Kyuubi: 网易数帆开源的企业级数据湖探索平台(架构篇)

Kyuubi 是网易数帆旗下易数大数据团队开源的一个企业级数据湖探索平台,建立在 Apache Spark 之上。Kyuubi 提供一个高性能的通用 JDBC 和 SQL 执行引擎,通过它,用户能够像处理普通数据一样处理大数据。本文将详细解读 Kyuubi 的架构设计。
引言
开源大数据项目的繁荣带来了强大的大数据平台,而对于负责数据价值挖掘的终端用户而言,平台的技术门槛是另一种挑战。如果能将平台的能力统合,并不断地优化和迭代,让用户能够通过 JDBC 和 SQL 这种最普遍最通用的技术来使用,数据生产力将可以得到进一步的提升。
Kyuubi就是在此背景下诞生的一个企业级数据湖探索平台,它能够作为一个高性能的通用 JDBC 和 SQL 执行引擎,促进用户像处理普通数据一样处理大数据。

Kyuubi 提供了一个标准化的 JDBC 接口,在大数据场景下可以方便地进行数据访问。终端用户可以专注于开发自己的业务系统和挖掘数据价值,而无需了解底层的大数据平台(计算引擎、存储服务、元数据管理等)。
Kyuubi 依赖 Apache Spark 提供高性能的数据查询能力,引擎能力的每一次提升,都能帮助 Kyuubi 的性能实现质的飞跃。此外,Kyuubi 通过引擎缓存提升了 ad-hoc 响应能力,并通过横向扩展和负载均衡提升了并发能力。
Kyuubi 提供完整的认证和授权服务,确保数据和元数据的安全。
Kyuubi 提供强大的高可用性和负载均衡,以保证 SLA 的承诺。
Kyuubi 提供两级弹性资源管理架构,有效提高资源利用率,同时覆盖所有场景的性能和响应需求,包括交互式,或批处理和点查询,或全表扫描。
Kyuubi 拥抱 Spark,并在 Spark 之上构建了一个生态系统,这它使得能够快速扩展现有的生态系统,并引入新的特性,例如云原生支持和Data Lake/Lake House支持。
Kyuubi 的愿景是建立在 Apache Spark 和 Data Lake 技术之上,统一门户,成为一个理想的数据湖管理平台。它可以以纯 SQL 的方式支持数据处理(如 ETL)和分析(如 BI)。所有的工作负载都可以在同一个平台上完成,使用一份数据,一个 SQL 接口。
架构概述
Kyuubi 系统的基本技术架构如下图所示。
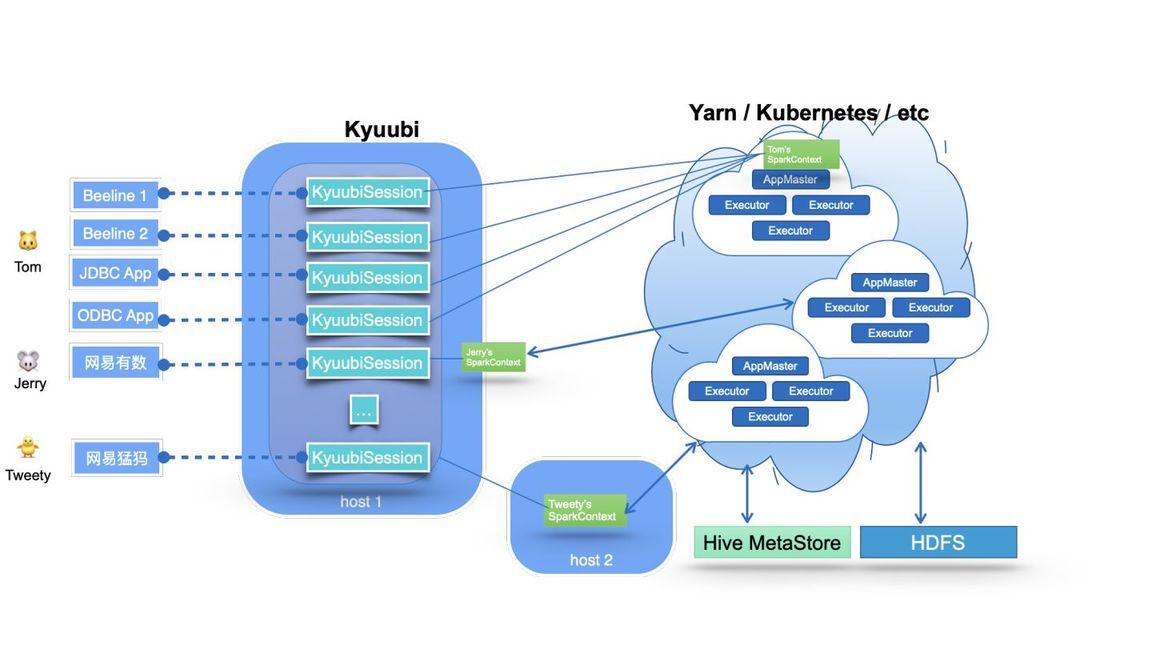
图的中间部分是 Kyuubi 服务端的主要部分,它处理来自图像左边所示的客户端的连接和执行请求。在 Kyuubi 中,这些连接请求被维护为Kyuubi Session,执行请求被维护为Kyuubi Operation,并与相应的 session 进行绑定。
Kyuubi Session的创建可以分为两种情况:轻量级和重量级。大多数 session 的创建都是轻量级的,用户无感知。唯一重量级的情况是在用户的共享域中没有实例化或缓存SparkContext,这种情况通常发生在用户第一次连接或长时间没有连接的时候。这种一次性成本的 session 维护模式可以满足大部分的 ad-hoc 快速响应需求。
Kyuubi 以松耦合的方式维护与SparkConext的连接。这些SparkContexts可以是本服务实例在客户端部署模式下在本地创建的 Spark 程序,也可以是集群部署模式下在 Yarn 或 Kubernetes 集群中创建的。在高可用模式下,这些SparkConext也可以由其他机器上的 Kyuubi 实例创建,然后由这个实例共享。
这些SparkConext实例本质上是由 Kyuubi 服务托管的远程查询执行引擎程序。这些程序在 Spark SQL 上实现,并对 SQL 语句进行端到端编译、优化和执行,以及与元数据(如 Hive Metastore)和存储(如 HDFS)服务进行必要的交互,最大限度地发挥 Spark SQL 的威力。它们可以自行管理自己的生命周期,自行缓存和回收,并且不受 Kyuubi 服务器上故障转移的影响。
接下来,我们来分享一下 Kyuubi 的一些关键设计理念。
统一接口
Kyuubi 实现了 Hive Service RPC 模块,它提供了与 HiveServer2 和 Spark Thrift Server 相同的数据访问方式。在客户端,您可以构建奇妙的业务报表、BI 应用,甚至 ETL 工作,只通过 Hive JDBC 模块。
您只需要熟悉结构化查询语言(SQL)和 Java 数据库连接(JDBC)就可以处理海量数据。它可以帮助您专注于业务系统的设计和实现。
SQL 是访问关系型数据库的标准语言,在大数据生态中也非常流行。
JDBC 为工具/数据库开发者提供了一个标准的 API,使得使用纯 Java API 编写数据库应用成为可能。
目前有很多免费或商业的 JDBC 工具。
运行时资源弹性
Kyuubi 和 Spark Thrift Server(STS)最大的区别在于,STS 是一个单一的 Spark 应用。例如,如果一个应用运行在 Apache Hadoop Yarn 集群上,这个应用也是一个单一的 Yarn 应用,创建后只能存在于 Yarn 集群的特定固定队列中。Kyuubi 支持提交多个 Spark 应用。
对于资源管理,Yarn 失去了资源管理器的角色,没有起到相应的资源隔离和共享的作用。当来自客户端的用户拥有不同的资源队列权限时,这种情况下 STS 将无法处理。
对于数据访问,单个 Spark 应用在全球范围内只有一个用户,也就是sparkUser,我们必须赋予它一个类似超级用户的角色,才能让它对不同的客户端用户进行数据访问,这在生产环境中是一种极不安全的做法。
Kyuubi 会根据客户端的连接请求创建不同的 Spark 应用,这些应用可以放在不同的共享域中,供其他连接请求共享。
Kyuubi 在启动过程中不会占用集群管理器(如 Yarn)的任何资源,如果没有任何活跃的 session 与SparkContext交互,Kyuubi 会将所有资源返还。
Spark 还提供了动态资源分配,根据工作负载动态调整应用程序占用的资源。这意味着应用可以将不再使用的资源还给集群,当有需求时再次请求。如果多个应用程序在您的 Spark 集群中共享资源,这个特性特别有用。
通过这些特性,Kyuubi 提供了一个两级弹性资源管理架构,以有效提高资源利用率。
比如说,
如果名为tom的用户打开了像上面这样的连接,Kyuubi 将尝试在 Yarn 集群中名为thequeue的队列中创建一个拥有[3,500]个执行器(3 核,每个 10g mem)的 Spark SQL 引擎应用程序。
一方面,由于 tom 启用了 Spark 的动态资源请求特性,Spark 会根据 SQL 操作的规模和队列中的可用资源,高效地请求和回收程序内的执行器。另一方面,当 Kyuubi 发现程序闲置时间过长时,也会对程序本身进行回收。
高可用性与负载均衡
对于企业服务来说,服务水平协议(SLA)的承诺必须达到很高的水平。而并发量也需要足够强大,以支持整个企业的请求。Spark Thrift Server 作为单一的 Spark 应用,在没有实现 High Availability 的情况下,很难满足 SLA 和并发的要求。当有大的查询请求时,在元数据服务访问、Spark Driver 的调度和内存压力,或者是应用的整体计算资源限制等方面都有潜在的瓶颈。
Kyuubi 基于 ZooKeeper 同时提供了高可用和负载均衡解决方案,如下图所示。
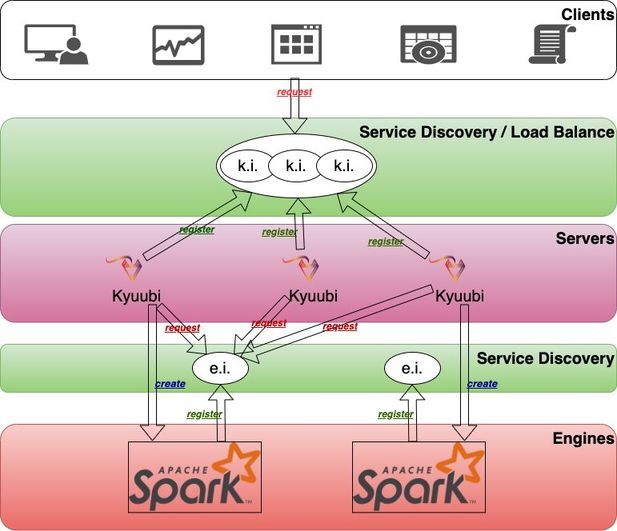
我们从上到下进行分解。
图中最上面的是客户端层,客户端可以从服务发现层的命名空间中找到多个注册的 Kyuubi 实例(k.i.),然后选择一个连接。注册到同一命名空间的 Kyuubi 实例相互提供了负载均衡的能力。
被选中的 Kyuubi 实例将从服务发现层的 eng-namespace 中选择一个可用的引擎实例(e.i.)建立连接。如果没有找到可用的实例,它将创建一个新的实例,等待引擎完成注册,然后继续连接。
如果是同一个人请求新的连接,则会将连接设置为同一个或另一个 Kyuubi 实例,但引擎实例会被重复使用。
对于来自不同用户的连接,将重复步骤 2 和 3。这是因为在服务发现层中,用于存储引擎实例地址的命名空间是基于用户隔离的(默认情况下),不同用户不能跨命名空间访问其他实例。
认证与授权
在一个安全的集群中,服务应该能够识别和认证呼叫者。由于用户声称的事实并不意味着这一定是真的。Kyuubi 的认证过程用于验证客户端用来与 Kyuubi 服务器对话的用户身份。一旦完成,如果成功,客户端和服务器之间将建立一个可信的连接;否则拒绝。
经过验证的客户端用户也将是创建关联引擎实例的用户,然后可以应用数据库对象或存储的授权。我们还创建了一个Submarine: Spark Security作为外部插件,实现基于 SQL 标准的细粒度授权。
结论
Kyuubi 是一个统一的多租户 JDBC 接口,用于大规模数据处理和分析,建立在Apache Spark™之上。它扩展了 Spark Thrift Server 在企业应用中的场景,其中最重要的是多租户支持。
除了网易集团业务,目前已有网约车、餐饮零售、物流等领域多家企业在其大数据技术栈中采用了 Kyuubi。欢迎大家加入到Kyuubi项目,共促大数据价值最大化!
作者简介: 燕青,网易数帆-易数事业部高级工程师,专注于开源大数据领域。网易数帆开源项目 Kyuubi 企业级数据湖探索平台作者。Apache Spark Committer / Apache Submarine Committer。
版权声明: 本文为 InfoQ 作者【网易数帆】的原创文章。
原文链接:【http://xie.infoq.cn/article/02eff06913b8a64aa2f370712】。文章转载请联系作者。

专注数字化转型基础软件研发 2020.07.22 加入
源自网易杭州研究院,是网易数字经济的创新载体和技术孵化器。聚合云计算、大数据、人工智能等新型技术,聚焦研发数据智能、软件研发、基础设施与中间件等基础软件,推动数字化业务发展。









评论