Elasticsearch 详细剖析

1、什么是 ElasticSearch
Elaticsearch,简称为 es, es 是一个开源的高扩展的分布式全文检索引擎,它可以近乎实时的存储、检索数据;本身扩展性很好,可以扩展到上百台服务器,处理 PB 级别的数据。es 也使用 Java 开发并使用 Lucene 作为其核心来实现所有索引和搜索的功能,但是它的目的是通过简单的 RESTful API 来隐藏 Lucene 的复杂性,从而让全文搜索变得简单。
2、ElasticSearch 使用案例
• 2013 年初,GitHub 抛弃了 Solr,采取 ElasticSearch 来做 PB 级的搜索。 “GitHub 使用 ElasticSearch 搜索 20TB 的数据,包括 13 亿文件和 1300 亿行代码”
• 维基百科:启动以 elasticsearch 为基础的核心搜索架构
• SoundCloud:“SoundCloud 使用 ElasticSearch 为 1.8 亿用户提供即时而精准的音乐搜索服务”
• 百度:百度目前广泛使用 ElasticSearch 作为文本数据分析,采集百度所有服务器上的各类指标数据及用户自定义数据,通过对各种数据进行多维分析展示,辅助定位分析实例异常或业务层面异常。目前覆盖百度内部 20 多个业务线(包括 casio、云分析、网盟、预测、文库、直达号、钱包、风控等),单集群最大 100 台机器,200 个 ES 节点,每天导入 30TB+数据
• 新浪使用 ES 分析处理 32 亿条实时日志
• 阿里使用 ES 构建挖财自己的日志采集和分析体系
3、ElasticSearch 对比 Solr
• Solr 利用 Zookeeper 进行分布式管理,而 Elasticsearch 自身带有分布式协调管理功能;
• Solr 支持更多格式的数据,而 Elasticsearch 仅支持 json 文件格式;
• Solr 官方提供的功能更多,而 Elasticsearch 本身更注重于核心功能,高级功能多有第三方插件提供;
• Solr 在传统的搜索应用中表现好于 Elasticsearch,但在处理实时搜索应用时效率明显低于 Elasticsearch
4、ElasticSearch 架构图以及基本概念(术语)
1、es 概述
Elasticsearch 是面向文档(document oriented)的,这意味着它可以存储整个对象或文档(document)。然而它不仅仅是存储,还会索引(index)每个文档的内容使之可以被搜索。在 Elasticsearch 中,你可以对文档(而非成行成列的数据)进行索引、搜索、排序、过滤。
Elasticsearch 比传统关系型数据库如下:
Relational DB -> Databases -> Tables -> Rows -> ColumnsElasticsearch-> Indices -> Types -> Documents -> Fields
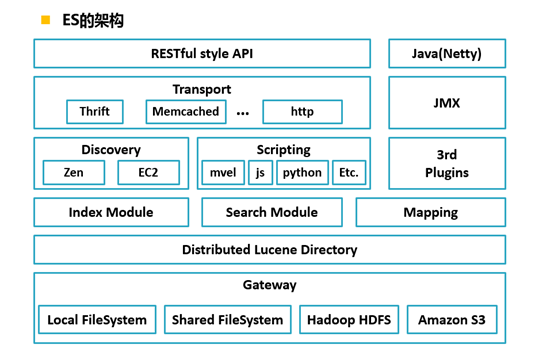
2、ES 架构模块
Gateway 是 ES 用来存储索引的文件系统,支持多种类型。
Gateway 的上层是一个分布式的 lucene 框架。
Lucene 之上是 ES 的模块,包括:索引模块、搜索模块、映射解析模块等
ES 模块之上是 Discovery、Scripting 和第三方插件。
Discovery 是 ES 的节点发现模块,不同机器上的 ES 节点要组成集群需要进行消息通信,集群内部需要选举 master 节点,这些工作都是由 Discovery 模块完成。支持多种发现机制,如 Zen 、EC2、gce、Azure。
Scripting 用来支持在查询语句中插入 javascript、python 等脚本语言,scripting 模块负责解析这些脚本,使用脚本语句性能稍低。ES 也支持多种第三方插件。
再上层是 ES 的传输模块和 JMX.传输模块支持多种传输协议,如 Thrift、memecached、http,默认使用 http。JMX 是 java 的管理框架,用来管理 ES 应用。
最上层是 ES 提供给用户的接口,可以通过 RESTful 接口和 ES 集群进行交互。
3、Elasticsearch 核心概念
1、索引 index
一个索引就是一个拥有几分相似特征的文档的集合。比如说,你可以有一个客户数据的索引,另一个产品目录的索引,还有一个订单数据的索引。一个索引由一个名字来标识(必须全部是小写字母的),并且当我们要对对应于这个索引中的文档进行索引、搜索、更新和删除的时候,都要使用到这个名字。在一个集群中,可以定义任意多的索引。
2、类型 type
在一个索引中,你可以定义一种或多种类型。一个类型是你的索引的一个逻辑上的分类/分区,其语义完全由你来定。通常,会为具有一组共同字段的文档定义一个类型。比如说,我们假设你运营一个博客平台并且将你所有的数据存储到一个索引中。在这个索引中,你可以为用户数据定义一个类型,为博客数据定义另一个类型,当然,也可以为评论数据定义另一个类型。
3、字段 Field
相当于是数据表的字段,对文档数据根据不同属性进行的分类标识
4、映射 mapping
mapping 是处理数据的方式和规则方面做一些限制,如某个字段的数据类型、默认值、分析器、是否被索引等等,这些都是映射里面可以设置的,其它就是处理 es 里面数据的一些使用规则设置也叫做映射,按着最优规则处理数据对性能提高很大,因此才需要建立映射,并且需要思考如何建立映射才能对性能更好。
5、文档 document
一个文档是一个可被索引的基础信息单元。比如,你可以拥有某一个客户的文档,某一个产品的一个文档,当然,也可以拥有某个订单的一个文档。文档以 JSON(Javascript Object Notation)格式来表示,而 JSON 是一个到处存在的互联网数据交互格式。
在一个 index/type 里面,你可以存储任意多的文档。注意,尽管一个文档,物理上存在于一个索引之中,文档必须被索引/赋予一个索引的 type。
6、集群 cluster
一个集群就是由一个或多个节点组织在一起,它们共同持有整个的数据,并一起提供索引和搜索功能。一个集群由一个唯一的名字标识,这个名字默认就是“elasticsearch”。这个名字是重要的,因为一个节点只能通过指定某个集群的名字,来加入这个集群
7、节点 node
一个节点是集群中的一个服务器,作为集群的一部分,它存储数据,参与集群的索引和搜索功能。和集群类似,一个节点也是由一个名字来标识的,默认情况下,这个名字是一个随机的漫威漫画角色的名字,这个名字会在启动的时候赋予节点。这个名字对于管理工作来说挺重要的,因为在这个管理过程中,你会去确定网络中的哪些服务器对应于 Elasticsearch 集群中的哪些节点。
一个节点可以通过配置集群名称的方式来加入一个指定的集群。默认情况下,每个节点都会被安排加入到一个叫做“elasticsearch”的集群中,这意味着,如果你在你的网络中启动了若干个节点,并假定它们能够相互发现彼此,它们将会自动地形成并加入到一个叫做“elasticsearch”的集群中。
在一个集群里,只要你想,可以拥有任意多个节点。而且,如果当前你的网络中没有运行任何 Elasticsearch 节点,这时启动一个节点,会默认创建并加入一个叫做“elasticsearch”的集群。
8、分片和复制 shards&replicas
一个索引可以存储超出单个结点硬件限制的大量数据。比如,一个具有 10 亿文档的索引占据 1TB 的磁盘空间,而任一节点都没有这样大的磁盘空间;或者单个节点处理搜索请求,响应太慢。为了解决这个问题,Elasticsearch 提供了将索引划分成多份的能力,这些份就叫做分片。当你创建一个索引的时候,你可以指定你想要的分片的数量。每个分片本身也是一个功能完善并且独立的“索引”,这个“索引”可以被放置到集群中的任何节点上。分片很重要,主要有两方面的原因: 1)允许你水平分割/扩展你的内容容量。 2)允许你在分片(潜在地,位于多个节点上)之上进行分布式的、并行的操作,进而提高性能/吞吐量。
至于一个分片怎样分布,它的文档怎样聚合回搜索请求,是完全由 Elasticsearch 管理的,对于作为用户的你来说,这些都是透明的。
在一个网络/云的环境里,失败随时都可能发生,在某个分片/节点不知怎么的就处于离线状态,或者由于任何原因消失了,这种情况下,有一个故障转移机制是非常有用并且是强烈推荐的。为此目的,Elasticsearch 允许你创建分片的一份或多份拷贝,这些拷贝叫做复制分片,或者直接叫复制。
复制之所以重要,有两个主要原因: 在分片/节点失败的情况下,提供了高可用性。因为这个原因,注意到复制分片从不与原/主要(original/primary)分片置于同一节点上是非常重要的。扩展你的搜索量/吞吐量,因为搜索可以在所有的复制上并行运行。总之,每个索引可以被分成多个分片。一个索引也可以被复制 0 次(意思是没有复制)或多次。一旦复制了,每个索引就有了主分片(作为复制源的原来的分片)和复制分片(主分片的拷贝)之别。分片和复制的数量可以在索引创建的时候指定。在索引创建之后,你可以在任何时候动态地改变复制的数量,但是你事后不能改变分片的数量。
默认情况下,Elasticsearch 中的每个索引被分片 5 个主分片和 1 个复制,这意味着,如果你的集群中至少有两个节点,你的索引将会有 5 个主分片和另外 5 个复制分片(1 个完全拷贝),这样的话每个索引总共就有 10 个分片。
版权声明: 本文为 InfoQ 作者【大数据技术指南】的原创文章。
原文链接:【http://xie.infoq.cn/article/07950e89243eb064b079cbac0】。
本文遵守【CC-BY 4.0】协议,转载请保留原文出处及本版权声明。

还未添加个人签名 2021.03.07 加入
还未添加个人简介









评论