架构师课程第九章:数据应用 总结
大数据概述:
大数据技术起源于 Google 在 2004 年前后发表的三篇论文,也被称为大数据"三驾马车”,分别是分布式文件系统GFS、大数据分布式计算框架 MapReduce 和 NoSQL 数据库系统BigTable。
大数据的引用的发展史
大数据应用的搜索引擎时代:google使用大数据文件系统存储网页数据,并对网页排名
大数据应用的数据仓库时代:企业把运行日志、应用采集数据、数据库数据放到一起进行计算分析得到想要了解的数据分析结果。
大数据应用的数据挖掘时代:对用户的数据分析,将每个人的不同特性挖掘出来,打上各种各样的标签,描绘出用户画像。针对用户特征,进行相关的内容推荐。
大数据应用的机器学习时代:收集大量的历史数据,统计其规律,按照规律预测正在发生的事情的结果。
大数据各类应用场景及主要的处理工具如下图:

大数据的存储:HDFS(Hadoop Distributed File System)
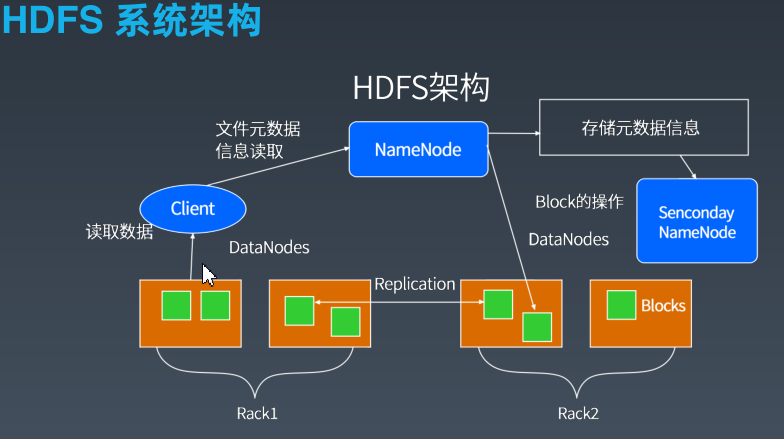
HDFS设计目标:以流式数据访问模式(一次写入多次读取)存储超大文件,运行与商用硬件集群上。
HDFS不适宜的场景:低延迟的数据访问,大量小文件,多用户随机写入修改文件。
HDFS采用分而治之的思想将文件切分成块(默认大小64M),以块为单位,每个块有多个副本存储在不同的服务器上(数据节点),并有各种运行机制(数据复制、故障检测、数据节的点心跳、块报告、数据完整性校验)保证高可用性。
大数据的处理:
一 MapReduce
特点:处理海量数据,分而治之利用上百上千 CPU 实现并行处理,分发计算程序,而不是分发数据。
MapReduce上用户程序由两部分组成;
map:
input: key(要处理的关键字),text(处理的一行数据)
output: 根据业务计算出这一行对应关键字的结果放到context中,如wordCount 结果就是 keyword, wordIntextCount
reduce:
input : key (要处理的关键字),Iterable<IntWritable>(处理不同行数据map函数相同key计算出结果的list)
output: 最终的想要结果
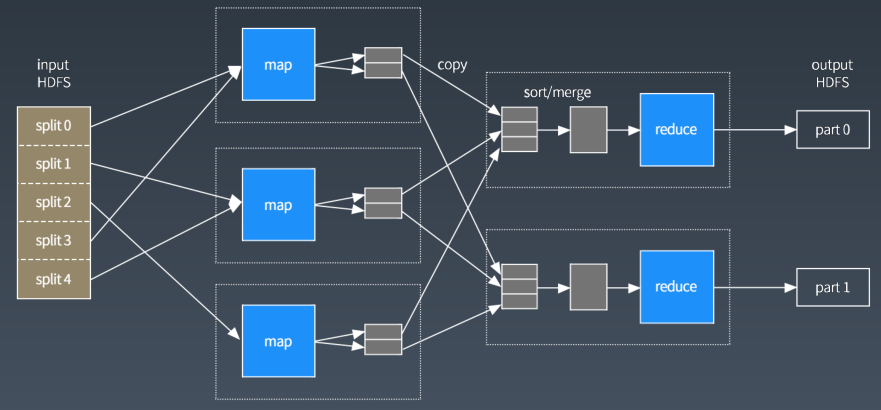
mapReduce在分布式集群中的数据处理过程如下图:
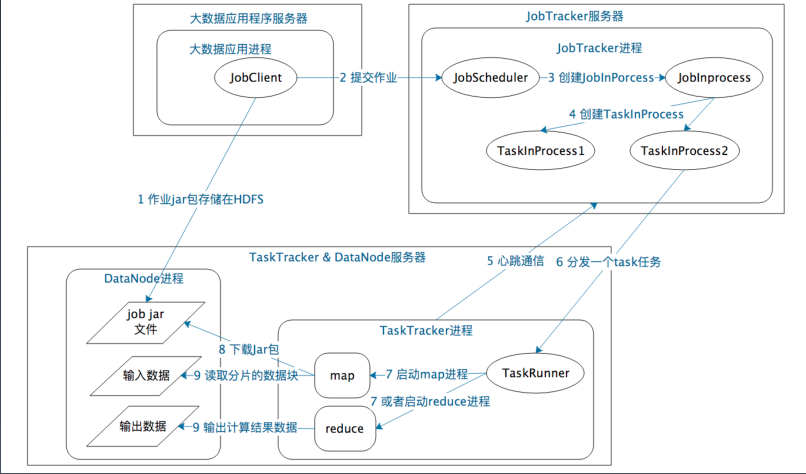
mapReduce的系统部署和调用架构图如下:
二 yarn
yarn是一个通用的运行时资源调度框架,用户可以编写自己的计算框架,在该运行环境中运行。
早期的mapReduce结构把服务器集群资源调度管理和 MapReduce 执行过程耦合在一起,想要在当前集群中运行其他计算任务如spark,storm 就无法统一使用集群中的资源。
yarn 的架构图:
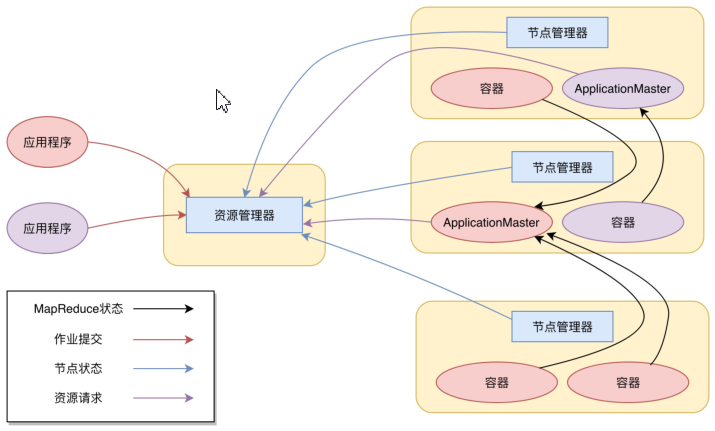
yarn 的工作流程(MapReduce为例)
我们向 Yarn提交应用程序,包括MapReduce ApplicationMaster、MapReduce程序,以及MapReduce Application 启动命令。
ResourceManager进程通信,根据集群资源、为用户程序分配第一个容器,并将MapReduce ApplicationMaster分发到这个容器上面,并在容器里面启动MapRdeuce ApplicationMaster。
MapReduce ApplicationMaster 启动后立即向 ResourceManager 进行注册,并为自己的应用程序申请容器资源。
MapReduce ApplicationMaster 申请到需要的容器后,立即和相应的 NodeManager进程通信,将用户 MapReduce 程序分发到NodeManager 进程所在的服务器,并在容器中运行,运行的就是 Map 或者 Reduce 任务。
Map 或者 Reduce 任务在运行期和MapReduce ApplicationMaster通信,汇报自己的运行状态,如果运行结束,MapReduce ApplicationMaster 向 ResourceManager进程注销并释放所有的容器资源。
三 Hive
基于SQL的MapReduce大数据处理工具
操作符(operator)是Hive的最小处理单元,每个操作符代表HDFS操作 或者MapReduce作业,编译器吧Hive SQL 转换成一组操作符交给Hadoop执行。
Hive 执行流程的图:
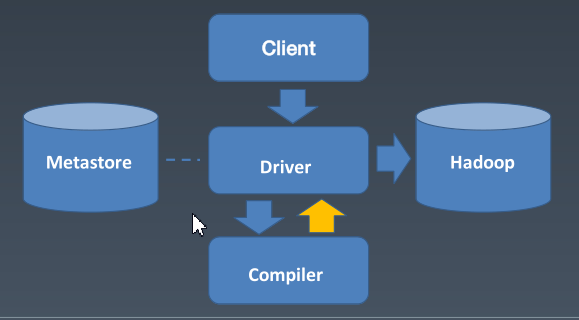
Hive 编译器(compiler)转换SQL:
把sql转换为抽象语法书 AST
把抽象语法书转化为查询块 QB
把QB转化为逻辑执行计划 Logical Plan
重写执行计划,带入更多的优化后的计划
将逻辑执行计划转化为物理执行计划 MapReduce jobs
适应新 Join 策略调整
四 spark
spark也是一个大数据处处理工具,相比于Hadoop有计算速度上的优势。
spark的特点
DAG切分的多几段计算过程更快速
使用内存存储中间计算结果跟高效(hadoop使用磁盘)
RDD 的编程模型跟简单(wordCount只需三行)
编程模型RDD
MapReduce针对输入数据,分为Map和Reduce两阶段,为面向过程编程的大数据计算。而Spark将数据集合抽象成一个RDD对象,对RDD进行各种计算处理,得到一个新的RDD,继续计算处理知道得出最后结果。spark可以理解为是面向对象的大数据计算。
spark 的计算阶段
spark将计算分割成多个计算阶段(stage),这些计算阶段组成一个有向无环图DAG,spark 任务调度器可以根据 DAG 的依赖关系执行计算阶段。
spark 的计算阶示例图:
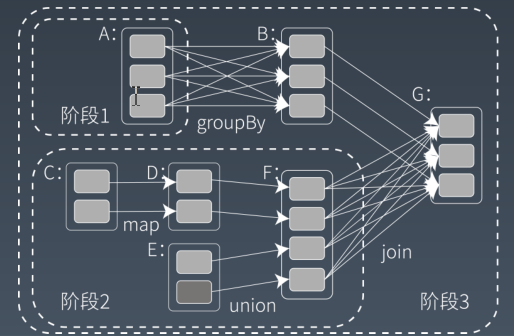
Spark 的执行过程
Spark 支持 standalone、yarn、Mesos、Kubernetes等多种部署方案,几种部署方案的原理也都一样,只是不同的组件角色命名不一样,但核心功能和运行流程都差不多。
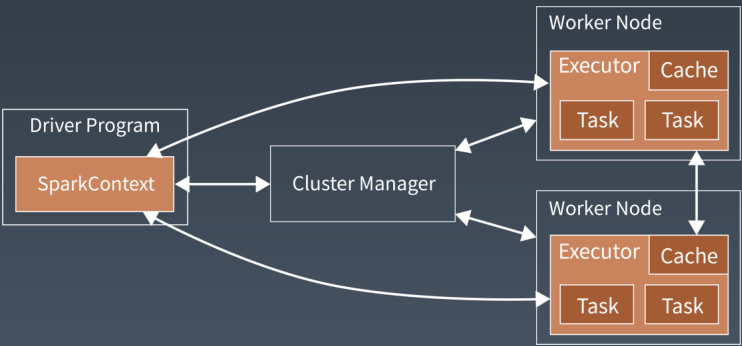
首先,spark 应用程序启动在自己的 JVM 进程里,即 Driver 进程中,启动后调用SparkContext初始化执行配置和输入数据。SparkContext 启动 DAGSchedule 构造执行的DAG图,切分成最小的执行代为也就是计算任务。
然后Driver 向 Cluster Manager 请求计算资源,用于DAG 的分布式计算。ClusterManager 收到请求后,将Driver的主机地址等信息通知给集群的所有计算节点Worker。
worker 收到信息以后,根据 Driver的主机地址,跟 Driver通信并注册,然后根据自己的空闲资源向Driver 通报自己可以领用的任务数。 Driver 根据 DAG 图开始向注册的Worker 分配任务。
worker 收到任务后,启动 Executor 进程开始执行任务。Executor 先检查自己是否有Driver 的执行代码,如果没有,从 Driver下载执行代码,通过Java 反射 加载后开始执行。
五 流计算
流计算不同一般的批量大数据计算,需要对实时产生的数据进行计算。
流计算的大数据工具有 strom,spark streming ,Flink
流计算可以看成是每一次处理很少量数据的一般批量大数据计算,数据量少时,就可以做到很快出计算结果。达到实时效果
流计算的应用场景
交通测速监控、淘宝用户每日访问的实时日志分析
六 大数据应用的测试工具
HiBench(intel公司研发,可生成用于测试的数据)
数据可视化
1、互联网运营常用数据指标
1)新增用户数
2)用户留存率
3)用户流失率
4)活跃用户数
5)PV
6)GMV
7)转换率
2、数据可视化图表
1)折线图
2)散点图
3)热力图
4)漏斗图
机器学习
常用算法:
1、网页排名算法 PageRank:根据网站引用另一个网站的地址计算网站的数量加上权重并排序
2、KNN分类算法
1)数据距离算法:数据分组,新数据计算到每个组的距离,分到距离近的组
2)提取文本的特征值TF-IDF算法:根据该文档关键字的词频与所有文档该关键字的词频得到文档特征值
3、贝叶斯分类算法:p(AB)=P(A|B)*P(B)/p(A)
4、K-means聚类算法
5、推荐引擎算法
1)基于人口统计的推荐
2)基于商品属性的推荐
3)基于用户的协同过滤推荐
4)基于商品的协同过滤推荐
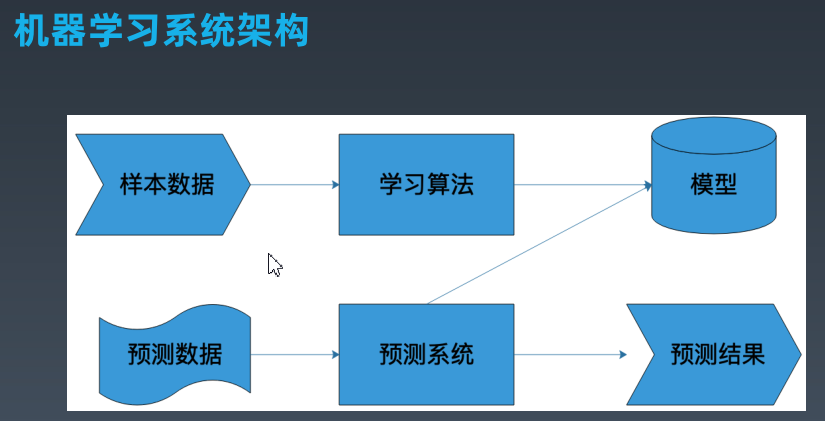
样本:用于训练的数据,已经打过分类标记的数据。
模型:就是映射样本输入与样本结果的函数,很多时候函数的类型是明确的如(y=a1x+b)这时只需要计算 a1和a0的两个参数的值。
算法: 就是要从模型的所有有可能的函数中找出一个最优的函数,使样本数据映射的函数f(x) 和真实 Y 值之间的距离最小。
机器学习的数学原理:就是在给定的函数类型情况下,如何寻找到 最优的函数表达式。在数学上求函数的极小值需要求 一介倒数,就是计算每个参数的一介倒数的为零的偏微分方程组。所以机器学习要计算偏微分方程。
神经网络
感知机:可以输入的数据输出为两类值。1或-1。
神经网络:就是模拟人的大脑神经元的连接方式,将感知机组成一个网络。
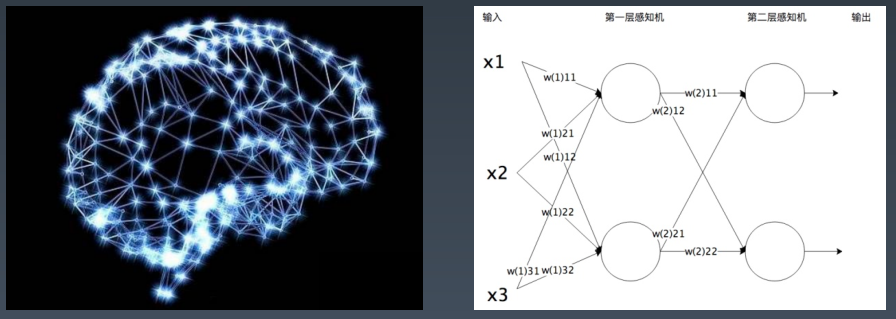
神经网络有两层感知机,第一层感知机对输入的数据计算后把结果传递给第二层感知机,第二层感知机计算后的到神经网络的决策结果。
如:神经网络在手洗数字识别中的应用
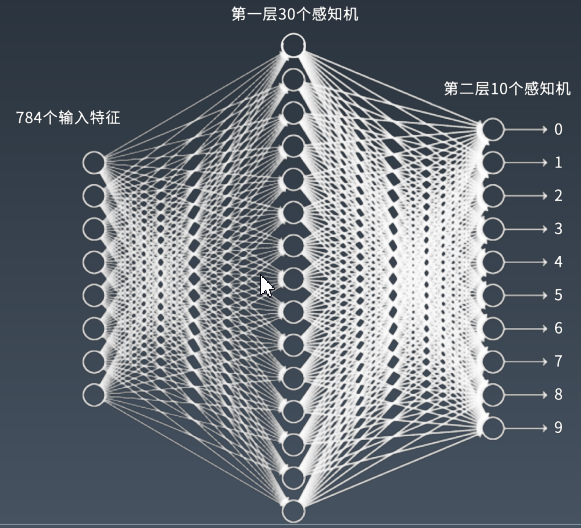

784位每个数字个的像素点个数,第二层10个感知机对应0-9的数字,中间层的感知机就需要研究人员研究调整寻找一个最合适的个数。达到能把手写数字的图片识别出来的效果。
深度学习
深度学习是在神经网络基础上加了多个中间层,层级数量和每层的感知机数量需要研究调整。

还未添加个人签名 2019.10.12 加入
精神小伙









评论