极客大学第五周课后作业
分布式缓存
缓存:存储在计算机上的一个原始数据复制集,以便于多次访问。
架构原理以及使用注意事项
缓存的关键指标
缓存命中率
缓存是否有效依赖于能多少次重用同一个缓存响应业务请求,这个度量指标被称作缓存命中率。
影响缓存命中率的因素
缓存键集合大小
缓存可使用内存空间
缓存对象生存时间
缓存键集合大小
缓存中的每个对象使用缓存键进行 识别,定位一个对象的唯一方式就是对缓存键执行精确匹配。
缓存可使用的内存空间
缓存可使用内存空间直接决定了缓存对象的平均大小和缓存对象数量。因为缓存通常存储在内存中,缓存对象可用空间受到严格限制且 相对昂贵。如果想缓存更多的对象,就需要先删除老的对象,再添加新的对象。替换(清除)对象会降低缓存命中率,因为缓存对象被删除后,将来的请求就无法命中了。物理上能缓存的对象越多,缓存命中率就越高。
缓存对象的生存时间
缓存对象生存时间称为 TTL( Time To Live )。需要合理设置缓存的失效时间。
常见的缓存实现形式
通读缓存
通读缓存给客户端返回缓存资源,并在请求未命中缓存时获取实际数据。客户端连接的是通读缓存而不是生成响应的原始服务器。
代理缓存
反向代理缓存
多层反向代理缓存
内容分发网络(CDN)
旁路缓存(cache-aside)
对象缓存是一种旁路缓存,旁路缓存通常是一个独立的键值对(key-value)存储。应用代码通常会询问对象缓存需要的对象是否存在,如果存在,它会获取并使用缓存的对象,如果不存在或已过期, 应用会连接主数据源来组装对象,并将其保存回对象缓存中以便将来使用。
浏览器对象缓存
本地对象缓存
远程分布式对象缓存
一致性hash算法
一致性hash算法采用对2^32取模,来计算位置。
具体细节参考如下博客
http://www.zsythink.net/archives/1182/
消息队列
消息队列可以简单理解为:把要传输的数据放在队列中。实现消息队列可以达到如下效果:
解耦
异步
削峰/限流
消息队列模式
点对点
发布订阅
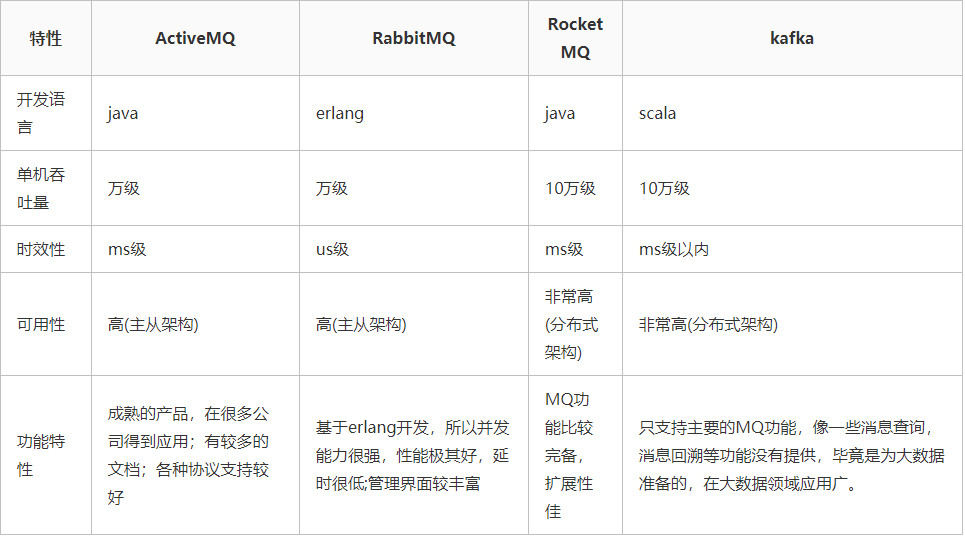
主要MQ产品比较
负载均衡
Load balancing,即负载均衡,是一种计算机技术,用来在多个计算机(计算机集群)、网络连接、CPU、磁盘驱动器或其他资源中分配负载,以达到最优化资源使用、最大化吞吐率、最小化响应时间、同时避免过载的目的。
负载均衡算法
轮询(Round Robin):顺序循环将请求一次顺序循环地连接每个服务器。当其中某个服务器发生第二到第7 层的故障,BIG-IP 就把其从顺序循环队列中拿出,不参加下一次的轮询,直到其恢复正常。
比率(Ratio):给每个服务器分配一个加权值为比例,根椐这个比例,把用户的请求分配到每个服务器。当其中某个服务器发生第二到第7 层的故障,BIG-IP 就把其从服务器队列中拿出,不参加下一次的用户请求的分配, 直到其恢复正常。
优先权(Priority):给所有服务器分组,给每个组定义优先权,BIG-IP 用户的请求,分配给优先级最高的服务器组(在同一组内,采用轮询或比率算法,分配用户的请求);当最高优先级中所有服务器出现故障,BIG-IP 才将请求送给次优先级的服务器组。这种方式,实际为用户提供一种热备份的方式。
课后作业

还未添加个人签名 2018.08.11 加入
还未添加个人简介









评论