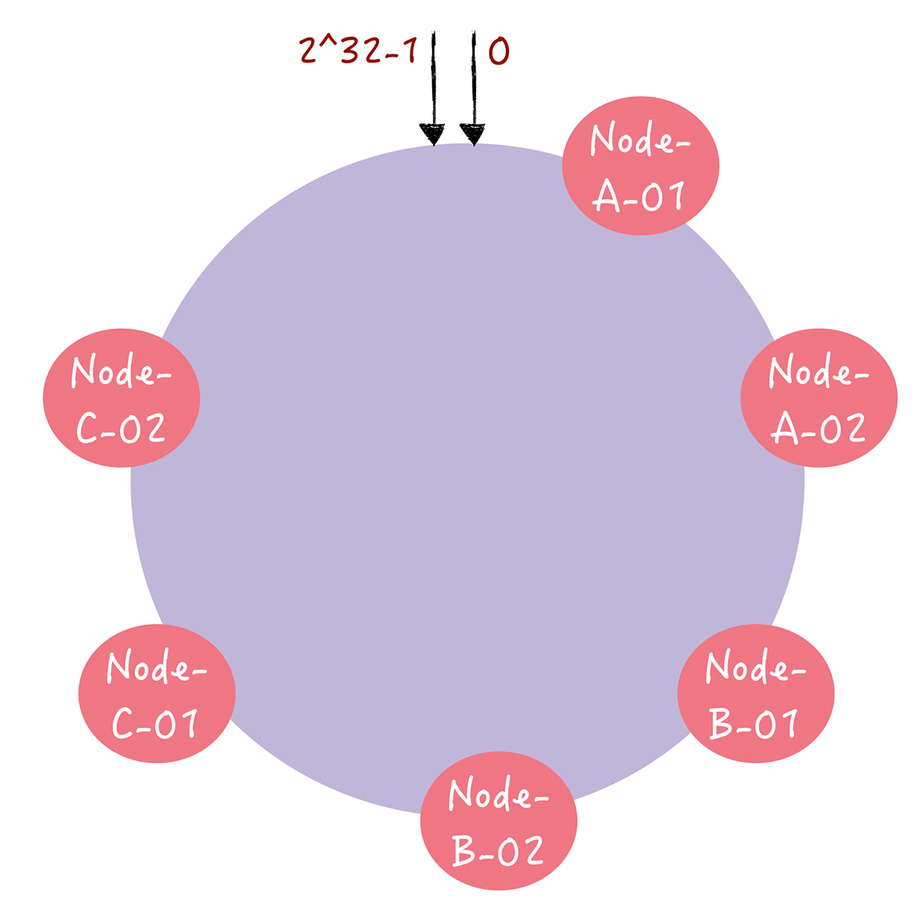
实现
构建哈希环
虚拟节点
哈希函数
选择 MurmurHash 作为哈希函数。
测试用例
测试 100 万 KV 数据,10 个服务器节点的情况下,计算这些 KV 数据在服务器上分布数量的标准差,以评估算法的存储负载不均衡性。
输出结果

还未添加个人签名 2019.04.10 加入
还未添加个人简介









评论