ARTS 打卡 -03
Algorithm
1st answer
Back up the original vector, which use O(n) extra memory space.
Runtime beats 86.65%.
Memory beats 18.36%.
Better answer
Reverse the vector three times, which is done in-place with O(1) extra memory space.
Review
OpenVINO™ toolkit
Introduction
OpenVINO™ toolkit, short for Open Visual Inference and Neural network Optimization toolkit, provides developers with improved neural network performance on a variety of Intel® processors and helps them further unlock cost-effective, real-time vision applications. The toolkit enables deep learning inference and easy heterogeneous execution across multiple Intel® platforms (CPU, Intel® Processor Graphics)—providing implementations across cloud architectures to edge devices. This open source distribution provides flexibility and availability to the developer community to innovate deep learning and AI solutions.
This toolkit allows developers to deploy pre-trained deep learning models through a high-level C++ Inference Engine API integrated with application logic.
This open source version includes two components: namely Model Optimizer and Inference Engine, as well as CPU, GPU and heterogeneous plugins to accelerate deep learning inferencing on Intel® CPUs and Intel® Processor Graphics. It supports pre-trained models from the Open Model Zoo, along with 100+ open source and public models in popular formats such as Caffe*, TensorFlow*, MXNet* and ONNX*.
Deployment Workflow
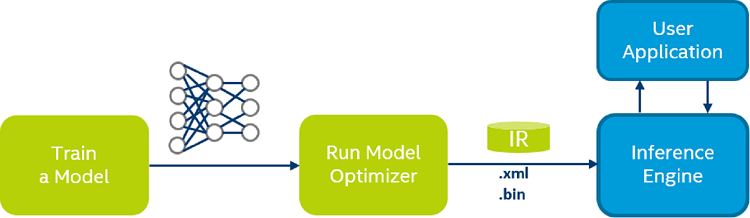
The process assumes that you have a network model trained using one of the supported frameworks. The scheme below illustrates the typical workflow for deploying a trained deep learning model:
The steps are:
Configure Model Optimizer for the specific framework (used to train your model).
Run Model Optimizer to produce an optimized Intermediate Representation (IR) of the model based on the trained network topology (.xml), weights and biases values (.bin), and other optional parameters.
Test the model in the IR format using the Inference Engine in the target environment with provided Inference Engine sample applications.
Integrate Inference Engine in your application to deploy the model in the target environment.
References
https://01.org/openvinotoolkit
https://docs.openvinotoolkit.org/
https://github.com/openvinotoolkit/openvino
https://docs.openvinotoolkit.org/latest/_docs_IE_DG_Introduction.html
Tips
std::emplace_back() vs std::push_back()
push_back() copies a string into a vector. First, a new string object will be implicitly created initialized with provided char*. Then push_back will be called which will copy this string into the vector using the move constructor because the original string is a temporary object. Then the temporary object will be destroyed.
emplace_back() constructs a string in-place, so no temporary string will be created but rather emplace_back() will be called directly with char* argument. It will then create a string to be stored in the vector initialized with this char*. So, in this case, we avoid constructing and destroying an unnecessary temporary string object.
Share
Lambda Expressions
Constructs a closure: an unnamed function object capable of capturing variables in scope.
https://www.geeksforgeeks.org/lambda-expression-in-c/
Multithreading in C++11
https://www.geeksforgeeks.org/multithreading-in-cpp/

还未添加个人签名 2020.05.21 加入
还未添加个人简介









评论