在看vue源码的过程中,不只加深了对vue本身的理解,也理解了正则,以及各种设计模式。
博客大部分是从代码开始讲起,所以,我打算更细致的讲一讲这部分的思想。
首先我们要知道什么是AST,以及为什么要用AST生成虚拟dom。
AST是指抽象语法树(abstract syntax tree),或者语法树(syntax tree),是源代码的抽象语法结构的树状表现形式。Vue在mount过程中,template会被编译成AST语法树。
简单来说,在js中AST的表现形式是像下面的结构
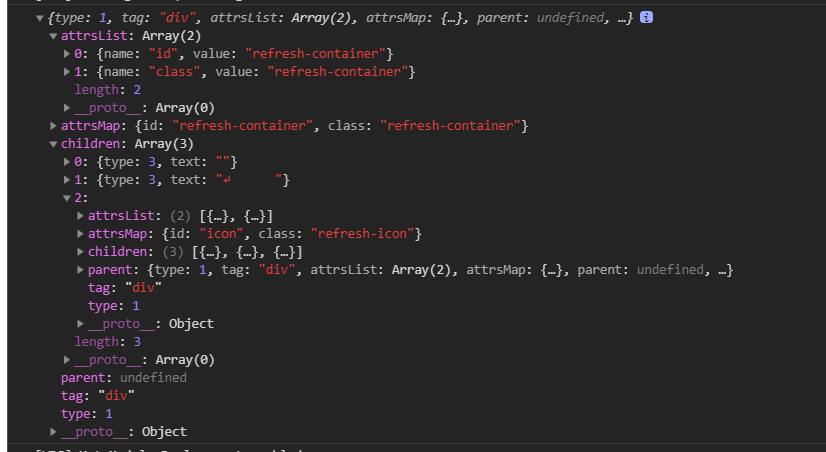
AST Object
它是怎么来的呢? 是通过js中的类html字符串转换而来的,所以我们的任务就变成了把类html转换成这种结构啦。 下面我先给出一串模板
const template = `
<div id="refresh-container" class="refresh-container">
<div id="icon" class="refresh-icon">
<canvas width="60" height="60" id="canvas"></canvas>
</div>
</div>
`
#1
首先我们对这个字符串进行trim操作,去除两端的空格。然后我们要用 let textStart = html.indexOf('<')判断这个字符串<的位置。这时候就分成了三个部分
我们从最简单的textStart = 0的情况开始
1.1
这时候又会有两种可能性
这一部分的结构讲完了, 再继续看看<0的情况
1.2
当textStart<0的时候,只有一种可能,这段html字符串已经没有标签或者注释了,即是纯文本。
1.3
当textStart > 0的时候,说明在标签或者注释之前含有文本(这里我们暂时不考虑文本中有<的情况,大家可以自己去尝试一下)
2
知道了所有的情况,我们来了解一下怎么处理这些情况。
2.1
对1.的情况,当匹配到标签的时候,比如<div id="refresh-container" class="refresh-container">我们要把它的tagName, id, class等等属性得到。设置两个栈。一个叫checkStack,用于与之后匹配到的结束标签进行比对。一个叫AstStack,用于辅助AST的建立。

checkStack
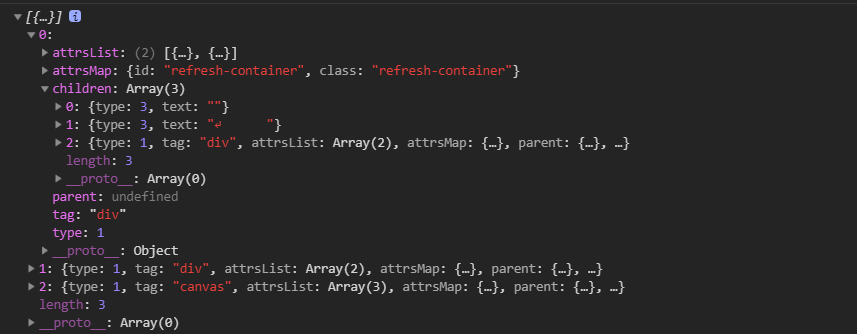
AST Stack
checkStack中单纯存放了tagName和attr,而AstStack中存放的是他的父元素和子元素,这些可以用于建立一个AST。
所以流程如下:
匹配到开始标签 --> 获得各种属性,创建一个match对象--> 推入checkStack中-->推入AstStack中 (这里先不讨论自闭和标签的情况,等会会用代码来详细讨论)
如果匹配到注释,不推入checkStack,具体流程如下:
匹配到注释开始 --> 获得注释所有的内容,并匹配到注释结束标签 --> 不推入checkStack --> 从AstStack中获取最后一个元素, 把该注释对象推入AstStack栈顶的children数组中
2.2
没有标签或注释,则会把该段纯文本推入AstStack栈顶元素的children中, 并不再遍历该段html,如果没有栈顶元素,则会报错
2.3
与2.2情况类似,只是还会继续遍历html
3
知道了流程和怎么处理,我们可以愉快的开始看代码啦!我们来看看精简版的,然后大家熟悉了流程可以再去看vue的源码
先来定义几个正则
const attribute = /^\s*([^\s"'<>\\/=]+)(?:\s*(=)\s*(?:"([^"]*)"+|'([^']*)'+|([^\s"'=<>`]+)))?/
const ncname = '[a-zA-Z_][\\w\\-\\.]*'
const qnameCapture = `((?:${ncname}\\:)?${ncname})`
const startTagOpen = new RegExp(`^<${qnameCapture}`)
const startTagClose = /^\s*(\/?)>/
const endTag = new RegExp(`^<\/${qnameCapture}[^>]*>`)
const comment = /^<!--/
具体解析,可以看我之前的文章。
我们使用parse函数作为一个主入口函数,
function parse(template) {
let root
let currentParent
let AstStack = []
parseHtml(template, {
start (tagName, attrs, isUnary) {
let element = createASTElement(tagName, attrs, currentParent)
if (!root) {
root = element
}
if (currentParent) {
currentParent.children.push(element)
element.parent = currentParent
}
if (!isUnary) {
AstStack.push(element)
currentParent = element
}
console.log(AstStack)
},
end () {
AstStack.pop()
currentParent = AstStack[AstStack.length - 1]
},
char (text) {
if (!currentParent) {
console.error('你没有根元素!')
} else {
const children = currentParent.children
children.push({
type: 3,
text
})
}
},
comment (text) {
console.log(text)
if (currentParent) {
currentParent.children.push({
type: 3,
text,
isComment: true
})
}
}
})
return root
}
在parse函数中定义root,即根节点,所有的dom元素会挂载到root上。currentParent可以理解成AstStack的栈顶指针。
在parseHtml中传入三个函数,分别处理上面说的那三种情况。我们先看parseHtml。
function parseHtml(template, options) {
let html = template
let opt = options
let index = 0
let lastTag
let checkStack = []
while (html) {
let textStart = html.indexOf('<')
if (textStart === 0) {
if (html.match(comment)) {
let commentEnd = html.indexOf('-->')
console.log(commentEnd)
if (commentEnd >= 0) {
if (opt.comment) {
opt.comment(html.substring(4, commentEnd))
}
}
advance(commentEnd + 3)
continue
}
const startTagMatch = parseStartTag();
if (startTagMatch) {
handleStartTag(startTagMatch)
}
const endTagMatch = html.match(endTag)
if (endTagMatch) {
advance(endTagMatch[0].length)
parseEndTag(endTagMatch[1])
}
}
let text
if (textStart >= 0) {
text = html.slice(0, textStart)
advance(textStart)
}
if (textStart < 0) {
text = html
html = ''
}
if (opt.char) {
opt.char(text)
}
}
}
对传入的字符串进行遍历,当以<开头的时候,如果匹配到comment,则再次查找注释结尾,把注释内容保留传入opt.commet()函数处理,然后再调用advance()截除注释部分。
来看看advance()
function advance (n) {
index += n
html = html.substring(n)
}
只是简单的增加index,并截除html
如果匹配到startTag, 即<div之类的标签, 则调用parseStartTag(),他会返回一个match对象并push进checkStack中.
function parseStartTag() {
const start = html.match(startTagOpen)
if (start) {
let match = {
tagName: start[1],
attrs: [],
start: index
}
advance(start[0].length)
let end, attr
while (!(end = html.match(startTagClose)) && (attr = html.match(attribute))) {
match.attrs.push(attr)
advance(attr[0].length)
}
if (end) {
match.isUnary = end[1]
match.end = index
advance(end[0].length)
return match
}
}
}
返回match对象后,再传入handleStartTag(),把该match对象推入checkStack中,并准备推入AstStack。
function handleStartTag(match) {
* 1: 格式化attr
* 2: 把标签入栈,方便匹配
* 3: 调用start函数,创建AST
* */
let tagName = match.tagName
let unaryTag = match.isUnary
let attrs = []
attrs.length = match.attrs.length
for (let i = 0; i < attrs.length; i++) {
attrs[i] = {
name: match.attrs[i][1],
value: match.attrs[i][3] || match.attrs[i][4] || match.attrs[i][5]
}
}
let isUnary = isUnaryTag(tagName) || !!unaryTag
if (!isUnary) {
checkStack.push({
tag: tagName,
attrs,
lowerCaseTag: tagName.toLowerCase()
})
console.log(checkStack)
}
if (opt.start) {
opt.start(tagName, attrs, isUnary)
}
}
如果是自闭合标签,那就不推入checkStack栈,因为不用于之后的标签进行比对。然后再调用start()对AST进行处理
如果匹配到endTag,如</div>等。
调用parseEndTag(),传入tagName,即div
function parseEndTag(tagName) {
* 对endTag通过checkStack进行匹配, 如果匹配到了则出栈, 维护栈顶指针,并调用end方法
* */
if (tagName) {
tagName = tagName.toLowerCase()
let pos
for (pos = checkStack.length - 1; pos>=0; pos--) {
if (checkStack[pos].tagName === tagName) {
break
}
}
if (pos >= 0) {
let i = checkStack.length - 1
if (i > pos) {
console.error(`tag<${checkStack[i - 1].tagName}没有匹配的end tag`)
}
opt.end()
checkStack.length = pos
lastTag = checkStack[pos - 1].tagName
}
}
}
再parseEnd中做做匹配。如果匹配到了标签,有可能匹配错误,所以就要再判断匹配的成功性
因为这些很简单,所以我就不再多讲了,大家可以看代码注释,或者直接在下面跟我讨论,我们直接讨论textStart>0和textStart<0的情况
我们可以将这两种情况统一起来考虑,因为本质上都是处理字符串.
let text
if (textStart >= 0) {
text = html.slice(0, textStart)
advance(textStart)
}
if (textStart < 0) {
text = html
html = ''
}
if (opt.char) {
opt.char(text)
}
核心思想都是将文本提取出来传入opt.char()处理。这里要注意,我们代码的缩进也是属于一个个空白字符,所以在碰到缩进的时候也是会调用这些方法的。
其实说到这里大部分都说完了,剩下的细节大家可以去看看源码。












评论 (2 条评论)