多核心 Linux 内核路径优化的不二法门之 -slab 与伙伴系统
Linux 内核的 slab 来自一种很简单的思想,即事先准备好一些会频繁分配,释放的数据结构。然而标准的 slab 实现太复杂且维护开销巨大,因此便分化 出了更加小巧的 slub,因此本文讨论的就是 slub,后面所有提到 slab 的地方,指的都是 slub。另外又由于本文主要描述内核优化方面的内容,并不 是基本原理介绍,因此想了解 slab 细节以及代码实现的请自行百度或者看源码。
单 CPU 上单纯的 slab
下图给出了单 CPU 上 slab 在分配和释放对象时的情景序列:
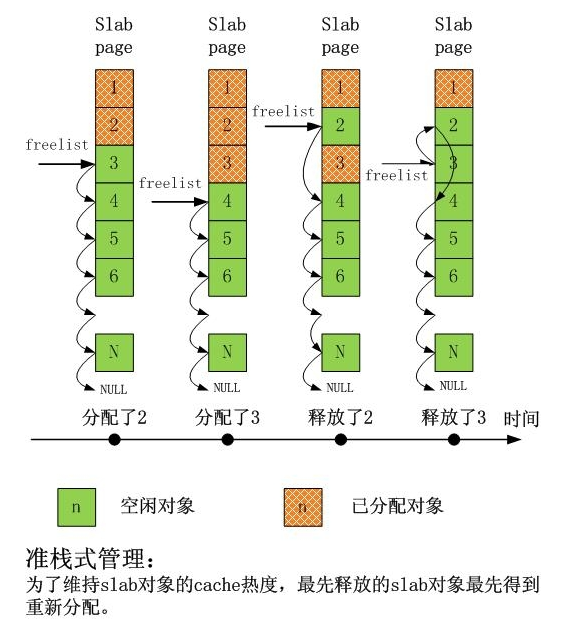
可以看出,非常之简单,而且完全达到了 slab 设计之初的目标。
扩展到多核心 CPU
现在我们简单的将上面的模型扩展到多核心 CPU,同样差不多的分配序列如下图所示:
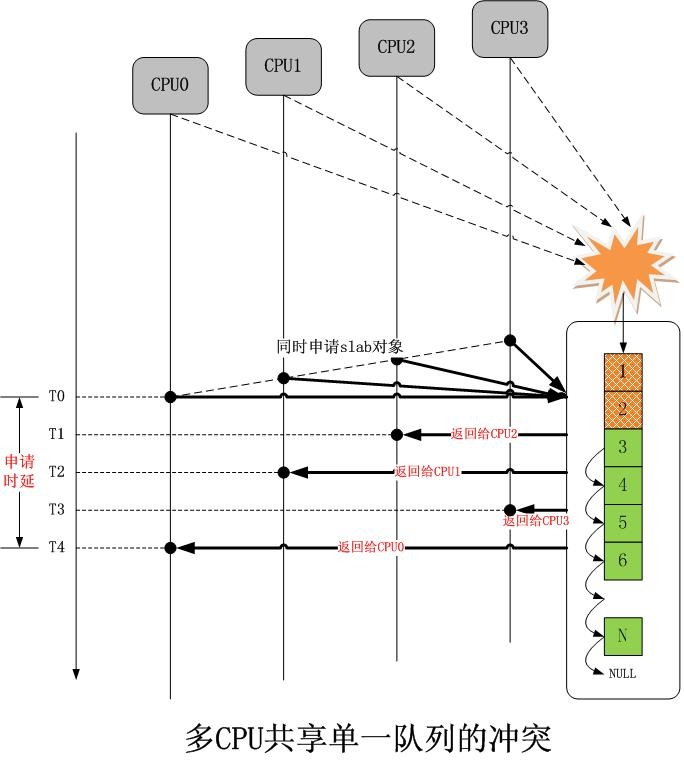
我们看到,在只有单一 slab 的时候,如果多个 CPU 同时分配对象,冲突是不可避免的,解决冲突的几乎是唯一的办法就是加锁排队,然而这将大大增加延迟,我们看到,申请单一对象的整个时延从 T0 开始,到 T4 结束,这太久了。
多 CPU 无锁化并行化操作的直接思路-复制给每个 CPU 一套相同的数据结构。
不二法门就是增加“每 CPU 变量”。对于 slab 而言,可以扩展成下面的样子:
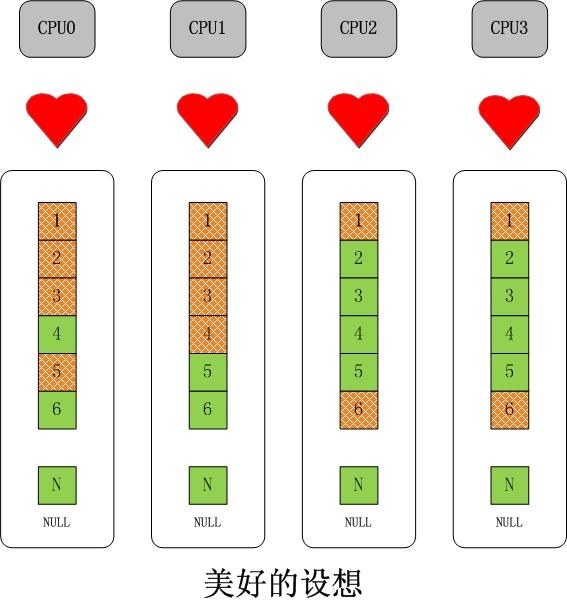
如果以为这么简单就结束了,那这就太没有意义了。
问题
首先,我们来看一个简单的问题,如果单独的某个 CPU 的 slab 缓存没有对象可分配了,但是其它 CPU 的 slab 缓存仍有大量空闲对象的情况,如下图所示:
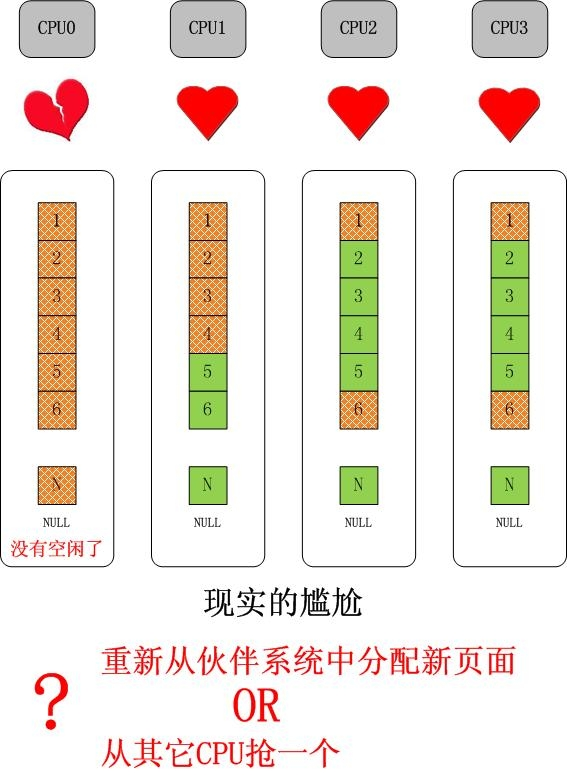
这 是可能的,因为对单独一种 slab 的需求是和该 CPU 上执行的进程/线程紧密相关的,比如如果 CPU0 只处理网络,那么它就会对 skb 等数据结构有大量的 需求,对于上图最后引出的问题,如果我们选择从伙伴系统中分配一个新的 page(或者 pages,取决于对象大小以及 slab cache 的 order),那么久而久之就会造成 slab 在 CPU 间分布的不均衡,更可能会因此吃掉大量的物理内存,这都是不希望看到的。
在继续之前,首先要明确的是,我们需要在 CPU 间均衡 slab,并且这些必须靠 slab 内部的机制自行完成,这个和进程在 CPU 间负载均衡是完全不同的, 对进程而言,拥有一个核心调度机制,比如基于时间片,或者虚拟时钟的步进速率等,但是对于 slab,完全取决于使用者自身,只要对象仍然在使用,就不能剥 夺使用者继续使用的权利,除非使用者自己释放。因此 slab 的负载均衡必须设计成合作型的,而不是抢占式的。
好了。现在我们知道,从伙伴系统重新分配一个 page(s)并不是一个好主意,它应该是最终的决定,在执行它之前,首先要试一下别的路线。
现在,我们引出第二个问题,如下图所示:
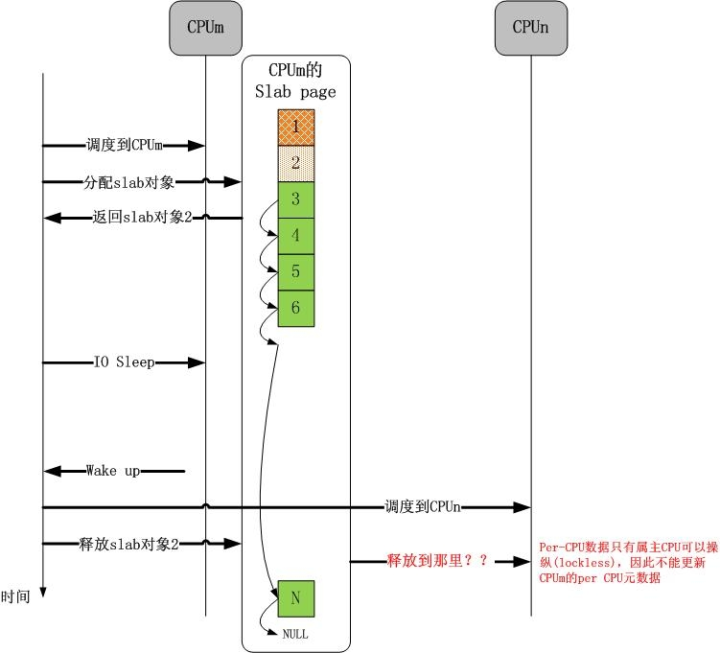
谁也不能保证分配 slab 对象的 CPU 和释放 slab 对象的 CPU 是同一个 CPU,谁也不能保证一个 CPU 在一个 slab 对象的生命周期内没有分配新的 page(s),这期间的复杂操作谁也没有规定。这些问题该怎么解决呢?事实上,理解了这些问题是怎么解决的,一个 slab 框架就彻底理解了。
问题的解决-分层 slab cache
无级变速总是让人向往。
如果一个 CPU 的 slab 缓存满了,直接去抢同级别的别的 CPU 的 slab 缓存被认为是一种鲁莽且不道义的做法。那么为何不设置另外一个 slab 缓存,获 取它里面的对象不像直接获取 CPU 的 slab 缓存那么简单且直接,但是难度却又不大,只是稍微增加一点消耗,这不是很好吗?事实上,CPU 的 L1,L2,L3 cache 不就是这个方案设计的吗?这事实上已经成为 cache 设计的不二法门。这个设计思想同样作用于 slab,就是 Linux 内核的 slub 实现。 现在可以给出概念和解释了。
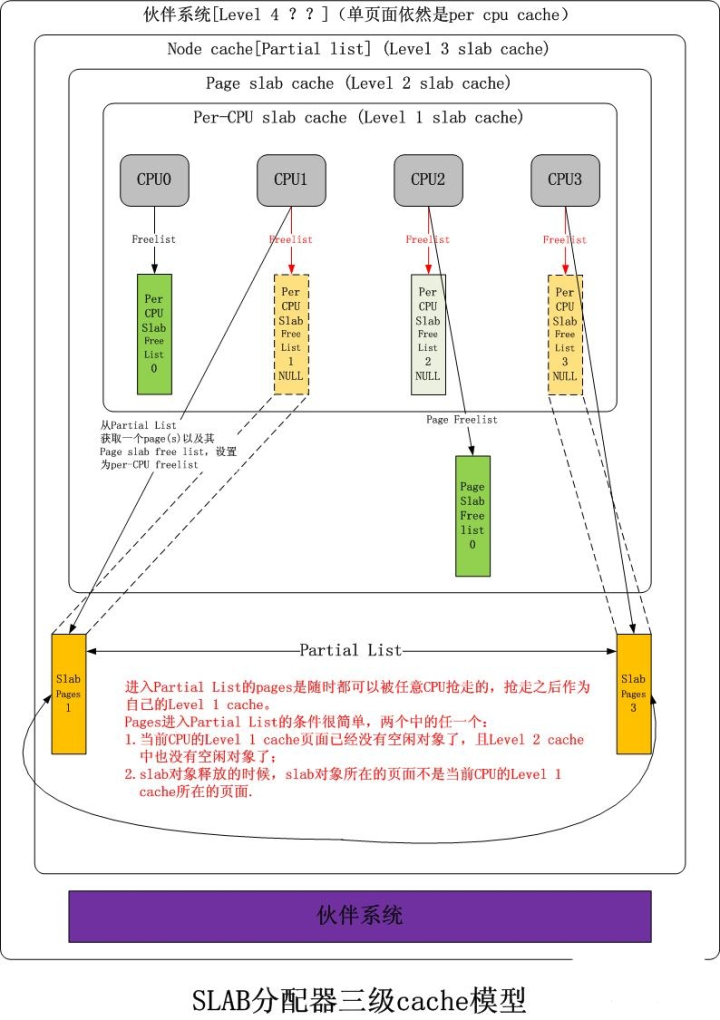
Linux kernel slab cache:一个分为 3 层的对象 cache 模型。
Level 1 slab cache:一个空闲对象链表,每个 CPU 一个的独享 cache,分配释放对象无需加锁。
Level 2 slab cache:一个空闲对象链表,每个 CPU 一个的共享 page(s) cache,分配释放对象时仅需要锁住该 page(s),与 Level 1 slab cache 互斥,不互相包容。
Level 3 slab cache:一个 page(s)链表,每个 NUMA NODE 的所有 CPU 共享的 cache,单位为 page(s),获取后被提升到对应 CPU 的 Level 1 slab cache,同时该 page(s)作为 Level 2 的共享 page(s)存在。
共享 page(s):该 page(s)被一个或者多个 CPU 占 有,每一个 CPU 在该 page(s)上都可以拥有互相不充图的空闲对象链表,该 page(s)拥有一个唯一的 Level 2 slab cache 空闲链表,该链表与上述一个或多个 Level 1 slab cache 空闲链表亦不冲突,多个 CPU 获取该 Level 2 slab cache 时必须争抢,获取后可以将该链表提升成自己的 Level 1 slab cache。
该 slab cache 的图示如下:
其行为如下图所示:

2 个场景
对于常规的对象分配过程,下图展示了其细节:
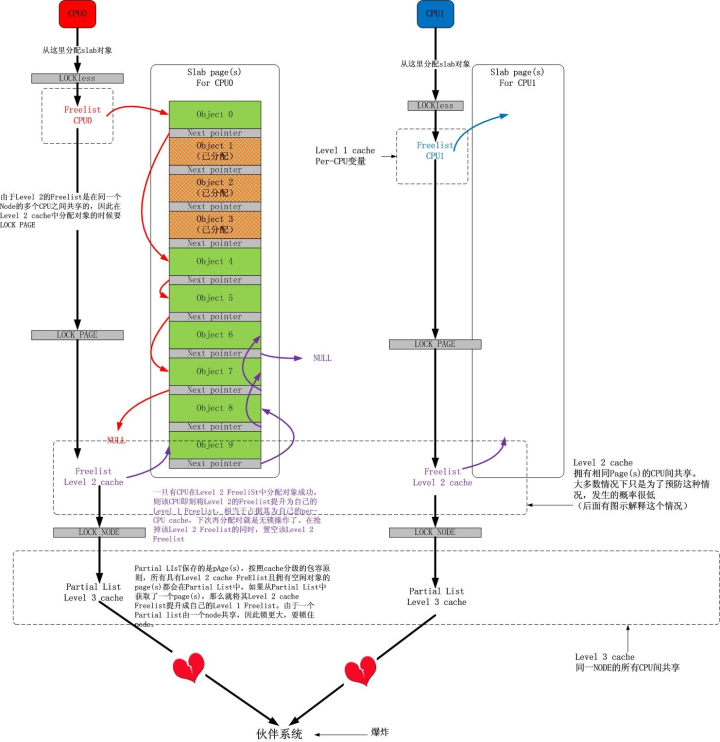
事实上,对于多个 CPU 共享一个 page(s)的情况,还可以有另一种玩法,如下图所示:
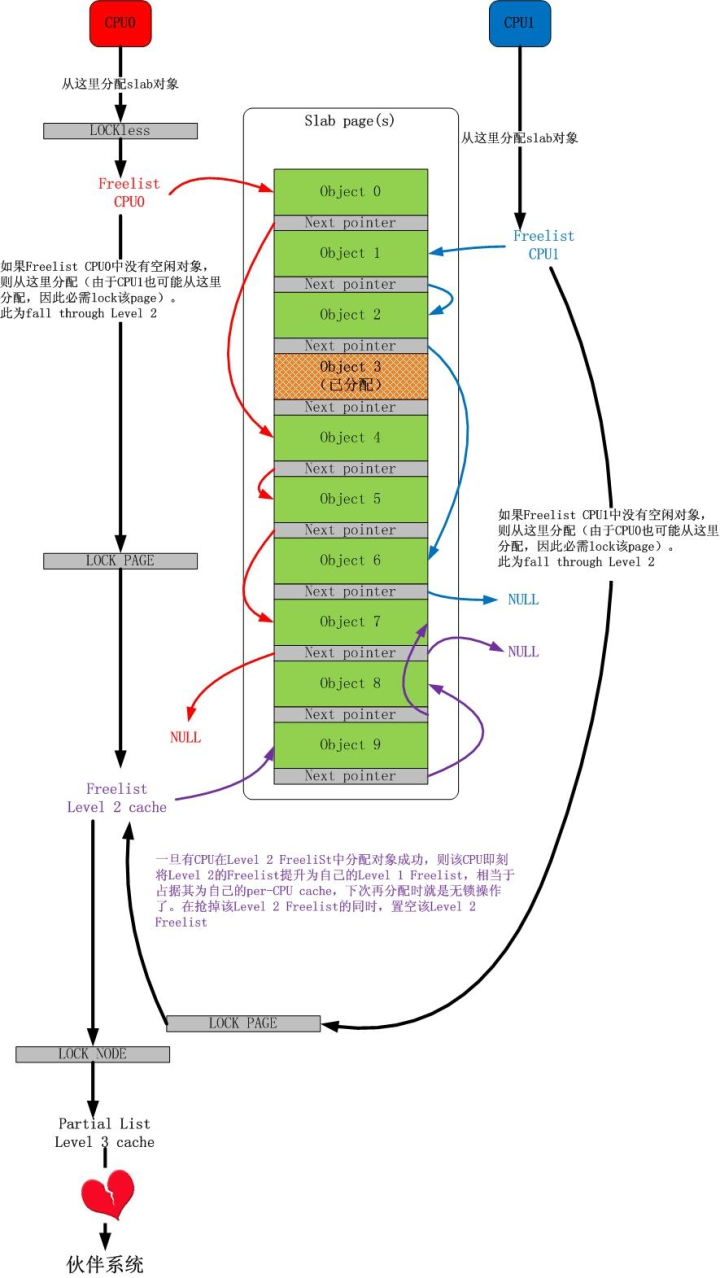
伙伴系统
前面我们简短的体会了 Linux 内核的 slab 设计,不宜过长,太长了不易理解.但是最后,如果 Level 3 也没有获取 page(s),那么最终会落到终极的伙伴系统。
伙伴系统是为了防内存分配碎片化的,所以它尽可能地做两件事:
1).尽量分配尽可能大的内存 2).尽量合并连续的小块内存成一块大内存
我们可以通过下面的图解来理解上面的原则:
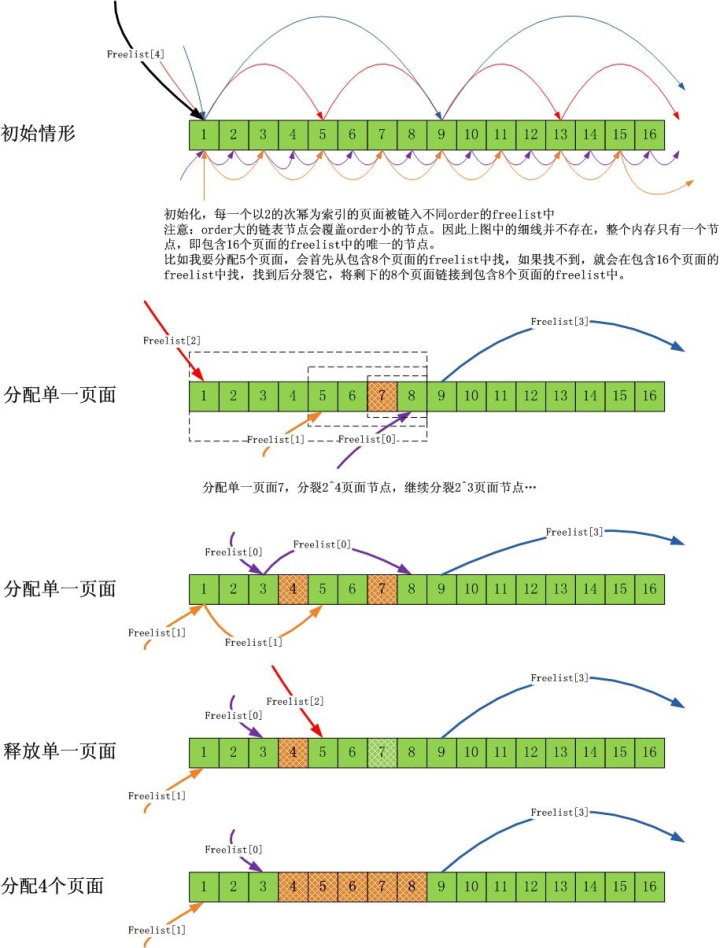
注意,本文是关于优化的,不是伙伴系统的科普,所以我假设大家已经理解了伙伴系统。
鉴于 slab 缓存对象大多数都是不超过 1 个页面的小结构(不仅仅 slab 系统,超过 1 个页面的内存需求相比 1 个页面的内存需求,很少),因此会有大量的针 对 1 个页面的内存分配需求。从伙伴系统的分配原理可知,如果持续大量分配单一页面,会有大量的 order 大于 0 的页面分裂成单一页面,在单核心 CPU 上, 这不是问题,但是在多核心 CPU 上,由于每一个 CPU 都会进行此类分配,而伙伴系统的分裂,合并操作会涉及大量的链表操作,这个锁开销是巨大的,因此需要 优化!
Linux 内核对伙伴系统针对单一页面的分配需求采取的批量分配“每 CPU 单一页面缓存”的方式!
每一个 CPU 拥有一个单一页面缓存池,需要单一页面的时候,可以无需加锁从当前 CPU 对应的页面池中获取页面。而当池中页面不足时,系统会批量从伙伴系统中拉取一堆页面到池中,反过来,在单一页面释放的时候,会择优将其释放到每 CPU 的单一页面缓存中。
为了维持“每 CPU 单一页面缓存”中页面的数量不会太多或太少(太多会影响伙伴系统,太少会影响 CPU 的需求),系统保持了两个值,当缓存页面数量低于 low 值的时候,便从伙伴系统中批量获取页面到池中,而当缓存页面数量大于 high 的时候,便会释放一些页面到伙伴系统中。
小结
多 CPU 操作系统内核中,关键的开销就是锁的开销。我认为这是一开始的设计导致的,因为一开始,多核 CPU 并没有出现,单核 CPU 上的共享保护几乎都是可以 用“禁中断”,“禁抢占”来简单实现的,到了多核时代,操作系统同样简单平移到了新的平台,因此同步操作是在单核的基础上后来添加的。简单来讲,目前的主 流操作系统都是在单核年代创造出来的,因此它们都是顺应单核环境的,对于多核环境,可能它们一开始的设计就有问题。
不管怎么说,优化操作的不二法门就是禁止或者尽量减少锁的操作。随之而来的思路就是为共享的关键数据结构创建"每 CPU 的缓存“,而这类缓存分为两种类型:
1).数据通路缓存。比如路由表之类的数据结构,你可以用 RCU 锁来保护,当然如果为每一个 CPU 都创建一个本地路由表缓存,也是不错的,现在的问题是何时更新它们,因为所有的缓存都是平级的,因此一种批量同步的机制是必须的。2).管理机制缓存。比 如 slab 对象缓存这类,其生命周期完全取决于使用者,因此不存在同步问题,然而却存在管理问题。采用分级 cache 的思想是好的,这个非常类似于 CPU 的 L1/L2/L3 缓存,采用这种平滑的开销逐渐增大,容量逐渐增大的机制,并配合以设计良好的换入/换出等算法,效果是非常明显的。
文章出自 Github:https://github.com/0voice/linux_kernel_wiki

直奔腾讯去,一起学习:Q群654378476 2021.05.20 加入
我要学完第十代《Linux C/C++服务架构开发》知识体系里的内容,直奔腾讯去,一起学习:Q群654378476 系统学习免费课程:https://ke.qq.com/course/417774?flowToken=1033508









评论