一文搞懂二分查找面试
随着行业越发"卷",对于立志进入名企的程序员来说算法已经成为一道迈步过去的槛,算法面试已经成为一种必考项目,在我看来主要是基于以下几个原因。
程序员的最基础能力还是 coding 能力,算法更加能展示程序员的基本功
八股文都可以通过突击复习。但是 coding 能力是需要长期的积累才有的技能。
算法 coding 能力有一定的区分度。能淘汰掉一部分逻辑混乱的程序员。
在算法面试二分查找更是重中之重, 他是我们每个程序员最熟悉的,因为他针对的数据集主要是数组,而数组也是我们最熟悉的数据结构,这样就不存在知识的不对等,因为凡是程序员都知道数组.这样就建立在一个公平的机制下考察大家的 coding 能力。
通常来说在一个给定的有序数组或者螺旋有序数组中要求使用 logn 的时间复杂度求解某一个算法, 90%都需要用到二分查找算法.
一个典型的 leetcode 二分查找题目如下
给定一个 n 个元素有序的(升序)整型数组 nums 和一个目标值 target ,写一个函数搜索 nums 中的 target,如果目标值存在返回下标,否则返回 -1。
示例 1:
输入: nums = [-1,0,3,5,9,12], target = 9 输出: 4 解释: 9 出现在 nums 中并且下标为 4 示例 2:
输入: nums = [-1,0,3,5,9,12], target = 2 输出: -1 解释: 2 不存在 nums 中因此返回 -1
通常我们的解法是这样的
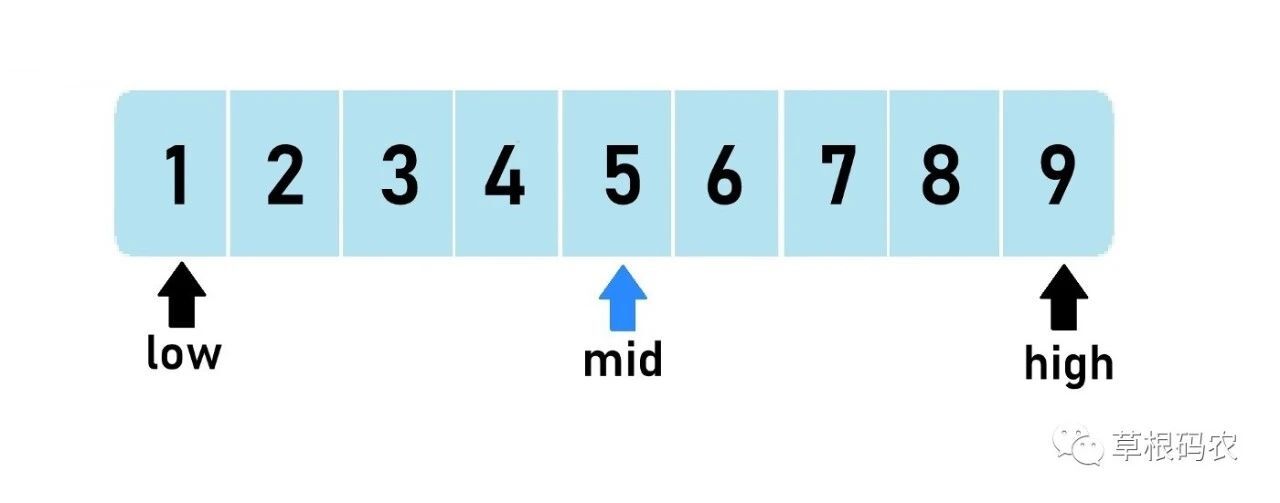
定义一个左指针 left,一个右指针 right, 我们取 left 和 right 的中间点 mid,如果 nums[mid]==target,那么我们就找到了这个节点,返回 mid 即可, 如果要找的 target 小于 nums[mid] 那证明 target 在节点 mid 的左边,我们修改 right 指针为 mid-1,反之证明 target 在 mid 节点的右半部分,我们修改 left 指针为 mid+1,如此循环往复,直到 left>right 为止.
注意事项
① 处必须是 left<=right 而不能是 left<right 因为有可能当 left==right 的时候,刚好是最后一个节点就是结果,那么如果不再进行最后一次处理的话,有可能就返回错误的-1.
② 处如果写成(left+right)/2,有可能发生整形溢出, 所以最好的方式 写成 left + (right - left)/2 或者 left + ((right - left) << 1) 这样给面试官你考虑问题很严谨,面试官会非常欣赏的。
③ 处必须是 mid-1 或者 mid+1 不能是直接 right=mid 或者 left=mid,因为这样很容易发生死循环.因为如果结果不存在的情况下,而此时省下刚好两个元素,那么经过一次循环内部之后,left 和 right 还是没有该变,这样就产生死循环了。
由此可见完全写正确一个二分查找还是有些细节需要注意的。
这是最最经典的二分查找, 面试中考察此题的概率微乎其微, 通常都是二分查找的变种问题。不同的问题 注意事项也不同.有的题目 left < right 就可以,有的题目 right=mid 也可以.那么这种边界问题该如何考虑呢?
解决边界问题的终极武器-模板
这个模板的核心有三个部分.
start + 1 < end
start + (end - start) / 2
nums[mid] ==, <, >
A[start] A[end] ? target
循环的条件一定是 start + 1 < end;
取中间节点写成 start + (end - start) / 2 避免整型溢出
缩小规模的时候都是 start = mid 或者 end = mid 不用 mid - 1 或者 mid+1, 因为循环结束条件是 start + 1 < end 不用担心会发生死循环, 所以可以无脑的写成 end = mid 或者 start = mid 等最后统一判断.
在循环结束之后剩余两个相邻的元素,也就是说我们通过循环内部的二分查找已经将元素缩小为 left 和 right 指向的两个值了,那么在这两个值中我们判断是不是我们要查找的 target 就行。
我们要理解一下每次进行二分的目的是为了缩小数据规模为原来的一半. 去掉没有解的一半,留下有解的另一半. 这是一个逐步缩小数据规模的过程. 之所以要在最后需要在判断一次 start 和 end 是否为 target 的目的是我们的 start 和 end 是有可能就是结果的。
接下里我们利用我们所学的模板和二分查找缩小数据规模的思想来解答二分查找常见的面试题目
给一个排序好的整形数组和一个 target 要求找到这 target 在整形数组 first/last/any 出现的位置。
给定一个排序的整数数组(升序)和一个要查找的整数
target,用 O(logn)O(logn)的时间查找到target第一次出现的下标(从0开始),如果target不存在于数组中,返回-1。
套用上面的模板.题目答案为
需要注意的是,因为这里是查找的第一次出现的下标, 所以当 nums[mid] == target 的时候, 我们可以舍弃 [mid+1,length-1]部分, 但是不能直接返回, 只能缩小数据规模令 right = mid; 令 right=mid 而不是 right=mid-1 就是因为有可能 right 就是最终的结果集.right 左边在没有等于 target 的元素。
最后判断的时候需要先判断 left,因为寻找的是第一次出现的,如果最后留下的 left 和 right 都是 target 的,那么首先判断 left 就可以找到第一个出现的下标。
给一个升序数组,找到
target最后一次出现的位置,如果没出现过返回-1
需要注意的是,因为这里是查找的最后出现的下标, 所以当 nums[mid] == target 的时候, 我们可以舍弃 [0,mid-1]部分, 但是不能直接返回, 只能缩小数据规模令 left = mid; 令 left=mid 而不是 left=mid-1 就是因为有可能 left 就是最终的结果集.right 左边在没有等于 target 的元素。
最后判断的时候需要先判断 right,因为寻找的是最后一次出现的,如果最后留下的 left 和 right 都是 target 的,那么首先判断 right 就可以找到最后一个出现 target 的下标。
你是产品经理,目前正在带领一个团队开发新的产品。不幸的是,你的产品的最新版本没有通过质量检测。由于每个版本都是基于之前的版本开发的,所以错误的版本之后的所有版本都是错的。
假设你有
n个版本[1, 2, ..., n],你想找出导致之后所有版本出错的第一个错误的版本。你可以通过调用
bool isBadVersion(version)接口来判断版本号version是否在单元测试中出错。实现一个函数来查找第一个错误的版本。你应该尽量减少对调用 API 的次数。示例 1:
输入:n = 5, bad = 4 输出:4 解释: 调用 isBadVersion(3) -> false 调用 isBadVersion(5) -> true 调用 isBadVersion(4) -> true 所以,4 是第一个错误的版本。
此题目的意思是从某一个版本之后,之后所有的提交都是错误。抽象出题目来说就是找到第一个 错误的的提交。跟上面找出 first 出现的 target 实际上是一个意思。
上面的 isBadVersion(mid) 如果是错误答案,那么证明答案区间就是在 [left,mid] 中,这样我们就可以去掉 [mide+1,right] 区间、二分法的灵魂就是去掉一部分没有答案的区间,留下有解的区间。
在 Rotated Sorted Array 中查找
描述
给定一个有序数组,但是数组以某个元素作为支点进行了旋转(比如,
0 1 2 4 5 6 7可能成为4 5 6 7 0 1 2)。给定一个目标值target进行搜索,如果在数组中找到目标值返回数组中的索引位置,否则返回-1。你可以假设数组中不存在重复的元素。样例
样例 1:
输入:
数组 = [4, 5, 1, 2, 3] target = 1 输出3
这道题目有一个很重要的特征就是假设数组中不存在重复的元素。题目中说数组是一个螺旋数组。我们用一个抽象图来表明数据的形状。
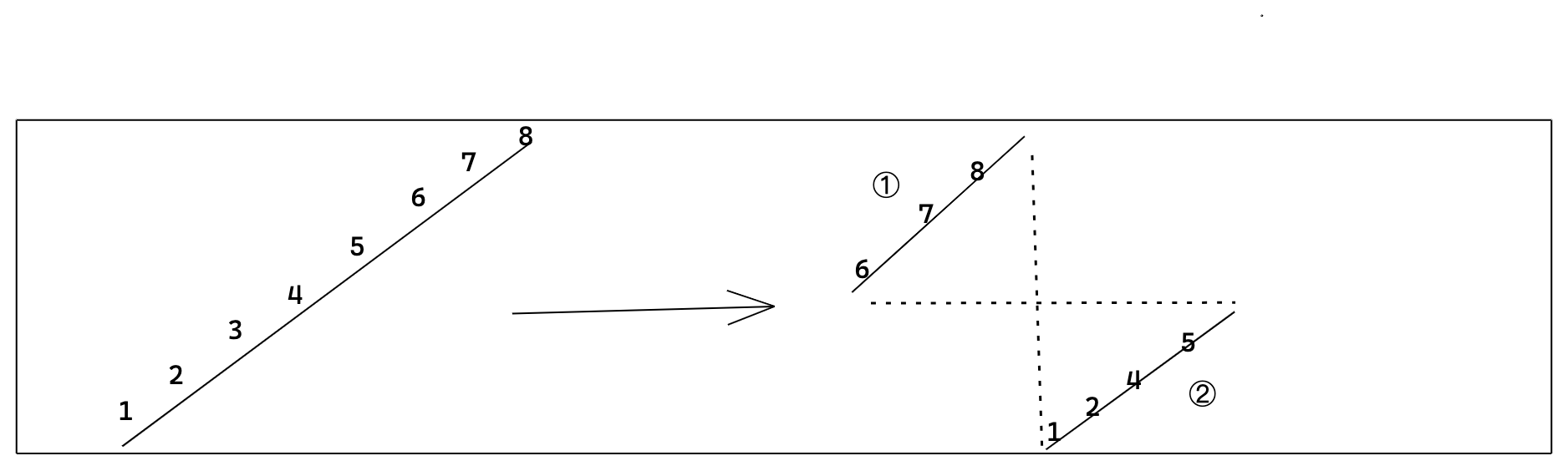
也就是将一个整形数组 1,2,3,4,5,6,7,8 在 元素 6 处进行旋转之后 6,7,8 排到首位.这样就形成右边的图形形状。
根据核心二分查找的思想,每次都能舍弃掉一部分,留下有解的一部分。这样当经过一次 left + (right - left) / 2 计算之后 mid 有可能在 ①处、也有可能在 ②处。
所以根据此条件我们就可以很轻松的写出解答。
在来看一到此题目的变种题目
已知存在一个按非降序排列的整数数组 nums ,数组中的值不必互不相同。
在传递给函数之前,nums 在预先未知的某个下标 k(0 <= k < nums.length)上进行了 旋转 ,使数组变为 [nums[k], nums[k+1], ..., nums[n-1], nums[0], nums[1], ..., nums[k-1]](下标 从 0 开始 计数)。例如, [0,1,2,4,4,4,5,6,6,7] 在下标 5 处经旋转后可能变为 [4,5,6,6,7,0,1,2,4,4] 。
给你 旋转后 的数组 nums 和一个整数 target ,请你编写一个函数来判断给定的目标值是否存在于数组中。如果 nums 中存在这个目标值 target ,则返回 true ,否则返回 false 。
示例 1:
输入:nums = [2,5,6,0,0,1,2], target = 0 输出:true 示例 2:
输入:nums = [2,5,6,0,0,1,2], target = 3 输出:false
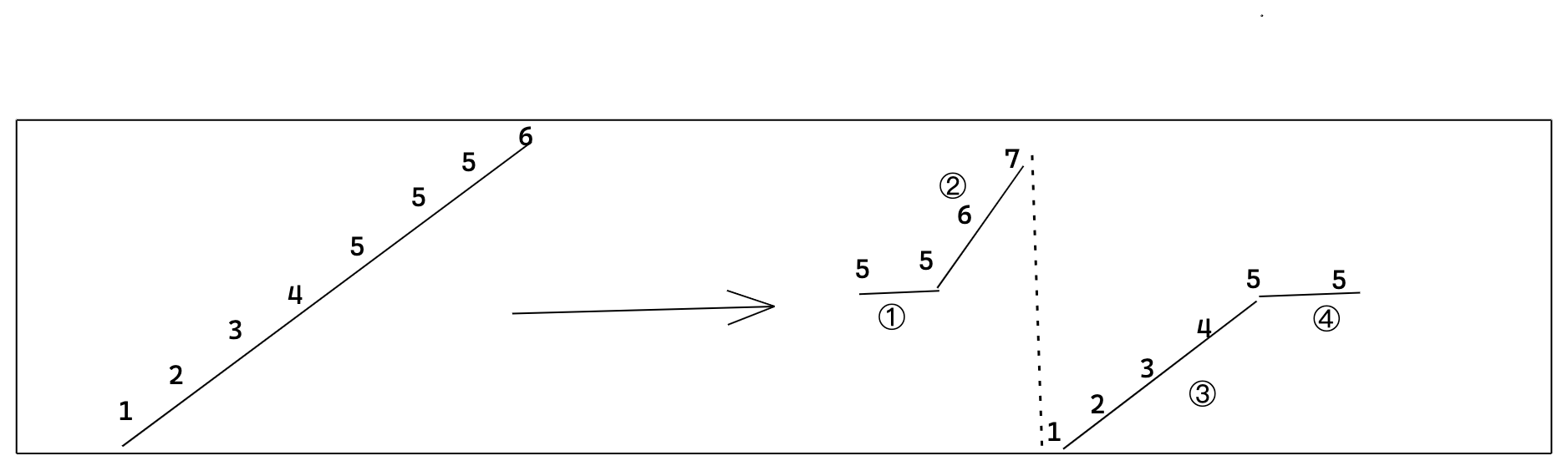
这里有一个区别点和上面那道题目就是 nums 元素不一定互不相同.是有可能存在相同的元素的。但是还是按照非降序排列。类似于题目中给出的例子 5,5,6,7,1,2,3,4,5,5
此题目要求只要找到 target 就返回 true.类似于我们第一个题目中找到数组中 target 的 any 位置。
话不多说、我们仍然根据题目将 nums 数组直观的用图形表示处理。
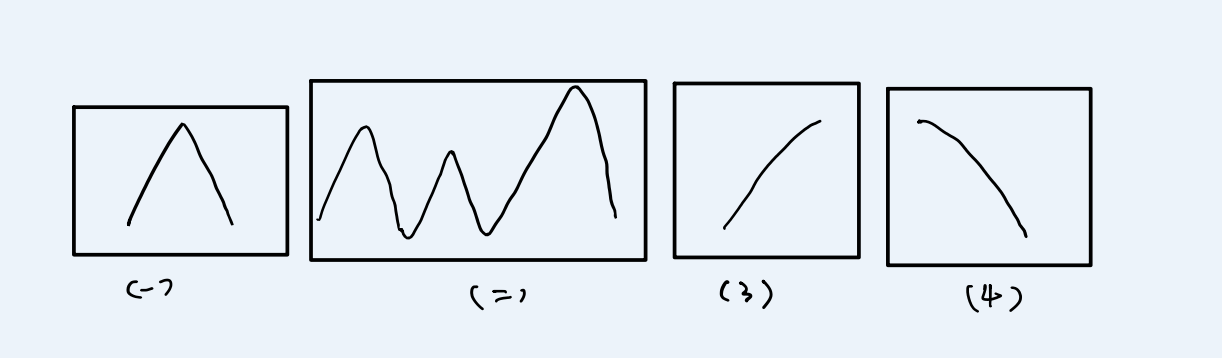
寻找峰值
给定一个整数数组(size 为
n),其具有以下特点:
相邻位置的数字是不同的
A[0] < A[1]并且A[n - 2] > A[n - 1]假定 P 是峰值的位置则满足
A[P] > A[P-1]且A[P] > A[P+1],返回数组中任意一个峰值的位置。数组保证至少存在一个峰如果数组存在多个峰,返回其中任意一个就行数组至少包含 3 个数
样例
样例 1:
输入:
A = [1, 2, 1, 3, 4, 5, 7, 6]输出:
1解释:
返回任意一个峰顶元素的下标,6 也同样正确。
同理我们根据题目抽象出数据模型图。这样直观的可以看出数据趋势图。
总结
本文我们主要就二分查找算法面试以及相关的缩小区间的问题进行了分享。其实我更愿意称这种问题为缩小区间问题。在循环内部经过一次取中间值来排除一部分区间的元素,逐步的缩小区间,来达到找到题目最终要求的结果.并且我们总结了模板,避免各种边界条件考虑不周。读者可以将本文所学 在 leetcode 中找到更多的题目进行训练。
参考题目:
https://leetcode-cn.com/problems/binary-search/
https://leetcode-cn.com/problems/search-insert-position/
https://leetcode-cn.com/problems/sqrtx/
https://leetcode-cn.com/problems/search-in-rotated-sorted-array-ii/
https://leetcode-cn.com/problems/search-in-rotated-sorted-array/
https://leetcode-cn.com/problems/find-peak-element/

还未添加个人签名 2017.12.22 加入
还未添加个人简介









评论