Spark & 流计算、数据分析与机器学习——总结
Spark
Spark 生态体系

Spark VS Hadoop
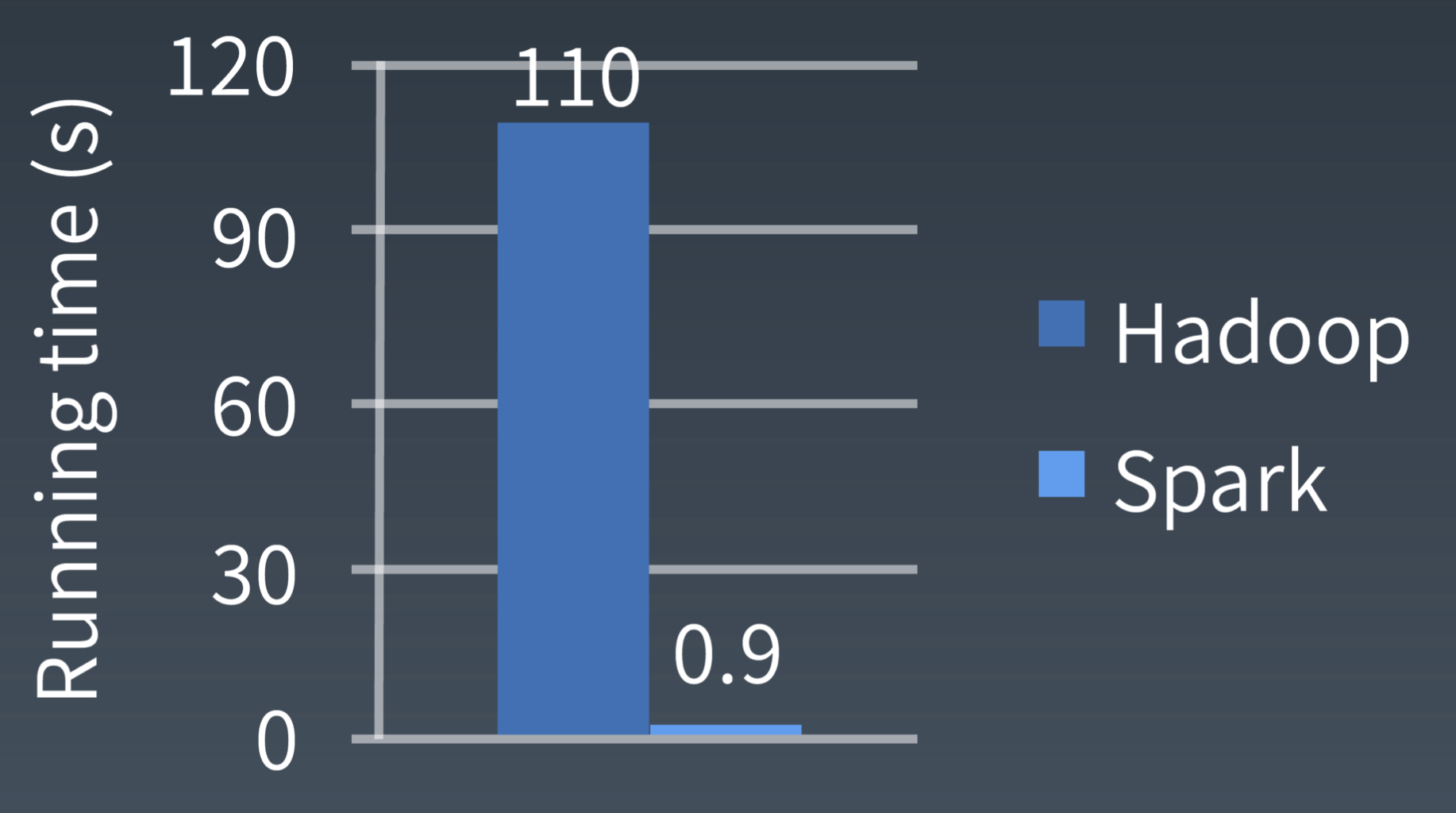
Spark 特点(为什么更快)
DAG 切分的多阶段计算过程更快
使用内存存储计算中间结果更高效
RDD 编程模型更简单
RDD:RDD 是 Spark 的核心概念,是弹性数据集(Resilient Distributed Datasets)的缩写;Spark 直接针对数据编程,将大规模的数据集合抽象成一个 RDD 对象,然后在这个 RDD 对象之上进行计算,得到新的 RDD 继续计算处理。
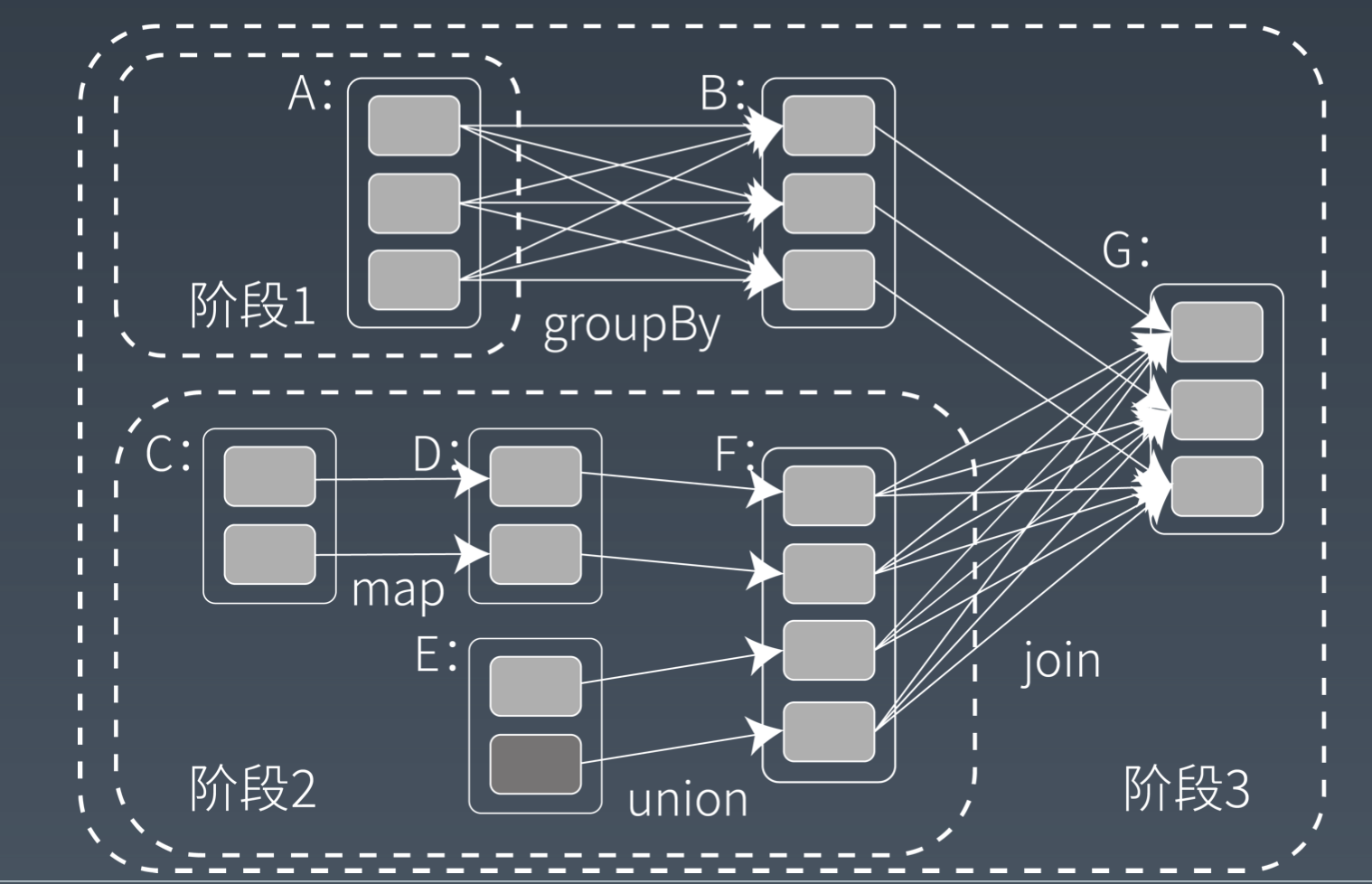
Spark 的计算阶段
和 MapReduce 一个应用一次只运行一个 map 和 reduce 不同,Spark 可以根据引用的复杂度,分割成更多的计算阶段(stage),这些计算阶段组成一个有向无环图 DAG,Spark 任务调度器可以根据 DAG 依赖关系执行计算阶段
Spark 的作业管理
Spark 里面的 RDD 函数有两种,一种是转换函数,调用后得到的还是一个 RDD,RDD 的计算逻辑主要就是通过转换函数完成。另一种是 action 函数,调用后不再返回 RDD,比如 rdd.count()函数调用。
RDD 里面的每个数据分片,Spark 都会创建一个计算任务去处理,所以一个计算阶段包含多个计算任务
Spark 的执行过程
Spark 支持 Standalone、Yarn、Mesos、kubernetes 等多种部署方案,各种部署方案原理也一样,只是不同组件角色名称不一样,但是核心功能和运行流程都差不多。
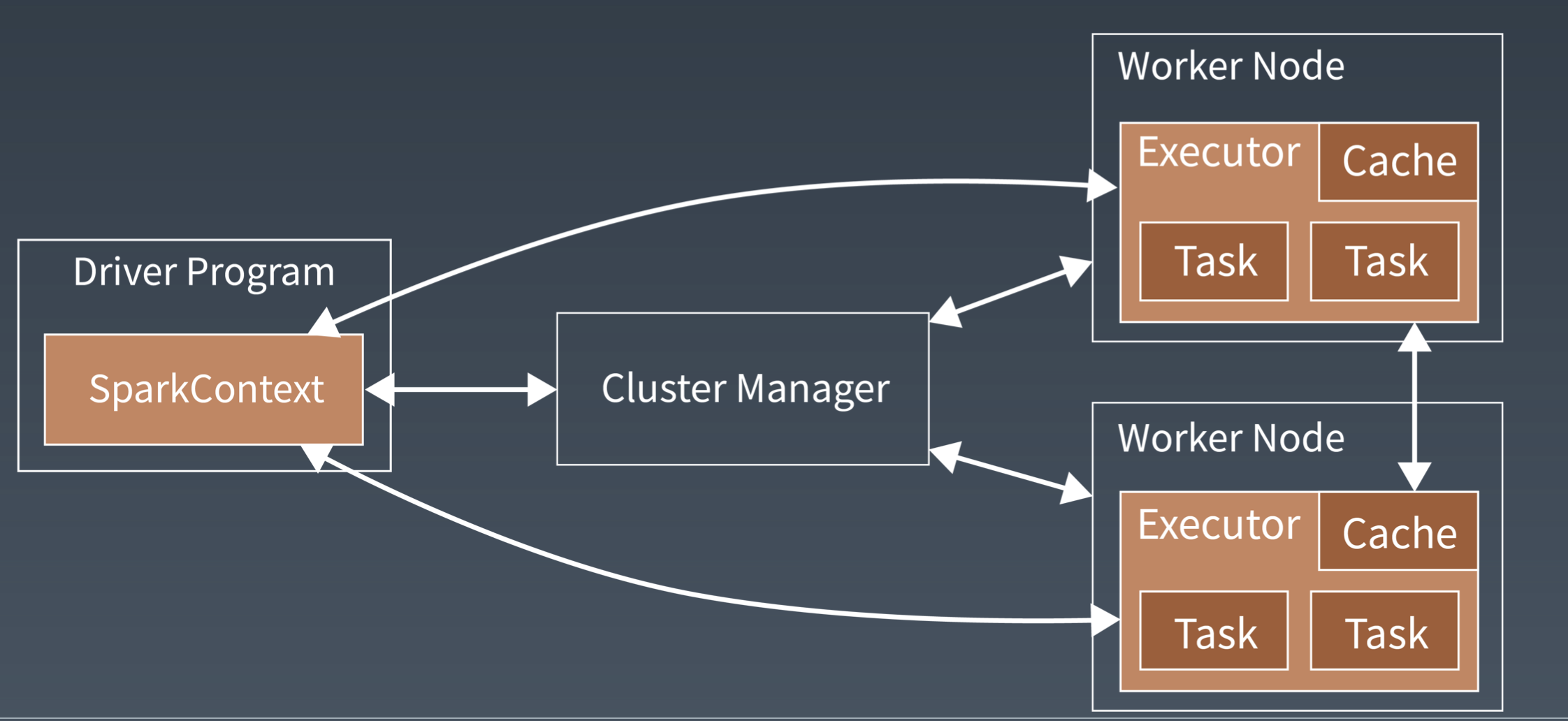
首先,Spark 应用启动在自己的 JVM 进程里,即 Driver 进程,启动后调用 SparkContext 初始化执行配置和输入数据。SparkContext 启动 DAGScheduler 构造执行的 DAG 图,切分成最小的执行单位就是计算任务
然后,Driver 向 Cluster Manager 请求计算资源,用于 DAG 的分布式计算。Cluster Manager 收到请求后,将 Driver 的主机地址等信息通知给集群所有的计算节点 worker
Worker 收到消息后,根据 Driver 的主机地址,跟 Driver 通信并注册,然后根据自己的空闲资源向 Driver 通报自己可以领用的任务数。Driver 根据 DAG 图 开始向注册的 Worker 分配任务
Worker 收到任务后,启动 Executor 进程开始执行任务。Executor 先检查自己是否有 Driver 的执行代码,如果没有,从 Driver 上下载执行代码,通过 JAVA 反射加载后开始执行。
流计算
Storm 实时的 Hadoop
实时计算系统的性质:
低延迟
高性能
分布式
可伸缩
高可用
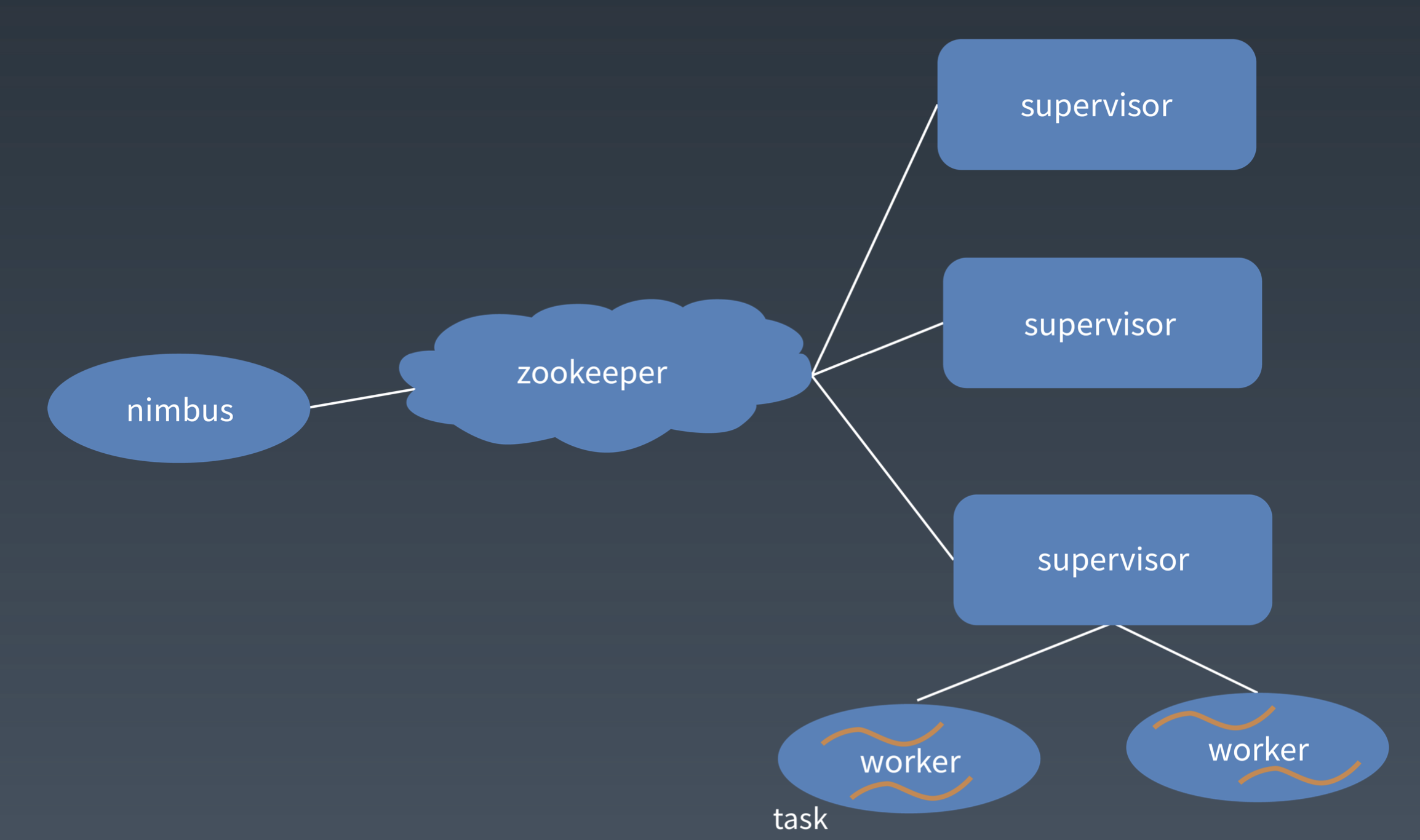
Storm 的基本概念

Nimbus: 负责资源分配和任务调度
Supervisor:负责接受 Nimbus 分配的任务,启动和停止自己管理的 Worker 进程
Worker: 运行具体处理逻辑的进程
Task: Worker 中 每一个 Spout/Bolt 的线程
Topology:Storm 中运行的一个实时应用程序
Spout: 在一个 Topology 中产生源数据流的组件
Bolt:在一个 Topology 中接受数据然后执行处理的组件
Tuple: 一次消息传递的基本单元
Stream:源源不断传递的 Tuple 就组成了 stream
Stream Groupings
Stream Groupings 定义一个流在 Bolt 任务间该如何切分,提供了 6 中类型:
随机分组
字段分组
全部分组
全局分组
无分组
直接分组
还可以通过实现 CustomStreamGrouping 接口定制自己需要的分组
Storm 的应用场景
实时日志处理
实时统计
实时风控
实时推荐
……
Spark Streaming

Flink

大数据可视化
互联网运营常用数据指标
新增用户数
用户留存率
活跃用户数
PV
打开产品就算活跃,打开以后是否频繁操作,就用 PV 这个指标衡量
GMV: 成交总金额(Gross Merchandise Volume)
转化率
数据可视化图表与数据监控
折线图
散点图
热力图
漏斗图
大数据算法与机器学习
网页排名算法 PageRank
PageRank 网页排名,又称网页级别、Google 左侧排名或佩奇排名。是一种由搜索引擎根据网页之间相互的超链接计算的技术。
PageRank 算法逻辑概述
PageRank 通过网页浩瀚的超链接关系来确定一个网页的等级。Google 把从 A 页面到 B 页面的链接解释为 A 页面为 B 页面投票,根据投票来源(甚至来源的来源)和投票目标的等级来决定新的等级。简单来说,一个高级的(权重、得票更高)页面可以使其它低等级页面的等级提升
一个页面的的票数是由所有链向它的也么的重要性决定的,到一个页面的超链接相当于投了该页一票。一个页面的 PagaRank 是由所有链向它的也么的重要性经过递归算法得到的。一个有较多链入的页面会有较高的等级,相反一个页面如果没有任务链入页面,那么它就没有等级。
PageRank 算法
假设一个由 4 个页面组成的小团体:A,B,C 和 D。如果所有页面都链入 A,那么 A 的 PR(PageRank)值将是 B、C、D 的 PR 总和:PR(A) = PR(B) + PR(C) + PR(D)
PageRank 计算公式
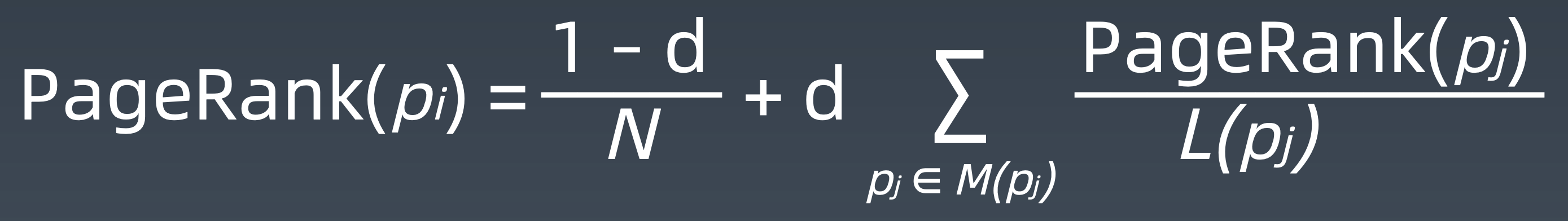
P1,P2……Pn 是被研究的页面,M(Pj)是链入 Pi 的集合,L(Pj) 是 Pj 链出页面的数量,而 N 是所有页面的数量
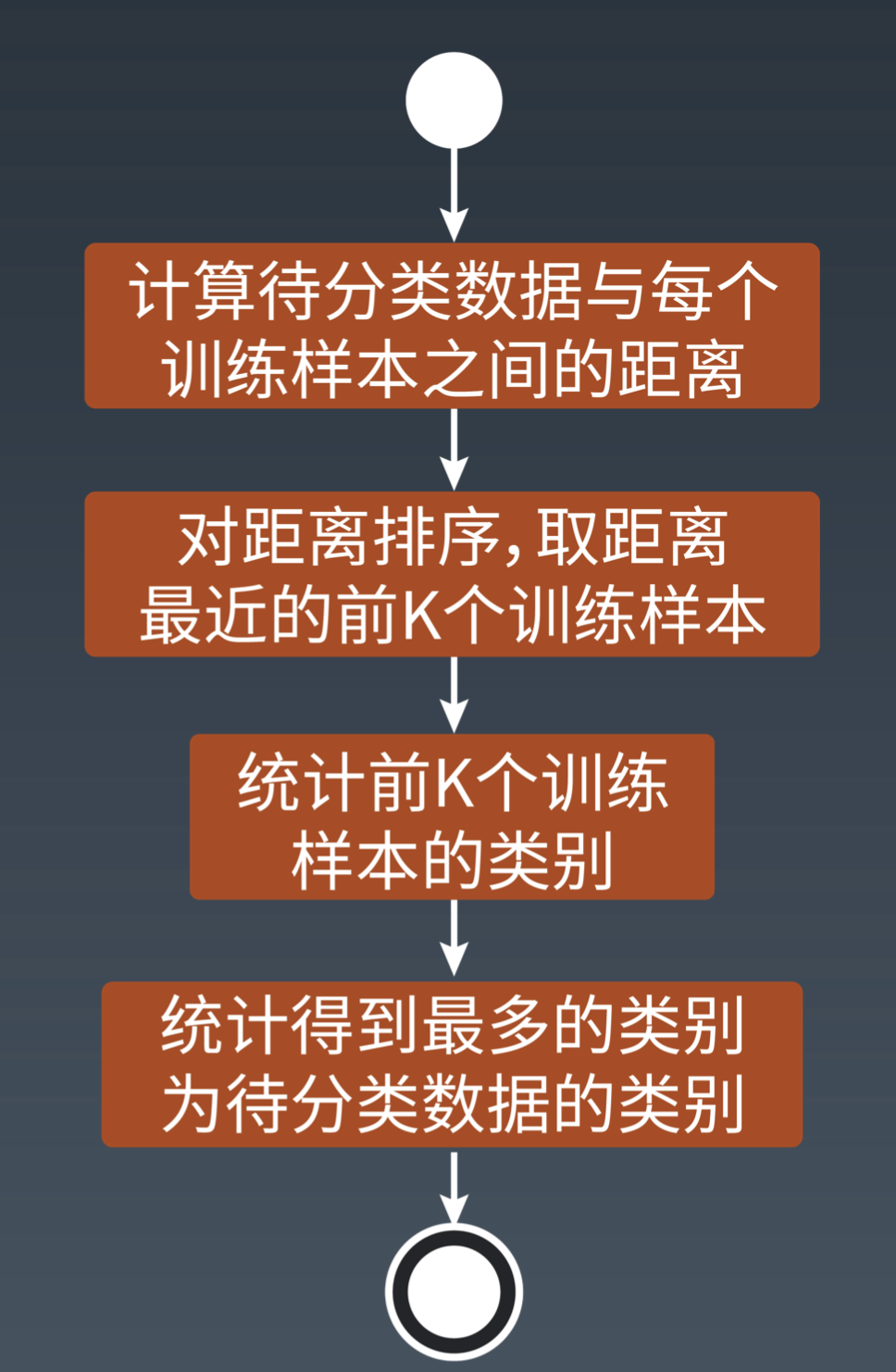
KNN 分类算法
也叫 K 近邻算法,对于一个需要分类的数据,将其和一组已经标注好的样本集合进行比较,得到距离最近的 K 个样本,K 个样本最多归属的类别,就是这个需要分类数据的类别
数据距离的算法
欧式距离计算公式
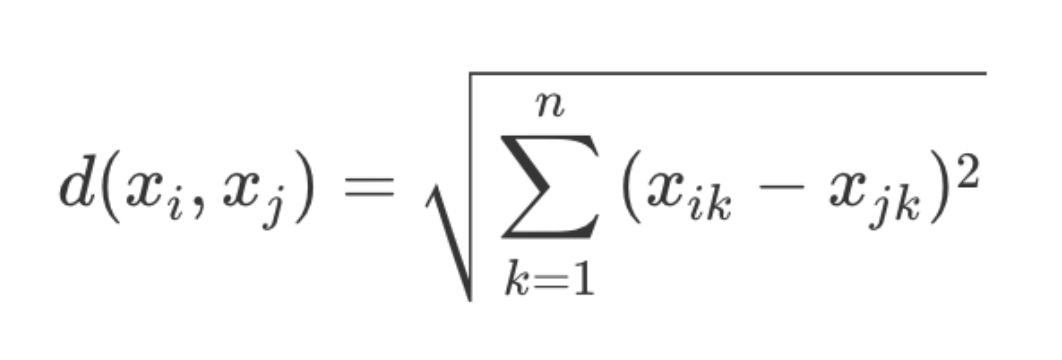
余弦相似度计算公式
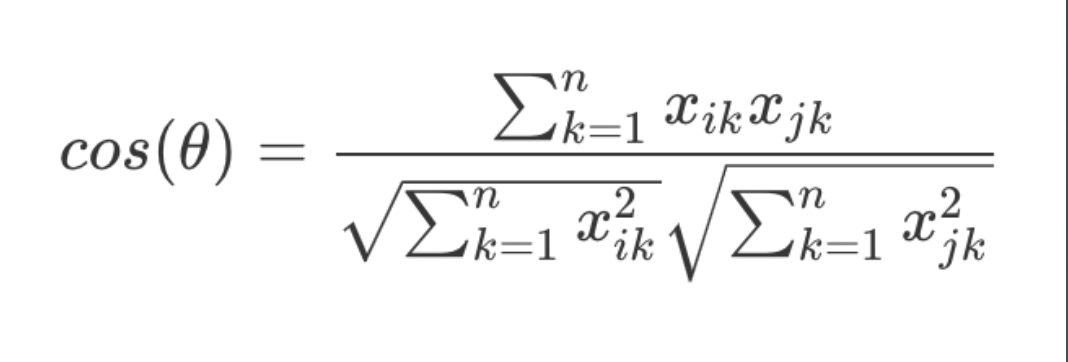
提取样本特征值 TF-IDF 算法
TF 是词频(Term Frequency),表示某个单词在文档中出现的频率

IDF 是逆文档频率(Inverse Document Frequency),表示这个单词在文档中的稀缺程度

贝叶斯分类算法
贝叶斯公式
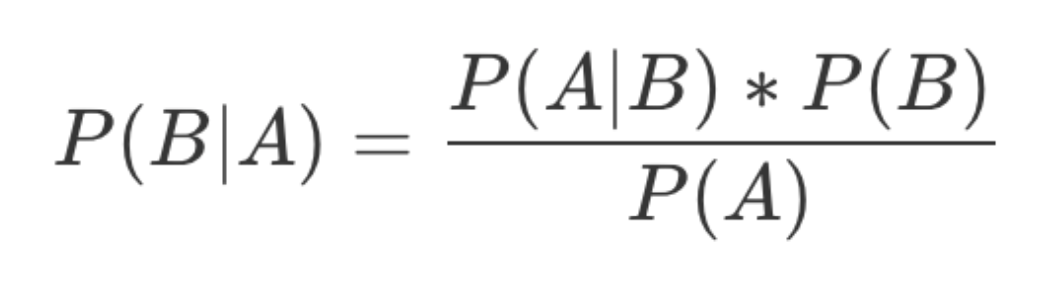
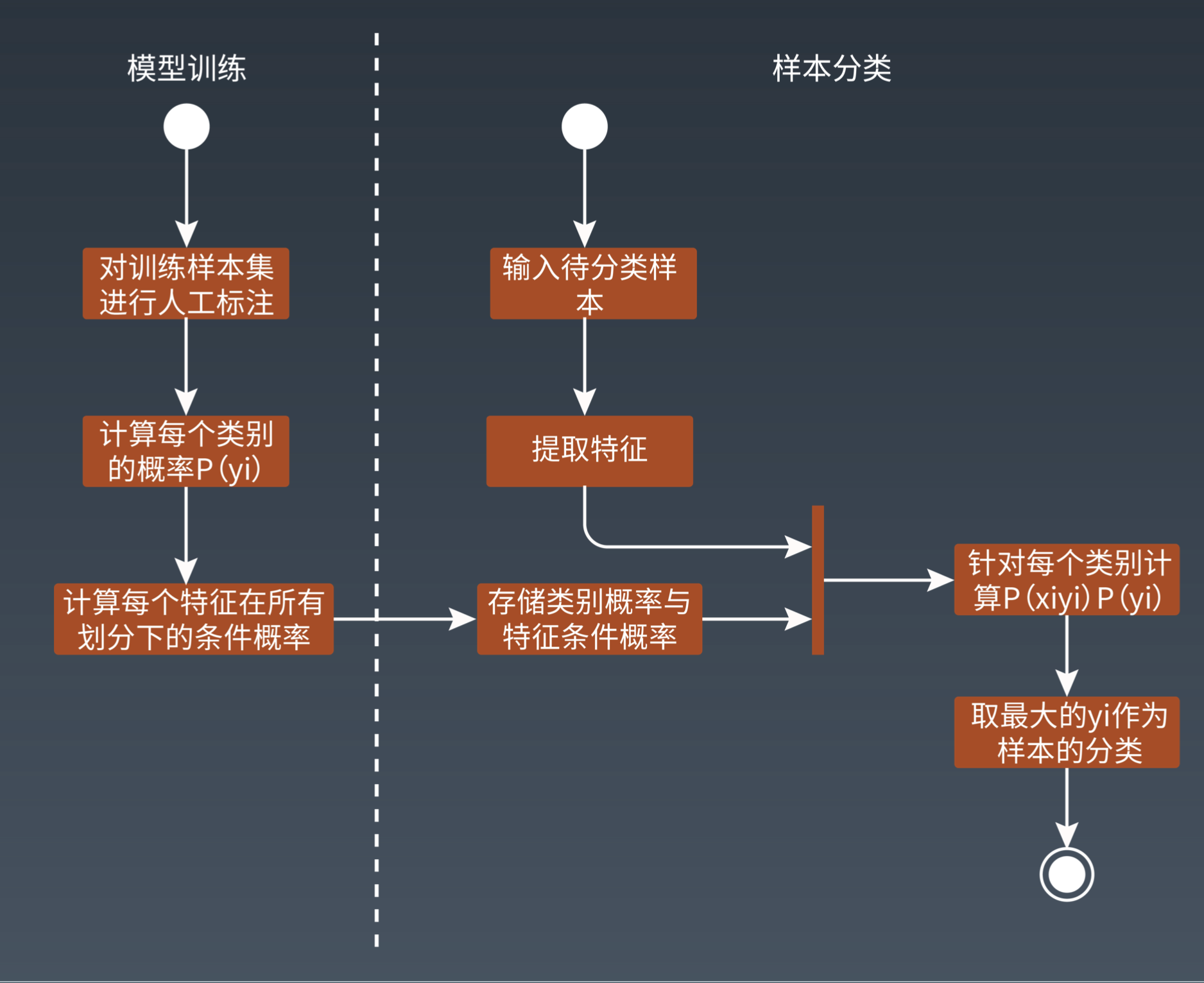
K-means 聚类算法
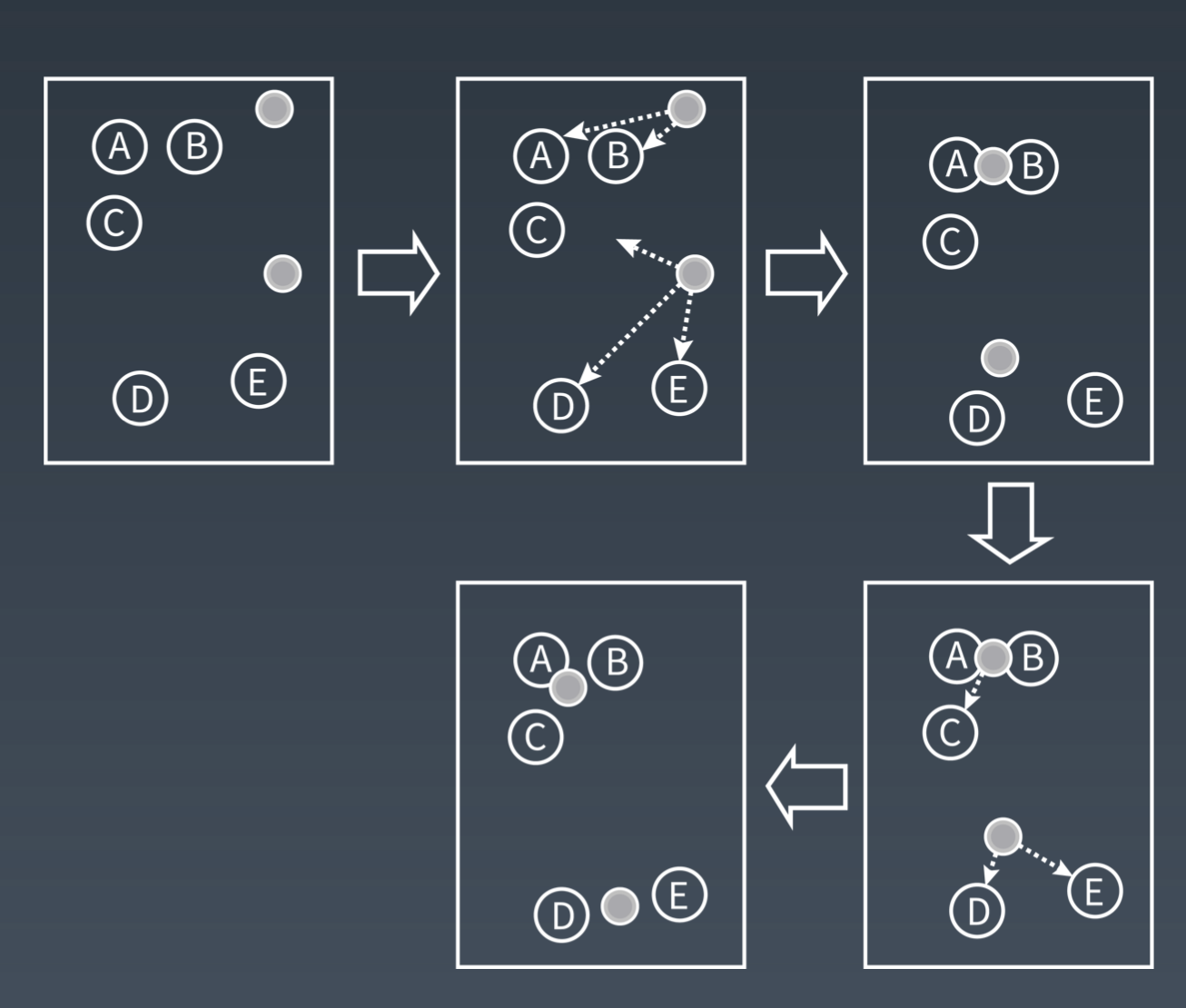
第一步:随机在图中取 K 个种子点,图中 K=2,即图中的实心小圆点
第二步:求图中所有点到这个 K 个种子点的距离,如果一个点离 X 种子点近,则就属于 X 点集群
第三步:对已经分好组的两组数据,分别求其中心点。
第四步:重复第二到第三步,直到每个分组的中心点不再移动。这时候距每个中心点最近的数据聚类为同一组数据
推荐引擎算法
基于人口统计的推荐
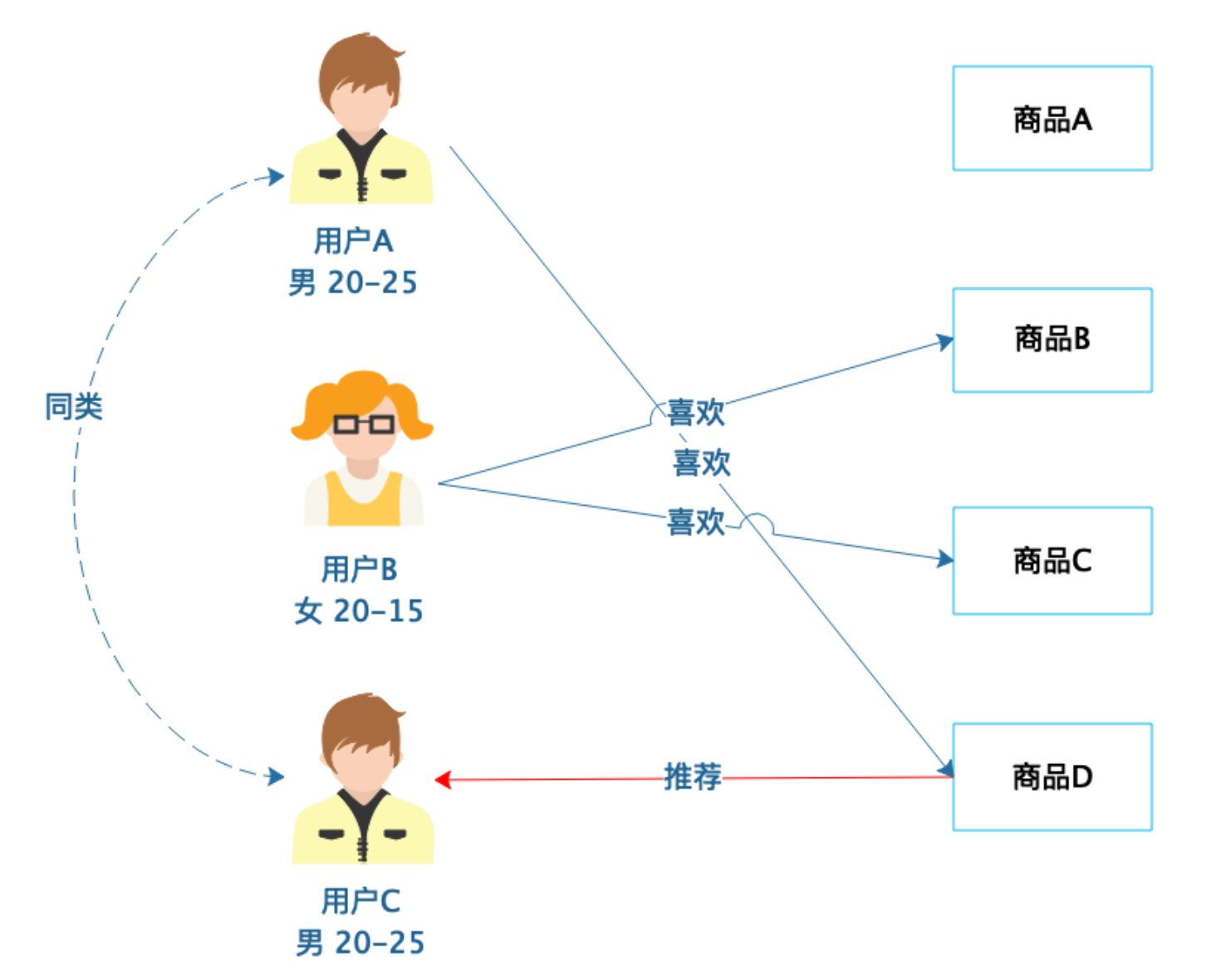
基于商品属性的推荐

基于用户的协同过滤推荐
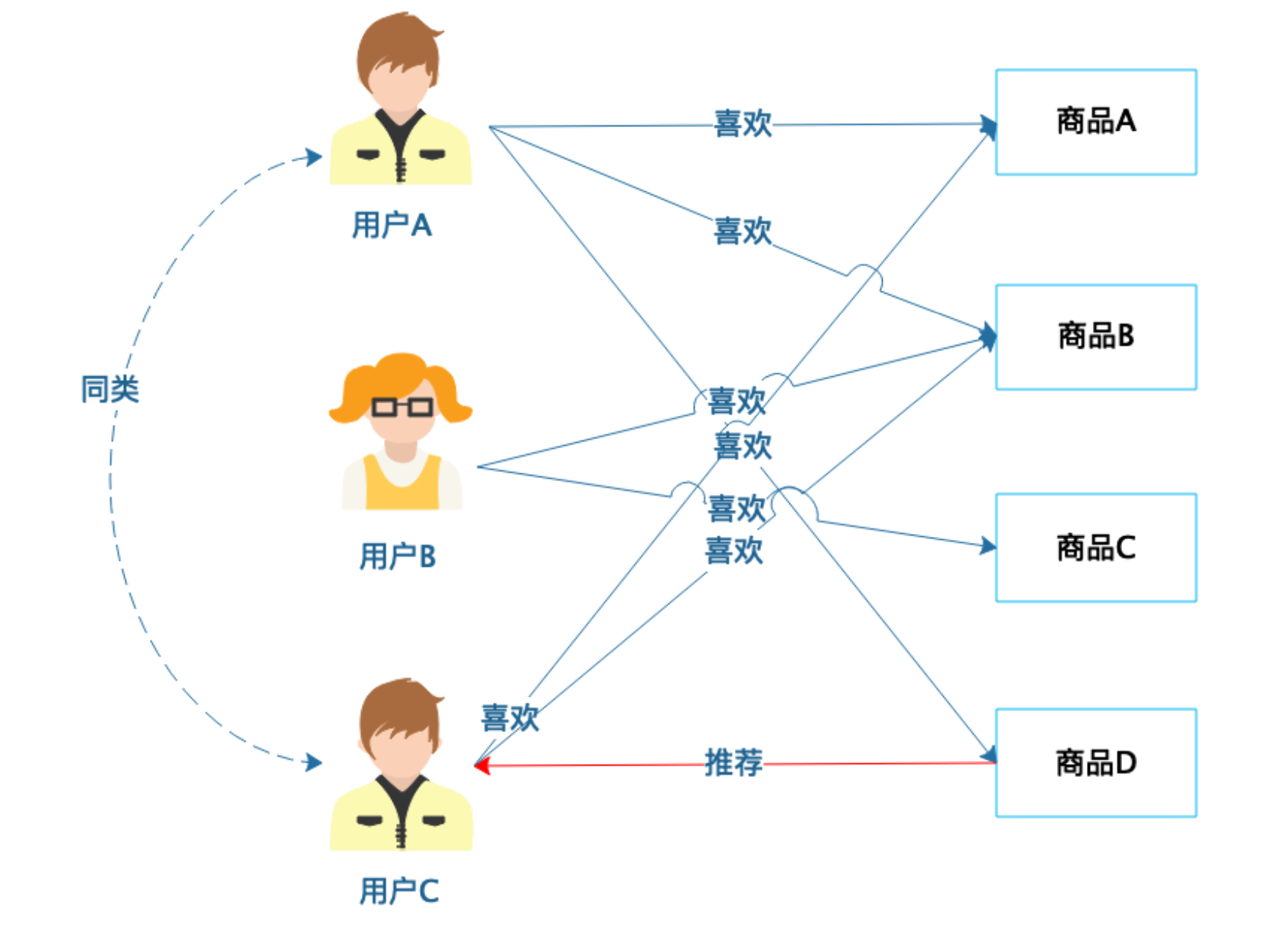
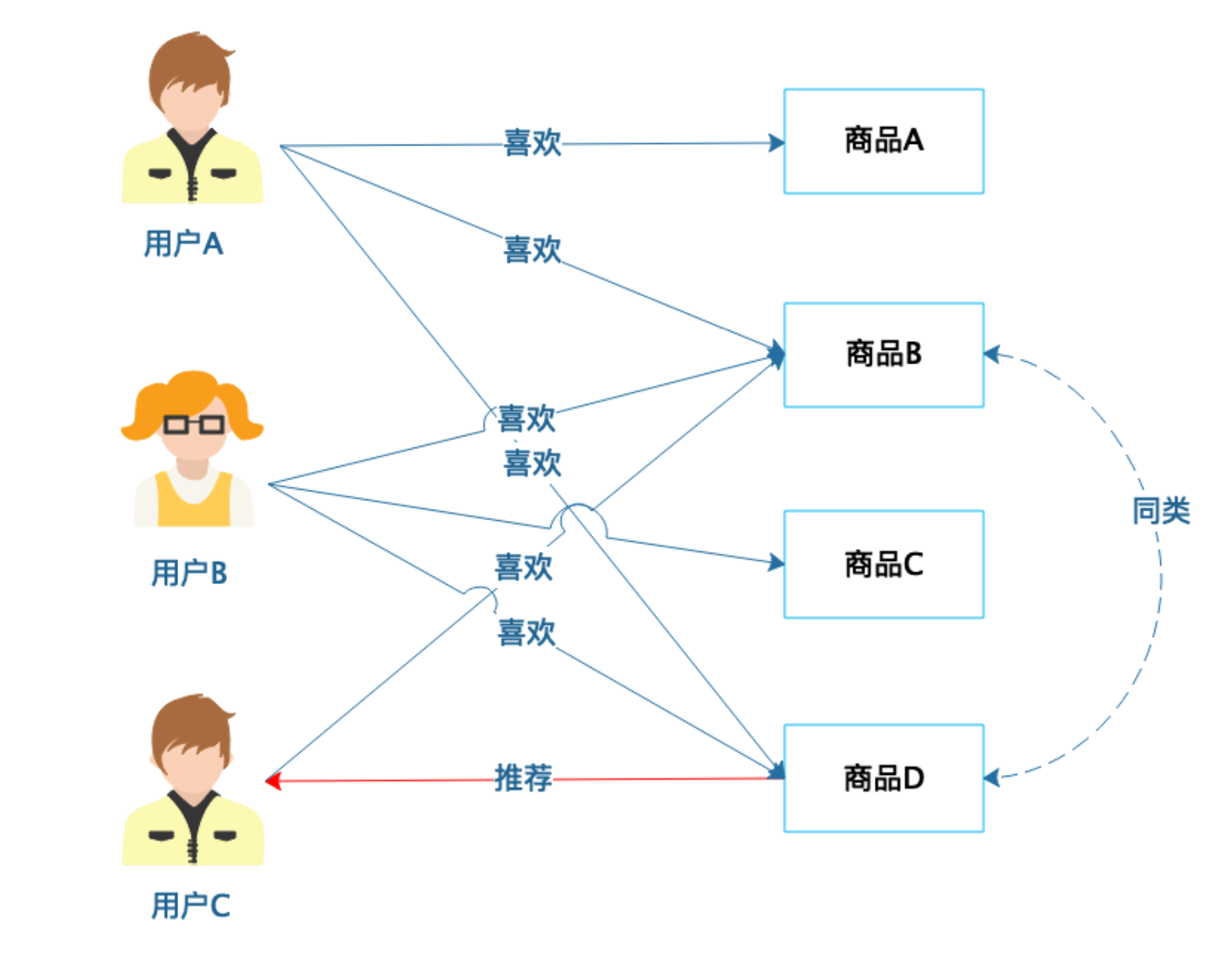
基于商品的协同过滤推荐
机器学习系统架构
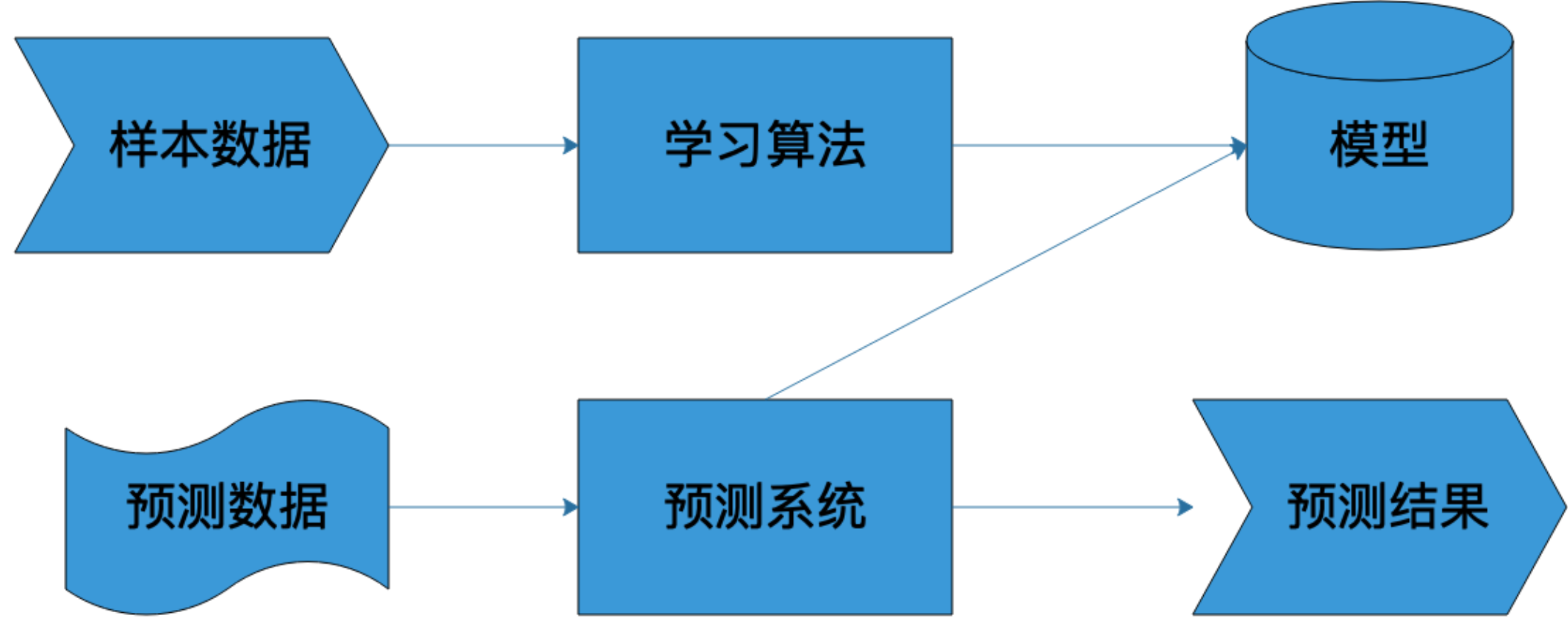
样本
样本就是我们通常说的训练数据,包括输入和结果两部分。T= (x1,y1),(x2,y2)……(xn,yn) xn 代表输入的数据,yn 代表数据的结果
模型
模型就是映射样本输入与样本结果的函数,可能是一个条件概率分布,也可能是一个决策函数。一个具体的机器学习系统所有可能的函数构成了模型的假设空间,数学表示为:
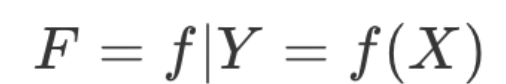
算法
算法就是从模型的假设空间中寻找一个最优的函数,使得样本空间的输入经过函数的映射得到的 f(x)和真实的 Y 值之间的距离最小。这个最优函数通常没法直接通过计算得到,需要用数值计算的方法不断迭代求解。
机器学习中用损失函数来评估模型是否最接近最优解。损失函数用来计算预测值与真实值的差距,常用的有 0-1 损失函数、平方损失函数、绝对损失函数、对数损失函数等。平方损失函数数学表述为:
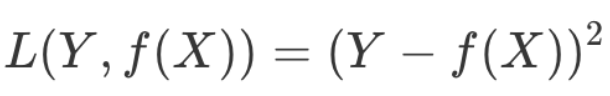
机器学习的数学原理
给定模型类型,也就是给定函数类型的情况下,如果寻找使结构风险最小的函数表达式。由于函数类型给定了,实际上就是求函数的参数。
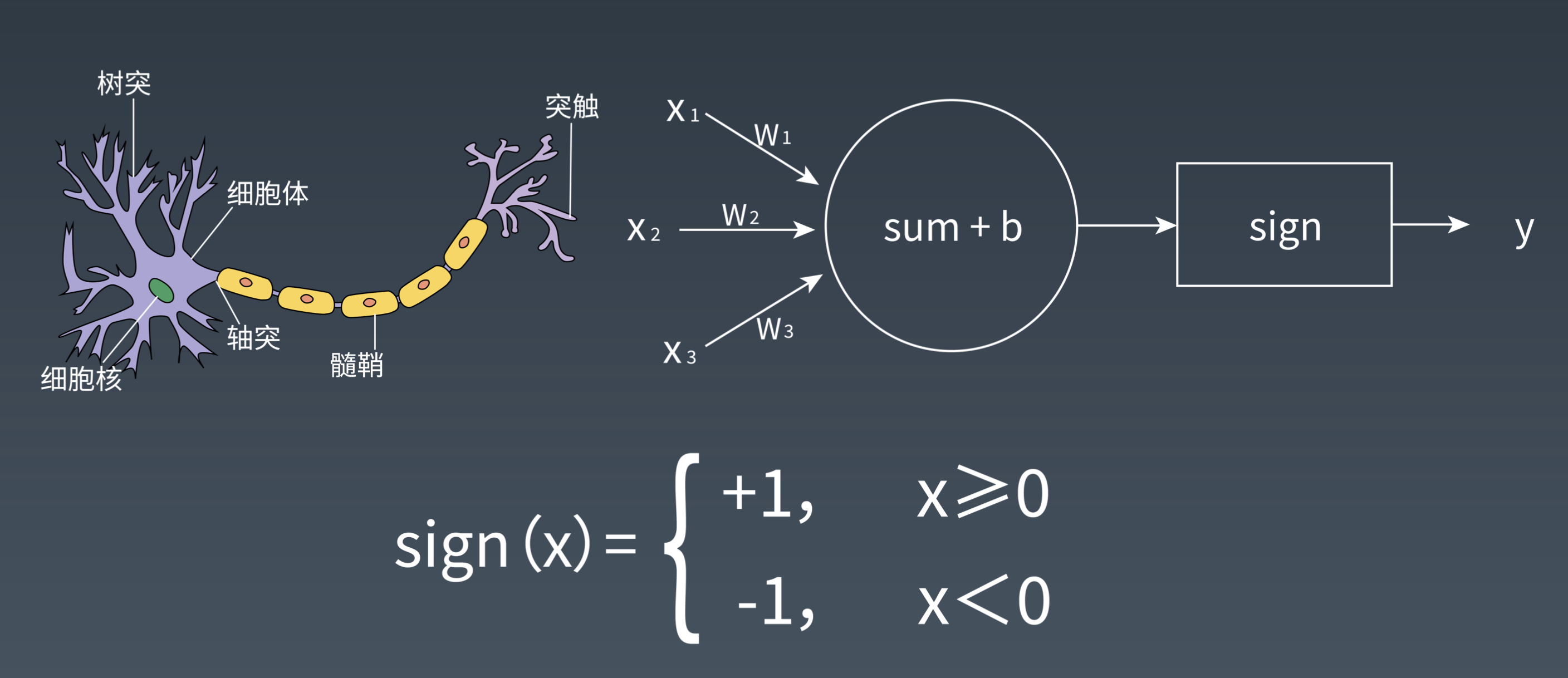
感知机
感知机是一种比较简单的二分类模型,将输入特征分类为+1,-1 两类
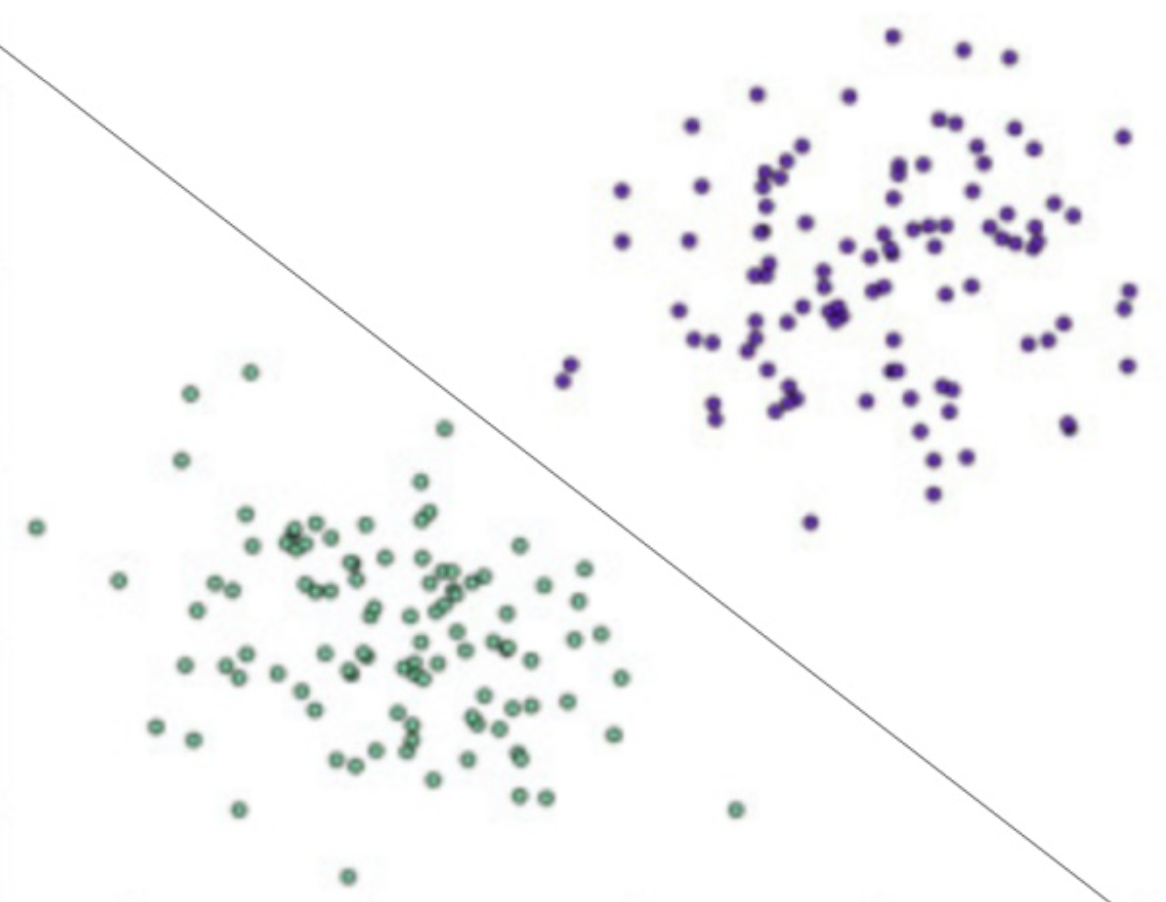
感知机模型
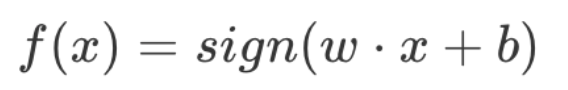
其中 x 代表输入的特征空间向量,输入空间是{-1,+1}, w 为权值向量,b 叫作偏置,sign 是一个符号函数
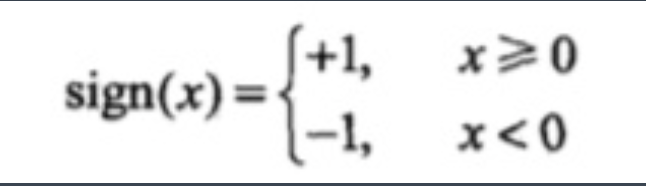
神经网络
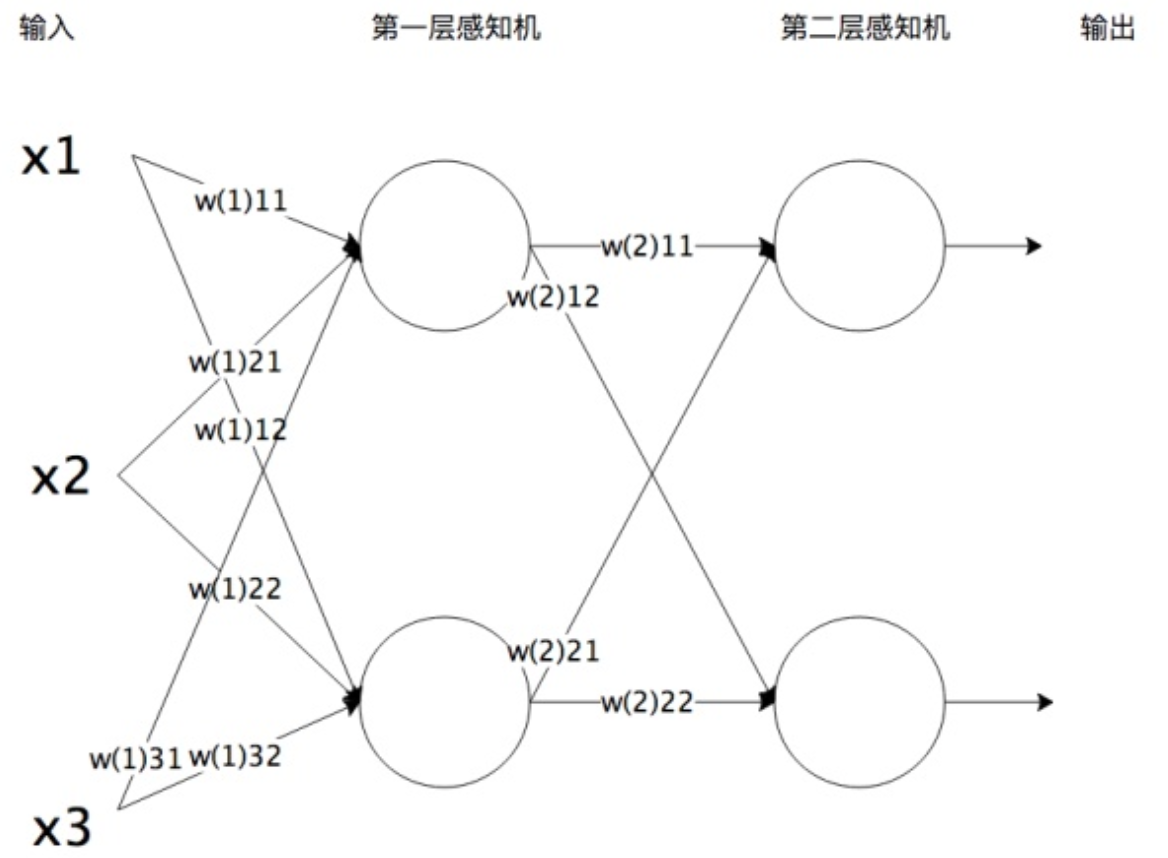
应用
识别数字
各种棋类 AI
……

还未添加个人签名 2018.10.21 加入
还未添加个人简介









评论