第十二周总结
发布于: 2020 年 08 月 31 日

本周讲授的是关于大数据的课程,包括大数据的发展历史、Hadoop 的由来,MapReduce 的核心代码逻辑,HDFS 框架的核心系统架构,以及数据分析用到的数据仓库工具 Hive。
一些基本的框架:
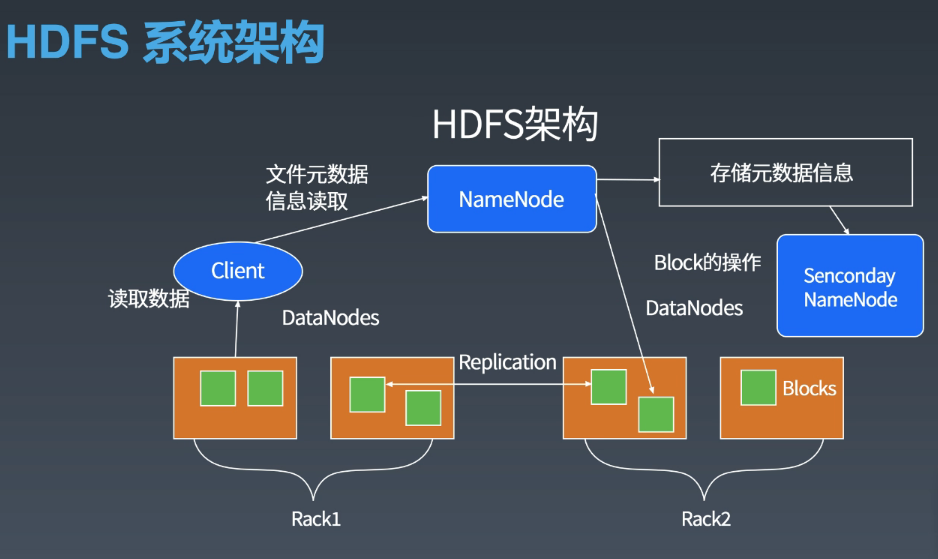
1.大数据存储用:HDFS。
HDFS 是把文件切分成块(默认 64M)存储的,每个块会部署在多个集群上,保证高可用。
HDFS 设计目标是以流式数据访问模式存储超大文件,适合一次写入多次读取。
对于需要低延迟的场景和大量小文件的场景,多用户随机写入的场景,不适合。
大数据批处理计算用:MapReduce(Yarn)和 Spark 框架
MapReduce 用来处理海量数据(大于 1TB),它会有上百上前的 CPU 实现并行处理,遵循移动计算比移动数据更划算的原则。
MapReduce 的特性:自动实现分布式并行计算、容错、提供状态监控工具,模型抽象简洁,易用。
适合 MapReduce 的计算类型有:TopK, K-means, Bayes, SQL
不适合 MapReduce 的计算类型:Fibonacci
大数据流处理计算用:Storm、Flink、Spark、Streaming
大数据应用的 NoSql 系统:HBase、Cassandra
应用场景
大数据分析与大数据仓库工具:Hive, SparkSQL
Hive 的架构和执行流程:
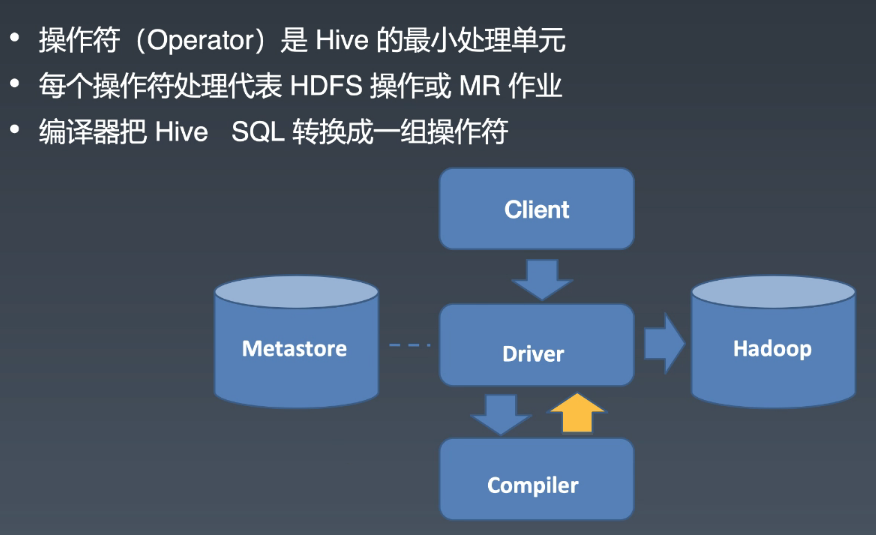
Hive 编译器:


大数据挖掘与机器学习:Mahout,MLib,TensorFlow

放肆才叫青春 2019.05.11 加入
IT软件工程师,一枚









评论